🌻个人主页:相洋同学
🥇学习在于行动、总结和坚持,共勉!
目录
01 回顾
02 RNN神经网络原理
03 RNN神经网络实现
04 RNN神经网络实验
RNN的特别结构使得RNN具备了短期记忆能力,使其能够学习部分语义信息。
01 回顾
RNN的特别结构使得RNN具备了短期记忆能力,使其能够学习部分语义信息。
我们回顾一下网络结构的全连接层,又称线性层,计算公式:y=w*x + b
w和b是参与训练的参数,w的维度决定了隐含层输出的维度
参考我之前的文章:【深度学习】手动实现全连接神经网络(FCNN)-CSDN博客

02 RNN神经网络原理
时序相关问题:要处理的任务是有一个序列的,后一步可能受到前一步的影响,NLP问题是天然的时序问题
RNN主要思想:将整个序列划分成多个时间步,将每一个时间步的信息依次输入模型,同时将模型输出的结果传给下一个时间步
从数学上实现方式:
我们首先来观察一下样本,假设我们每个样本是一句话,一句话由若干字组成

如果使用传统池化方法,对相应维度做加和求平均。我们就丧失了语义信息:I am a cat 和 cat am a I似乎就没有了区别

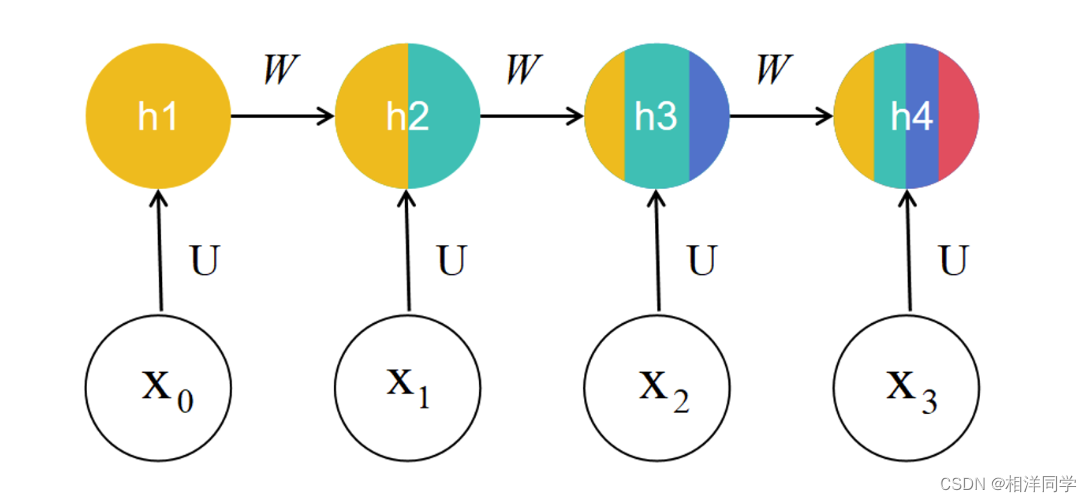
RNN的优势这个时候就凸显了出来,RNN就是将样本进行了多个时间步的处理,后一个时间步等于前一个时间步信息做线性变换,参数为W,再加上当前U与xt的乘积,这样我们既存储了当前时间步信息,也继承了前面时间步的信息。

