第五章:数据类构建器
数据类就像孩子一样。它们作为一个起点是可以的,但要作为一个成熟的对象参与,它们需要承担一些责任。
马丁·福勒和肯特·贝克¹
Python 提供了几种构建简单类的方法,这些类只是一组字段,几乎没有额外功能。这种模式被称为“数据类”,而dataclasses是支持这种模式的包之一。本章涵盖了三种不同的类构建器,您可以将它们用做编写数据类的快捷方式:
collections.namedtuple
最简单的方法——自 Python 2.6 起可用。
typing.NamedTuple
一种需要在字段上添加类型提示的替代方法——自 Python 3.5 起,3.6 中添加了class语法。
@dataclasses.dataclass
一个类装饰器,允许比以前的替代方案更多的定制化,增加了许多选项和潜在的复杂性——自 Python 3.7 起。
在讨论完这些类构建器之后,我们将讨论为什么数据类也是一个代码异味的名称:一种可能是糟糕面向对象设计的症状的编码模式。
注意
typing.TypedDict可能看起来像另一个数据类构建器。它使用类似的语法,并在 Python 3.9 的typing模块文档中的typing.NamedTuple之后描述。
但是,TypedDict不会构建您可以实例化的具体类。它只是一种语法,用于为将用作记录的映射值接受的函数参数和变量编写类型提示,其中键作为字段名。我们将在第十五章的TypedDict中看到它们。
本章的新内容
本章是流畅的 Python第二版中的新内容。第一版的第二章中出现了“经典命名元组”一节,但本章的其余部分是全新的。
我们从三个类构建器的高级概述开始。
数据类构建器概述
考虑一个简单的类来表示地理坐标对,如示例 5-1 所示。
示例 5-1。class/coordinates.py
class Coordinate:
def __init__(self, lat, lon):
self.lat = lat
self.lon = lon
那个Coordinate类完成了保存纬度和经度属性的工作。编写__init__样板变得非常乏味,特别是如果你的类有超过几个属性:每个属性都被提及三次!而且那个样板并没有为我们购买我们期望从 Python 对象中获得的基本功能:
>>> from coordinates import Coordinate
>>> moscow = Coordinate(55.76, 37.62)
>>> moscow
<coordinates.Coordinate object at 0x107142f10> # ①
>>> location = Coordinate(55.76, 37.62)
>>> location == moscow # ②
False >>> (location.lat, location.lon) == (moscow.lat, moscow.lon) # ③
True
①
从object继承的__repr__并不是很有用。
②
无意义的==;从object继承的__eq__方法比较对象 ID。
③
比较两个坐标需要显式比较每个属性。
本章涵盖的数据类构建器会自动提供必要的__init__、__repr__和__eq__方法,以及其他有用的功能。
注意
这里讨论的类构建器都不依赖继承来完成工作。collections.namedtuple和typing.NamedTuple都构建了tuple子类的类。@dataclass是一个类装饰器,不会以任何方式影响类层次结构。它们每个都使用不同的元编程技术将方法和数据属性注入到正在构建的类中。
这里是一个使用namedtuple构建的Coordinate类——一个工厂函数,根据您指定的名称和字段构建tuple的子类:
>>> from collections import namedtuple
>>> Coordinate = namedtuple('Coordinate', 'lat lon')
>>> issubclass(Coordinate, tuple)
True >>> moscow = Coordinate(55.756, 37.617)
>>> moscow
Coordinate(lat=55.756, lon=37.617) # ①
>>> moscow == Coordinate(lat=55.756, lon=37.617) # ②
True
①
有用的__repr__。
②
有意义的__eq__。
较新的typing.NamedTuple提供了相同的功能,为每个字段添加了类型注释:
>>> import typing
>>> Coordinate = typing.NamedTuple('Coordinate',
... [('lat', float), ('lon', float)])
>>> issubclass(Coordinate, tuple)
True
>>> typing.get_type_hints(Coordinate)
{'lat': <class 'float'>, 'lon': <class 'float'>}
提示
一个带有字段作为关键字参数构造的类型命名元组也可以这样创建:
Coordinate = typing.NamedTuple('Coordinate', lat=float, lon=float)
这更易读,也让您提供字段和类型的映射作为 **fields_and_types。
自 Python 3.6 起,typing.NamedTuple 也可以在 class 语句中使用,类型注解的写法如 PEP 526—变量注解的语法 中描述的那样。这样更易读,也方便重写方法或添加新方法。示例 5-2 是相同的 Coordinate 类,具有一对 float 属性和一个自定义的 __str__ 方法,以显示格式为 55.8°N, 37.6°E 的坐标。
示例 5-2. typing_namedtuple/coordinates.py
from typing import NamedTuple
class Coordinate(NamedTuple):
lat: float
lon: float
def __str__(self):
ns = 'N' if self.lat >= 0 else 'S'
we = 'E' if self.lon >= 0 else 'W'
return f'{abs(self.lat):.1f}°{ns}, {abs(self.lon):.1f}°{we}'
警告
尽管 NamedTuple 在 class 语句中出现为超类,但实际上并非如此。typing.NamedTuple 使用元类的高级功能² 来自定义用户类的创建。看看这个:
>>> issubclass(Coordinate, typing.NamedTuple)
False
>>> issubclass(Coordinate, tuple)
True
在 typing.NamedTuple 生成的 __init__ 方法中,字段按照在 class 语句中出现的顺序作为参数出现。
像 typing.NamedTuple 一样,dataclass 装饰器支持 PEP 526 语法来声明实例属性。装饰器读取变量注解并自动生成类的方法。为了对比,可以查看使用 dataclass 装饰器编写的等效 Coordinate 类,如 示例 5-3 中所示。
示例 5-3. dataclass/coordinates.py
from dataclasses import dataclass
@dataclass(frozen=True)
class Coordinate:
lat: float
lon: float
def __str__(self):
ns = 'N' if self.lat >= 0 else 'S'
we = 'E' if self.lon >= 0 else 'W'
return f'{abs(self.lat):.1f}°{ns}, {abs(self.lon):.1f}°{we}'
请注意,示例 5-2 和 示例 5-3 中的类主体是相同的——区别在于 class 语句本身。@dataclass 装饰器不依赖于继承或元类,因此不应干扰您对这些机制的使用。³ 示例 5-3 中的 Coordinate 类是 object 的子类。
主要特点
不同的数据类构建器有很多共同点,如 表 5-1 所总结的。
表 5-1. 三种数据类构建器之间的选定特点比较;x 代表该类型数据类的一个实例
| namedtuple | NamedTuple | dataclass | |
|---|---|---|---|
| 可变实例 | 否 | 否 | 是 |
| class 语句语法 | 否 | 是 | 是 |
| 构造字典 | x._asdict() | x._asdict() | dataclasses.asdict(x) |
| 获取字段名 | x._fields | x._fields | [f.name for f in dataclasses.fields(x)] |
| 获取默认值 | x._field_defaults | x._field_defaults | [f.default for f in dataclasses.fields(x)] |
| 获取字段类型 | 不适用 | x.annotations | x.annotations |
| 使用更改创建新实例 | x._replace(…) | x._replace(…) | dataclasses.replace(x, …) |
| 运行时新类 | namedtuple(…) | NamedTuple(…) | dataclasses.make_dataclass(…) |
警告
typing.NamedTuple 和 @dataclass 构建的类具有一个 __annotations__ 属性,其中包含字段的类型提示。然而,不建议直接从 __annotations__ 中读取。相反,获取该信息的推荐最佳实践是调用 inspect.get_annotations(MyClass)(Python 3.10 中添加)或 typing.get_type_hints(MyClass)(Python 3.5 到 3.9)。这是因为这些函数提供额外的服务,如解析类型提示中的前向引用。我们将在本书的后面更详细地讨论这个问题,在 “运行时注解问题” 中。
现在让我们讨论这些主要特点。
可变实例
这些类构建器之间的一个关键区别是,collections.namedtuple 和 typing.NamedTuple 构建 tuple 的子类,因此实例是不可变的。默认情况下,@dataclass 生成可变类。但是,装饰器接受一个关键字参数 frozen—如 示例 5-3 中所示。当 frozen=True 时,如果尝试在初始化实例后为字段分配值,类将引发异常。
类语句语法
只有typing.NamedTuple和dataclass支持常规的class语句语法,这样可以更容易地向正在创建的类添加方法和文档字符串。
构造字典
这两种命名元组变体都提供了一个实例方法(._asdict),用于从数据类实例中的字段构造一个dict对象。dataclasses模块提供了一个执行此操作的函数:dataclasses.asdict。
获取字段名称和默认值
所有三种类构建器都允许您获取字段名称和可能为其配置的默认值。在命名元组类中,这些元数据位于._fields和._fields_defaults类属性中。您可以使用dataclasses模块中的fields函数从装饰的dataclass类中获取相同的元数据。它返回一个具有多个属性的Field对象的元组,包括name和default。
获取字段类型
使用typing.NamedTuple和@dataclass帮助定义的类具有字段名称到类型的映射__annotations__类属性。如前所述,使用typing.get_type_hints函数而不是直接读取__annotations__。
具有更改的新实例
给定一个命名元组实例x,调用x._replace(**kwargs)将返回一个根据给定关键字参数替换了一些属性值的新实例。dataclasses.replace(x, **kwargs)模块级函数对于dataclass装饰的类的实例也是如此。
运行时新类
尽管class语句语法更易读,但它是硬编码的。一个框架可能需要在运行时动态构建数据类。为此,您可以使用collections.namedtuple的默认函数调用语法,该语法同样受到typing.NamedTuple的支持。dataclasses模块提供了一个make_dataclass函数来实现相同的目的。
在对数据类构建器的主要特性进行概述之后,让我们依次专注于每个特性,从最简单的开始。
经典的命名元组
collections.namedtuple函数是一个工厂,构建了增强了字段名称、类名和信息性__repr__的tuple子类。使用namedtuple构建的类可以在需要元组的任何地方使用,并且实际上,Python 标准库的许多函数现在用于返回元组的地方现在返回命名元组以方便使用,而不会对用户的代码产生任何影响。
提示
由namedtuple构建的类的每个实例占用的内存量与元组相同,因为字段名称存储在类中。
示例 5-4 展示了我们如何定义一个命名元组来保存有关城市信息的示例。
示例 5-4. 定义和使用命名元组类型
>>> from collections import namedtuple
>>> City = namedtuple('City', 'name country population coordinates') # ①
>>> tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667)) # ②
>>> tokyo
City(name='Tokyo', country='JP', population=36.933, coordinates=(35.689722, 139.691667)) >>> tokyo.population # ③
36.933 >>> tokyo.coordinates
(35.689722, 139.691667) >>> tokyo[1]
'JP'
①
创建命名元组需要两个参数:一个类名和一个字段名称列表,可以作为字符串的可迭代对象或作为单个以空格分隔的字符串给出。
②
字段值必须作为单独的位置参数传递给构造函数(相反,tuple构造函数接受一个单一的可迭代对象)。
③
你可以通过名称或位置访问这些字段。
作为tuple子类,City继承了一些有用的方法,比如__eq__和用于比较运算符的特殊方法,包括__lt__,它允许对City实例的列表进行排序。
除了从元组继承的属性和方法外,命名元组还提供了一些额外的属性和方法。示例 5-5 展示了最有用的:_fields类属性,类方法_make(iterable)和_asdict()实例方法。
示例 5-5. 命名元组属性和方法(继续自上一个示例)
>>> City._fields # ①
('name', 'country', 'population', 'location') >>> Coordinate = namedtuple('Coordinate', 'lat lon')
>>> delhi_data = ('Delhi NCR', 'IN', 21.935, Coordinate(28.613889, 77.208889))
>>> delhi = City._make(delhi_data) # ②
>>> delhi._asdict() # ③
{'name': 'Delhi NCR', 'country': 'IN', 'population': 21.935, 'location': Coordinate(lat=28.613889, lon=77.208889)} >>> import json
>>> json.dumps(delhi._asdict()) # ④
'{"name": "Delhi NCR", "country": "IN", "population": 21.935, "location": [28.613889, 77.208889]}'
①
._fields 是一个包含类的字段名称的元组。
②
._make() 从可迭代对象构建 City;City(*delhi_data) 将执行相同操作。
③
._asdict() 返回从命名元组实例构建的 dict。
④
._asdict() 对于将数据序列化为 JSON 格式非常有用,例如。
警告
直到 Python 3.7,_asdict 方法返回一个 OrderedDict。自 Python 3.8 起,它返回一个简单的 dict——现在我们可以依赖键插入顺序了。如果你一定需要一个 OrderedDict,_asdict 文档建议从结果构建一个:OrderedDict(x._asdict())。
自 Python 3.7 起,namedtuple 接受 defaults 关键字参数,为类的 N 个最右字段的每个字段提供一个默认值的可迭代对象。示例 5-6 展示了如何为 reference 字段定义一个带有默认值的 Coordinate 命名元组。
示例 5-6。命名元组属性和方法,继续自示例 5-5
>>> Coordinate = namedtuple('Coordinate', 'lat lon reference', defaults=['WGS84'])
>>> Coordinate(0, 0)
Coordinate(lat=0, lon=0, reference='WGS84')
>>> Coordinate._field_defaults
{'reference': 'WGS84'}
在“类语句语法”中,我提到使用 typing.NamedTuple 和 @dataclass 支持的类语法更容易编写方法。你也可以向 namedtuple 添加方法,但这是一种 hack。如果你对 hack 不感兴趣,可以跳过下面的框。
现在让我们看看 typing.NamedTuple 的变化。
带类型的命名元组
Coordinate 类与示例 5-6 中的默认字段可以使用 typing.NamedTuple 编写,如示例 5-8 所示。
示例 5-8。typing_namedtuple/coordinates2.py
from typing import NamedTuple
class Coordinate(NamedTuple):
lat: float # ①
lon: float
reference: str = 'WGS84' # ②
①
每个实例字段都必须带有类型注释。
②
reference 实例字段带有类型和默认值的注释。
由 typing.NamedTuple 构建的类除了那些 collections.namedtuple 生成的方法和从 tuple 继承的方法外,没有任何其他方法。唯一的区别是存在 __annotations__ 类属性——Python 在运行时完全忽略它。
鉴于 typing.NamedTuple 的主要特点是类型注释,我们将在继续探索数据类构建器之前简要介绍它们。
类型提示 101
类型提示,又称类型注释,是声明函数参数、返回值、变量和属性预期类型的方式。
你需要了解的第一件事是,类型提示完全不受 Python 字节码编译器和解释器的强制执行。
注意
这是对类型提示的非常简要介绍,足以理解 typing.NamedTuple 和 @dataclass 声明中使用的注释的语法和含义。我们将在第八章中介绍函数签名的类型提示,以及在第十五章中介绍更高级的注释。在这里,我们将主要看到使用简单内置类型的提示,比如 str、int 和 float,这些类型可能是用于注释数据类字段的最常见类型。
无运行时效果
将 Python 类型提示视为“可以由 IDE 和类型检查器验证的文档”。
这是因为类型提示对 Python 程序的运行时行为没有影响。查看示例 5-9。
示例 5-9。Python 不会在运行时强制执行类型提示
>>> import typing
>>> class Coordinate(typing.NamedTuple):
... lat: float
... lon: float
...
