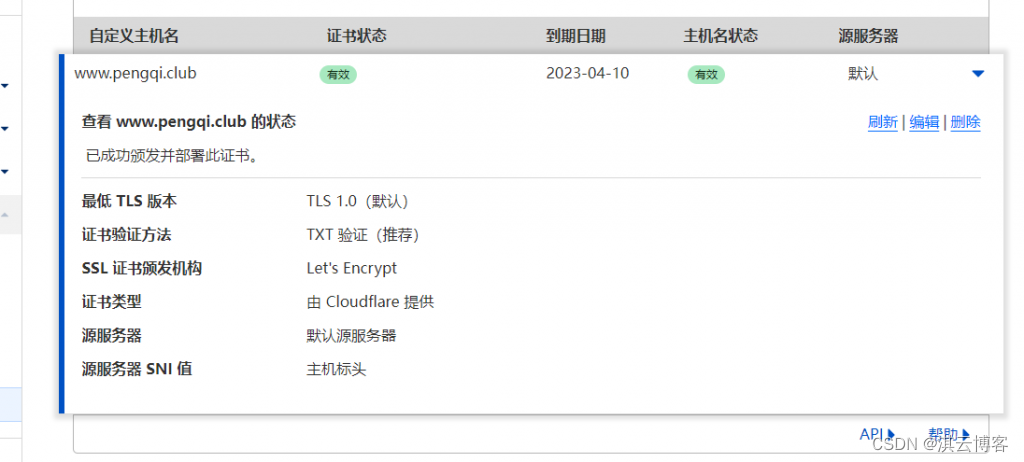
目录
背景介绍
网站分析
第1步:找到网页源代码
第2步:分析网页源代码
Python 实现
成果展示
后续 Todo
背景介绍
今天这篇文章,3个目的,1个是自己记录,1个是给大家分享,还有1个是向这个被爬网站的前端程序员致敬 —— 就是最近花了不少时间和精力研究,然后终于有所突破的1个Python 爬虫案例。
背景呢是我在B站上找了1个 讲 Scrapy 爬虫框架的视频,就跟着敲代码,跟着他在学。学的过程中就遇到他讲到1个案例 - 爬 aqistudy 这个天气网站的历史数据,他这个视频上传时间是2022年3月,但实际是2019年录制的,反正从他录的视频看,2019年时候这个网站还是很“正常”的。这里的“正常” 是带引号的正常哈,当时虽然也是异步请求页面数据,但是他可以右键,可以F12啥的,然后就是在 Scrapy 的中间件里调用 Selenium 模拟了下页面渲染,就能拿到数据了。
但是但是,各位,现在是2013年了,我打开这个网站一看,简直是天翻地覆,改得程序员他妈都不认识了,2019年那套东西,完全用不了了。可是这又激发了我的兴趣,我们一向是逢山开路遇水架桥,有问题就要解决的,而且正好最近失业赋闲,有大把的时间,那怎么办?搞他!
正式开始前还想交代下,我研究这个就是因为好奇和好玩,面向问题遇到问题解决问题。我不是前端程序员,对于我来说更重要的是搞清楚逻辑,不是具体实现。所以有些地方的解读可能会存在偏差,请大家见谅。
网站分析
闲话不多说,先直接来看下这个网站。他的数据实际是按照城市,然后每个城市的月份,再然后每个月份的每一天这样来组织的。我们的目的,是想拿到这个网站上提供的所有城市的天维度的历史数据 —— 野心勃勃,动机不良,入门还是入狱,请谨慎操作!!!!

爬虫么,正常思路就是先看网页源代码有没有提供数据,没有的话就找Ajax请求,我们就照着这个思路往下走。
城市列表页面,相对简单,右键查看源代码,可以根据xpath 匹配得到城市名称,以及城市对应的url。这里推荐1个Chrome 插件:xpath helper ,很快很好用。

月数据页面我们不关心,来看日维度的数据页面。天啊,这是什么,非法调试,右键被禁用?F12被禁用? —— 最开始搞到这儿,我是又惊又喜,惊的是 WTF 这怎么搞,喜的是不错哦,有点儿意思 。

第1步:找到网页源代码
然后接下来我就开始各种搜索,怎么破这个限制。有人说Ctrl + shift + i的,有人说 更多工具 -> 开发者工具的,我一试:牛逼,如图 —— 来到了传说中的“无限Debugger” —— 总之就是你按照这样的形式(注意这个定语)样打开开发者工具,他就让你一直在这里循环,页面不会加载,更不会发出什么ajax 请求。
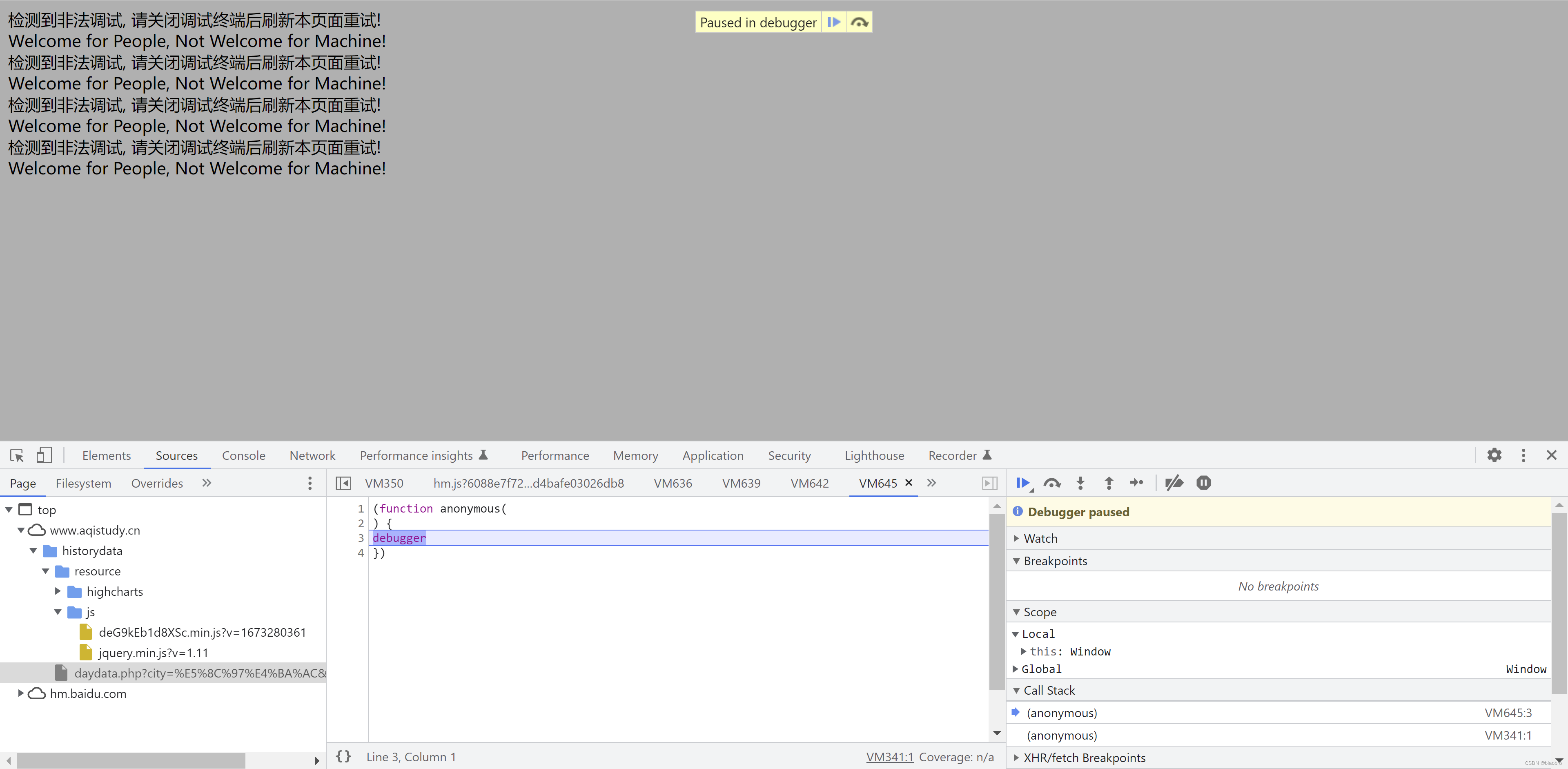
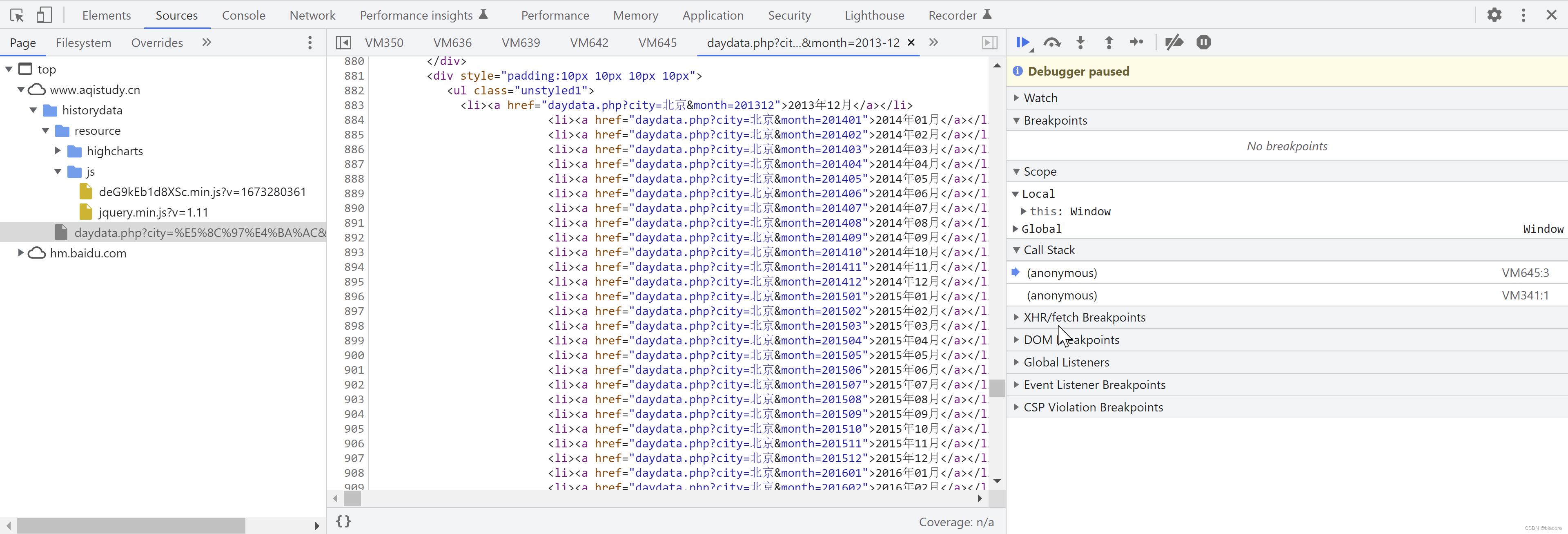
但是这里我有个发现 —— 其实也是反反复复费尽周折无心插柳:网页源代码出来了,就是这个 daydata.php,如果你在开发者工具Page栏里双击这个文件,你看到的是这样样子。我第一次看到这个时,反应时,WTF 不行,看样子对方把我识别为Machine 了,给我这么1个网页。
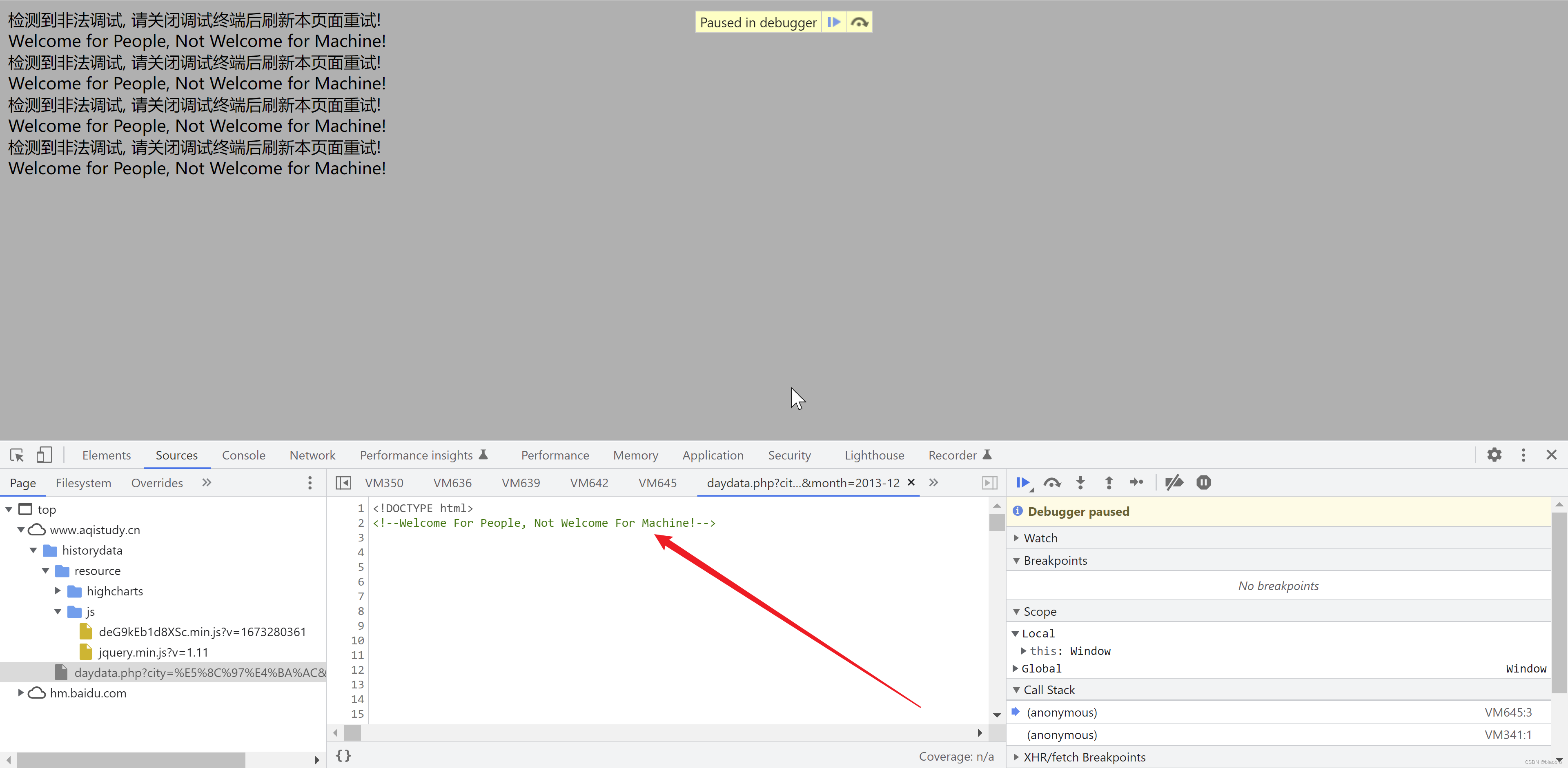
但是 —— 后面会有无数个但是,忽然有一次我发现这个这个文件右侧有滚动条,可以下拉,于是我就下拉,拉了很久发现全都是空白就要放弃的时候,新大陆出现了 —— 从第639行开始,有html 代码了!!!
