堆排序
- 前言
- 一、堆排序的基本思想
- 二、堆排序的特性总结
- 三、堆排序的动图展示
- 四、堆排序的代码实现
- 向上建堆
- test.c
前言
堆排序是一种利用堆数据结构实现的排序算法。首先,它将待排序的数组构建成一个大顶堆或小顶堆。然后,通过不断将堆顶元素(最大或最小)与末尾元素交换并重新调整堆,使得数组逐渐有序。最后,当堆的大小减至1时,排序完成。堆排序的时间复杂度为O(nlogn),空间复杂度为O(1),具有稳定性和适用性广的优点。
一、堆排序的基本思想

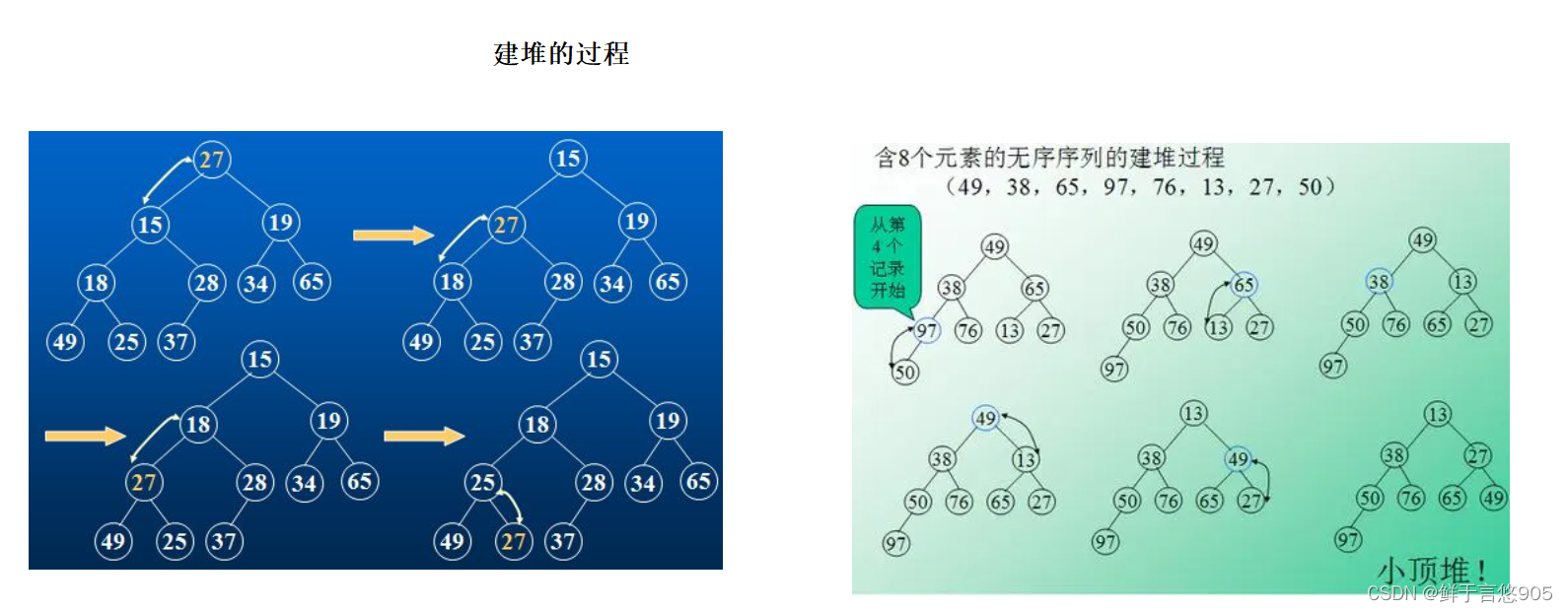
堆排序的基本思想是将待排序的序列构造成一个大顶堆或小顶堆,此时,整个序列的最大值(或最小值)就是堆顶的根节点。将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值或最小值),然后将剩余的堆重新构造成一个堆,这样就会得到新的最大值(或最小值)。如此反复执行,便能得到一个有序序列了。
具体实现时,首先需要根据给定的待排序数组构建一个初始堆。构建堆的过程通常是从最后一个非叶子节点开始,向上遍历每个节点,对每个节点进行下沉操作,以确保每个节点都满足堆的性质。下沉操作是堆排序中的关键步骤,它通过比较节点与其子节点的值,确保父节点的值大于(对于大顶堆)或小于(对于小顶堆)其子节点的值。
在堆构建完成后,堆的根节点就是序列中的最大(或最小)元素。将其与堆数组的最后一个元素交换,然后移除最后一个元素(或将其视为已排序部分),此时堆的大小减一。接着,对剩余部分重新进行下沉操作,以恢复堆的性质。这个过程重复进行,直到堆的大小减至1,此时序列已经完全排序。
堆排序的时间复杂度为O(nlogn),其中n是待排序序列的长度。这是因为构建初始堆的时间复杂度为O(n),而每次移除堆顶元素并重新构建堆的时间复杂度为O(logn)。由于这个过程需要重复n次,所以总的时间复杂度为O(nlogn)。堆排序是一种原地排序算法,因为它只涉及到元素之间的交换和移动,不需要额外的存储空间。
值得注意的是,堆排序是一种不稳定的排序算法。这是因为在构建堆和下沉的过程中,相同值的元素可能会改变它们的相对顺序。因此,如果稳定性是一个重要的考量因素,那么可能需要选择其他的排序算法,如归并排序或冒泡排序。
二、堆排序的特性总结
- 堆排序使用堆来选数,效率就高了很多。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(1)
- 稳定性:不稳定
堆排序是一种基于二叉堆数据结构所设计的排序算法,它兼具选择排序和插入排序的优点,并在许多情况下展现出其独特的性能特点。