>>> trash = Coordinate('Ni!', None)
>>> print(trash)
Coordinate(lat='Ni!', lon=None) # ①
①
我告诉过你:运行时不进行类型检查!
如果你在 Python 模块中键入示例 5-9 的代码,它将运行并显示一个无意义的 Coordinate,没有错误或警告:
$ python3 nocheck_demo.py
Coordinate(lat='Ni!', lon=None)
类型提示主要用于支持第三方类型检查器,如Mypy或PyCharm IDE内置的类型检查器。这些是静态分析工具:它们检查 Python 源代码“静止”,而不是运行代码。
要看到类型提示的效果,你必须在你的代码上运行其中一个工具—比如一个检查器。例如,这是 Mypy 对前面示例的看法:
$ mypy nocheck_demo.py
nocheck_demo.py:8: error: Argument 1 to "Coordinate" has
incompatible type "str"; expected "float"
nocheck_demo.py:8: error: Argument 2 to "Coordinate" has
incompatible type "None"; expected "float"
正如你所看到的,鉴于Coordinate的定义,Mypy 知道创建实例的两个参数必须是float类型,但对trash的赋值使用了str和None。⁵
现在让我们谈谈类型提示的语法和含义。
变量注释语法
typing.NamedTuple和@dataclass都使用在PEP 526中定义的变量注释语法。这是在class语句中定义属性的上下文中对该语法的快速介绍。
变量注释的基本语法是:
var_name: some_type
PEP 484 中的“可接受的类型提示”部分解释了什么是可接受的类型,但在定义数据类的上下文中,这些类型更有可能有用:
-
一个具体的类,例如,
str或FrenchDeck -
一个参数化的集合类型,如
list[int],tuple[str, float],等等。 -
typing.Optional,例如,Optional[str]—声明一个可以是str或None的字段
你也可以用一个值初始化变量。在typing.NamedTuple或@dataclass声明中,如果在构造函数调用中省略了相应的参数,那个值将成为该属性的默认值:
var_name: some_type = a_value
变量注释的含义
我们在“无运行时效果”中看到类型提示在运行时没有效果。但在导入时—模块加载时—Python 会读取它们以构建__annotations__字典,然后typing.NamedTuple和@dataclass会使用它们来增强类。
我们将从示例 5-10 中的一个简单类开始这个探索,这样我们以后可以看到typing.NamedTuple和@dataclass添加的额外功能。
示例 5-10. meaning/demo_plain.py:带有类型提示的普通类
class DemoPlainClass:
a: int # ①
b: float = 1.1 # ②
c = 'spam' # ③
①
a成为__annotations__中的一个条目,但在类中不会创建名为a的属性。
②
b被保存为注释,并且也成为一个具有值1.1的类属性。
③
c只是一个普通的类属性,不是一个注释。
我们可以在控制台中验证,首先读取DemoPlainClass的__annotations__,然后尝试获取其名为a、b和c的属性:
>>> from demo_plain import DemoPlainClass
>>> DemoPlainClass.__annotations__
{'a': <class 'int'>, 'b': <class 'float'>}
>>> DemoPlainClass.a
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: type object 'DemoPlainClass' has no attribute 'a'
>>> DemoPlainClass.b
1.1
>>> DemoPlainClass.c
'spam'
注意,__annotations__特殊属性是由解释器创建的,用于记录源代码中出现的类型提示—即使在一个普通类中也是如此。
a只作为一个注释存在。它不会成为一个类属性,因为没有值与它绑定。⁶ b和c作为类属性存储,因为它们绑定了值。
这三个属性都不会出现在DemoPlainClass的新实例中。如果你创建一个对象o = DemoPlainClass(),o.a会引发AttributeError,而o.b和o.c将检索具有值1.1和'spam'的类属性——这只是正常的 Python 对象行为。
检查一个typing.NamedTuple
现在让我们检查一个使用与示例 5-10 中DemoPlainClass相同属性和注释构建的类,该类使用typing.NamedTuple(示例 5-11)。
示例 5-11. meaning/demo_nt.py:使用typing.NamedTuple构建的类
import typing
class DemoNTClass(typing.NamedTuple):
a: int # ①
b: float = 1.1 # ②
c = 'spam' # ③
①
a成为一个注释,也成为一个实例属性。
②
b是另一个注释,也成为一个具有默认值1.1的实例属性。
③
c只是一个普通的类属性;没有注释会引用它。
检查DemoNTClass,我们得到:
>>> from demo_nt import DemoNTClass
>>> DemoNTClass.__annotations__
{'a': <class 'int'>, 'b': <class 'float'>}
>>> DemoNTClass.a
<_collections._tuplegetter object at 0x101f0f940>
>>> DemoNTClass.b
<_collections._tuplegetter object at 0x101f0f8b0>
>>> DemoNTClass.c
'spam'
这里我们对a和b的注释与我们在示例 5-10 中看到的相同。但是typing.NamedTuple创建了a和b类属性。c属性只是一个具有值'spam'的普通类属性。
a和b类属性是描述符,这是第二十三章中介绍的一个高级特性。现在,将它们视为类似于属性获取器的属性:这些方法不需要显式调用运算符()来检索实例属性。实际上,这意味着a和b将作为只读实例属性工作——当我们回想起DemoNTClass实例只是一种花哨的元组,而元组是不可变的时,这是有道理的。
DemoNTClass也有一个自定义的文档字符串:
>>> DemoNTClass.__doc__
'DemoNTClass(a, b)'
让我们检查DemoNTClass的一个实例:
>>> nt = DemoNTClass(8)
>>> nt.a
8
>>> nt.b
1.1
>>> nt.c
'spam'
要构造nt,我们至少需要将a参数传递给DemoNTClass。构造函数还接受一个b参数,但它有一个默认值1.1,所以是可选的。nt对象具有预期的a和b属性;它没有c属性,但 Python 会像往常一样从类中检索它。
如果尝试为nt.a、nt.b、nt.c甚至nt.z分配值,您将收到略有不同的错误消息的AttributeError异常。尝试一下并思考这些消息。
检查使用 dataclass 装饰的类
现在,我们将检查示例 5-12。
示例 5-12. meaning/demo_dc.py:使用@dataclass装饰的类
from dataclasses import dataclass
@dataclass
class DemoDataClass:
a: int # ①
b: float = 1.1 # ②
c = 'spam' # ③
①
a变成了一个注释,也是由描述符控制的实例属性。
②
b是另一个注释,也成为一个具有描述符和默认值1.1的实例属性。
③
c只是一个普通的类属性;没有注释会引用它。
现在让我们检查DemoDataClass上的__annotations__、__doc__和a、b、c属性:
>>> from demo_dc import DemoDataClass
>>> DemoDataClass.__annotations__
{'a': <class 'int'>, 'b': <class 'float'>}
>>> DemoDataClass.__doc__
'DemoDataClass(a: int, b: float = 1.1)'
>>> DemoDataClass.a
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: type object 'DemoDataClass' has no attribute 'a'
>>> DemoDataClass.b
1.1
>>> DemoDataClass.c
'spam'
__annotations__和__doc__并不奇怪。然而,在DemoDataClass中没有名为a的属性——与示例 5-11 中的DemoNTClass相反,后者具有一个描述符来从实例中获取a作为只读属性(那个神秘的<_collections._tuplegetter>)。这是因为a属性只会存在于DemoDataClass的实例中。它将是一个公共属性,我们可以获取和设置,除非类被冻结。但是b和c存在为类属性,b保存了b实例属性的默认值,而c只是一个不会绑定到实例的类属性。
现在让我们看看DemoDataClass实例的外观:
>>> dc = DemoDataClass(9)
>>> dc.a
9
>>> dc.b
1.1
>>> dc.c
'spam'
再次,a和b是实例属性,c是我们通过实例获取的类属性。
如前所述,DemoDataClass实例是可变的—并且在运行时不进行类型检查:
>>> dc.a = 10
>>> dc.b = 'oops'
我们甚至可以做更愚蠢的赋值:
>>> dc.c = 'whatever'
>>> dc.z = 'secret stash'
现在dc实例有一个c属性—但这并不会改变c类属性。我们可以添加一个新的z属性。这是正常的 Python 行为:常规实例可以有自己的属性,这些属性不会出现在类中。⁷
关于 @dataclass 的更多信息
到目前为止,我们只看到了@dataclass的简单示例。装饰器接受几个关键字参数。这是它的签名:
@dataclass(*, init=True, repr=True, eq=True, order=False,
unsafe_hash=False, frozen=False)
第一个位置的*表示剩余参数只能通过关键字传递。表格 5-2 描述了这些参数。
表格 5-2. @dataclass装饰器接受的关键字参数
| 选项 | 含义 | 默认值 | 注释 |
|---|---|---|---|
init | 生成__init__ | True | 如果用户实现了__init__,则忽略。 |
repr | 生成__repr__ | True | 如果用户实现了__repr__,则忽略。 |
eq | 生成__eq__ | True | 如果用户实现了__eq__,则忽略。 |
order | 生成__lt__、__le__、__gt__、__ge__ | False | 如果为True,则在eq=False时引发异常,或者如果定义或继承了将要生成的任何比较方法。 |
unsafe_hash | 生成__hash__ | False | 复杂的语义和几个注意事项—参见:数据类文档。 |
frozen | 使实例“不可变” | False | 实例将相对安全免受意外更改,但实际上并非不可变。^(a) |
^(a) @dataclass通过生成__setattr__和__delattr__来模拟不可变性,当用户尝试设置或删除字段时,会引发dataclass.FrozenInstanceError—AttributeError的子类。 |
默认设置实际上是最常用的常见用例的最有用设置。你更有可能从默认设置中更改的选项是:
frozen=True
防止对类实例的意外更改。
order=True
允许对数据类的实例进行排序。
鉴于 Python 对象的动态特性,一个好奇的程序员很容易绕过frozen=True提供的保护。但是在代码审查中,这些必要的技巧应该很容易被发现。
如果eq和frozen参数都为True,@dataclass会生成一个合适的__hash__方法,因此实例将是可散列的。生成的__hash__将使用所有未被单独排除的字段数据,使用我们将在“字段选项”中看到的字段选项。如果frozen=False(默认值),@dataclass将将__hash__设置为None,表示实例是不可散列的,因此覆盖了任何超类的__hash__。
PEP 557—数据类对unsafe_hash有如下说明:
虽然不建议这样做,但你可以通过
unsafe_hash=True强制数据类创建一个__hash__方法。如果你的类在逻辑上是不可变的,但仍然可以被改变,这可能是一个特殊的用例,应该仔细考虑。
我会保留unsafe_hash。如果你觉得必须使用该选项,请查看dataclasses.dataclass文档。
可以在字段级别进一步定制生成的数据类。
字段选项
我们已经看到了最基本的字段选项:使用类型提示提供(或不提供)默认值。你声明的实例字段将成为生成的__init__中的参数。Python 不允许在具有默认值的参数之后使用没有默认值的参数,因此在声明具有默认值的字段之后,所有剩余字段必须也具有默认值。
可变默认值是初学 Python 开发者常见的错误来源。在函数定义中,当函数的一个调用改变了默认值时,易变默认值很容易被破坏,从而改变了后续调用的行为——这是我们将在“可变类型作为参数默认值:不好的想法”中探讨的问题(第六章)。类属性经常被用作实例的默认属性值,包括在数据类中。@dataclass使用类型提示中的默认值生成带有默认值的参数供__init__使用。为了防止错误,@dataclass拒绝了示例 5-13 中的类定义。
示例 5-13. dataclass/club_wrong.py:这个类会引发ValueError。
@dataclass
class ClubMember:
name: str
guests: list = []
如果加载了具有ClubMember类的模块,你会得到这个:
$ python3 club_wrong.py
Traceback (most recent call last):
File "club_wrong.py", line 4, in <module>
class ClubMember:
...several lines omitted...