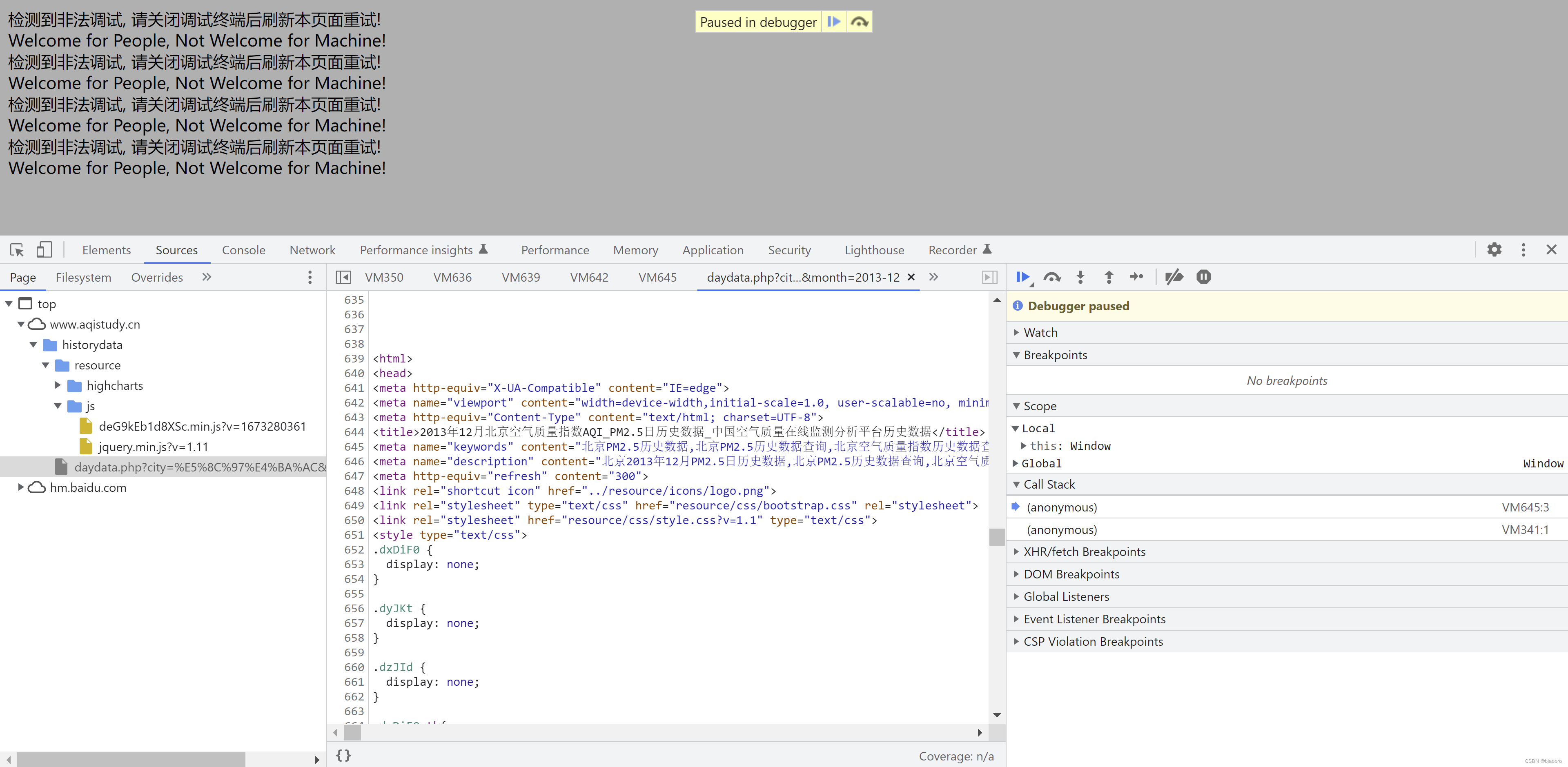
然后再往下,有了正常的 css 样式,和月份以及城市列表了。到这儿我知道,我的第一个难关应该已经跨过去了,有这个东西就好说,可以继续。
后来还找到1个查看网页源代码的方法:在浏览器地址栏里输入 view-source:那些被禁用了右键的网页的url 。对,映入眼帘的还是一大片一大片的空白,让你以为你是不是被封印了。

第2步:分析网页源代码
接下来可以看看网页源代码了,刨去那大片留白,其实他的代码很少,但是无论你怎么找,你都不会找到网页上展示的这些数据,你能找到几个包含了空气指标的Table 标签,但是等等等等:页面上展示的只有1个表格,为什么源代码里会有3个 Table 标签,而且各自的表头都不一致???
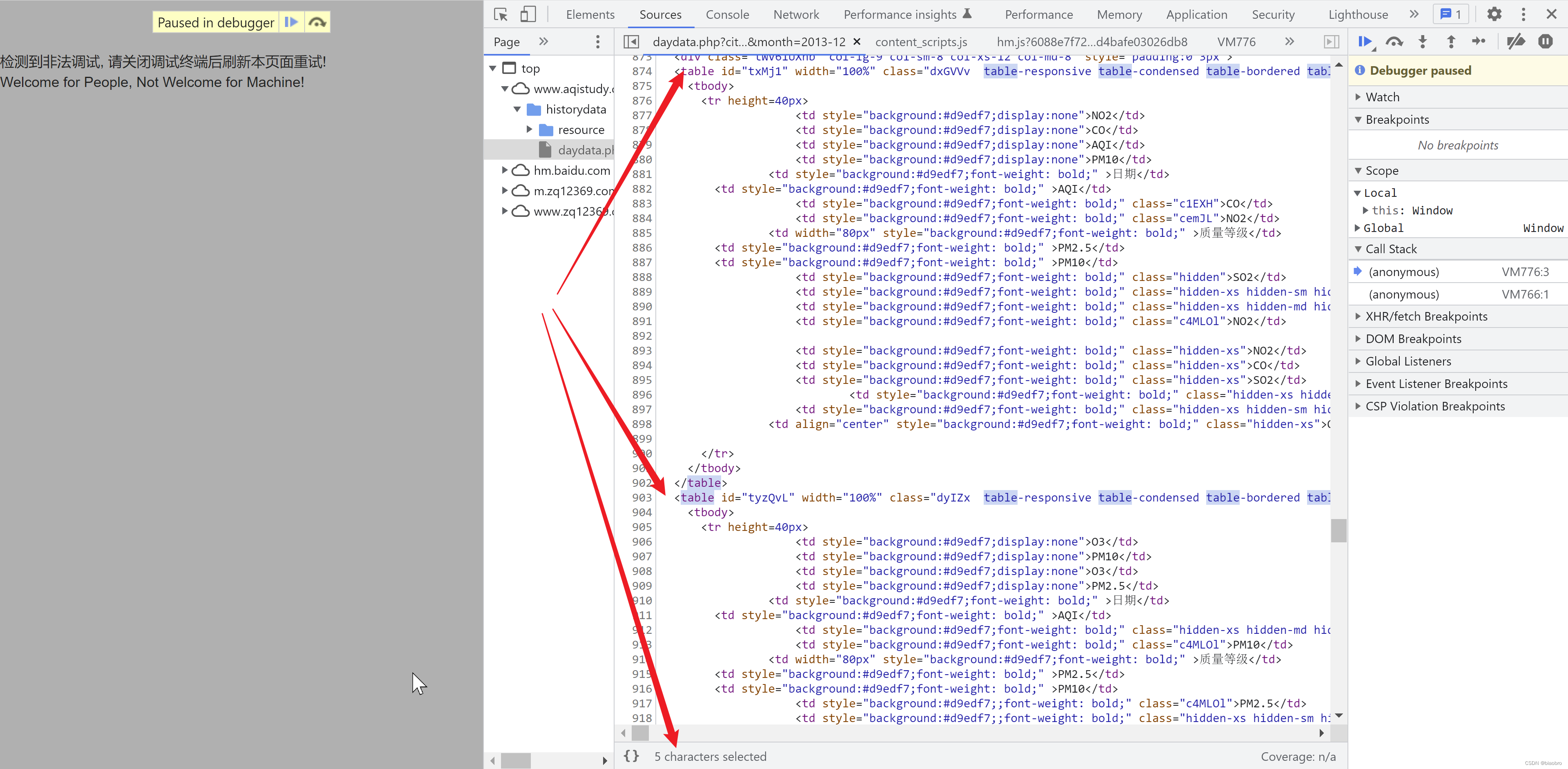
如果说前面遇到的障碍还不算什么,那这里真的就是我想给网站的程序员点赞的第1个地方。事实上,在后续的代码逻辑中,他确实是根据一些逻辑来在3个里面选择1个加以使用的。代码长下面这个样子 —— 有人会注意到为什么和上面那个图的 Table ID 不一样,因为不是1个时间点也不是同1个城市同1个月份,Table ID 不重要,重要的是逻辑。这段逻辑我命名为 数据获取和展示.代码。—— 因为这这个时间点,我只是存疑,并不知道具体是什么样的逻辑或代码。后面我们会讲到这个 数据获取和展示.代码 是怎么来的
有些跑题,我们最终关心的是怎么拿到原始数据,而不是这些数据在他网站是怎么展示的。继续,网页源代码里没有直接提供原始数据,也看不到发送ajax 请求的地方,那怎么办?调试吧,看他代码到底是怎么执行的。但是前面可以看到已经是无限Debugger了,怎么调试???
