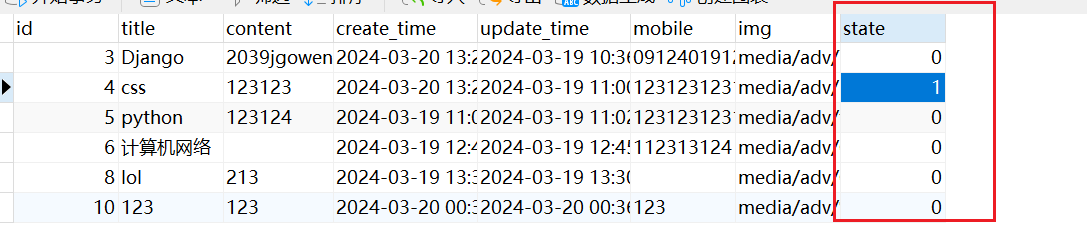
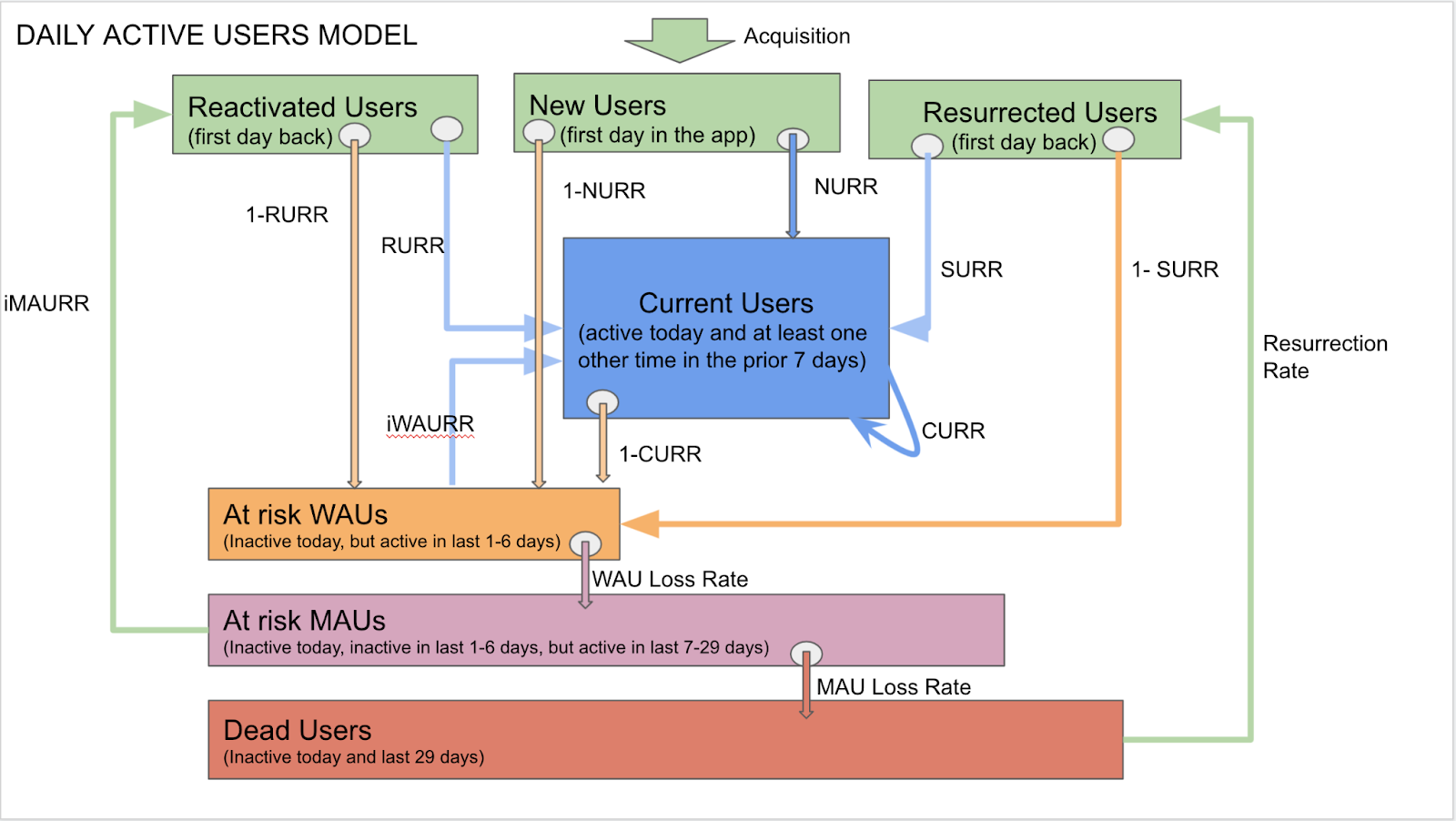
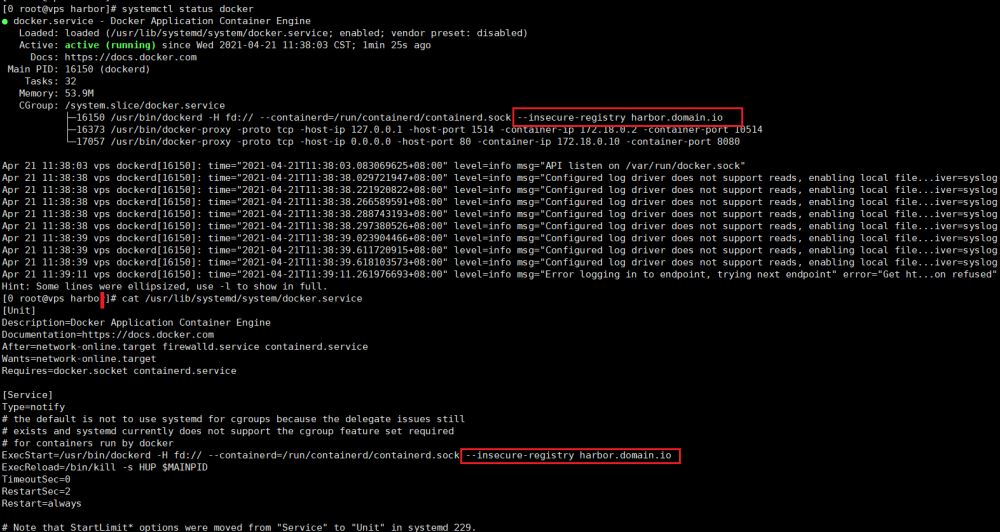
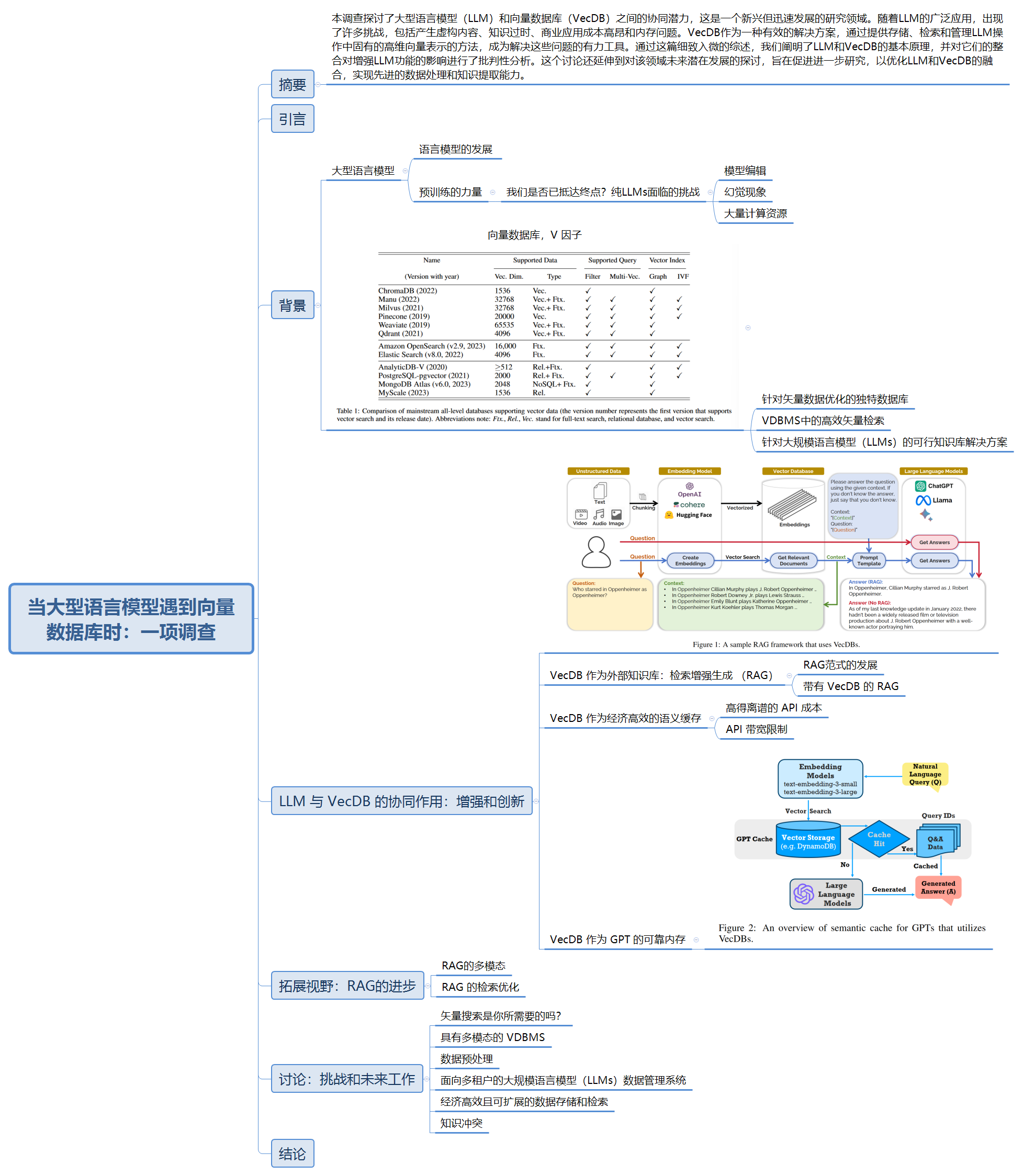
区别于C/C++中的指针,Go语言中的指针不能进行偏移和运算,是安全指针。

要搞明白Go语言中的指针概念需要先知道3个概念:指针地址,指针类型和指针取值。
一. Go语言的指针
Go语言中的函数传参都是值拷贝,当我们想修改某个变量时,我们可以创建一个指向该变量地址的指针变量。传递数据使用指针,而无须拷贝数据。类型指针不能进行偏移和运算。Go语言中的指针操作非常简单,只需要记住两个符号'*'(解引用,根据地址取值)和'&'(取地址)。
1.1 指针地址和指针类型
每个变量运行时都拥有一个地址,这个地址代表变量在内存中的位置。Go语言中使用&字符放在变量前面,对变量进行取地址操作。Go语言中的值类型(int,float,bool,string,array,struct)都有对应的指针类型,如*int,*int64,*string,*[5]int等。
指针就是地址,指针类型是一个类型,比如:*int(整型指针类型)。
取变量指针的语法:
ptr := &v
其中:
v:代表被取地址的变量,类型T
ptr:用于接收地址的变量,ptr的类型就是*T,称作T的指针类型。*代表指针。
举个例子:
package main
import "fmt"
func main() {
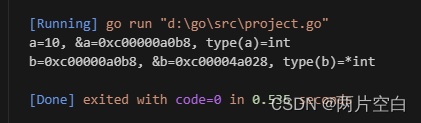
a := 10
b := &a
fmt.Printf("a=%d, &a=%p, type(a)=%T\n", a, &a, a)