ValueError: mutable default <class 'list'> for field guests is not allowed:
use default_factory
ValueError消息解释了问题并建议解决方案:使用default_factory。示例 5-14 展示了如何纠正ClubMember。
示例 5-14. dataclass/club.py:这个ClubMember定义可行
from dataclasses import dataclass, field
@dataclass
class ClubMember:
name: str
guests: list = field(default_factory=list)
在示例 5-14 的guests字段中,不是使用字面列表作为默认值,而是通过调用dataclasses.field函数并使用default_factory=list来设置默认值。
default_factory参数允许你提供一个函数、类或任何其他可调用对象,每次创建数据类的实例时都会调用它以构建默认值。这样,ClubMember的每个实例都将有自己的list,而不是所有实例共享来自类的相同list,这很少是我们想要的,通常是一个错误。
警告
很好的是@dataclass拒绝了具有list默认值的字段的类定义。但是,请注意,这是一个部分解决方案,仅适用于list、dict和set。其他用作默认值的可变值不会被@dataclass标记。你需要理解问题并记住使用默认工厂来设置可变默认值。
如果你浏览dataclasses模块文档,你会看到一个用新语法定义的list字段,就像示例 5-15 中一样。
示例 5-15. dataclass/club_generic.py:这个ClubMember定义更加精确
from dataclasses import dataclass, field
@dataclass
class ClubMember:
name: str
guests: list[str] = field(default_factory=list) # ①
①
list[str]表示“一个str的列表”。
新的语法list[str]是一个参数化的泛型类型:自 Python 3.9 以来,list内置接受方括号表示法来指定列表项的类型。
警告
在 Python 3.9 之前,内置的集合不支持泛型类型表示法。作为临时解决方法,在typing模块中有相应的集合类型。如果你需要在 Python 3.8 或更早版本中使用参数化的list类型提示,你必须导入typing中的List类型并使用它:List[str]。有关此问题的更多信息,请参阅“遗留支持和已弃用的集合类型”。
我们将在第八章中介绍泛型。现在,请注意示例 5-14 和 5-15 都是正确的,Mypy 类型检查器不会对这两个类定义提出任何异议。
区别在于guests: list表示guests可以是任何类型对象的list,而guests: list[str]表示guests必须是每个项都是str的list。这将允许类型检查器在将无效项放入列表的代码中找到(一些)错误,或者从中读取项。
default_factory 很可能是field函数的最常见选项,但还有其他几个选项,列在表 5-3 中。
表 5-3. field函数接受的关键字参数
| 选项 | 含义 | 默认值 |
|---|---|---|
default | 字段的默认值 | _MISSING_TYPE^(a) |
default_factory | 用于生成默认值的 0 参数函数 | _MISSING_TYPE |
init | 在__init__参数中包含字段 | True |
repr | 在__repr__中包含字段 | True |
compare | 在比较方法__eq__、__lt__等中使用字段 | True |
hash | 在__hash__计算中包含字段 | None^(b) |
metadata | 具有用户定义数据的映射;被@dataclass忽略 | None |
^(a) dataclass._MISSING_TYPE 是一个标志值,表示未提供选项。它存在的原因是我们可以将None设置为实际的默认值,这是一个常见用例。^(b) 选项hash=None表示只有在compare=True时,该字段才会在__hash__中使用。 |
default选项的存在是因为field调用取代了字段注释中的默认值。如果要创建一个默认值为False的athlete字段,并且还要在__repr__方法中省略该字段,你可以这样写:
@dataclass
class ClubMember:
name: str
guests: list = field(default_factory=list)
athlete: bool = field(default=False, repr=False)
后初始化处理
由 @dataclass 生成的 __init__ 方法只接受传递的参数并将它们分配给实例字段的实例属性,或者如果缺少参数,则分配它们的默认值。但您可能需要做的不仅仅是这些来初始化实例。如果是这种情况,您可以提供一个 __post_init__ 方法。当存在该方法时,@dataclass 将在生成的 __init__ 中添加代码,以调用 __post_init__ 作为最后一步。
__post_init__ 的常见用例是验证和基于其他字段计算字段值。我们将学习一个简单的示例,该示例使用 __post_init__ 来实现这两个目的。
首先,让我们看看名为 HackerClubMember 的 ClubMember 子类的预期行为,如 示例 5-16 中的文档测试所描述。
示例 5-16. dataclass/hackerclub.py: HackerClubMember 的文档测试
"""
``HackerClubMember`` objects accept an optional ``handle`` argument::
>>> anna = HackerClubMember('Anna Ravenscroft', handle='AnnaRaven')
>>> anna
HackerClubMember(name='Anna Ravenscroft', guests=[], handle='AnnaRaven')
If ``handle`` is omitted, it's set to the first part of the member's name::
>>> leo = HackerClubMember('Leo Rochael')
>>> leo
HackerClubMember(name='Leo Rochael', guests=[], handle='Leo')
Members must have a unique handle. The following ``leo2`` will not be created,
because its ``handle`` would be 'Leo', which was taken by ``leo``::
>>> leo2 = HackerClubMember('Leo DaVinci')
Traceback (most recent call last):
...
ValueError: handle 'Leo' already exists.
To fix, ``leo2`` must be created with an explicit ``handle``::
>>> leo2 = HackerClubMember('Leo DaVinci', handle='Neo')
>>> leo2
HackerClubMember(name='Leo DaVinci', guests=[], handle='Neo')
"""
请注意,我们必须将 handle 作为关键字参数提供,因为 HackerClubMember 继承自 ClubMember 的 name 和 guests,并添加了 handle 字段。生成的 HackerClubMember 的文档字符串显示了构造函数调用中字段的顺序:
>>> HackerClubMember.__doc__
"HackerClubMember(name: str, guests: list = <factory>, handle: str = '')"
这里,<factory> 是指某个可调用对象将为 guests 生成默认值的简便方式(在我们的例子中,工厂是 list 类)。关键是:要提供一个 handle 但没有 guests,我们必须将 handle 作为关键字参数传递。
dataclasses 模块文档中的“继承”部分 解释了在存在多级继承时如何计算字段的顺序。
注意
在 第十四章 中,我们将讨论错误使用继承,特别是当超类不是抽象类时。创建数据类的层次结构通常不是一个好主意,但在这里,它帮助我们缩短了 示例 5-17 的长度,侧重于 handle 字段声明和 __post_init__ 验证。
示例 5-17 展示了实现方式。
示例 5-17. dataclass/hackerclub.py: HackerClubMember 的代码
from dataclasses import dataclass
from club import ClubMember
@dataclass
class HackerClubMember(ClubMember): # ①
all_handles = set() # ②
handle: str = '' # ③
def __post_init__(self):
cls = self.__class__ # ④
if self.handle == '': # ⑤
self.handle = self.name.split()[0]
if self.handle in cls.all_handles: # ⑥
msg = f'handle {self.handle!r} already exists.'
raise ValueError(msg)
cls.all_handles.add(self.handle) # ⑦
①
HackerClubMember 扩展了 ClubMember。
②
all_handles 是一个类属性。
③
handle 是一个类型为 str 的实例字段,其默认值为空字符串;这使其成为可选的。
④
获取实例的类。
⑤
如果 self.handle 是空字符串,则将其设置为 name 的第一部分。
⑥
如果 self.handle 在 cls.all_handles 中,则引发 ValueError。
⑦
将新的 handle 添加到 cls.all_handles。
示例 5-17 的功能正常,但对于静态类型检查器来说并不令人满意。接下来,我们将看到原因以及如何解决。
类型化类属性
如果我们使用 Mypy 对 示例 5-17 进行类型检查,我们会受到批评:
$ mypy hackerclub.py
hackerclub.py:37: error: Need type annotation for "all_handles"
(hint: "all_handles: Set[<type>] = ...")