于是乎我又开始了艰难的搜索之旅,有人说在Debugger断点设置 条件断点为False,或者Never pause,我甚至尝试了安装油猴插件做js脚本替换。前面2个比较直观,不行就是不行。后面这个可能是我姿势不对,最终也是不行。
但是皇天不负有心人,终于的终于,在1个网站上看到说:网站可能会监控网页窗口的大小,判断是否打开了开发者工具,从而进入无限Debugger。Bingo!牛逼!原来还有这么一招!于是我把开发者工具窗口 undock into separate window,拆分成1个新的窗口。

然后直接在地址栏里输入日历史数据页面的地址。很好,现在页面正常展示了,不再是“检测到非法调试,请关闭调试终端后刷新本页面重试!”,虽然开发者工具看起来还是进入到了无限Debugger。

实际上在这里,如果切换到network 栏,已经可以看到新发出的请求,对就是这个 historyapi.php。headers 里可以看到请求地址,请求方法,请求头。然后最关键的,也是这个案例中最迷人的, payload 和 response 里可以看到的那串长长的看不懂的字符。
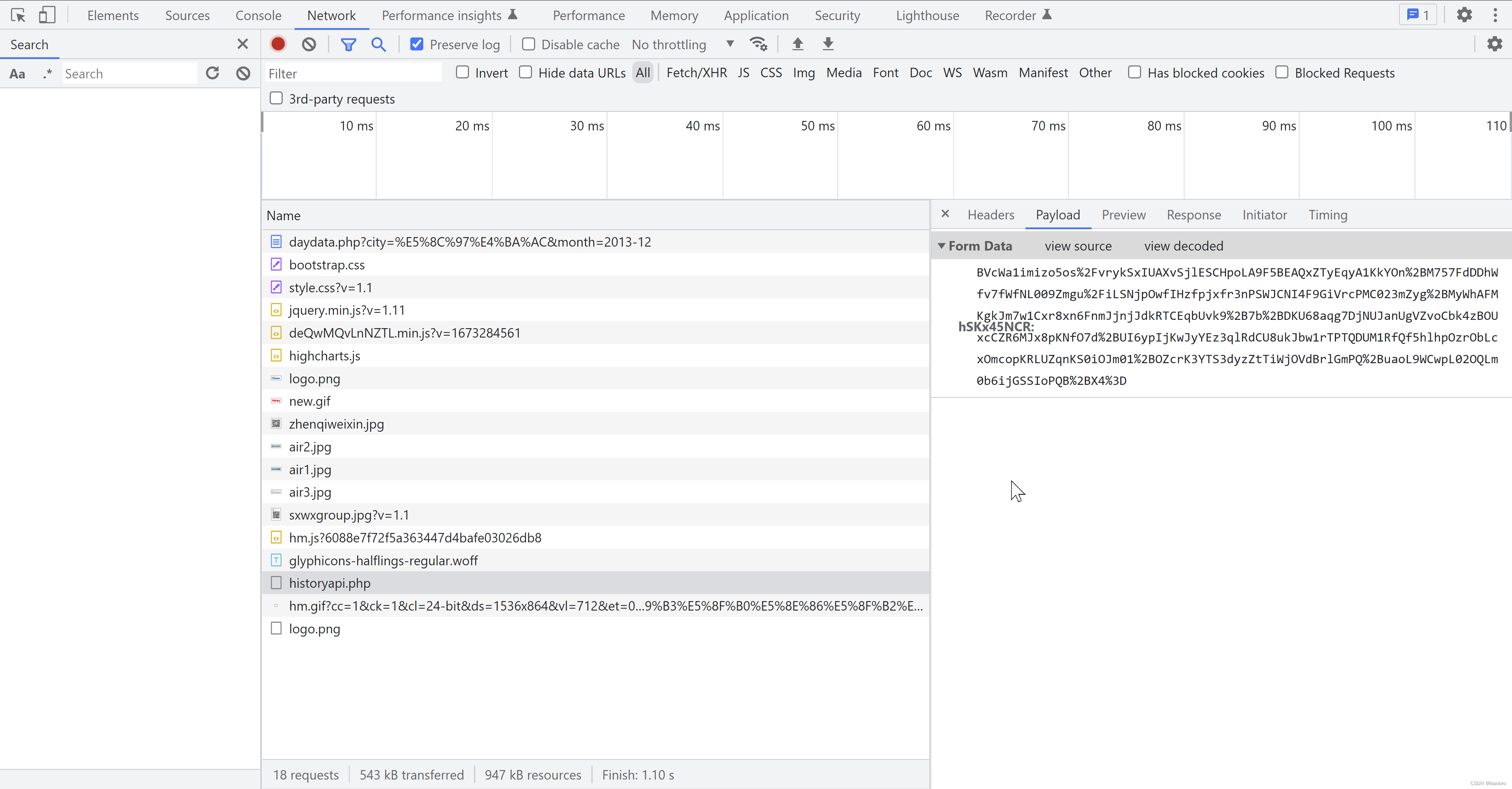
有经验的同学应该一看就知道,这一定是有对参数进行加密和对返回解密的过程。但是的但是,我是前端菜鸟啊,我当时就想,WTF 这怎么来的?怎么办,找吧。怎么找?我搜索FormData 里的这个key,No matches found.
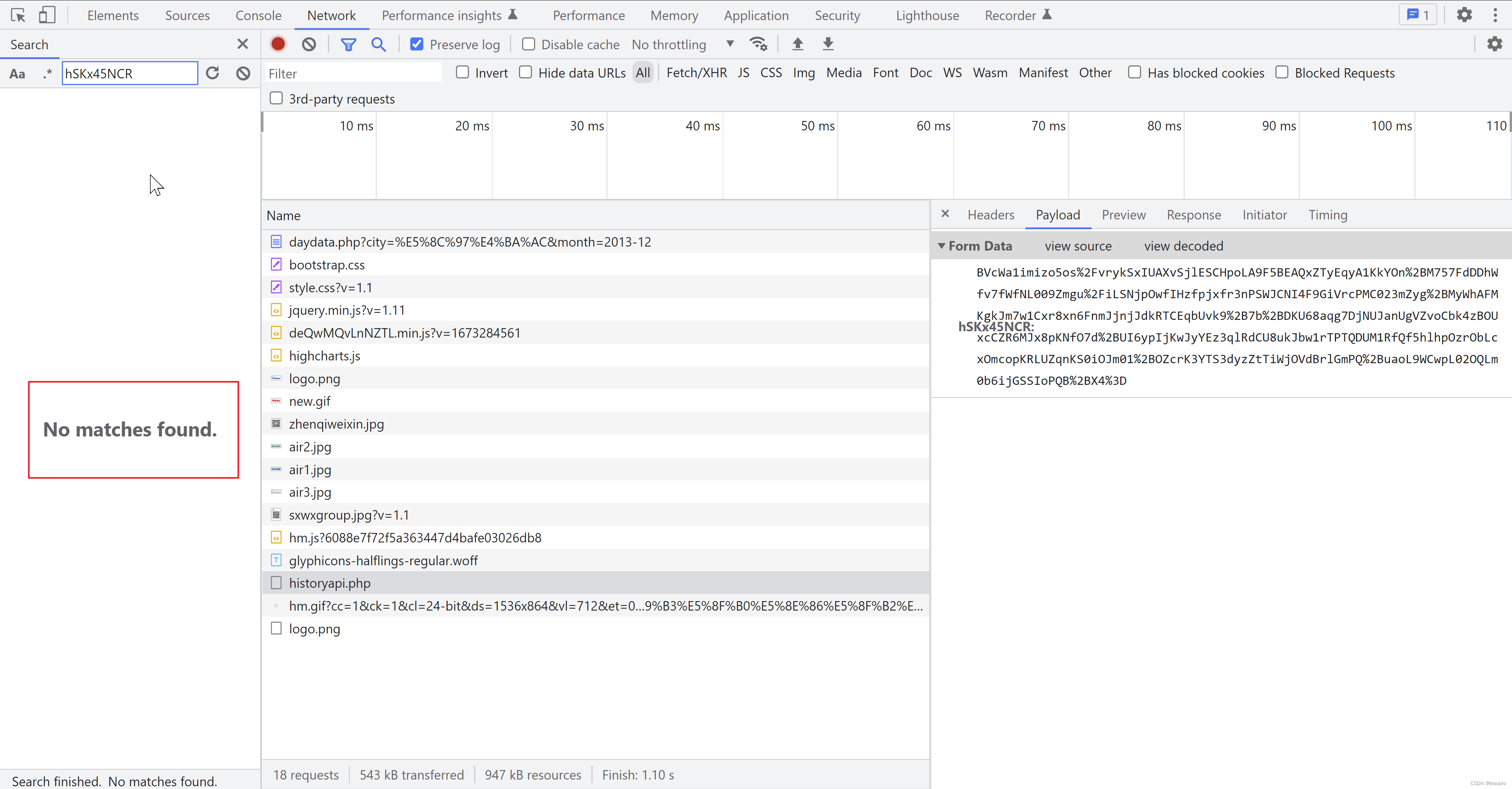
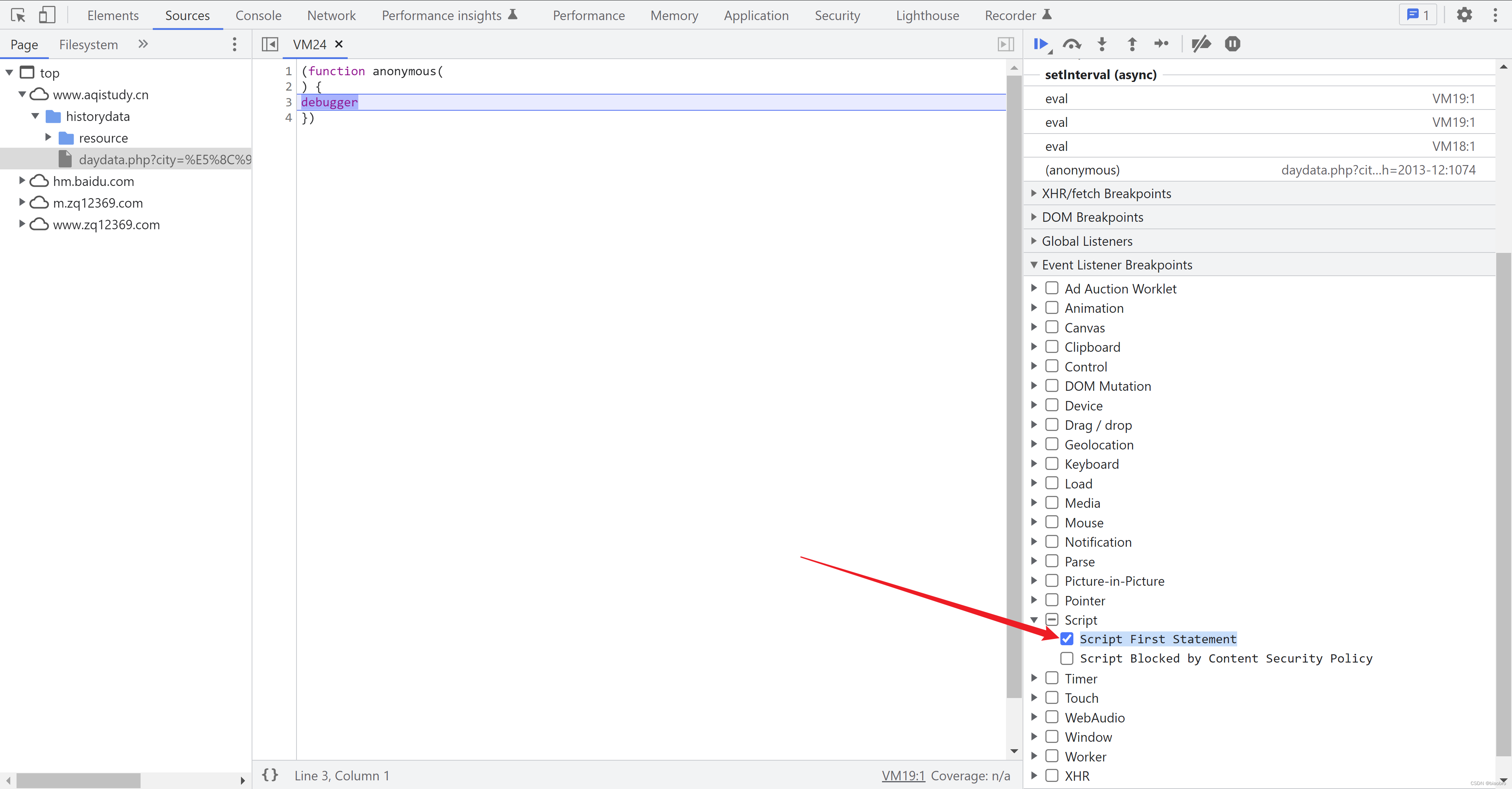
怎么办?还是回到起点,调试,一步步执行,看是在哪里生成的吧。于是新的问题来了,开发者工具即使能打开,也是无限 Debugger,没有办法调试。怎么能让代码停下来,在监测窗口大小代码被执行前停下来,甚至在最开始就停下来,受控执行,而不是放任浏览器自己一鼓作气势如破竹一路向西?我灵光一现,想起2021年底研究 js 逆向时设置过页面的鼠标点击事件断点 —— 用于监测点击登录按钮后停下来,那回到这里是不是有些其他条件可以用?—— 咦,怎么有个Script,下面还有个 Script First Statement —— Statement 无论哪种编程语言都会有这东西,脚本第1次被申明的时间点 —— 这会不会就是我梦寐以求(其实是真爱和自由)的东西?