fmt.Printf("b=%p, &b=%p, type(b)=%T\n", b, &b, b)
}
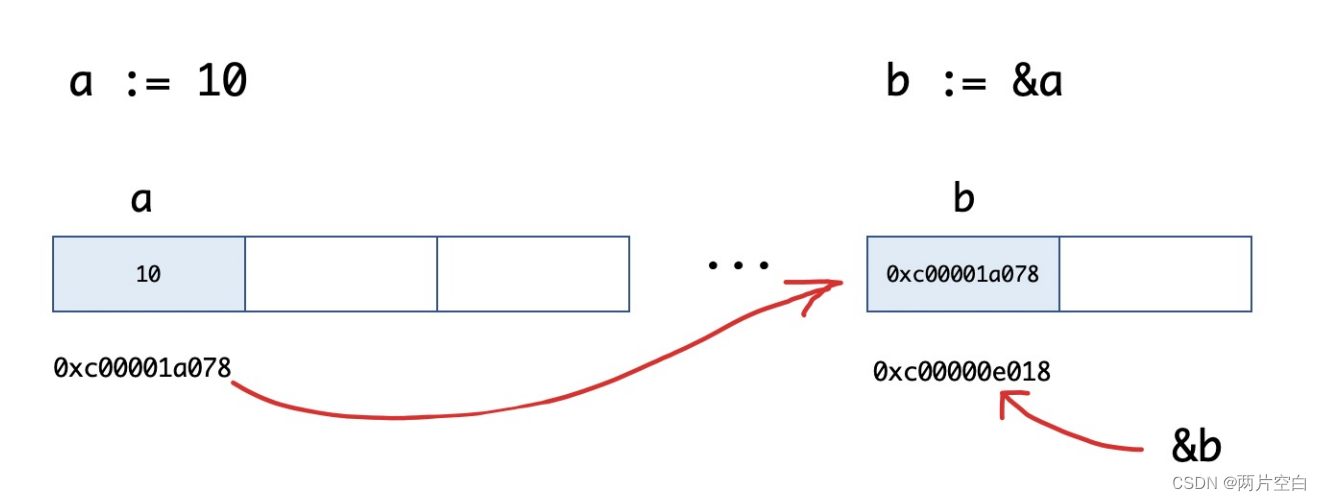
b := &a图示:
1.2 指针取值
对普通变量使用&操作符取地址后会获得这个变量的指针,然后可以对指针使用*操作,也就是指针取值。
但是数组指针不需要使用*符号,直接索引就可以取值。
package main
import "fmt"
func main() {
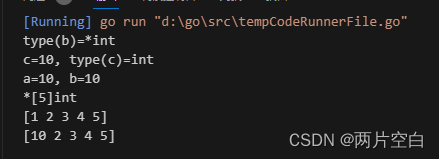
a := 10
b := &a
fmt.Printf("type(b)=%T\n", b)
c := *b
fmt.Printf("c=%d, type(c)=%T\n", c, c)
//修改值
*b = 10
fmt.Printf("a=%d, b=%d\n", a, *b)
//数组指针取值
arr := [...]int{1, 2, 3, 4, 5}
//获得指针数组
ptr := &arr
fmt.Printf("%T\n", ptr)
fmt.Println(arr)
//修改值,就是修改原数组
ptr[0] = 10
fmt.Println(arr)
}
总结:取地址操作符&和取值操作符*是一对互补操作符,&取出地址,*根据地址取出地址指向的值。
变量,指针地址,指针变量,取地址,取值的互相关系和特性如下:
- 对变量进行取地址操作(&),可以获得这个变量的指针变量。
- 指针变量的值就是指针地址。
- 对指针变量进行取值操作(*),可以获得指针变量指向原变量的值。
指针传值示例:
package main
import "fmt"
func test1(x int) {
x = 100
}
func test2(x *int) {
*x = 200
}
func main() {