Found 1 error in 1 file (checked 1 source file)
不幸的是,Mypy 提供的提示(我在审阅时使用的版本是 0.910)在 @dataclass 使用的上下文中并不有用。首先,它建议使用 Set,但我使用的是 Python 3.9,因此可以使用 set,并避免从 typing 导入 Set。更重要的是,如果我们向 all_handles 添加一个类型提示,如 set[…],@dataclass 将找到该注释,并将 all_handles 变为实例字段。我们在“检查使用 dataclass 装饰的类”中看到了这种情况。
在 PEP 526—变量注释的语法 中定义的解决方法很丑陋。为了编写带有类型提示的类变量,我们需要使用一个名为 typing.ClassVar 的伪类型,它利用泛型 [] 符号来设置变量的类型,并声明它为类属性。
为了让类型检查器和 @dataclass 满意,我们应该在 示例 5-17 中这样声明 all_handles:
all_handles: ClassVar[set[str]] = set()
那个类型提示表示:
all_handles是一个类型为set-of-str的类属性,其默认值为空set。
要编写该注释的代码,我们必须从 typing 模块导入 ClassVar。
@dataclass 装饰器不关心注释中的类型,除了两种情况之一,这就是其中之一:如果类型是 ClassVar,则不会为该属性生成实例字段。
在声明仅初始化变量时,字段类型对 @dataclass 有影响的另一种情况是我们接下来要讨论的。
不是字段的初始化变量
有时,您可能需要向 __init__ 传递不是实例字段的参数。这些参数被 dataclasses 文档 称为仅初始化变量。要声明这样的参数,dataclasses 模块提供了伪类型 InitVar,其使用与 typing.ClassVar 相同的语法。文档中给出的示例是一个数据类,其字段从数据库初始化,并且必须将数据库对象传递给构造函数。
示例 5-18 展示了说明“仅初始化变量”部分的代码。
示例 5-18. 来自 dataclasses 模块文档的示例
@dataclass
class C:
i: int
j: int = None
database: InitVar[DatabaseType] = None
def __post_init__(self, database):
if self.j is None and database is not None:
self.j = database.lookup('j')
c = C(10, database=my_database)
注意 database 属性的声明方式。InitVar 将阻止 @dataclass 将 database 视为常规字段。它不会被设置为实例属性,并且 dataclasses.fields 函数不会列出它。但是,database 将是生成的 __init__ 将接受的参数之一,并且也将传递给 __post_init__。如果您编写该方法,必须在方法签名中添加相应的参数,如示例 5-18 中所示。
这个相当长的 @dataclass 概述涵盖了最有用的功能——其中一些出现在之前的部分中,比如“主要特性”,在那里我们并行讨论了所有三个数据类构建器。dataclasses 文档 和 PEP 526—变量注释的语法 中有所有细节。
在下一节中,我将展示一个更长的示例,使用 @dataclass。
@dataclass 示例:Dublin Core 资源记录
经常使用 @dataclass 构建的类将具有比目前呈现的非常简短示例更多的字段。Dublin Core 为一个更典型的 @dataclass 示例提供了基础。
Dublin Core Schema 是一组可以用于描述数字资源(视频、图像、网页等)以及实体资源(如书籍或 CD)和艺术品等对象的词汇术语。⁸
维基百科上的 Dublin Core
标准定义了 15 个可选字段;示例 5-19 中的 Resource 类使用了其中的 8 个。
示例 5-19. dataclass/resource.py: Resource 类的代码,基于 Dublin Core 术语
from dataclasses import dataclass, field
from typing import Optional
from enum import Enum, auto
from datetime import date
class ResourceType(Enum): # ①
BOOK = auto()
EBOOK = auto()
VIDEO = auto()
@dataclass
class Resource:
"""Media resource description."""
identifier: str # ②
title: str = '<untitled>' # ③
creators: list[str] = field(default_factory=list)
date: Optional[date] = None # ④
type: ResourceType = ResourceType.BOOK # ⑤
description: str = ''
language: str = ''
subjects: list[str] = field(default_factory=list)
①
这个 Enum 将为 Resource.type 字段提供类型安全的值。
②
identifier 是唯一必需的字段。
③
title 是第一个具有默认值的字段。这迫使下面的所有字段都提供默认值。
④
date 的值可以是 datetime.date 实例,或者是 None。
⑤
type 字段的默认值是 ResourceType.BOOK。
示例 5-20 展示了一个 doctest,演示了代码中 Resource 记录的外观。
示例 5-20. dataclass/resource.py: Resource 类的代码,基于 Dublin Core 术语
>>> description = 'Improving the design of existing code'
>>> book = Resource('978-0-13-475759-9', 'Refactoring, 2nd Edition',
... ['Martin Fowler', 'Kent Beck'], date(2018, 11, 19),
... ResourceType.BOOK, description, 'EN',
... ['computer programming', 'OOP'])
>>> book # doctest: +NORMALIZE_WHITESPACE
Resource(identifier='978-0-13-475759-9', title='Refactoring, 2nd Edition',
creators=['Martin Fowler', 'Kent Beck'], date=datetime.date(2018, 11, 19),
type=<ResourceType.BOOK: 1>, description='Improving the design of existing code',
language='EN', subjects=['computer programming', 'OOP'])
由 @dataclass 生成的 __repr__ 是可以的,但我们可以使其更易读。这是我们希望从 repr(book) 得到的格式:
>>> book # doctest: +NORMALIZE_WHITESPACE
Resource(
identifier = '978-0-13-475759-9',
title = 'Refactoring, 2nd Edition',
creators = ['Martin Fowler', 'Kent Beck'],
date = datetime.date(2018, 11, 19),
type = <ResourceType.BOOK: 1>,
description = 'Improving the design of existing code',
language = 'EN',
subjects = ['computer programming', 'OOP'],
)
示例 5-21 是用于生成最后代码片段中所示格式的__repr__的代码。此示例使用dataclass.fields来获取数据类字段的名称。
示例 5-21. dataclass/resource_repr.py:在示例 5-19 中实现的Resource类中实现的__repr__方法的代码
def __repr__(self):
cls = self.__class__
cls_name = cls.__name__
indent = ' ' * 4
res = [f'{cls_name}('] # ①
for f in fields(cls): # ②
value = getattr(self, f.name) # ③
res.append(f'{indent}{f.name} = {value!r},') # ④
res.append(')') # ⑤
return '\n'.join(res) # ⑥
①
开始res列表以构建包含类名和开括号的输出字符串。
②
对于类中的每个字段f…
③
…从实例中获取命名属性。
④
附加一个缩进的行,带有字段的名称和repr(value)—这就是!r的作用。
⑤
附加闭括号。
⑥
从res构建一个多行字符串并返回它。
通过这个受到俄亥俄州都柏林灵感的例子,我们结束了对 Python 数据类构建器的介绍。
数据类很方便,但如果过度使用它们,您的项目可能会受到影响。接下来的部分将进行解释。
数据类作为代码异味
无论您是通过自己编写所有代码来实现数据类,还是利用本章描述的类构建器之一,都要意识到它可能在您的设计中信号问题。
在重构:改善现有代码设计,第 2 版(Addison-Wesley)中,Martin Fowler 和 Kent Beck 提供了一个“代码异味”目录—代码中可能表明需要重构的模式。标题为“数据类”的条目开头是这样的:
这些类具有字段、获取和设置字段的方法,除此之外什么都没有。这样的类是愚蠢的数据持有者,往往被其他类以过于详细的方式操纵。
在福勒的个人网站上,有一篇标题为“代码异味”的启发性文章。这篇文章与我们的讨论非常相关,因为他将数据类作为代码异味的一个例子,并建议如何处理。以下是完整的文章。⁹
面向对象编程的主要思想是将行为和数据放在同一个代码单元中:一个类。如果一个类被广泛使用但本身没有重要的行为,那么处理其实例的代码可能分散在整个系统的方法和函数中(甚至重复)—这是维护头痛的根源。这就是为什么福勒的重构涉及将责任带回到数据类中。
考虑到这一点,有几种常见情况下,拥有一个几乎没有行为的数据类是有意义的。
数据类作为脚手架
在这种情况下,数据类是一个初始的、简单的类实现,用于启动新项目或模块。随着时间的推移,该类应该拥有自己的方法,而不是依赖其他类的方法来操作其实例。脚手架是临时的;最终,您的自定义类可能会完全独立于您用来启动它的构建器。
Python 也用于快速问题解决和实验,然后保留脚手架是可以的。
数据类作为中间表示
数据类可用于构建即将导出到 JSON 或其他交换格式的记录,或者保存刚刚导入的数据,跨越某些系统边界。Python 的数据类构建器都提供了一个方法或函数,将实例转换为普通的dict,您总是可以调用构造函数,使用作为关键字参数扩展的**的dict。这样的dict非常接近 JSON 记录。
在这种情况下,数据类实例应被视为不可变对象—即使字段是可变的,也不应在其处于这种中间形式时更改它们。如果这样做,您将失去将数据和行为紧密结合的主要优势。当导入/导出需要更改值时,您应该实现自己的构建器方法,而不是使用给定的“作为字典”方法或标准构造函数。
现在我们改变主题,看看如何编写匹配任意类实例而不仅仅是我们在“使用序列进行模式匹配”和“使用映射进行模式匹配”中看到的序列和映射的模式。
匹配类实例
类模式旨在通过类型和—可选地—属性来匹配类实例。类模式的主题可以是任何类实例,不仅仅是数据类的实例。¹⁰
类模式有三种变体:简单、关键字和位置。我们将按照这个顺序来学习它们。
简单类模式
我们已经看到了一个简单类模式作为子模式在“使用序列进行模式匹配”中的示例:
case [str(name), _, _, (float(lat), float(lon))]:
该模式匹配一个四项序列,其中第一项必须是str的实例,最后一项必须是一个包含两个float实例的 2 元组。
类模式的语法看起来像一个构造函数调用。以下是一个类模式,匹配float值而不绑定变量(如果需要,case 体可以直接引用x):
match x:
case float():
do_something_with(x)
但这很可能是您代码中的一个错误:
match x:
case float: # DANGER!!!
do_something_with(x)
在前面的示例中,case float:匹配任何主题,因为 Python 将float视为一个变量,然后将其绑定到主题。
float(x)的简单模式语法是一个特例,仅适用于列在“类模式”部分末尾的 PEP 634—结构化模式匹配:规范中的九个受祝福的内置类型:
bytes dict float frozenset int list set str tuple
在这些类中,看起来像构造函数参数的变量—例如,在我们之前看到的序列模式中的str(name)中的x—被绑定到整个主题实例或与子模式匹配的主题部分,如示例中的str(name)所示:
case [str(name), _, _, (float(lat), float(lon))]:
如果类不是这九个受祝福的内置类型之一,那么类似参数的变量表示要与该类实例的属性进行匹配的模式。
关键字类模式
要了解如何使用关键字类模式,请考虑以下City类和示例 5-22 中的五个实例。
示例 5-22. City类和一些实例
import typing
class City(typing.NamedTuple):
continent: str
name: str
country: str
cities = [
City('Asia', 'Tokyo', 'JP'),
City('Asia', 'Delhi', 'IN'),
City('North America', 'Mexico City', 'MX'),
City('North America', 'New York', 'US'),
City('South America', 'São Paulo', 'BR'),
]
给定这些定义,以下函数将返回一个亚洲城市列表:
def match_asian_cities():
results = []
for city in cities:
match city:
case City(continent='Asia'):
results.append(city)
return results
模式City(continent='Asia')匹配任何City实例,其中continent属性值等于'Asia',而不管其他属性的值如何。
如果您想收集country属性的值,您可以编写:
def match_asian_countries():
results = []
for city in cities:
match city:
case City(continent='Asia', country=cc):
results.append(cc)
return results
模式City(continent='Asia', country=cc)匹配与之前相同的亚洲城市,但现在cc变量绑定到实例的country属性。如果模式变量也称为country,这也适用:
match city:
case City(continent='Asia', country=country):
results.append(country)
关键字类模式非常易读,并且适用于具有公共实例属性的任何类,但它们有点冗长。
位置类模式在某些情况下更方便,但它们需要主题类的显式支持,我们将在下一节中看到。
位置类模式
给定示例 5-22 中的定义,以下函数将使用位置类模式返回一个亚洲城市列表:
def match_asian_cities_pos():
results = []
for city in cities:
match city:
case City('Asia'):
results.append(city)
return results
模式City('Asia')匹配任何City实例,其中第一个属性值为'Asia',而不管其他属性的值如何。
如果您要收集country属性的值,您可以编写:
def match_asian_countries_pos():
results = []
for city in cities:
match city:
case City('Asia', _, country):
results.append(country)
return results
模式City('Asia', _, country)匹配与之前相同的城市,但现在country变量绑定到实例的第三个属性。
我提到了“第一个”或“第三个”属性,但这到底是什么意思?