@此时是2023年1月10号凌晨1:45,暂停休息,早起继续。
@现在是2023年1月10号早晨8:32,继续。
接下来的步骤,一定要注意顺序不能错,否则就还是无限Debugger模式。
- 第1步:为了排除无关因素干扰,我们都使用浏览器的无痕模式。
- 第2步:F12打开开发者工具窗口,勾选 Script First Statement
- 第2.X步:为了便于观察和截屏,我调整了浏览器窗口和开发者工具窗口大小。这里可以选中窗口后,然后键盘按 window + 左键,或者右键,快速停靠
- 第3步:回到浏览器输入日历史数据的页面地址,敲回车
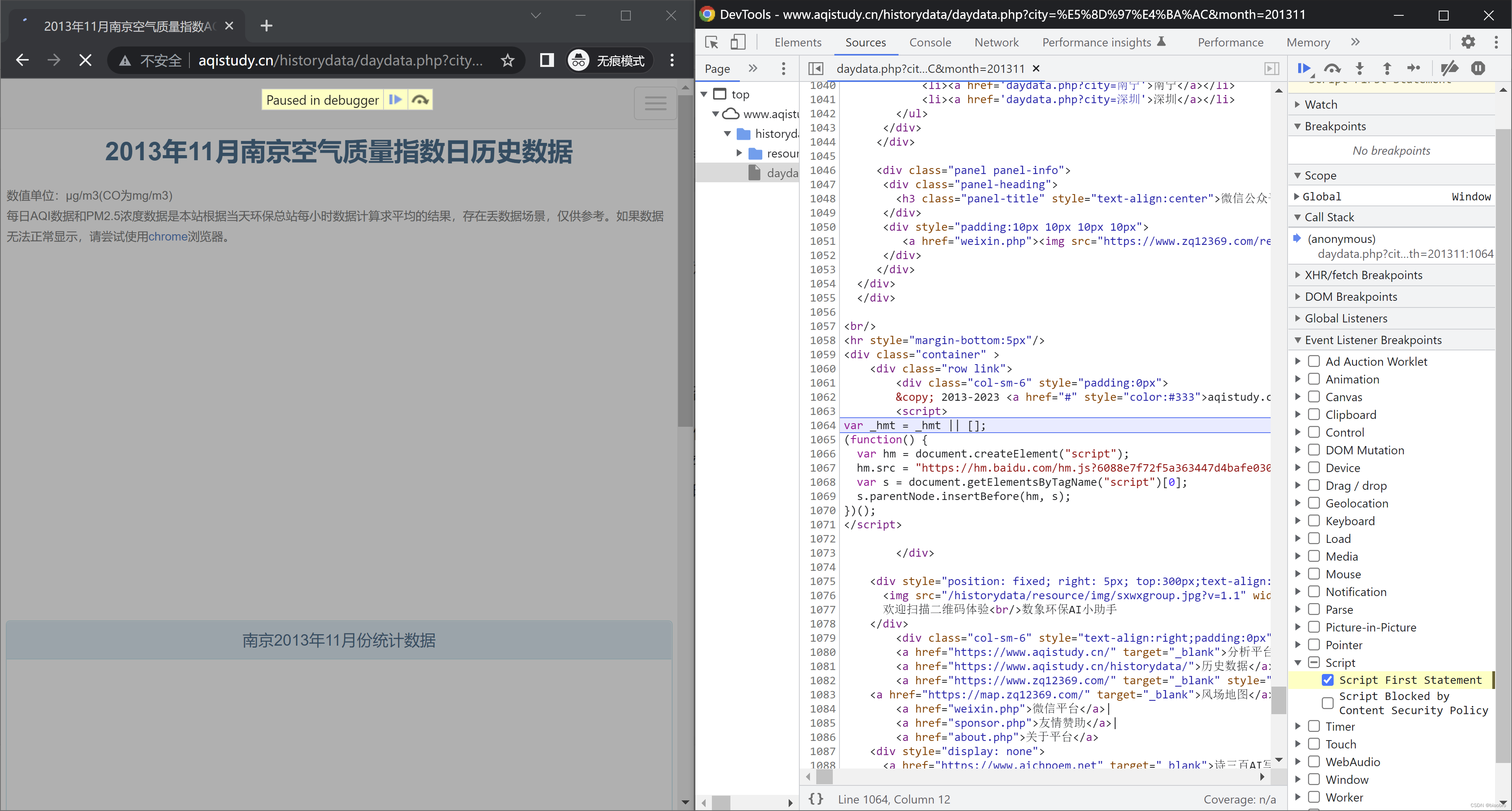
- 第4步:见证奇迹的时刻
哇喔,发生了什么?他停下来了,在 daydata.php 这个网页源代码中的第1段 script 的地方,浏览器停了下来,没有进入无限Debugger!!! hhhhhh 请让我仰天大笑五十分钟 —— 这就是调试的作用。
再下来要做的事情,就是按部就班,找到所有的Script 部分,然后打上断点 —— 这个操作事后被证明是多余,因为前面设置了 Script 事件断点,浏览器在每段 Script 的开头一定会停下来,等着你操作。
来逐一审视下这一共5个 Script 代码片段。
第1段这里是去执行 baidu 的这个js 文件,这个文件,他是百度的1个标准的东西,用来生成cookie 啥的,感兴趣的同学可以自行搜索:百度统计。或者进入传送门:百度统计的JS脚本原理分析 另外我们要爬的这个网站,他没有要求我们必须注册才能访问,所以很明显,我们没有必要去关心cookie 是怎么设置的,事实上我们期望每次都是不使用cookie,直接发送请求获取最新数据。所以第1段代码,我们按F8直接运行跳过。
第2段代码,可以看到他是去服务器上请求1个新的js 文件,路径是 “resource/js/jquery.min.js?v=1.11”,这个文件很重要,我们将这段代码逻辑命名为:前置数据编码和解码.代码. 前置是因为后面还有进一步的编码解码逻辑会调用到他。他是在标准的jquery.min.js (路径参数是v1.11,实际是1.10.2)基础上加了一些代码,一共7个部分。
- 第1部分是标准库,后文的 ajax 请求会调用这里的代码。
- 第2部分是检测是否有 jQuery,字面意思是这样
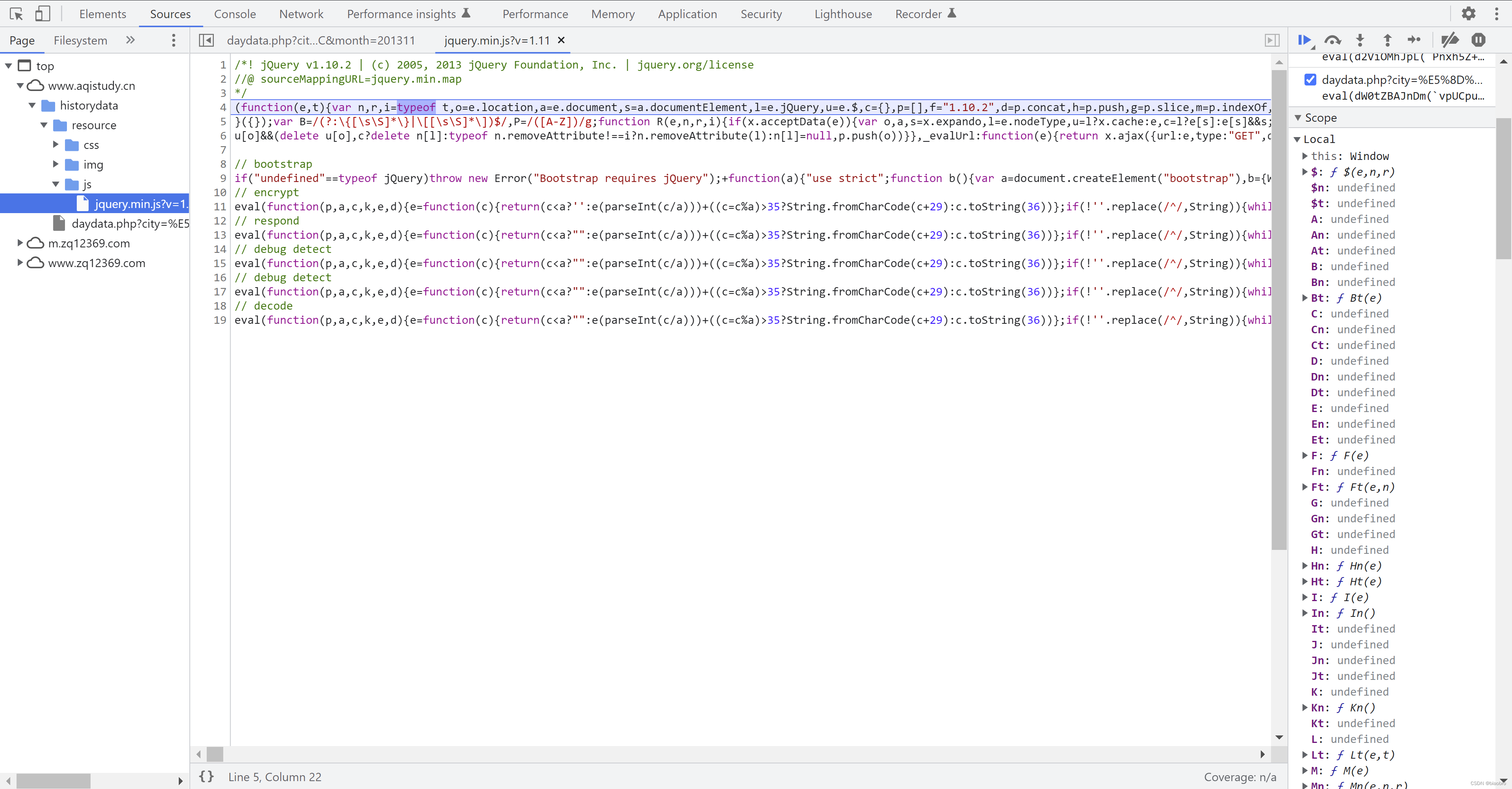
- 第3到第7部分,每1部分都是执行1个带了很长很长字符串参数的 eval 函数,函数逻辑完全一致,不同之处只有后面的这个参数。我们点击代码窗口左下角的 {} 代码格式化按钮,这样便于观察。然后要做的就是在每个 eval 片段的开头和末尾打上断点,然后F8 执行,观察他的输出是什么
- eval 内部的这个function,从结果看就是做字符串变换。其实我很好奇程序员是怎么想到这个招儿的。有兴趣的同学可以在 eval 开头停下后按F11 进入代码逐行运行观察,这是非常细节的部分,这里不再展开了。我后来还花了些时间用 Python 还原了他的处理逻辑:字符串处理.代码 拿去不谢。你可以本地跑一下,看是不是会有更多体感。
# !/usr/bin/env python3
# _*_ coding:utf-8 _*_
"""