03 RNN神经网络实现
我们首先用pytorch来实现RNN网络的,而后通过自己构造的RNN,对我们构造的RNN网络进行验证
# 使用torch创建RNN层,不进行训练,记录初始化的参数w_ih,w_hh
import torch
import torch.nn as nn
import numpy as np
class TorchRNN(nn.Module):
def __init__(self,input_size,hidden_size):
super(TorchRNN,self).__init__()
self.layer = nn.RNN(input_size,hidden_size,bias=False,batch_first=True)
def forward(self,x):
return self.layer(x)
x = np.array([[1, 2, 3, 4],
[3, 4, 5, 6],
[5, 6, 7, 8],
[7, 8, 9, 10]]) #网络输入
#torch实验
hidden_size = 5
torch_model = TorchRNN(4, hidden_size)
# print(torch_model.state_dict())
w_ih = torch_model.state_dict()["layer.weight_ih_l0"] # w_ih就是U
w_hh = torch_model.state_dict()["layer.weight_hh_l0"] # w_hh就是W
我们自己再构造一个RNN
class MyRNN:
def __init__(self,w_ih,w_hh,hidden_size):
self.w_ih = w_ih
self.w_hh = w_hh
self.hidden_size = hidden_size
def forward(self,x):
ht = np.zeros((self.hidden_size))
output = []
for xt in x:
ux = np.dot(xt,self.w_ih.T) # xt维度:1*4,w_ih.T维度:4*5,ux维度:4*5
wh = np.dot(ht,self.w_hh.T) # ht维度:1*5,w_hh.T维度:5*5
ht_next = np.tanh(ux+wh) # 维度:4*5
output.append(ht_next)
ht = ht_next
return np.array(output),ht
x = np.array([[1, 2, 3, 4],
[3, 4, 5, 6],
[5, 6, 7, 8],
[7, 8, 9, 10]]) #网络输入
最后预测输出,对比结果:
torch_x = torch.FloatTensor([x])
output, h = torch_model.forward(torch_x)
print(h)
print(output.detach().numpy(), "torch模型预测结果")
print(h.detach().numpy(), "torch模型预测隐含层结果")
print("---------------")
diy_model = MyRNN(w_ih, w_hh, hidden_size)
output, h = diy_model.forward(x)
print(output, "diy模型预测结果")
print(h, "diy模型预测隐含层结果")
==========================
[[[ 0.9770124 -0.98210144 -0.898459 0.43363687 -0.7096077 ]
[ 0.99852514 -0.9999082 -0.97600037 0.87200433 -0.49491423]
[ 0.999937 -0.9999985 -0.9864487 0.9611373 -0.592286 ]
[ 0.99999815 -1. -0.99189234 0.98961574 -0.72276914]]] torch模型预测结果
[[[ 0.99999815 -1. -0.99189234 0.98961574 -0.72276914]]] torch模型预测隐含层结果
---------------
[[ 0.97701239 -0.98210147 -0.89845902 0.43363689 -0.70960771]
[ 0.99852516 -0.9999082 -0.97600034 0.87200431 -0.49491426]
[ 0.99993697 -0.9999985 -0.98644868 0.96113729 -0.59228603]
[ 0.99999817 -0.99999997 -0.99189236 0.98961571 -0.72276908]] diy模型预测结果
[ 0.99999817 -0.99999997 -0.99189236 0.98961571 -0.72276908] diy模型预测隐含层结果
我们可以看到相差不大,第一个矩阵中是所有时间步的结果,最后隐含层的结果就是最后一个时间步的结果
04 RNN神经网络实验
我们再构造一个任务:预测字母a出现的位置
import torch
import torch.nn as nn
import numpy as np
import random
import json
import matplotlib.pyplot as plt
"""
基于pytorth的网络编写
实现一个网络完成一个简单nlp任务
判断文本中是否有某些特定字符出现
"""
class TorchModel(nn.Module):
def __init__(self, vector_dim, sentence_length, vocab,hidden_dim,output_dim):
super(TorchModel, self).__init__()
self.embedding = nn.Embedding(len(vocab), vector_dim) #embedding层
self.rnn = nn.RNN(vector_dim, hidden_dim,batch_first=True) #线性层 hidden_dim是隐藏层维度,最好与vector_dim相同或者是它的倍数
self.classify = nn.Linear(hidden_dim, output_dim) # 线性层,将RNN的输出维度转化为最终输出维度
self.loss = nn.CrossEntropyLoss() #loss函数采用均方差损失
# 当输入真实标签,返回loss值,无真实标签,返回预测值
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #(batch_size, sen_len) -> (batch_size, sen_len, vector_dim)
x,_ = self.rnn(x) # (batch_size, sen_len, vector_dim) -> (batch_size, sen_len, hidden_dim)
# 取rnn最后一个时间步的输出
x = x[:, -1, :]
y_pred = self.classify(x) #(batch_size, vector_dim) -> (batch_size, 1) 3*5 5*1 -> 3*1
#(batch_size, 1) -> (batch_size, 1)
if y is not None:
return self.loss(y_pred, y) #预测值和真实值计算损失
else:
return y_pred #输出预测结果
#字符集随便挑了一些字,实际上还可以扩充
#为每个字生成一个标号
#{"a":1, "b":2, "c":3...}
#abc -> [1,2,3]
def build_vocab():
chars = "abcdefghij" #字符集
vocab = {"pad":0}
for index, char in enumerate(chars):