使City或任何类与位置模式配合工作的是一个名为__match_args__的特殊类属性的存在,这是本章中的类构建器自动创建的。这是City类中__match_args__的值:
>>> City.__match_args__
('continent', 'name', 'country')
如您所见,__match_args__声明了属性的名称,按照它们在位置模式中使用的顺序。
在“支持位置模式匹配”中,我们将编写代码为一个我们将在没有类构建器帮助的情况下创建的类定义__match_args__。
提示
您可以在模式中组合关键字和位置参数。可能列出用于匹配的实例属性中的一些,但不是全部,可能需要在模式中除了位置参数之外还使用关键字参数。
是时候进行章节总结了。
章节总结
本章的主题是数据类构建器collections.namedtuple,typing.NamedTuple和dataclasses.dataclass。我们看到,每个都从作为工厂函数参数提供的描述生成数据类,或者从class语句中生成具有类型提示的后两者。特别是,两种命名元组变体都生成tuple子类,仅添加按名称访问字段的能力,并提供一个列出字段名称的_fields类属性,作为字符串元组。
接下来,我们并排研究了三个类构建器的主要特性,包括如何将实例数据提取为dict,如何获取字段的名称和默认值,以及如何从现有实例创建新实例。
这促使我们首次研究类型提示,特别是用于注释class语句中属性的提示,使用 Python 3.6 中引入的符号,PEP 526—变量注释语法。总体而言,类型提示最令人惊讶的方面可能是它们在运行时根本没有任何影响。Python 仍然是一种动态语言。需要外部工具,如 Mypy,利用类型信息通过对源代码的静态分析来检测错误。在对 PEP 526 中的语法进行基本概述后,我们研究了在普通类和由typing.NamedTuple和@dataclass构建的类中注释的效果。
接下来,我们介绍了@dataclass提供的最常用功能以及dataclasses.field函数的default_factory选项。我们还研究了在数据类上下文中重要的特殊伪类型提示typing.ClassVar和dataclasses.InitVar。这个主题以基于 Dublin Core Schema 的示例结束,示例说明了如何使用dataclasses.fields在自定义的__repr__中迭代Resource实例的属性。
然后,我们警告可能滥用数据类,违反面向对象编程的基本原则:数据和触及数据的函数应该在同一个类中。没有逻辑的类可能是放错逻辑的迹象。
在最后一节中,我们看到了模式匹配如何与任何类的实例一起使用,而不仅仅是本章介绍的类构建器构建的类。
进一步阅读
Python 对我们涵盖的数据类构建器的标准文档非常好,并且有相当多的小例子。
对于特别的 @dataclass,PEP 557—数据类 的大部分内容都被复制到了 dataclasses 模块文档中。但 PEP 557 还有一些非常信息丰富的部分没有被复制,包括 “为什么不只使用 namedtuple?”,“为什么不只使用 typing.NamedTuple?”,以及以这个问答结束的 “原理” 部分:
在哪些情况下不适合使用数据类?
API 兼容元组或字典是必需的。需要超出 PEPs 484 和 526 提供的类型验证,或者需要值验证或转换。
Eric V. Smith,PEP 557 “原理”
在 RealPython.com 上,Geir Arne Hjelle 写了一篇非常完整的 “Python 3.7 中数据类的终极指南”。
在 PyCon US 2018 上,Raymond Hettinger 提出了 “数据类:终结所有代码生成器的代码生成器”(视频)。
对于更多功能和高级功能,包括验证,由 Hynek Schlawack 领导的 attrs 项目 在 dataclasses 出现多年之前,并提供更多功能,承诺“通过解除您实现对象协议(也称为 dunder 方法)的繁琐工作,带回编写类的乐趣。” Eric V. Smith 在 PEP 557 中承认 attrs 对 @dataclass 的影响。这可能包括 Smith 最重要的 API 决定:使用类装饰器而不是基类和/或元类来完成工作。
Glyph——Twisted 项目的创始人——在 “每个人都需要的一个 Python 库” 中写了一篇关于 attrs 的优秀介绍。attrs 文档包括 替代方案的讨论。
书籍作者、讲师和疯狂的计算机科学家 Dave Beazley 写了 cluegen,又一个数据类生成器。如果你看过 Dave 的任何演讲,你就知道他是一个从第一原则开始元编程 Python 的大师。因此,我发现从 cluegen 的 README.md 文件中了解到鼓励他编写 Python 的 @dataclass 替代方案的具体用例,以及他提出解决问题方法的哲学,与提供工具相对立:工具可能一开始使用更快,但方法更灵活,可以带你走得更远。
将 数据类 视为代码坏味道,我找到的最好的来源是 Martin Fowler 的书 重构,第二版。这个最新版本缺少了本章前言的引语,“数据类就像孩子一样……”,但除此之外,这是 Fowler 最著名的书的最佳版本,特别适合 Python 程序员,因为示例是用现代 JavaScript 编写的,这比 Java 更接近 Python——第一版的语言。
网站 Refactoring Guru 也对 数据类代码坏味道 进行了描述。
¹ 来自《重构》,第一版,第三章,“代码中的坏味道,数据类”部分,第 87 页(Addison-Wesley)。
² 元类是 第二十四章,“类元编程” 中涵盖的主题之一。
³ 类装饰器在 第二十四章,“类元编程” 中有介绍,与元类一起。两者都是超出继承可能的方式来定制类行为。
⁴ 如果你了解 Ruby,你会知道在 Ruby 程序员中,注入方法是一种众所周知但有争议的技术。在 Python 中,这并不常见,因为它不适用于任何内置类型——str,list 等。我认为这是 Python 的一个福音。
⁵ 在类型提示的背景下,None不是NoneType的单例,而是NoneType本身的别名。当我们停下来思考时,这看起来很奇怪,但符合我们的直觉,并且使函数返回注解在返回None的常见情况下更容易阅读。
⁶ Python 没有未定义的概念,这是 JavaScript 设计中最愚蠢的错误之一。感谢 Guido!
⁷ 在__init__之后设置属性会破坏“dict 工作方式的实际后果”中提到的__dict__键共享内存优化。
⁸ 来源:都柏林核心 英文维基百科文章。
⁹ 我很幸运在 Thoughtworks 有马丁·福勒作为同事,所以只用了 20 分钟就得到了他的许可。
¹⁰ 我将这部分内容放在这里,因为这是最早关注用户定义类的章节,我认为与类一起使用模式匹配太重要,不能等到书的第二部分。我的理念是:了解如何使用类比定义类更重要。
第六章:对象引用、可变性和回收
“你很伤心,”骑士焦急地说:“让我唱首歌来安慰你。[…] 这首歌的名字叫‘鳕鱼的眼睛’。”
“哦,那就是歌的名字吗?”爱丽丝试图表现出兴趣。
“不,你没理解,”骑士说,看起来有点恼火。“那就是名字的称呼。名字真的就是‘老老老人’。”
改编自刘易斯·卡罗尔,《镜中世界》
爱丽丝和骑士设定了我们在本章中将看到的基调。主题是对象和它们的名称之间的区别。一个名称不是对象;一个名称是一个独立的东西。
我们通过提出一个关于 Python 中变量的比喻来开始本章:变量是标签,而不是盒子。如果引用变量对你来说是老生常谈,这个类比可能仍然有用,如果你需要向他人解释别名问题。
然后我们讨论对象标识、值和别名的概念。元组的一个令人惊讶的特性被揭示出来:它们是不可变的,但它们的值可能会改变。这引发了对浅复制和深复制的讨论。引用和函数参数是我们接下来的主题:可变参数默认值的问题以及如何安全处理客户端传递的可变参数。
本章的最后几节涵盖了垃圾回收、del命令以及 Python 对不可变对象玩弄的一些技巧。
这是一个相当枯燥的章节,但它的主题是许多真实 Python 程序中微妙错误的核心。
本章新内容
这里涵盖的主题非常基础和稳定。在第二版中没有值得一提的变化。
我添加了一个使用is测试哨兵对象的示例,并在“选择==还是 is”的末尾警告了is运算符的误用。
这一章曾经在本书的第四部分,但我决定将其提前,因为它作为第二部分“数据结构”的结尾要比作为“面向对象习语”的开头更好。
注意
这本书第一版中关于“弱引用”的部分现在是fluentpython.com上的一篇文章。
让我们从忘掉变量就像存储数据的盒子开始。
变量不是盒子
1997 年,我在麻省理工学院参加了一门关于 Java 的暑期课程。教授琳恩·斯坦¹指出,通常的“变量就像盒子”比喻实际上阻碍了理解面向对象语言中引用变量的理解。Python 变量就像 Java 中的引用变量;一个更好的比喻是,变量视为附加到对象的名称的标签。下一个示例和图将帮助您理解为什么。
示例 6-1 是一个简单的互动,而“变量就像盒子”这个想法无法解释。图 6-1 说明了为什么盒子的比喻对于 Python 是错误的,而便利贴提供了一个有助于理解变量实际工作方式的图像。
示例 6-1。变量a和b持有对同一列表的引用,而不是列表的副本
>>> a = [1, 2, 3] # ①
>>> b = a # ②
>>> a.append(4) # ③
>>> b # ④
[1, 2, 3, 4]
①
创建一个列表[1, 2, 3],并将变量a绑定到它。
②
将变量b绑定到与a引用相同的值。
③
通过向a引用的列表追加另一个项目来修改列表。
④
你可以通过变量b看到效果。如果我们把b看作是一个盒子,里面存放着从a盒子中复制的[1, 2, 3],这种行为就毫无意义了。
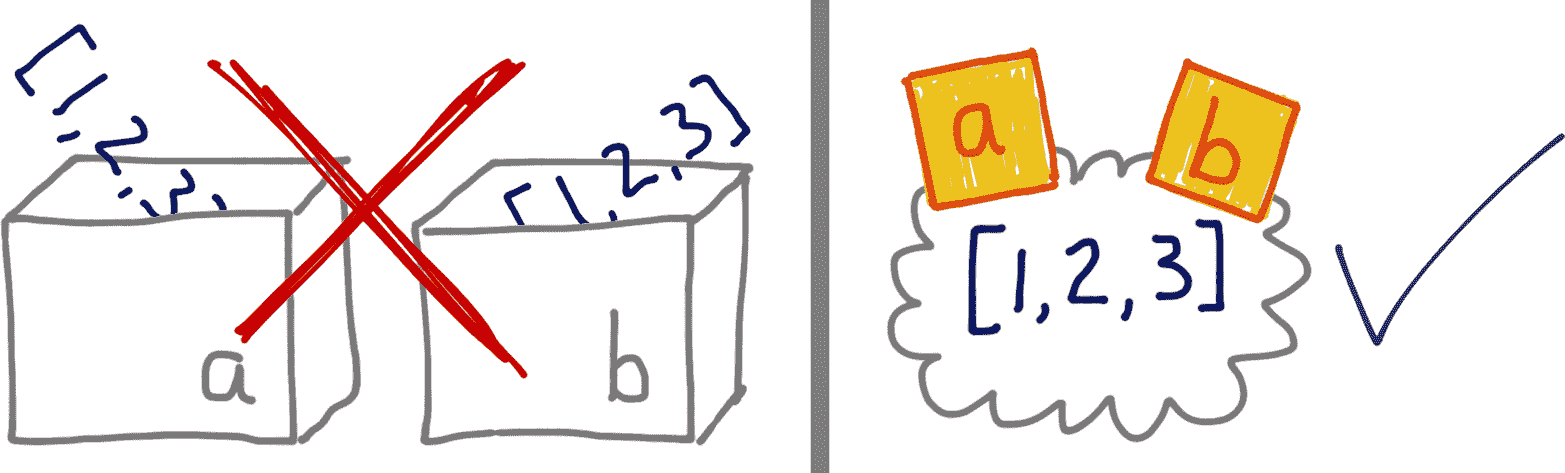
图 6-1。如果你把变量想象成箱子,就无法理解 Python 中的赋值;相反,把变量想象成便利贴,示例 6-1 就变得容易解释了。
因此,b = a语句并不会复制箱子a的内容到箱子b中。它将标签b附加到已经有标签a的对象上。
Stein 教授也非常谨慎地谈到了赋值。例如,在谈论模拟中的一个跷跷板对象时,她会说:“变量s被赋给了跷跷板”,但从不说“跷跷板被赋给了变量s”。对于引用变量,更合理的说法是变量被赋给了对象,而不是反过来。毕竟,对象在赋值之前就已经创建了。示例 6-2 证明了赋值的右侧先发生。
由于动词“赋值”被以矛盾的方式使用,一个有用的替代方法是“绑定”:Python 的赋值语句x = …将x名称绑定到右侧创建或引用的对象上。对象必须在名称绑定到它之前存在,正如示例 6-2 所证明的那样。
示例 6-2。只有在对象创建后,变量才会绑定到对象上。
>>> class Gizmo:
... def __init__(self):
... print(f'Gizmo id: {id(self)}')
...