@File : test.py
@Project : Scrapy
@CreateTime : 2023/1/3 14:17
@Author : biaobro
@Software : PyCharm
@Last Modify Time : 2023/1/3 14:17
@Version : 1.0
@Description : None
"""
# 这些是在 能够通过html 页面得到的 jquery.min.js 文件中定义的,目前看来是固定的
encrypt_param = [太多了自己复制粘贴到这里吧]
response_param = [太多了自己复制粘贴到这里吧]
debug_param1 = [太多了自己复制粘贴到这里吧]
debug_param2 = [太多了自己复制粘贴到这里吧]
decode_param = [太多了自己复制粘贴到这里吧]
param_list = encrypt_param
# 列表中的元素依次赋值给6个变量
p, a, c, k, e, d = param_list
# 对应JS代码里的 W() 函数
# 将10进制数 转成 36进制
# 36进制 = 26个字母 + 10个数字
def toString36(number):
num_str = '0123456789abcdefghijklmnopqrstuvwxyz'
if number == 0:
return '0'
base36 = []
while number != 0:
number, i = divmod(number, 36) # 返回 number// 36 , number%36
base36.append(num_str[i])
result = ''.join(reversed(base36))
# print("return from base36_encode() : " + result)
return result
def e_func(c):
if c < a:
x1 = ''
else:
x1 = e_func(c // a)
c = c % a
if c > 35:
# 将Unicode 编码转为一个字符:
x2 = chr((c + 29) & 0xffff)
else:
x2 = toString36(c) # c.toString(36)
return x1 + x2
def update_p(src_p):
regex = r'\b\w+\b'
import re
return re.sub(regex, repl, src_p)
# 作为 re.sub 的第二个参数, repl 只能有1个默认参数 match object
def repl(match):
x = d.get(match.group())
return x
if __name__ == '__main__':
while c:
c = c - 1
d[e_func(c)] = k[c] or e_func(c)
# d type is dict, will be str if after json.dump
# print(type(d), d)
new_p = update_p(p)
print(new_p)