vocab[char] = index+1 #每个字对应一个序号
vocab['unk'] = len(vocab) #26
return vocab
def build_sample(vocab, sentence_length):
# 随机选择除'a'外的其他字符,总数为sentence_length-1
remaining_keys = list(vocab.keys())
remaining_keys.remove('a') # 移除'a',避免重复选择
x = random.sample(remaining_keys, sentence_length - 1)
x.append('a') # 确保'a'被包含在样本中
random.shuffle(x) # 打乱列表,使'a'的位置随机
# 计算'a'的位置
y = x.index('a')
# 将字符转换为索引
x = [vocab[word] for word in x]
return x, y
# 建立数据集
# 建立需要的样本数量。需要多少生成多少
def build_dataset(sample_length,vocab,sentence_length):
dataset_x = []
dataset_y = []
for i in range(sample_length):
x,y = build_sample(vocab,sentence_length)
dataset_x.append(x)
dataset_y.append(y)
# 如果在处理数据集上出了问题,那就会功亏一篑
return torch.LongTensor(dataset_x),torch.LongTensor(dataset_y)
# 建立模型
def build_model(vector_dim, sentence_length, vocab,hidden_dim,output_dim):
model = TorchModel(vector_dim, sentence_length, vocab,hidden_dim,output_dim)
return model
# 测试代码
def evaluate(model, vocab, sentence_length):
model.eval() # 将模型设置为评估模式
test_sample_num = 200
x, y = build_dataset(test_sample_num, vocab, sentence_length)
correct = 0 # 记录正确预测的数量
with torch.no_grad(): # 不计算梯度
y_pred = model(x) # 模型预测
_, predicted_labels = torch.max(y_pred, 1) # 获取最大概率的索引,即预测的类别
correct += (predicted_labels == y).sum().item() # 计算正确预测的数量
print(f'本次测试集预测准确率为{correct / test_sample_num}')
return correct / test_sample_num
def main():
epoch_num = 20 # 训练轮数
batch_size = 2 # 每轮训练样本数
train_sample = 50 # 每轮训练的样本总数
char_dim = 20 # 每个字的维度
sentence_length = 5 # 样本文本长度
learning_rate = 0.01 # 学习率
hidden_dim = 10
output_dim = 5
vocab = build_vocab()
# 建立模型
model = build_model(char_dim, sentence_length, vocab,hidden_dim,output_dim)
# 选择优化器
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)
log = []
x,y = build_dataset(train_sample,vocab,sentence_length)
# 训练过程
for epoch in range(epoch_num):
model.train()
watch_loss = []
for batch_index in range(train_sample//batch_size):
x_train = x[batch_index*batch_size:(batch_index+1)*batch_size]
y_train = y[batch_index*batch_size:(batch_index+1)*batch_size]
optimizer.zero_grad()
loss = model(x_train,y_train)
loss.backward()
optimizer.step()
watch_loss.append(loss.item())
print(f'===========第{epoch+1}轮训练结果,平均loss:{np.mean(watch_loss)}============')
acc = evaluate(model,vocab,sentence_length)
log.append([acc,float(np.mean(watch_loss))])
# 保存模型
torch.save(model.state_dict(),'nlpmodel.pth')
# 保存词表
writer = open("vocab.json", "w", encoding="utf8")
writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))
writer.close()
# 画图:
plt.plot(range(1,epoch_num+1),[i[0] for i in log],label='acc')
plt.plot(range(1,epoch_num+1),[i[1] for i in log],label='loss')
plt.legend()
plt.show()
return
def predicr(model_path,vocab_path,input_strings): # 加载模型
char_dim = 20
sentence_length = 5
hidden_dim = 10
output_dim = 5
vocab = json.load(open(vocab_path,'r',encoding='utf-8')) # 加载字符表
model = build_model(char_dim, sentence_length, vocab,hidden_dim,output_dim)
model.load_state_dict(torch.load(model_path))
x = []
for i in input_strings:
x.append([vocab[j] for j in i]) # 将输入文本序列化
model.eval() # 测试模式
with torch.no_grad():
result = model(torch.LongTensor(x))
_, predicted_positions = torch.max(result, dim=1) # 获取每个样本最大概率的位置
for i, pred_pos in enumerate(predicted_positions):
print(f'输入:{input_strings[i]},预测位置:{pred_pos.item()}') # 打印每个输入字符串的预测位置
if __name__ == '__main__':
main()
test_strings = ["abcde", "bacdf", "aebdc",]
predicr("nlpmodel.pth", "vocab.json", test_strings)
可视化
仅仅20轮,模型准确率就达到了1

以上
互联网是最好的课本,实践是最好的老师,AI是最好的学习助手
行动起来,共勉