>>> x = Gizmo()
Gizmo id: 4301489152 # ①
>>> y = Gizmo() * 10 # ②
Gizmo id: 4301489432 # ③
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for *: 'Gizmo' and 'int'
>>> >>> dir() # ④
['Gizmo', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'x']
①
输出Gizmo id: …是创建Gizmo实例的副作用。
②
乘以Gizmo实例会引发异常。
③
这里有证据表明在尝试乘法之前实际上实例化了第二个Gizmo。
④
但变量y从未被创建,因为异常发生在赋值的右侧正在被评估时。
提示
要理解 Python 中的赋值,首先阅读右侧:那里是创建或检索对象的地方。之后,左侧的变量将绑定到对象上,就像贴在上面的标签一样。只需忘记箱子。
因为变量只是标签,所以一个对象可以有多个标签分配给它。当发生这种情况时,就会出现别名,这是我们下一个主题。
身份、相等性和别名
路易斯·卡罗尔是查尔斯·卢特维奇·道奇森教授的笔名。卡罗尔先生不仅等同于道奇森教授,他们是一体的。示例 6-3 用 Python 表达了这个想法。
示例 6-3。charles和lewis指向同一个对象。
>>> charles = {'name': 'Charles L. Dodgson', 'born': 1832}
>>> lewis = charles # ①
>>> lewis is charles
True >>> id(charles), id(lewis) # ②
(4300473992, 4300473992) >>> lewis['balance'] = 950 # ③
>>> charles
{'name': 'Charles L. Dodgson', 'born': 1832, 'balance': 950}
①
lewis是charles的别名。
②
is运算符和id函数证实了这一点。
③
向lewis添加一个项目等同于向charles添加一个项目。
然而,假设有一个冒名顶替者——我们称他为亚历山大·佩达琴科博士——声称自己是查尔斯·L·道奇森,出生于 1832 年。他的证件可能相同,但佩达琴科博士不是道奇森教授。图 6-2 说明了这种情况。

图 6-2。charles和lewis绑定到同一个对象;alex绑定到一个相等值的单独对象。
示例 6-4 实现并测试了图 6-2 中所示的alex对象。
示例 6-4。alex和charles比较相等,但alex不是charles。
>>> alex = {'name': 'Charles L. Dodgson', 'born': 1832, 'balance': 950} # ①
>>> alex == charles # ②
True >>> alex is not charles # ③
True
①
alex指的是一个与分配给charles的对象相同的对象的复制品。
②
这些对象之所以相等是因为dict类中的__eq__实现。
③
但它们是不同的对象。这是写负身份比较的 Pythonic 方式:a is not b。
示例 6-3 是别名的一个例子。在那段代码中,lewis和charles是别名:两个变量绑定到同一个对象。另一方面,alex不是charles的别名:这些变量绑定到不同的对象。绑定到alex和charles的对象具有相同的值—这是==比较的内容—但它们具有不同的身份。
在Python 语言参考中,“3.1. 对象、值和类型”中指出:
一个对象的身份一旦创建就不会改变;您可以将其视为对象在内存中的地址。
is运算符比较两个对象的身份;id()函数返回表示其身份的整数。
对象的 ID 的真正含义取决于实现。在 CPython 中,id()返回对象的内存地址,但在另一个 Python 解释器中可能是其他内容。关键点是 ID 保证是唯一的整数标签,并且在对象的生命周期内永远不会更改。
在实践中,我们编程时很少使用id()函数。通常使用is运算符进行身份检查,该运算符比较对象的 ID,因此我们的代码不需要显式调用id()。接下来,我们将讨论is与==的区别。
提示
对于技术审阅员 Leonardo Rochael,最常见使用id()的情况是在调试时,当两个对象的repr()看起来相似,但您需要了解两个引用是别名还是指向不同的对象。如果引用在不同的上下文中—比如不同的堆栈帧—使用is运算符可能不可行。
选择==和is之间
==运算符比较对象的值(它们持有的数据),而is比较它们的身份。
在编程时,我们通常更关心对象的值而不是对象的身份,因此在 Python 代码中,==比is出现得更频繁。
但是,如果您要将变量与单例进行比较,则使用is是有意义的。到目前为止,最常见的情况是检查变量是否绑定到None。这是建议的做法:
x is None
而其否定的正确方式是:
x is not None
None是我们用is测试的最常见的单例。哨兵对象是我们用is测试的另一个单例的例子。以下是创建和测试哨兵对象的一种方法:
END_OF_DATA = object()
# ... many lines
def traverse(...):
# ... more lines
if node is END_OF_DATA:
return
# etc.
is运算符比==更快,因为它无法被重载,所以 Python 不必查找和调用特殊方法来评估它,计算就像比较两个整数 ID 一样简单。相反,a == b是a.__eq__(b)的语法糖。从object继承的__eq__方法比较对象 ID,因此它产生与is相同的结果。但大多数内置类型使用更有意义的实现覆盖__eq__,实际上考虑对象属性的值。相等性可能涉及大量处理—例如,比较大型集合或深层嵌套结构时。
警告
通常我们更关心对象的相等性而不是身份。检查None是is运算符的唯一常见用例。我在审查代码时看到的大多数其他用法都是错误的。如果不确定,请使用==。这通常是您想要的,并且也适用于None—尽管不如is快。
总结一下关于身份与相等性的讨论,我们会看到著名的不可变tuple并不像您期望的那样不变。
元组的相对不可变性
元组,像大多数 Python 集合(列表、字典、集合等)一样,都是容器:它们保存对对象的引用。² 如果所引用的项是可变的,即使元组本身不变,它们也可能发生变化。换句话说,元组的不可变性实际上是指tuple数据结构的物理内容(即它保存的引用),而不是扩展到所引用的对象。
示例 6-5 说明了元组的值因所引用的可变对象的更改而发生变化的情况。元组中永远不会改变的是它包含的项的标识。
示例 6-5。t1和t2最初比较相等,但在元组t1内更改可变项后,它们变得不同
>>> t1 = (1, 2, [30, 40]) # ①
>>> t2 = (1, 2, [30, 40]) # ②
>>> t1 == t2 # ③
True >>> id(t1[-1]) # ④
4302515784 >>> t1[-1].append(99) # ⑤
>>> t1
(1, 2, [30, 40, 99]) >>> id(t1[-1]) # ⑥
4302515784 >>> t1 == t2 # ⑦
False
①
t1是不可变的,但t1[-1]是可变的。
②
构建一个元组t2,其项与t1的项相等。
③
尽管是不同的对象,t1和t2比较相等,正如预期的那样。
④
检查t1[-1]列表的标识。
⑤
在原地修改t1[-1]列表。
⑥
t1[-1]的标识没有改变,只是它的值改变了。
⑦
t1和t2现在是不同的。
这种相对不可变性是谜题“A += Assignment Puzzler”背后的原因。这也是为什么一些元组是不可哈希的,正如我们在“什么是可哈希的”中所看到的。
在需要复制对象时,相等性和标识之间的区别会产生进一步的影响。副本是一个具有不同 ID 的相等对象。但是,如果一个对象包含其他对象,副本是否也应该复制内部对象,还是可以共享它们?这并没有单一的答案。继续阅读以了解讨论。
默认情况下是浅拷贝
复制列表(或大多数内置的可变集合)的最简单方法是使用类型本身的内置构造函数。例如:
>>> l1 = [3, [55, 44], (7, 8, 9)]
>>> l2 = list(l1) # ①
>>> l2
[3, [55, 44], (7, 8, 9)] >>> l2 == l1 # ②
True >>> l2 is l1 # ③
False
①
list(l1)创建了l1的一个副本。
②
这些拷贝是相等的…
③
…但是指向两个不同的对象。
对于列表和其他可变序列,使用快捷方式l2 = l1[:]也会创建一个副本。
然而,使用构造函数或[:]会产生一个浅拷贝(即,最外层容器被复制,但副本填充的是对原始容器持有的相同项的引用)。这节省内存,并且如果所有项都是不可变的,则不会出现问题。但是,如果有可变项,这可能会导致令人不快的惊喜。
在示例 6-6 中,我们创建了一个包含另一个列表和一个元组的列表的浅拷贝,然后进行更改以查看它们对所引用对象的影响。
提示
如果你手头有一台连接的电脑,我强烈推荐观看示例 6-6 的交互式动画,网址为Online Python Tutor。就我所知,直接链接到pythontutor.com上的准备好的示例并不总是可靠,但这个工具非常棒,所以抽出时间复制粘贴代码是值得的。
示例 6-6. 对包含另一个列表的列表进行浅复制;复制并粘贴此代码以在 Online Python Tutor 中查看动画
l1 = [3, [66, 55, 44], (7, 8, 9)]
l2 = list(l1) # ①
l1.append(100) # ②
l1[1].remove(55) # ③
print('l1:', l1)
print('l2:', l2)
l2[1] += [33, 22] # ④
l2[2] += (10, 11) # ⑤
print('l1:', l1)
print('l2:', l2)
①
l2是l1的浅复制。这个状态在图 6-3 中描述。
②
在l1后添加100对l2没有影响。
③
在这里我们从内部列表l1[1]中移除55。这会影响到l2,因为l2[1]与l1[1]绑定到同一个列表。
④
对于像l2[1]引用的列表这样的可变对象,运算符+=会就地修改列表。这种变化在l1[1]上可见,因为l1[1]是l2[1]的别名。
⑤
在元组上使用+=会创建一个新的元组并重新绑定变量l2[2]。这等同于执行l2[2] = l2[2] + (10, 11)。现在l1和l2中最后位置的元组不再是同一个对象。参见图 6-4。
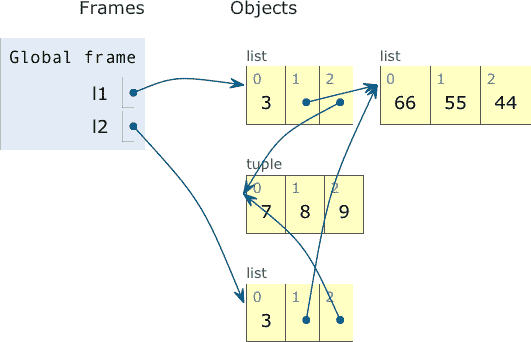
图 6-3. 在示例 6-6 中赋值l2 = list(l1)后的程序状态。l1和l2指向不同的列表,但这些列表共享对同一内部列表对象[66, 55, 44]和元组(7, 8, 9)的引用。 (图示由 Online Python Tutor 生成。)
示例 6-6 的输出是示例 6-7,对象的最终状态在图 6-4 中描述。
示例 6-7. 示例 6-6 的输出
l1: [3, [66, 44], (7, 8, 9), 100]
l2: [3, [66, 44], (7, 8, 9)]
l1: [3, [66, 44, 33, 22], (7, 8, 9), 100]
l2: [3, [66, 44, 33, 22], (7, 8, 9, 10, 11)]
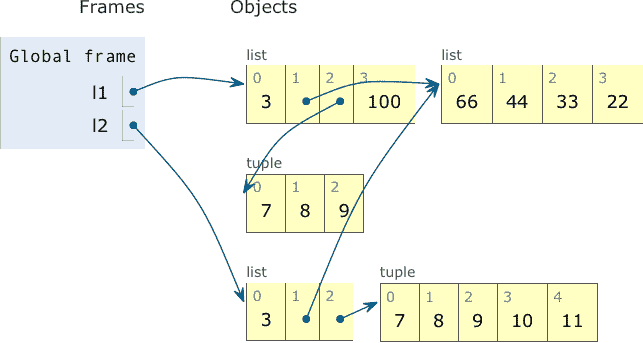