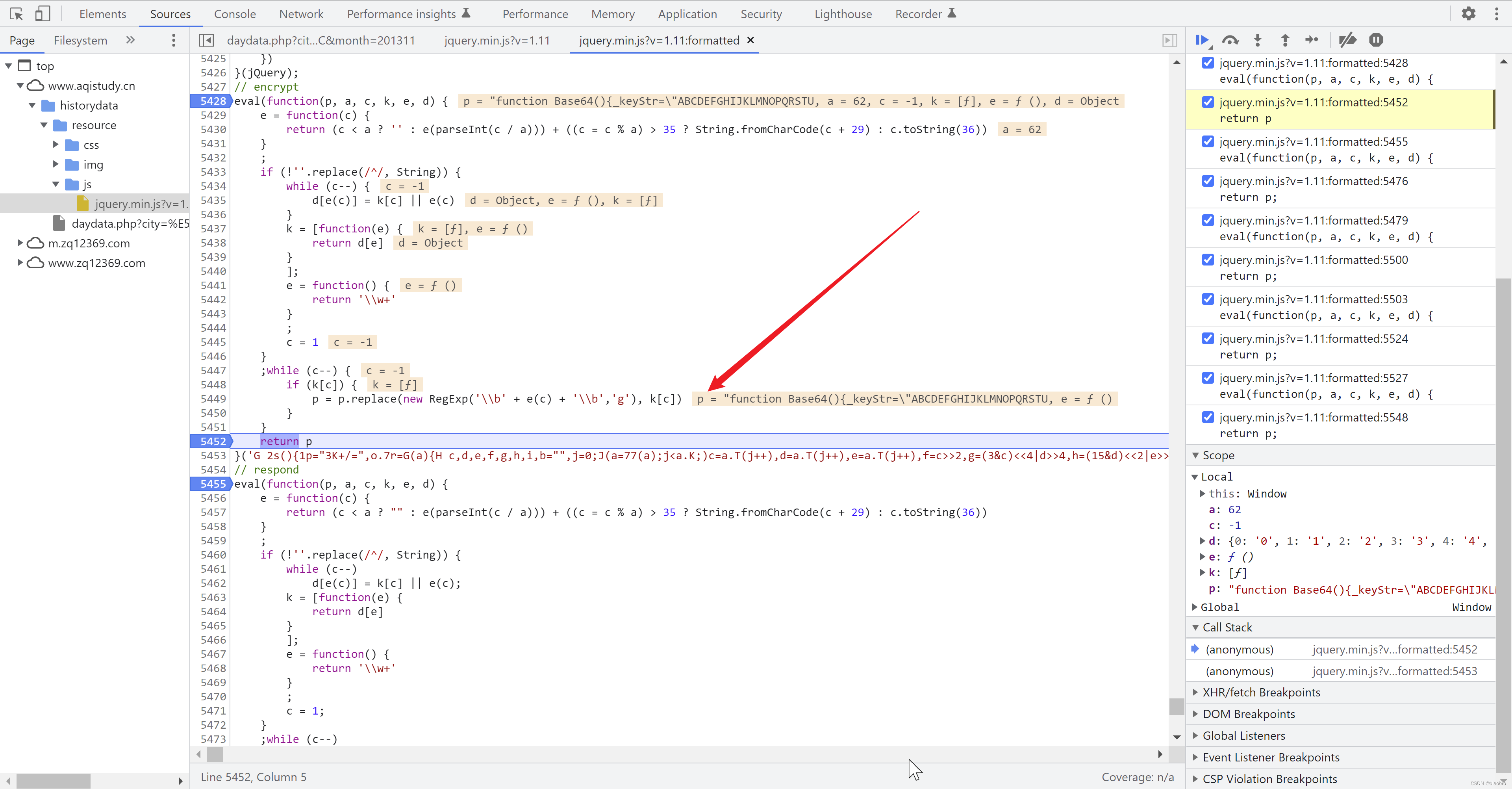
- 第3部分,可以看到返回是 function Base64() 开头的一串至少看起来不再是毫无 意义的字符串了,你可以从右侧scope 窗口把 p的内容复制出来,对的你没看错,他有36.6KB
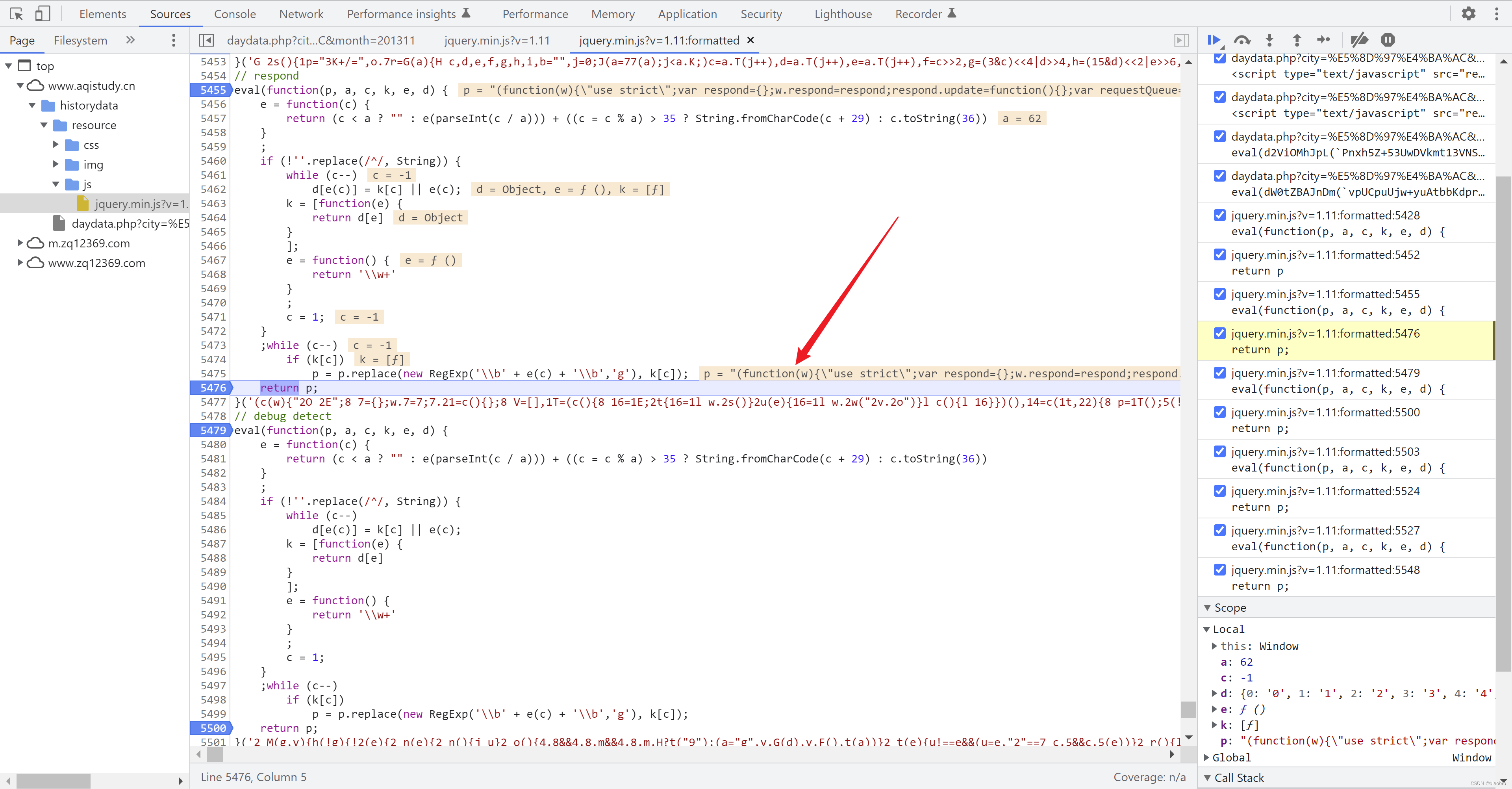
- 第4部分,也返回了 一串看起来有意义的代码,但是这段代码我到最后也没发现在哪里有用到,可以忽略
- 第5部分 和 第6部分可以一起来看,看到注释里写的 debug detect 了么,对没错 —— 程序员一定要养成写注释的习惯, 哈哈哈哈哈哈 ~ 前面遇到的反爬措施诸如右键被禁用、F12被禁用、无限Debugger 就是在这2个部分里实现的
- 其中第5部分,window.addEventListener("resize", o) —— 能看得懂英文就行,向窗口里添加了1个监测 resize 的监听器
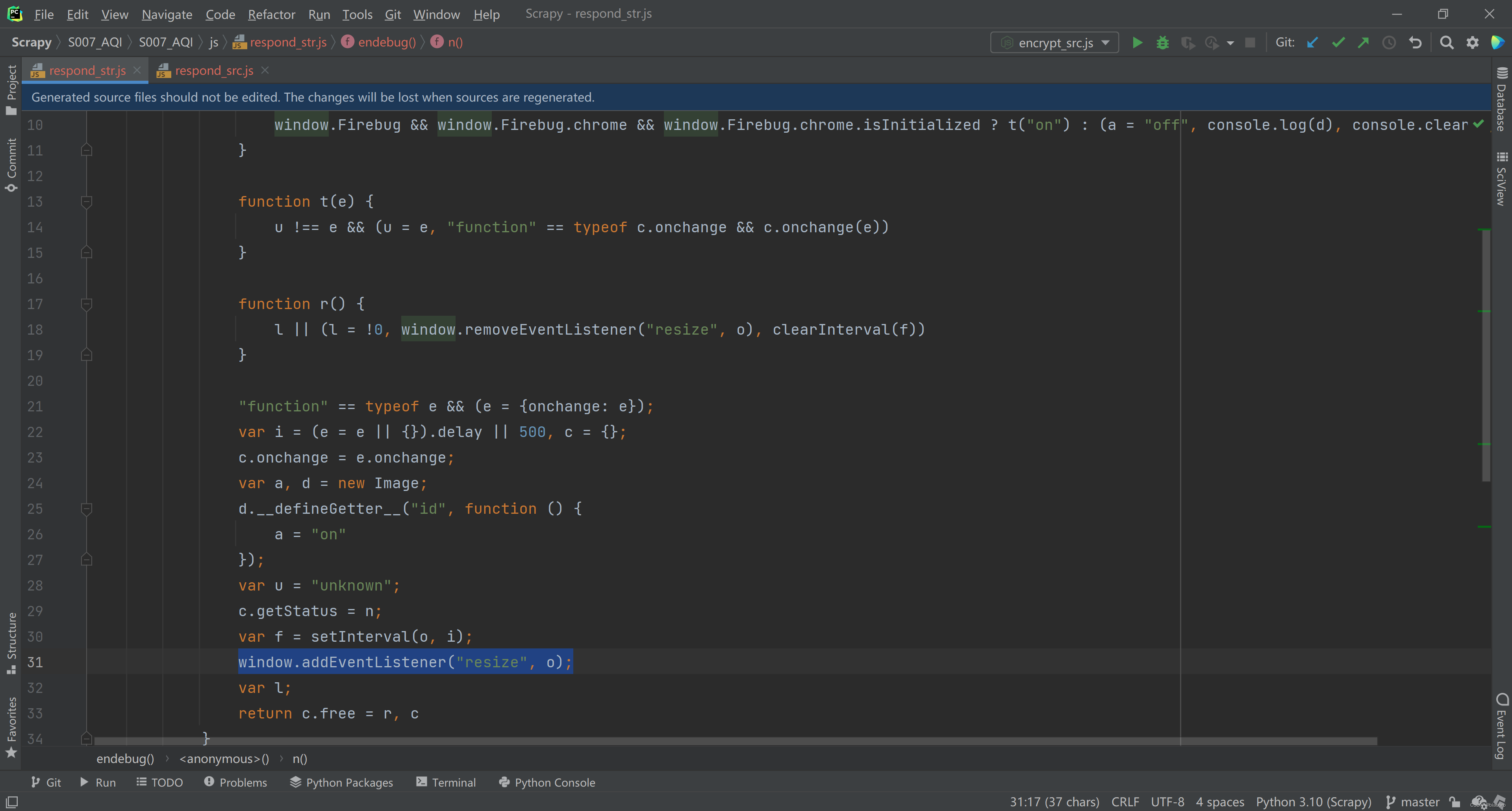
- 然后第6部分,你发现他返回的是对这个 txsdefwsw 函数的继续调用,并不是我上面提到的什么反爬代码 —— 别慌,保留疑问,先继续
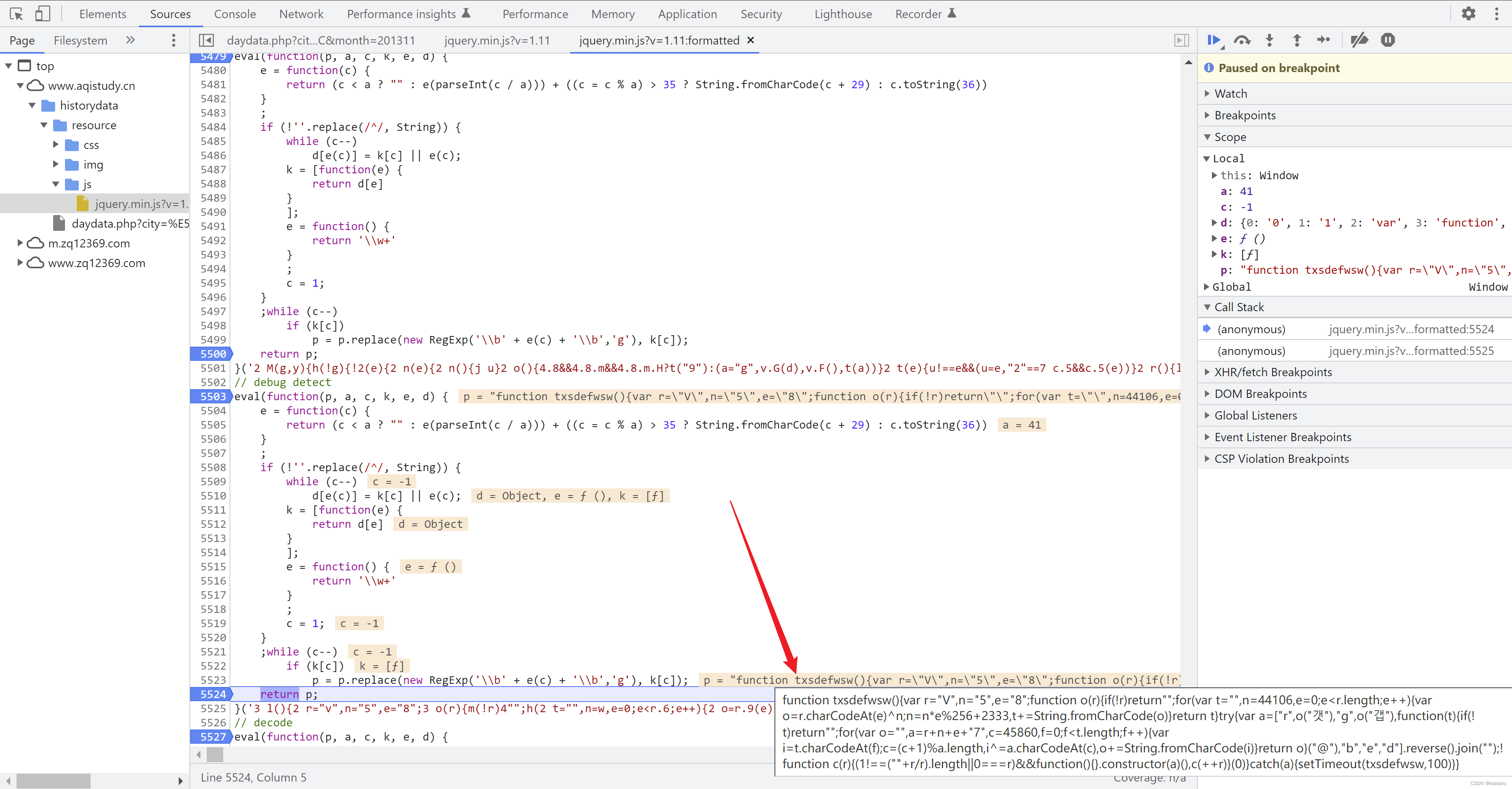
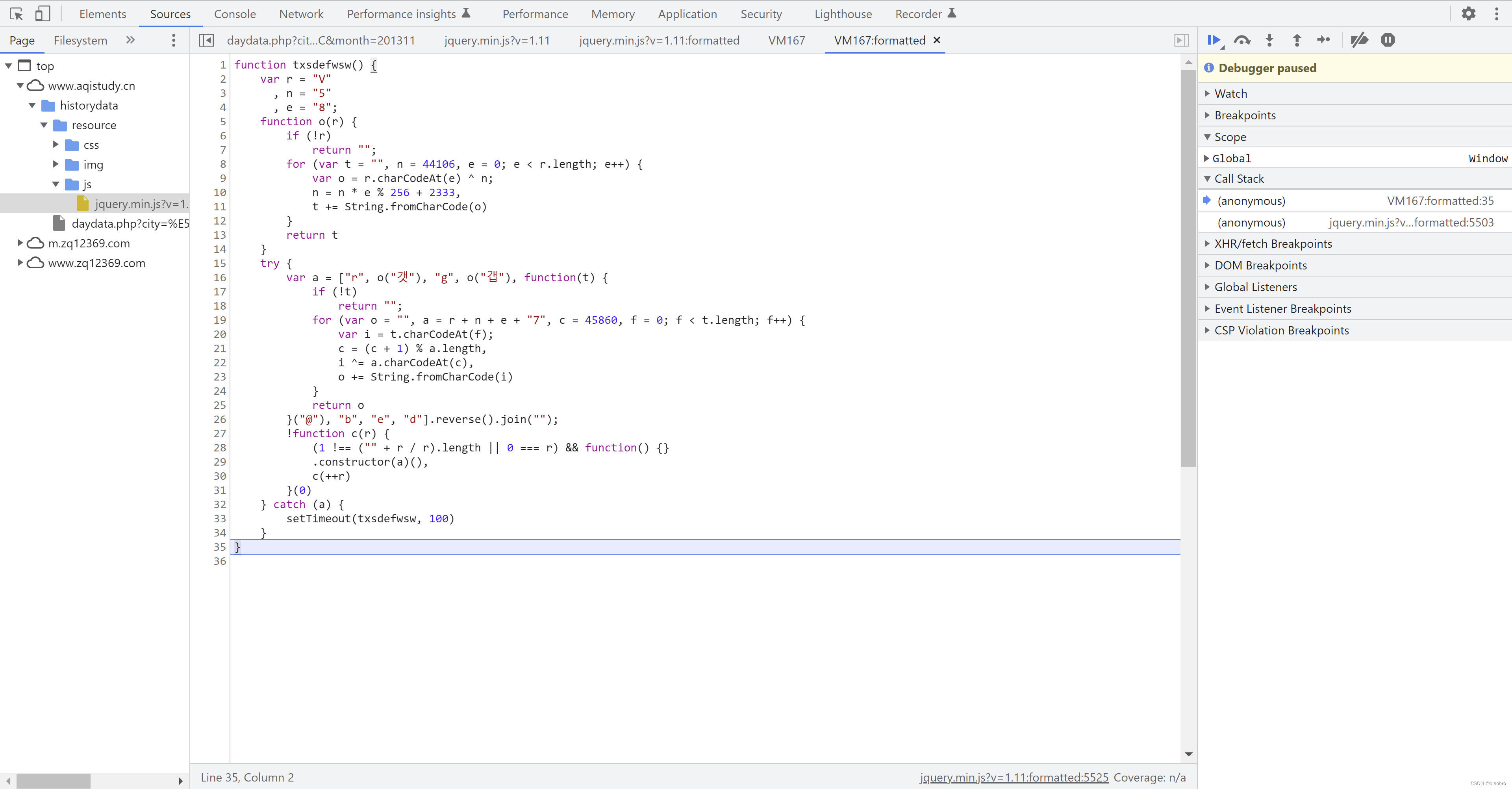
- 我们先看第第7部分,他返回的是1个新的名为 dweklxde 的函数,其中实现了对 Base64 对象的实例化,然后调用实例的 decode 函数
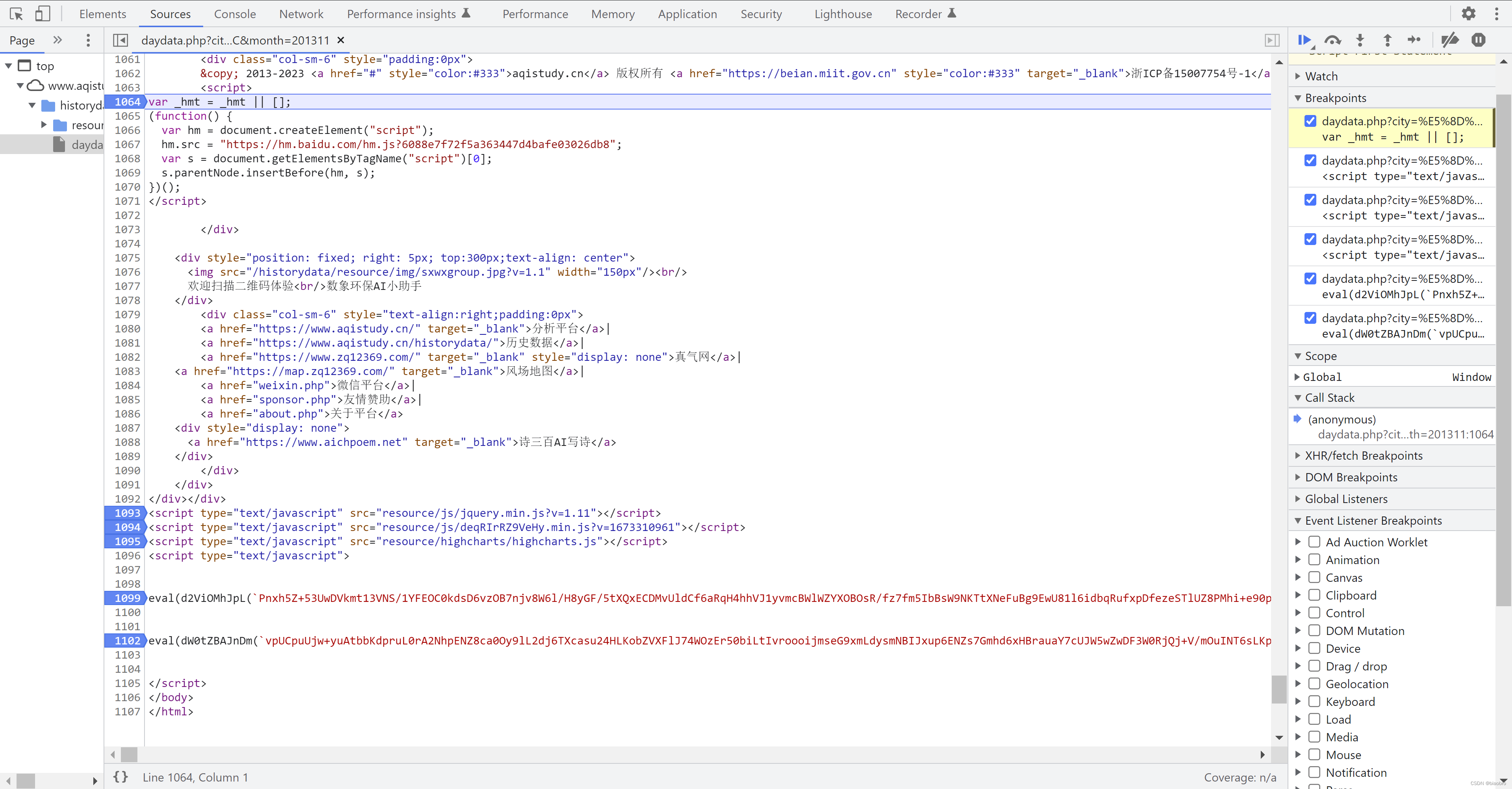
- 到这里,第2个 Script 分析完了,他们最重要的职能就是生成了一些新的 js 代码。而且注意,这个Script 以及新生成的代码不会随着请求时间或其他条件的变化而变化,你可以重复上面的步骤,验证我说的是否正确。这里强调不变,是因为我们接下来要进入第3个 Script,这是1个随请求时间变化而变化的代码段。再次向程序员致敬。
- 我们继续F8,代码进入 "resource/js/deqRIrRZ9VeHy.min.js?v=1673310961" 并停在开头。这个文件他也是从服务器发送请求,获取到的。如果你多次尝试并且注意观察,就会发现文件名称,.min 前面的这串字符,以及v后面跟的这串数字,似乎每次都不一样 —— 等等,为什么是似乎? 这串字符我没有找到他的规律,最后放弃了。但是这串数字呢,嗯,10位,那就是时间戳啊?!时间戳转换工具(Unix timestamp) - 在线工具 果不其然。等等,我好像又发现了什么,08:36:01 —— 即便我是在 08:39,08:42,08:44 拿到 daydata.php 的源代码,他也还是 1673310961 对应 08:36:01 —— 那这是?于是又经过了锲而不舍的尝试,最终发现他是在每个整点范围内从 06 分开始,每隔10分钟变化1次,每次v发生变化,js 文件的内容就会变化,换句话说,06分开始的每个10分钟间隔内,你拿到的 js 文件是完全相同的 —— 虽然到最后会发现,探索这个变化规律对我们获取数据的目标并没有什么卵帮助,你想,我都能拿到 js 文件了,文件里的东西我随便拿出来用,我管你怎么变化 —— 实际上这也是最终爬虫代码的处理思路,但这是马后炮,在研究网页代码逻辑的过程中,你不知道哪些地方会影响你的最终结果,还是要注意并探索每一处细节的变化