x := 10
//值拷贝,没有修改实参,修改的是形参
test1(x)
fmt.Println(x)
//传入指针,修改了传入变量
test2(&x)
fmt.Println(x)
}
1.3 空指针
-
当一个指针被定义没有分配到任何变量时,它的值为nil
-
空指针判断
package main
import "fmt"
func main() {
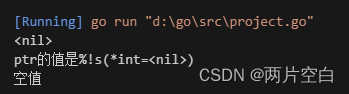
var ptr *int
fmt.Println(ptr)
fmt.Printf("ptr的值是%s\n", ptr)
if ptr == nil {
fmt.Println("空值")
} else {
fmt.Println("非空")
}
}
1.4 new和make
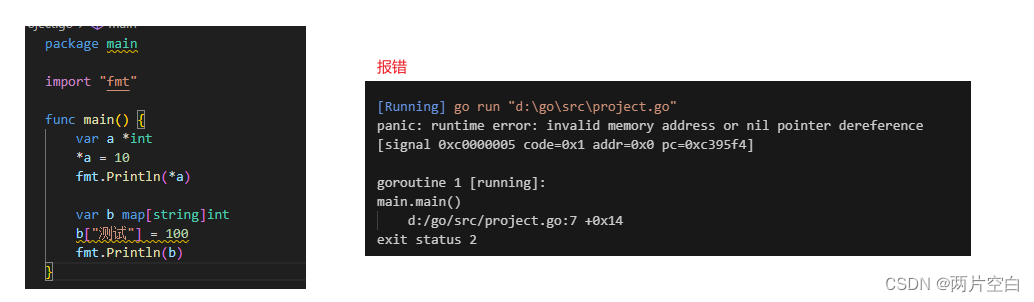
下面这个例子报panic错的原因是:在Go语言中对于引用类型的变量,我们使用的时候不仅要声明它,我们还需要为它分配内存,都在我们的值没有办法存储。而对于值类型的声明不需要分配内存空间,是因为他们在声明的时候已经默认分配好了内存空间。这时的指针相当于是一个野指针。
下面的a指针变量和b变量(map引用类型),只进行了声明(声明之后默认给初始值,指针初始值为nil,map初始值为map[]等),没有分配内存,a的值为nil,b的值为map[](map底层实际是一个指向hmap的指针,声明实际指针也是nil)。不能使用。
分配内存,需要用到Go语言内建的new和make函数。
1.4.1 new
new是一个内置函数,它的函数签名如下:
func new(Type) *Type其中:
- Type表示类型,new函数只接受一个参数,这个参数是一个类型。
- *Type表示类型指针,new函数返回一个指向该类型内存地址的指针。