图 6-4. l1和l2的最终状态:它们仍然共享对同一列表对象的引用,现在包含[66, 44, 33, 22],但操作l2[2] += (10, 11)创建了一个新的元组,内容为(7, 8, 9, 10, 11),与l1[2]引用的元组(7, 8, 9)无关。 (图示由 Online Python Tutor 生成。)
现在应该清楚了,浅复制很容易实现,但可能并不是你想要的。如何进行深复制是我们下一个话题。
任意对象的深复制和浅复制
使用浅复制并不总是问题,但有时你需要进行深复制(即不共享嵌入对象引用的副本)。copy模块提供了deepcopy和copy函数,用于返回任意对象的深复制和浅复制。
为了说明copy()和deepcopy()的用法,示例 6-8 定义了一个简单的类Bus,代表一辆载有乘客的校车,然后在路线上接送乘客。
示例 6-8. 公共汽车接送乘客
class Bus:
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers)
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name)
现在,在交互式示例 6-9 中,我们将创建一个bus对象(bus1)和两个克隆体—一个浅复制(bus2)和一个深复制(bus3)—来观察当bus1放下一个学生时会发生什么。
示例 6-9. 使用copy和deepcopy的效果
>>> import copy
>>> bus1 = Bus(['Alice', 'Bill', 'Claire', 'David'])
>>> bus2 = copy.copy(bus1)
>>> bus3 = copy.deepcopy(bus1)
>>> id(bus1), id(bus2), id(bus3)
(4301498296, 4301499416, 4301499752) # ①
>>> bus1.drop('Bill')
>>> bus2.passengers
['Alice', 'Claire', 'David'] # ②
>>> id(bus1.passengers), id(bus2.passengers), id(bus3.passengers)
(4302658568, 4302658568, 4302657800) # ③
>>> bus3.passengers
['Alice', 'Bill', 'Claire', 'David'] # ④
①
使用copy和deepcopy,我们创建了三个不同的Bus实例。
②
在bus1删除'Bill'后,bus2也缺少了他。
③
检查passengers属性显示bus1和bus2共享相同的列表对象,因为bus2是bus1的浅拷贝。
④
bus3是bus1的深拷贝,因此其passengers属性引用另一个列表。
请注意,在一般情况下,制作深拷贝并不是一件简单的事情。对象可能具有导致天真算法陷入无限循环的循环引用。deepcopy函数记住已复制的对象,以优雅地处理循环引用。这在示例 6-10 中有演示。
示例 6-10。循环引用:b引用a,然后附加到a;deepcopy仍然成功复制a
>>> a = [10, 20]
>>> b = [a, 30]
>>> a.append(b)
>>> a
[10, 20, [[...], 30]]
>>> from copy import deepcopy
>>> c = deepcopy(a)
>>> c
[10, 20, [[...], 30]]
此外,在某些情况下,深拷贝可能太深。例如,对象可能引用不应复制的外部资源或单例。您可以通过实现__copy__()和__deepcopy__()特殊方法来控制copy和deepcopy的行为,如copy模块文档中所述。
通过别名共享对象也解释了 Python 中参数传递的工作原理,以及在参数默认值中使用可变类型的问题。接下来将介绍这些问题。
函数参数作为引用
Python 中的唯一参数传递模式是共享调用。这是大多数面向对象语言使用的模式,包括 JavaScript、Ruby 和 Java(这适用于 Java 引用类型;基本类型使用按值调用)。共享调用意味着函数的每个形式参数都会得到每个参数中引用的副本。换句话说,函数内部的参数成为实际参数的别名。
这种方案的结果是函数可以更改作为参数传递的任何可变对象,但它不能更改这些对象的标识(即,它不能完全用另一个对象替换对象)。示例 6-11 展示了一个简单函数在其中一个参数上使用+=的情况。当我们将数字、列表和元组传递给函数时,传递的实际参数会以不同的方式受到影响。
示例 6-11。一个函数可以更改它接收到的任何可变对象
>>> def f(a, b):
... a += b
... return a
...
>>> x = 1
>>> y = 2
>>> f(x, y)
3 >>> x, y # ①
(1, 2) >>> a = [1, 2]
>>> b = [3, 4]
>>> f(a, b)
[1, 2, 3, 4] >>> a, b # ②
([1, 2, 3, 4], [3, 4]) >>> t = (10, 20)
>>> u = (30, 40)
>>> f(t, u) # ③
(10, 20, 30, 40) >>> t, u
((10, 20), (30, 40))
①
数字x保持不变。
②
列表a已更改。
③
元组t保持不变。
与函数参数相关的另一个问题是在默认情况下使用可变值,如下所述。
将可变类型用作参数默认值:不好的主意
具有默认值的可选参数是 Python 函数定义的一个很好的特性,允许我们的 API 在保持向后兼容的同时发展。但是,应避免将可变对象作为参数的默认值。
为了说明这一点,在示例 6-12 中,我们从示例 6-8 中获取Bus类,并将其__init__方法更改为创建HauntedBus。在这里,我们试图聪明地避免在以前的__init__中使用passengers=None的默认值,而是使用passengers=[],从而避免了if。这种“聪明”让我们陷入了麻烦。
示例 6-12。一个简单的类来说明可变默认值的危险
class HauntedBus:
"""A bus model haunted by ghost passengers"""
def __init__(self, passengers=[]): # ①
self.passengers = passengers # ②
def pick(self, name):
self.passengers.append(name) # ③
def drop(self, name):
self.passengers.remove(name)
①
当未传递passengers参数时,此参数绑定到默认的空列表对象。
②
这个赋值使得self.passengers成为passengers的别名,而passengers本身是默认列表的别名,当没有传递passengers参数时。
③
当使用.remove()和.append()方法与self.passengers一起使用时,实际上是在改变函数对象的属性的默认列表。
示例 6-13 展示了HauntedBus的诡异行为。
示例 6-13. 被幽灵乘客缠身的公交车
>>> bus1 = HauntedBus(['Alice', 'Bill']) # ①
>>> bus1.passengers
['Alice', 'Bill'] >>> bus1.pick('Charlie')
>>> bus1.drop('Alice')
>>> bus1.passengers # ②
['Bill', 'Charlie'] >>> bus2 = HauntedBus() # ③
>>> bus2.pick('Carrie')
>>> bus2.passengers
['Carrie'] >>> bus3 = HauntedBus() # ④
>>> bus3.passengers # ⑤
['Carrie'] >>> bus3.pick('Dave')
>>> bus2.passengers # ⑥
['Carrie', 'Dave'] >>> bus2.passengers is bus3.passengers # ⑦
True >>> bus1.passengers # ⑧
['Bill', 'Charlie']
①
bus1从一个有两名乘客的列表开始。
②
到目前为止,bus1没有什么意外。
③
bus2从空开始,所以默认的空列表被分配给了self.passengers。
④
bus3也是空的,再次分配了默认列表。
⑤
默认值不再是空的!
⑥
现在被bus3选中的Dave出现在了bus2中。
⑦
问题在于bus2.passengers和bus3.passengers指向同一个列表。
⑧
但bus1.passengers是一个独立的列表。
问题在于没有初始乘客列表的HauntedBus实例最终共享同一个乘客列表。
这类 bug 可能很微妙。正如示例 6-13 所展示的,当使用乘客实例化HauntedBus时,它的表现如预期。只有当HauntedBus从空开始时才会发生奇怪的事情,因为这时self.passengers变成了passengers参数的默认值的别名。问题在于每个默认值在函数定义时被计算—即通常在模块加载时—并且默认值变成函数对象的属性。因此,如果默认值是一个可变对象,并且你对其进行更改,这种更改将影响到函数的每次未来调用。
在运行示例 6-13 中的代码后,你可以检查HauntedBus.__init__对象,并看到幽灵学生缠绕在其__defaults__属性中:
>>> dir(HauntedBus.__init__) # doctest: +ELLIPSIS
['__annotations__', '__call__', ..., '__defaults__', ...]
>>> HauntedBus.__init__.__defaults__
(['Carrie', 'Dave'],)
最后,我们可以验证bus2.passengers是绑定到HauntedBus.__init__.__defaults__属性的第一个元素的别名:
>>> HauntedBus.__init__.__defaults__[0] is bus2.passengers
True
可变默认值的问题解释了为什么None通常被用作可能接收可变值的参数的默认值。在示例 6-8 中,__init__检查passengers参数是否为None。如果是,self.passengers绑定到一个新的空列表。如果passengers不是None,正确的实现将该参数的副本绑定到self.passengers。下一节将解释为什么复制参数是一个好的实践。
使用可变参数进行防御性编程
当你编写一个接收可变参数的函数时,你应该仔细考虑调用者是否希望传递的参数被更改。
例如,如果你的函数接收一个dict并在处理过程中需要修改它,那么这种副作用是否应该在函数外部可见?实际上这取决于上下文。这实际上是对函数编写者和调用者期望的一种调整。
本章中最后一个公交车示例展示了TwilightBus如何通过与其客户共享乘客列表来打破期望。在研究实现之前,看看示例 6-14 中TwilightBus类如何从类的客户的角度工作。
示例 6-14。当被TwilightBus放下时,乘客消失了
>>> basketball_team = ['Sue', 'Tina', 'Maya', 'Diana', 'Pat'] # ①
>>> bus = TwilightBus(basketball_team) # ②
>>> bus.drop('Tina') # ③
>>> bus.drop('Pat')
>>> basketball_team # ④
['Sue', 'Maya', 'Diana']
①
basketball_team拥有五个学生名字。
②
一个TwilightBus装载着球队。
③
公交车放下一个学生,然后又一个。
④
被放下的乘客从篮球队中消失了!