- 再次回到正题,我们还是先格式化代码。是不是有些眼熟,eval(function...)(很长很长的一串参数,其实是分了p,a,c,k,e,d 共6个部分) —— 对,上面提到变化,除了文件名称,这个文件内容也是相应变化 —— 包括参数部分,以及函数体内的第1个 e 函数
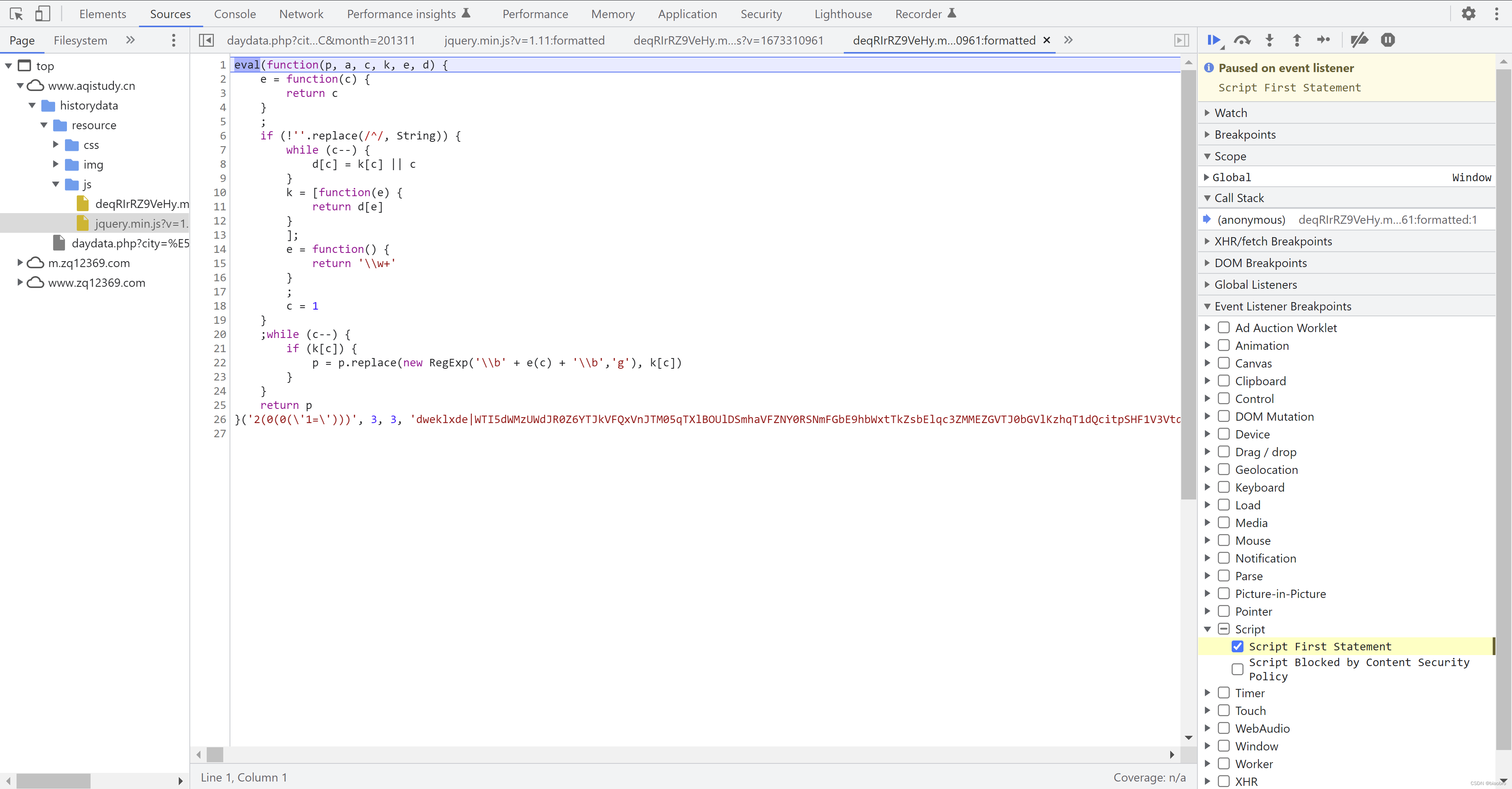
- 但是无论这些地方怎么变化,最终得到的结果 p 就3种形式
- 第1种是 const 变量定义开头的代码
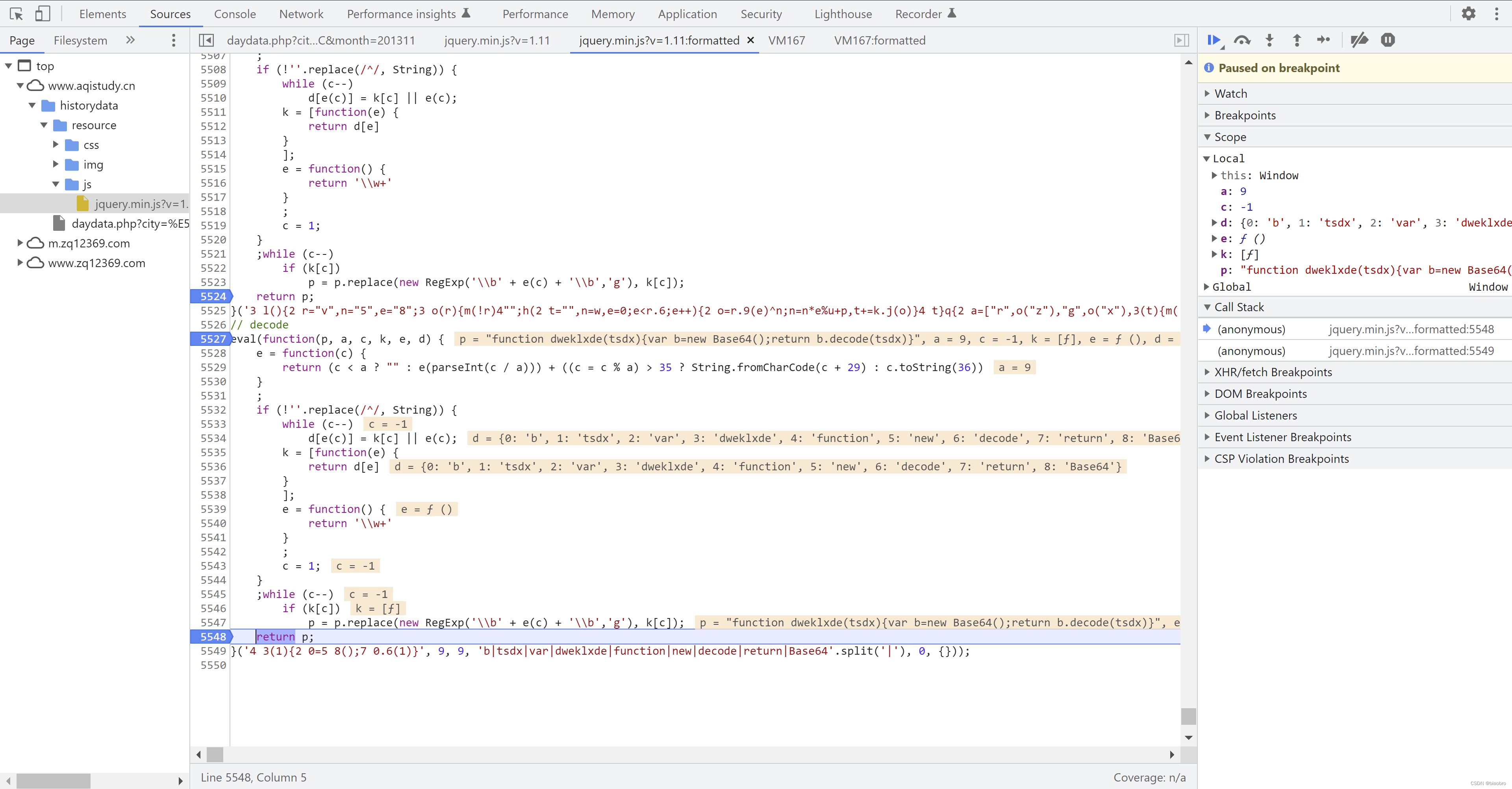
- 第2种是 dweklxde(参数) 的形式,会调用 jquery.min.js 中的第7部分代码,做Base64 decode
- 第3种是 图中这样嵌套 dweklxde(dweklxde(参数)),执行2次 dweklxde
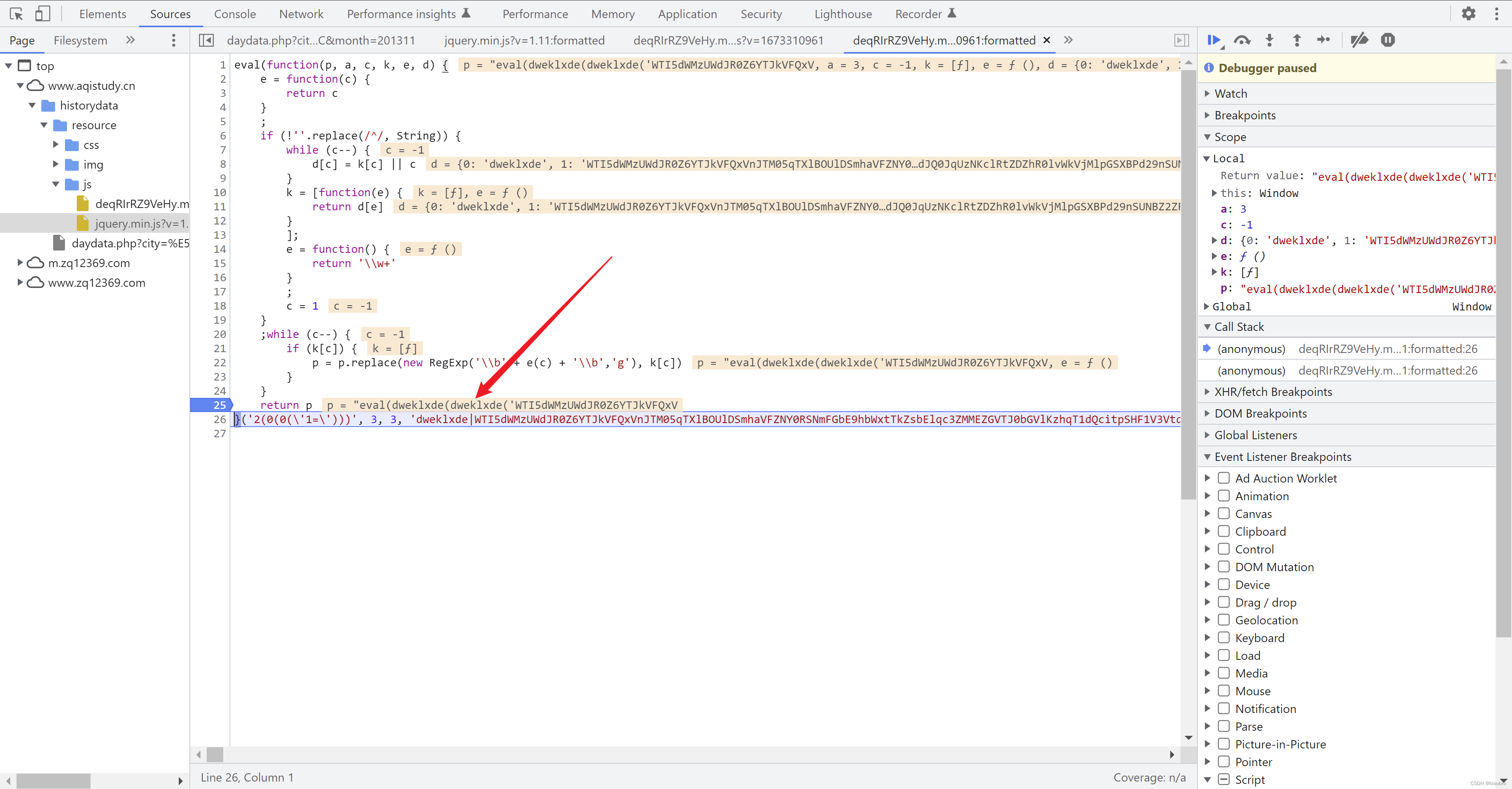
- 第2种和第3种,做完Base64 decode 之后的最终结果都是第1种形式的代码(在内存中运行,而不是以文件形式存在),如下图。
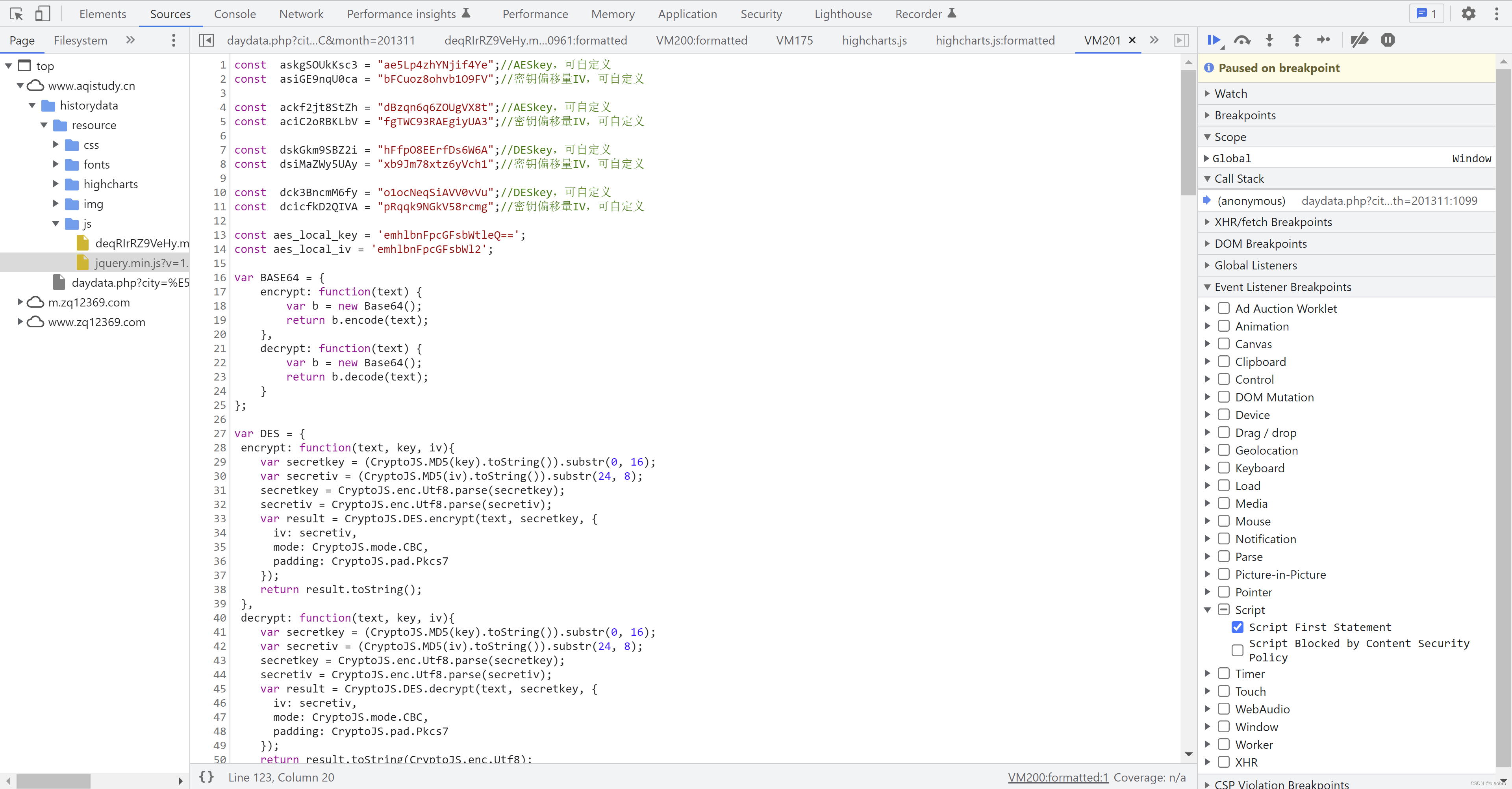
- 这段代码需要仔细审视,他是我们实现爬虫逻辑的基石。我们把他命名为:终极数据编码和解码以及发送请求.代码,(终极是对应前面提到的的前置)并复制出来观察。
- 开头定义了一些编解码使用的key
- 然后实例化了
- BASE64,
- 调用标准库 CryptoJS 实现的AES 和 DES,
- 以及 localStorageUtil 用于保存数据到本地
- 然后是一些不知名的函数,就是调用上面这些实例中的方法,并传入参数
- 最后这个是重中之重,可以看到 ajax,以及对应的请求参数、方法、成功之后的回调函数 —— 这部分代码是用于获取数据的源头,我单独整理了一份带注释版本。贴在下面,拿走不谢
// 第1个参数 mOOJ9grcY: 具体的接口名称,值固定为'GETDAYDATA'
// 第2个参数 oJQns9QgnY: 请求参数,字典形式,包含城市和月份 {city:"蚌埠",month:"201411"}
// 第3个参数 用于处理数据图形化的回调函数,可以忽略
// 第4个参数 值固定为6,用来判断是从本地缓存取数据,还是发送实时请求,可以忽略
function sqYiXA5UVXgiuVRV(mOOJ9grcY, oJQns9QgnY, c6Zyoz4Xr, pgA9wHO) {
// 调用 hex_md5 函数,对接口和参数进行 md5 加密
const kxhi = hex_md5(mOOJ9grcY + JSON.stringify(oJQns9QgnY));
// 判断本地缓存中是否存在数据,以及数据是否过期,返回缓存中的数据或者 null
const dpoaV = gCJUyxOQRicGo55H(kxhi, pgA9wHO);
// 如果本地数据为 null,则发起请求