- 空间效率:堆排序是一种原地排序算法,这意味着它不需要额外的存储空间来辅助排序过程,除了原数组本身。这使得堆排序在处理大数据集时,相较于其他需要额外空间的排序算法,具有更高的空间效率。
- 时间效率:堆排序的时间复杂度在最坏情况下为O(nlogn),其中n是待排序元素的数量。这意味着无论输入数据的初始状态如何,堆排序都能保持相对稳定的性能。这一点在处理大型数据集时尤为重要,因为某些排序算法(如快速排序)在特定输入情况下可能会退化为O(n²)的时间复杂度。
- 不稳定性:堆排序是一种不稳定的排序算法。这意味着如果两个元素具有相同的值,它们在排序后的相对位置可能会改变。这在某些应用中可能是一个缺点,但在其他不需要保持元素相对位置不变的场景中则不是问题。
- 易于实现:堆排序的算法逻辑相对简单,容易理解和实现。尽管其背后的二叉堆数据结构可能初看起来有些复杂,但一旦理解了其基本原理,实现堆排序就会变得相对直观。
- 适用性:堆排序特别适用于外部排序,即当数据量太大,无法一次性加载到内存中进行排序时。通过将数据分割成小块,并在每个小块上建立堆,然后逐步合并这些堆,可以实现大数据集的有效排序。
综上所述,堆排序是一种高效、稳定、易于实现且适用性广的排序算法。尽管它在某些方面可能不如其他排序算法(如快速排序或归并排序)出色,但在许多实际应用中,它仍然是一种非常有用的排序工具。
三、堆排序的动图展示
堆排序
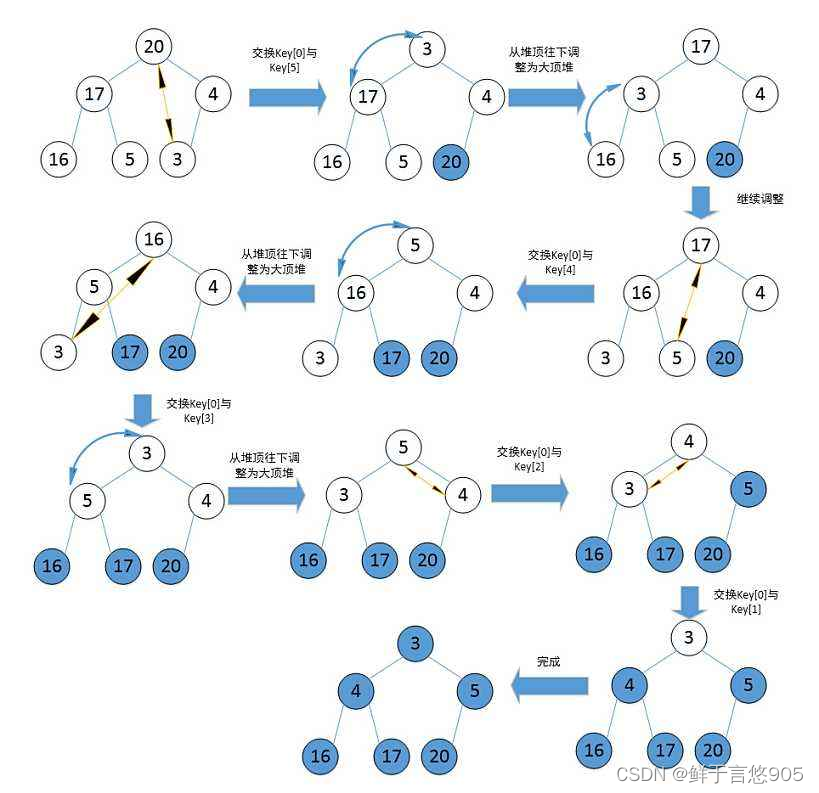
堆排序是一种基于二叉堆的排序算法,它通过构建最大堆或最小堆,然后不断删除堆顶元素并调整堆结构来实现排序。动图展示通常能够直观地展示堆排序的整个过程,包括初始堆的构建、堆顶元素的删除和堆的调整等步骤。通过动图展示,可以清晰地看到堆排序算法的执行过程,从而更好地理解和掌握该算法的实现原理。
四、堆排序的代码实现
向上建堆
详细可看这篇——堆

ps:上面是建堆的时间复杂度不是堆排序的时间复杂度
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
test.c
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
void HeapSort(int* a, int n);
void PrintArray(int* a, int n);
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child + 1] > a[child])
{
child++;
}
if (a[child] > a[parent])