new函数不太常用,使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的默认值。举个例子:
package main
import "fmt"
func main() {
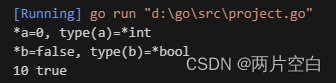
a := new(int)
b := new(bool)
//默认值
fmt.Printf("*a=%d, type(a)=%T\n", *a, a)
fmt.Printf("*b=%v, type(b)=%T\n", *b, b)
*a = 10
*b = true
fmt.Println(*a, *b)
}
上面报错的例子中,由于var a *int只是声明没有初始化分配内存,是一个野指针,不能使用。初始化需要使用new函数 var a *int = new(int),之后才能使用。
1.4.2 make
make也是用来内存分配的,区别于new,它只用于slice,map以及chan(管道)的内存创建,而它返回的类型就是这三个类型本身,而不是他们的指针类型。因为这三个类型都是引用类型,所以就没有必要返回指针类型。
函数签名:
func make(t Type, size ...IntegerType) Type其中:
- t Type表示类型。
- size ...IntegerType:是一个可变参数,int类型,可以传多个值,一般传入类型大小。
- 返回值类型Type,不是指针,直接是引用类型。
make函数是无可替代的,我们在使用slice,map以及channel的时候,都需要使用make进行初始化,然后才可以对他们进行操作。
上面例子中的var b map[string]int只是声明了变量b是一个map类型的变量,需要像下面的示例代码一样使用make函数进行初始化操作之后,才能对其进行赋值:
package main
import "fmt"
func main() {
var b map[string]int = make(map[string]int, 10)
b["测试"] = 100
fmt.Println(b)
}
1.4.3 make和new的区别
-
二者都是用来做内存分配的。
-
make只用于slice,map和channel引用类型的初始化,返回的还是这三个引用类型本身。
-
而new用于类型的内存分配,并且内存对应的值为类型的默认值,返回的是指向类型的指针。
1.5 多级指针
在Go语言中也存在多级指针。指针变量在内存中也需要保存,也有地址,多级指针实际就是保存指针变量的地址。
package main
import "fmt"
func main() {
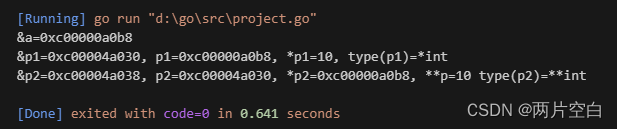
a := 10
fmt.Printf("&a=%p\n", &a)
//p1保存a的地址,*p1<=>a
p1 := &a
fmt.Printf("&p1=%p, p1=%p, *p1=%d, type(p1)=%T\n", &p1, p1, *p1, p1)
//p2保存p1的地址 *p2为p1的值即a的地址,**p2<=>*p1<=>a
p2 := &p1
fmt.Printf("&p2=%p, p2=%p, *p2=%p, **p=%d type(p2)=%T\n", &p2, p2, *p2, **p2, p2)
}
二.内存逃逸
查看内存逃逸信息命令:
go build -gcflags "-m" project.go
go run -gcflags "-m -l" project.go
参数:
-m:打印逃逸信息
-l:禁止内联编译2.1 现象
- make,new和函数内部的变量保存在哪里?