TwilightBus违反了“最少惊讶原则”,这是接口设计的最佳实践。³ 当公交车放下一个学生时,他们的名字从篮球队名单中被移除,这确实令人惊讶。
示例 6-15 是TwilightBus的实现以及问题的解释。
示例 6-15。一个简单的类,展示了修改接收参数的危险性
class TwilightBus:
"""A bus model that makes passengers vanish"""
def __init__(self, passengers=None):
if passengers is None:
self.passengers = [] # ①
else:
self.passengers = passengers # ②
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name) # ③
①
当passengers为None时,我们小心地创建一个新的空列表。
②
然而,这个赋值使self.passengers成为passengers的别名,而passengers本身是传递给__init__的实际参数的别名(即示例 6-14 中的basketball_team)。
③
当使用.remove()和.append()方法与self.passengers一起使用时,实际上是在修改作为构造函数参数传递的原始列表。
这里的问题是公交车别名化了传递给构造函数的列表。相反,它应该保留自己的乘客列表。修复方法很简单:在__init__中,当提供passengers参数时,应该用其副本初始化self.passengers,就像我们在示例 6-8 中正确做的那样:
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers) # ①
①
复制passengers列表,或者如果它不是列表,则将其转换为list。
现在我们对乘客列表的内部处理不会影响用于初始化公交车的参数。作为一个额外的好处,这个解决方案更加灵活:现在传递给passengers参数的参数可以是一个tuple或任何其他可迭代对象,比如一个set甚至是数据库结果,因为list构造函数接受任何可迭代对象。当我们创建自己的列表来管理时,我们确保它支持我们在.pick()和.drop()方法中使用的必要的.remove()和.append()操作。
提示
除非一个方法明确意图修改作为参数接收的对象,否则在类中简单地将其分配给实例变量会导致别名化参数对象。如果有疑问,请复制。你的客户会更加满意。当然,复制并非免费:在 CPU 和内存方面会有成本。然而,导致微妙错误的 API 通常比稍慢或使用更多资源的 API 更大的问题。
现在让我们谈谈 Python 语句中最被误解的之一:del。
del 和 垃圾回收
对象永远不会被显式销毁;然而,当它们变得不可达时,它们可能被垃圾回收。
The Python Language Reference 中 “Data Model” 章节
del 的第一个奇怪之处在于它不是一个函数,而是一个语句。我们写 del x 而不是 del(x)—尽管后者也可以工作,但只是因为在 Python 中表达式 x 和 (x) 通常表示相同的东西。
第二个令人惊讶的事实是 del 删除的是引用,而不是对象。Python 的垃圾收集器可能会间接地将对象从内存中丢弃,作为 del 的间接结果,如果被删除的变量是对象的最后一个引用。重新绑定一个变量也可能导致对象的引用数达到零,从而导致其销毁。
>>> a = [1, 2] # ①
>>> b = a # ②
>>> del a # ③
>>> b # ④
[1, 2] >>> b = [3] # ⑤
①
创建对象 [1, 2] 并将 a 绑定到它。
②
将 b 绑定到相同的 [1, 2] 对象。
③
删除引用 a。
④
[1, 2] 没有受到影响,因为 b 仍然指向它。
⑤
将 b 重新绑定到不同的对象会移除对 [1, 2] 的最后一个引用。现在垃圾收集器可以丢弃该对象。
警告
有一个 __del__ 特殊方法,但它不会导致实例的销毁,并且不应该被您的代码调用。__del__ 在实例即将被销毁时由 Python 解释器调用,以便让它有机会释放外部资源。您很少需要在自己的代码中实现 __del__,但一些 Python 程序员却花时间编写它却没有好的理由。正确使用 __del__ 是相当棘手的。请参阅 The Python Language Reference 中 “Data Model” 章节的 __del__ 特殊方法文档。
在 CPython 中,垃圾回收的主要算法是引用计数。基本上,每个对象都会记录指向它的引用计数。一旦该 refcount 达到零,对象立即被销毁:CPython 调用对象的 __del__ 方法(如果定义了)然后释放为对象分配的内存。在 CPython 2.0 中,添加了一种分代垃圾回收算法,用于检测涉及引用循环的对象组—即使有指向它们的未解除引用,当所有相互引用都包含在组内时。Python 的其他实现具有更复杂的垃圾收集器,不依赖于引用计数,这意味着当没有更多引用指向对象时,__del__ 方法可能不会立即被调用。请参阅 A. Jesse Jiryu Davis 的 “PyPy、垃圾回收和死锁” 讨论 __del__ 的不当和适当使用。
为了演示对象生命周期的结束,示例 6-16 使用 weakref.finalize 注册一个回调函数,当对象被销毁时将被调用。
示例 6-16. 当没有更多引用指向对象时观察对象结束
>>> import weakref
>>> s1 = {1, 2, 3}
>>> s2 = s1 # ①
>>> def bye(): # ②
... print('...like tears in the rain.')
...
>>> ender = weakref.finalize(s1, bye) # ③
>>> ender.alive # ④
True >>> del s1
>>> ender.alive # ⑤
True >>> s2 = 'spam' # ⑥
...like tears in the rain. >>> ender.alive
False
①
s1 和 s2 是指向相同集合 {1, 2, 3} 的别名。
②
此函数不得是即将被销毁的对象的绑定方法或以其他方式保留对它的引用。
③
在s1引用的对象上注册bye回调。
④
在调用finalize对象之前,.alive属性为True。
⑤
正如讨论的那样,del并没有删除对象,只是删除了对它的s1引用。
⑥
重新绑定最后一个引用s2会使{1, 2, 3}变得不可访问。它被销毁,bye回调被调用,ender.alive变为False。
示例 6-16 的重点在于明确del并不会删除对象,但对象可能在使用del后变得不可访问而被删除。
你可能想知道为什么在示例 6-16 中{1, 2, 3}对象被销毁。毕竟,s1引用被传递给finalize函数,该函数必须保持对它的引用以便监视对象并调用回调。这是因为finalize持有对{1, 2, 3}的弱引用。对对象的弱引用不会增加其引用计数。因此,弱引用不会阻止目标对象被垃圾回收。弱引用在缓存应用中很有用,因为你不希望缓存的对象因为被缓存引用而保持活动状态。
注意
弱引用是一个非常专业的主题。这就是为什么我选择在第二版中跳过它。相反,我在fluentpython.com上发布了“弱引用”。
Python 对不可变对象的戏法
注意
这个可选部分讨论了一些对 Python 的用户来说并不重要的细节,可能不适用于其他 Python 实现甚至未来的 CPython 版本。尽管如此,我看到有人遇到这些边缘情况,然后开始错误地使用is运算符,所以我觉得值得一提。
令人惊讶的是,对于元组t,t[:]并不会创建一个副本,而是返回对同一对象的引用。如果写成tuple(t)也会得到对同一元组的引用。⁴ 示例 6-17 证明了这一点。
示例 6-17. 从另一个元组构建的元组实际上是完全相同的元组
>>> t1 = (1, 2, 3)
>>> t2 = tuple(t1)
>>> t2 is t1 # ①
True >>> t3 = t1[:]
>>> t3 is t1 # ②
True
①
t1和t2绑定到同一个对象。
②
t3也是如此。
相同的行为也可以观察到str、bytes和frozenset的实例。请注意,frozenset不是一个序列,因此如果fs是一个frozenset,fs[:]不起作用。但fs.copy()具有相同的效果:它欺骗性地返回对同一对象的引用,根本不是副本,正如示例 6-18 所示。⁵
示例 6-18. 字符串字面量可能创建共享对象
>>> t1 = (1, 2, 3)
>>> t3 = (1, 2, 3) # ①
>>> t3 is t1 # ②
False >>> s1 = 'ABC'
>>> s2 = 'ABC' # ③
>>> s2 is s1 # ④
True
①
从头开始创建一个新元组。
②
t1和t3相等,但不是同一个对象。
③
从头开始创建第二个str。
④
令人惊讶:a和b指向同一个str!
共享字符串字面量是一种名为内部化的优化技术。CPython 使用类似的技术来避免程序中频繁出现的数字(如 0、1、-1 等)的不必要重复。请注意,CPython 并不会对所有字符串或整数进行内部化,它用于执行此操作的标准是一个未记录的实现细节。
警告
永远不要依赖于str或int的内部化!始终使用==而不是is来比较字符串或整数的相等性。内部化是 Python 解释器内部使用的优化。
本节讨论的技巧,包括frozenset.copy()的行为,是无害的“谎言”,可以节省内存并使解释器更快。不要担心它们,它们不应该给你带来任何麻烦,因为它们只适用于不可变类型。也许这些琐事最好的用途是与其他 Python 爱好者打赌。⁶
章节总结
每个 Python 对象都有一个标识、一个类型和一个值。对象的值随时间可能会改变,只有对象的值可能会随时间改变。⁷
如果两个变量引用具有相等值的不可变对象(a == b为True),实际上很少关心它们是引用副本还是别名引用相同对象,因为不可变对象的值不会改变,只有一个例外。这个例外是不可变集合,例如元组:如果不可变集合保存对可变项的引用,那么当可变项的值发生变化时,其值实际上可能会改变。在实践中,这种情况并不常见。在不可变集合中永远不会改变的是其中对象的标识。frozenset类不会受到这个问题的影响,因为它只能保存可散列的元素,可散列对象的值根据定义永远不会改变。
变量保存引用在 Python 编程中有许多实际后果:
-
简单赋值不会创建副本。
-
使用
+=或*=进行增强赋值会在左侧变量绑定到不可变对象时创建新对象,但可能会就地修改可变对象。 -
将新值分配给现有变量不会更改先前绑定到它的对象。这被称为重新绑定:变量现在绑定到不同的对象。如果该变量是先前对象的最后一个引用,那么该对象将被垃圾回收。
-
函数参数作为别名传递,这意味着函数可能会改变作为参数接收的任何可变对象。除了制作本地副本或使用不可变对象(例如,传递元组而不是列表)外,没有其他方法可以阻止这种情况发生。
-
使用可变对象作为函数参数的默认值是危险的,因为如果参数在原地更改,则默认值也会更改,影响到依赖默认值的每个未来调用。
在 CPython 中,对象一旦引用数达到零就会被丢弃。如果它们形成具有循环引用但没有外部引用的组,它们也可能被丢弃。
在某些情况下,保留对一个对象的引用可能是有用的,这个对象本身不会保持其他对象的存活。一个例子是一个类想要跟踪其所有当前实例。这可以通过弱引用来实现,这是更有用的集合WeakValueDictionary、WeakKeyDictionary、WeakSet以及weakref模块中的finalize函数的基础机制。有关更多信息,请参阅fluentpython.com上的“弱引用”章节。
进一步阅读
Python 语言参考的“数据模型”章节以清晰的方式解释了对象的标识和值。
Wesley Chun,Core Python 系列书籍的作者,在 2011 年的 EuroPython 上做了题为Understanding Python’s Memory Model, Mutability, and Methods的演讲,不仅涵盖了本章的主题,还涉及了特殊方法的使用。
Doug Hellmann 撰写了关于“copy – Duplicate Objects”和“weakref—Garbage-Collectable References to Objects”的帖子,涵盖了我们刚讨论过的一些主题。
更多关于 CPython 分代垃圾收集器的信息可以在gc 模块文档中找到,其中以“此模块提供了一个可选垃圾收集器的接口。”开头。这里的“可选”修饰词可能令人惊讶,但“数据模型”章节也指出:
实现可以延迟垃圾收集或完全省略它——垃圾收集的实现质量如何取决于实现,只要不收集仍然可达的对象。
Pablo Galindo 在Python 开发者指南中深入探讨了 Python 的 GC 设计,针对 CPython 实现的新手和有经验的贡献者。
CPython 3.4 垃圾收集器改进了具有__del__方法的对象的处理,如PEP 442—Safe object finalization中所述。
维基百科有一篇关于string interning的文章,提到了这种技术在几种语言中的使用,包括 Python。
维基百科还有一篇关于“Haddocks’ Eyes”的文章,这是我在本章开头引用的 Lewis Carroll 的歌曲。维基百科编辑写道,这些歌词被用于逻辑和哲学作品中“阐述名称概念的符号地位:名称作为识别标记可以分配给任何东西,包括另一个名称,从而引入不同级别的符号化。”
¹ Lynn Andrea Stein 是一位屡获殊荣的计算机科学教育家,目前在奥林工程学院任教。
² 相比之下,像str、bytes和array.array这样的扁平序列不包含引用,而是直接保存它们的内容——字符、字节和数字——在连续的内存中。
³ 在英文维基百科中查看最少惊讶原则。
⁴ 这是明确记录的。在 Python 控制台中键入help(tuple)以阅读:“如果参数是一个元组,则返回值是相同的对象。”在写这本书之前,我以为我对元组了解一切。
⁵ 使copy方法不复制任何内容的无害谎言是为了接口兼容性:它使frozenset更兼容set。无论两个相同的不可变对象是相同的还是副本,对最终用户都没有影响。
⁶ 这些信息的可怕用途是在面试候选人或为“认证”考试编写问题时询问。有无数更重要和更有用的事实可用于检查 Python 知识。
⁷ 实际上,通过简单地将不同的类分配给其__class__属性,对象的类型可以更改,但这是纯粹的邪恶,我后悔写下这个脚注。

![[STM32] Keil MDK 新建工程编译不通过(warning: #2803-D和Error: L6218E)解决方法备忘](https://img-blog.csdnimg.cn/direct/bd42bb115f0746bf82a1372db0c3bd76.png#pic_center)