{
Swap(&a[parent], &a[child]);
parent = child;
child = child * 2 + 1;
}
else
{
break;
}
}
}
void TestHeapSort()
{
int a[] = { 5, 13, 9, 16, 12, 4, 7, 1, 28, 25, 3, 9, 6, 2, 4, 7, 1, 8 };
//int a[] = { 5, 3, 9, 6, 2, 4, 7, 1, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
HeapSort(a, sizeof(a) / sizeof(int));
PrintArray(a, sizeof(a) / sizeof(int));
}
void PrintArray(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
void TestOP()
{
srand(time(0));
const int N = 10000;
int* a1 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
}
int begin1 = clock();
HeapSort(a1, N);
int end1 = clock();
printf("HeapSort:%d\n", end1 - begin1);
free(a1);
}
void HeapSort(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}
int main()
{
TestHeapSort();
TestOP();
return 0;
}
这段代码实现了堆排序算法。
首先,AdjustDown函数用来调整以parent为根节点的子树,使之符合大顶堆的性质。在每一次调整中,函数会找到parent节点的左右孩子中较大的那个,并与parent节点进行比较。如果孩子节点较大,则交换它们的值,并将parent更新为较大孩子的位置,继续向下调整。如果孩子节点不大于parent节点,则停止调整。这个过程保证了每一次调整都能将较大的元素移动到较下面的位置。
HeapSort函数首先通过调用AdjustDown函数将待排序数组调整为一个大顶堆。然后,它通过不断交换堆顶元素与最后一个元素,并缩小堆的范围来对堆进行排序。在每一次交换后,需要调用AdjustDown函数将交换后的堆顶元素移动到合适的位置。
最终,经过多次交换与调整,待排序数组就会按照从小到大的顺序排列好。