make和new出来的变量保存在堆上。
而函数内部定义的变量需要通过逃逸分析来决定保存位置。
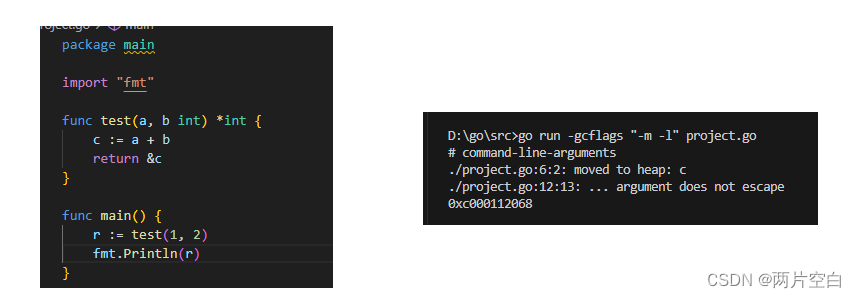
现象:通过内存逃逸命令我们可以看到变量c被保存到了堆上。
原因:由于test()函数返回指针变量(&c),Go编译器认为外部还会使用到变量c,如果将其回收,返回的指针就变成了野指针,获取不到对应值了。于是将其分配到了堆上。这个操作时Go编译器做的。
对比C/C++,将变量分配到堆上的操作需要程序员来做,否则变量被回收,返回的指针编程了野指针。
2.1 逃逸分析定义
Go语言的逃逸分析是指:Go编译器用来决定变量存储位置的过程。
2.2 逃逸分析标准
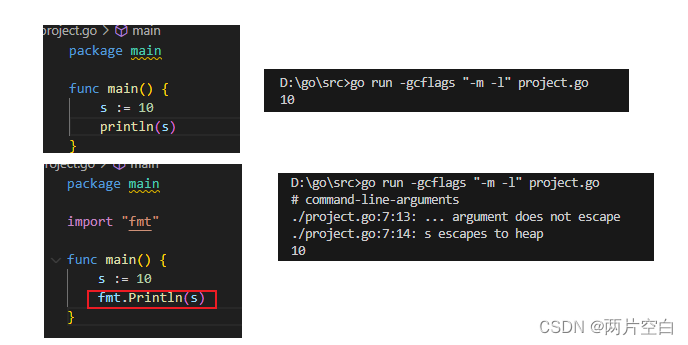
- 如果一个变量只在函数内部使用,并且没有其他引用,那么它通常会被分配到栈上。
- 如果变量在函数返回后仍然被引用,会造成逃逸
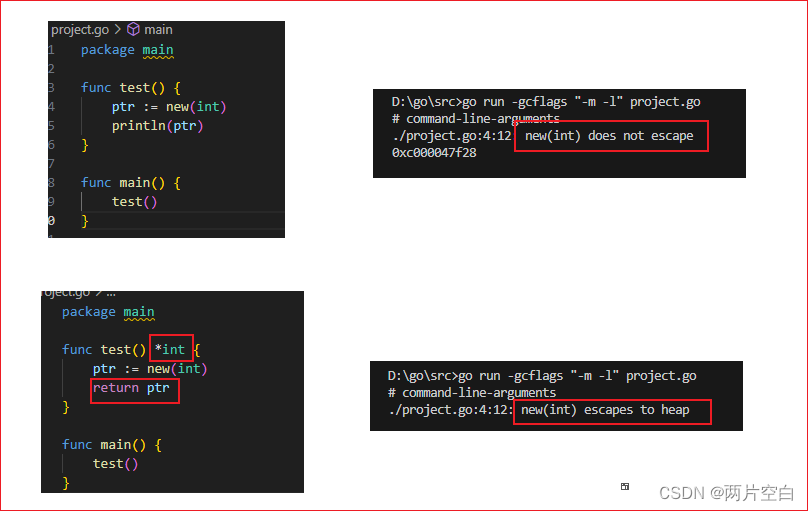
- 栈空间不足,会造成逃逸
- 动态类型逃逸,不确定变量类型
当函数参数为"interface{}"类型,如最常用的fmt.Println(a ...interface{}),编译期间很难确定其参数的具体类型,也会发生逃逸。
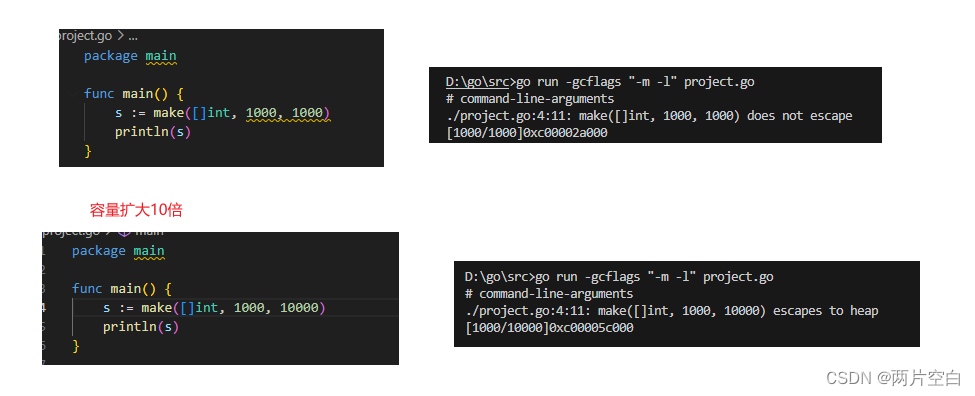
- 不确定长度大小,会发生逃逸
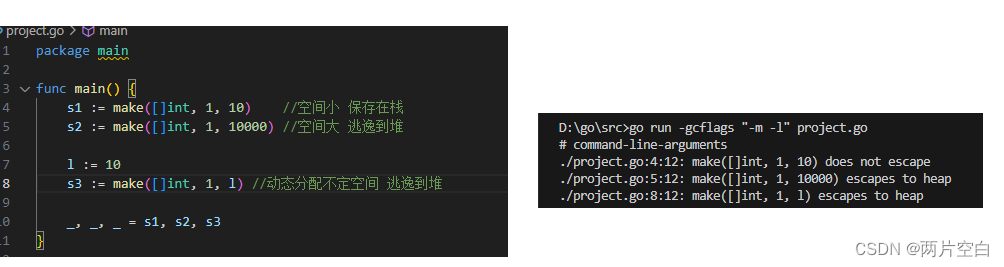
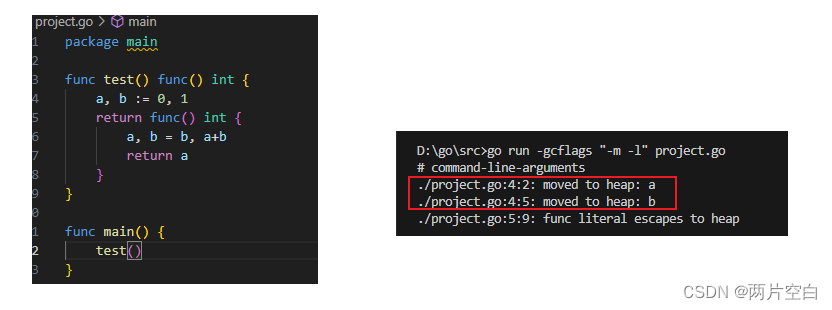
- 闭包引用对象发生逃逸
2.3 总结
-
逃逸分析在编译阶段完成
-
逃逸分析目的是决定内分配地址是栈还是堆
-
栈上分配内存比在堆中分配内存有更高的效率
-
栈上分配的内存不需要GC处理,堆上分配的内存使用完毕会交给GC处理
在实际中,应该尽量避免逃逸。栈中的变量不需要gc回收。同时栈的分配比堆快,性能好。
另外,还可以进行同步消除,如果定义的对象的方法上有同步锁,但在运行时却只有一个线程在访问,此时逃逸分析后的机器码会去掉同步锁运行
三.引用类型和指针类型区别
引用类型和指针类型是两个不同的类型。与C++中的引用相似,但也有很多不同的地方。
区别:
- 从定义上
引用类型包括slice,map,channel,interface等,它们实际是对底层数据结构的抽象,通过这些类型可以直接操作底层数据结构的元素。
指针是一个保存变量地址的变量,它指向变量在内存中的位置。
- 从传递方式上
引用类型在函数调用时使用的是引用传递,函数在内部修改参数,会影响实际参数的值,可以直接使用。
指针类型虽然说也是引用传递,但由于他是间接访问,在函数内部对指针进行修改不会修改实际参数值,而需要进行解引用。
- 从性质上
引用类型是原变量的别名,没有自己独立的空间。
指针类型的变量是一个实体,保存另一个变量的地址。但是Go语言中的指针不能进行运算。
指针有多级指针
引用没有多级引用。