if (!dpoaV) {
// 对请求方法、参数、以及appid、时间戳等参数组合,然后做 Base64, DES 加密
var pVCQ1id = pkbD4Ulf3(mOOJ9grcY, oJQns9QgnY);
// 发起请求
$.ajax({
url: 'api/historyapi.php',
// data 字典中的key hl5u9DqdT 是解析出来的,pVCQ1id 是前面加密结果
// key 也是每隔10分钟变化,不能一直沿用
data: {
hl5u9DqdT: pVCQ1id
},
type: "post",
success: function(dpoaV) {
// 对数据进行Base64、AES、DES 多轮解密
dpoaV = d8l2LIyh8mFRH8ZZF(dpoaV);
op22Ya = JSON.parse(dpoaV);
// 如果成功拿到数据,则保存到本地1份
if (op22Ya.success) {
if (pgA9wHO > 0) {
op22Ya.result.time = new Date().getTime();
localStorageUtil.save(kxhi, op22Ya.result)
}
c6Zyoz4Xr(op22Ya.result)
} else {
console.log(op22Ya.errcode, op22Ya.errmsg)
}
}
})
// 如果本地数据有效,则直接发给数据图形化回调函数
} else {
c6Zyoz4Xr(dpoaV)
}
}- 上面第3个 Script 执行完,继续F8,会进入第4个 Script,就是这个 "resource/highcharts/highcharts.js",这个文件从服务器请求得到,也是1个第3方的库,代码很长,看他的名字 chart —— 应该就是绘图相关的,直接F8 执行跳过。实际到这里为止,执行过的 Script 都是要么生成一些新的待执行代码,要么就是跟我们的目标无关
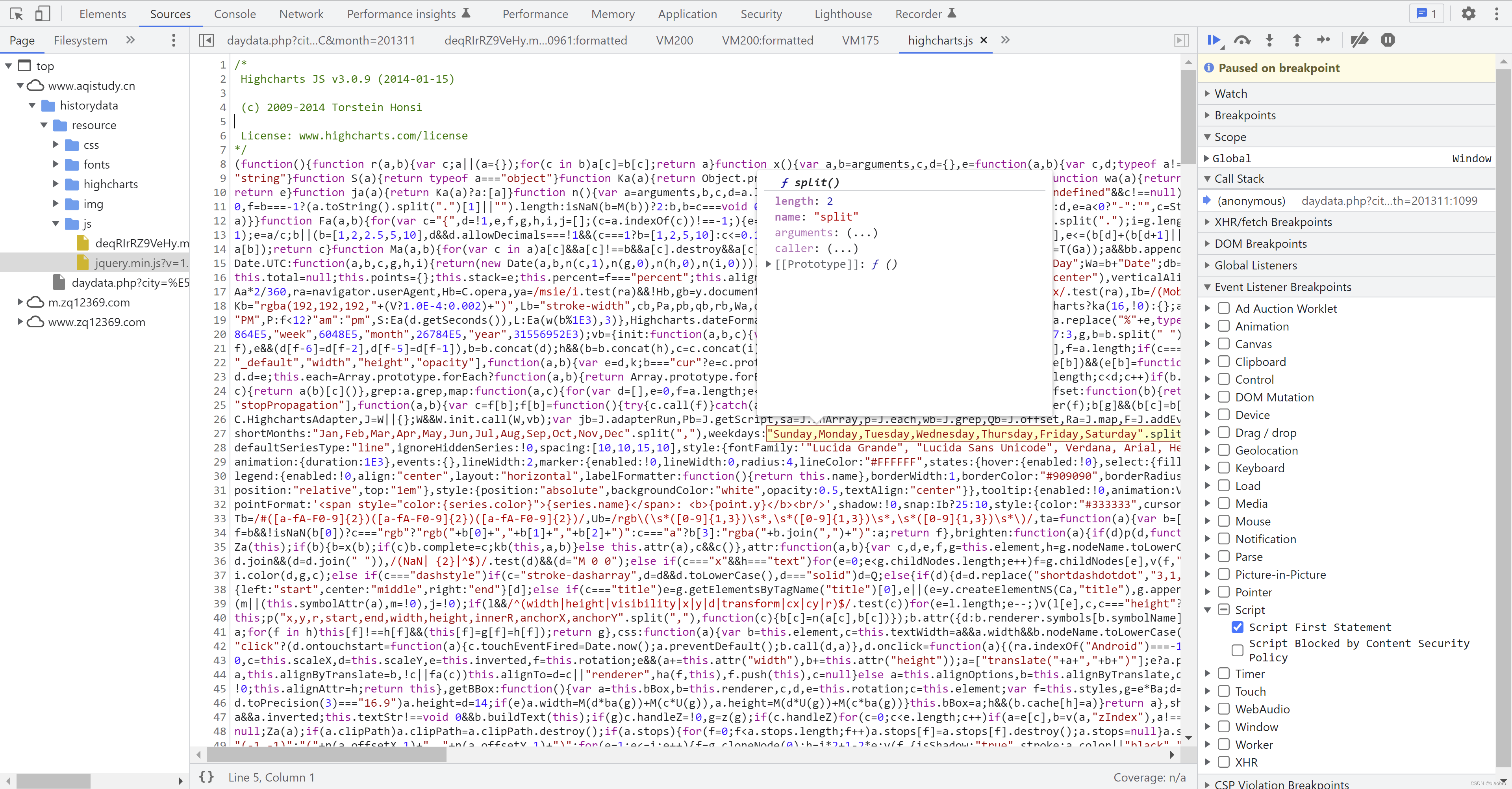
- 然后来到第5个 Script,这里面又包含了2段代码,我们将其命名为 5.1 和 5.2. 如果你有心的话,一看就会知道,2个eval 里面的函数 d2ViOMhJpL 和 dW0tZBAJnDm,其实都是在上面提到的 终极数据编码和解码以及发送请求.代码 中得到的。没心也没关系,我们可以调试,甚至你可以鼠标放到函数名称上根据弹出的浮窗,点击FunctionLocation 直接跳转。
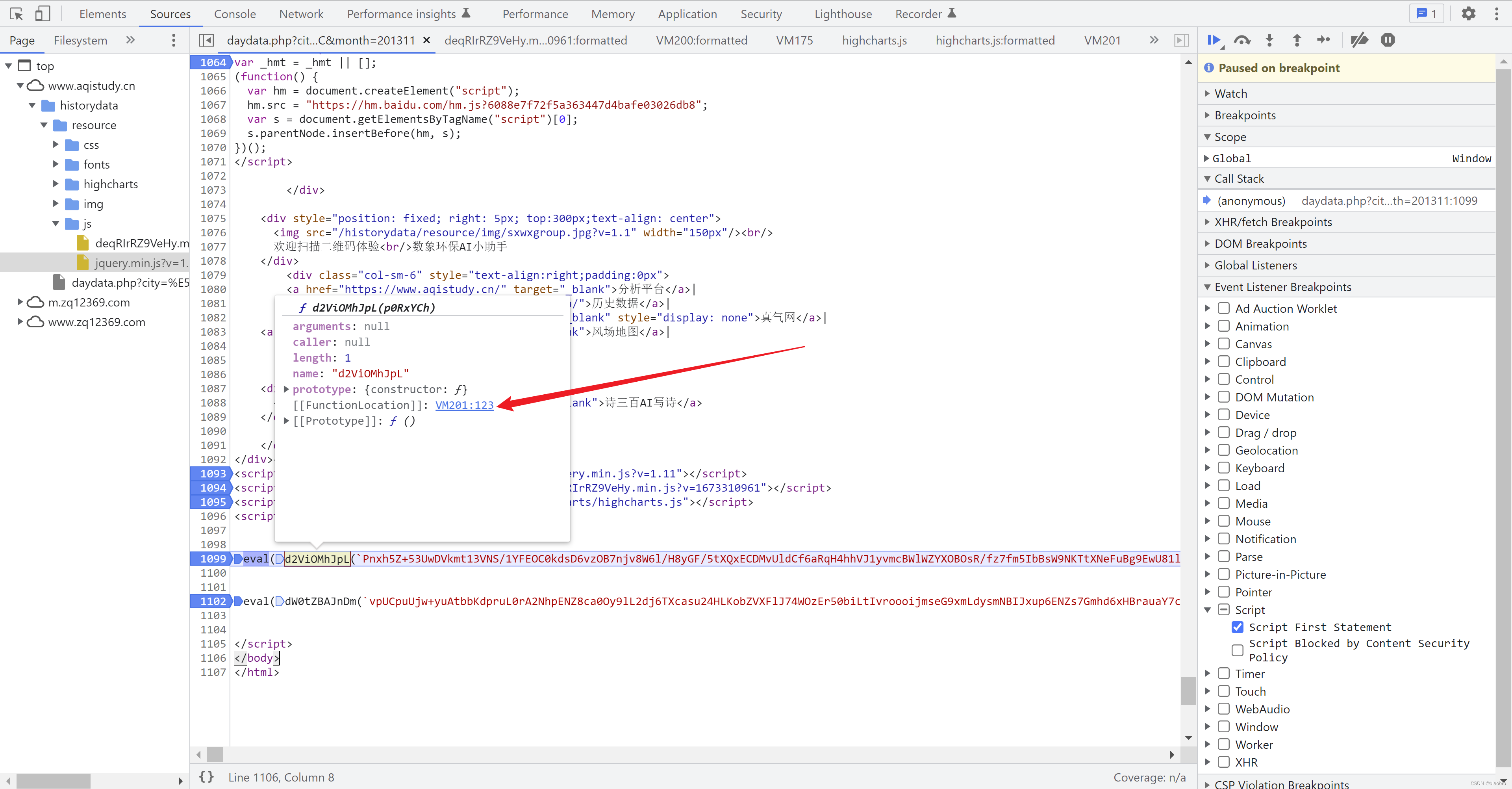
- 我们在5.1 第1099 行位置,按下F11,进入AES.decrypt 函数内部的开头处。在return 那行打上断点,然后F8 执行(第124 行这个是固定 decrypt 逻辑,没什么好研究的),你可以看到结果是1段字符串形式的新的eval(function...()) 代码。
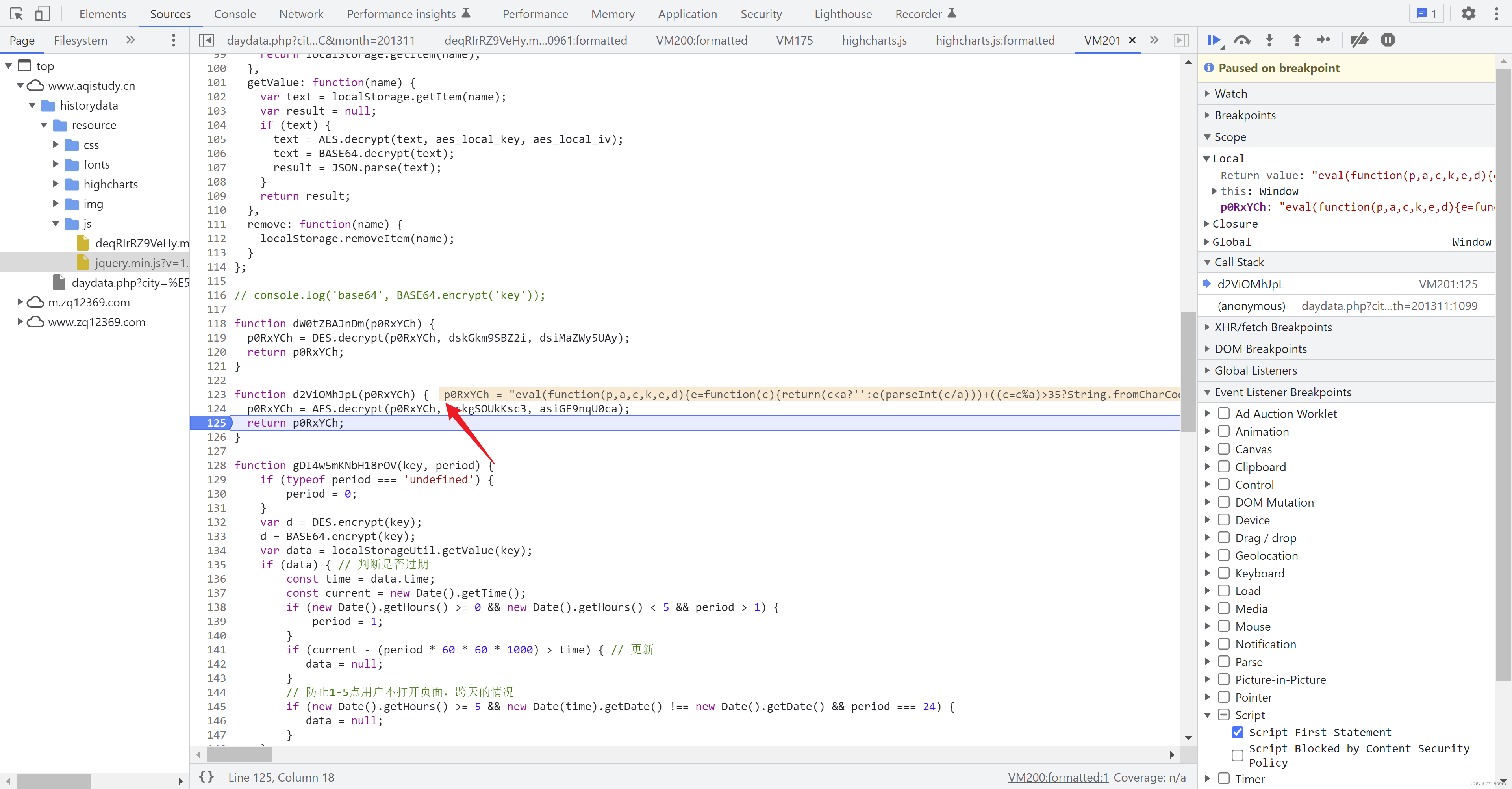
- 继续F11,会回到daydata.php 的5.1 处,然后继续F11,会进入到新生成的这个 eval 内部。在return 处打上断点,F8 执行。
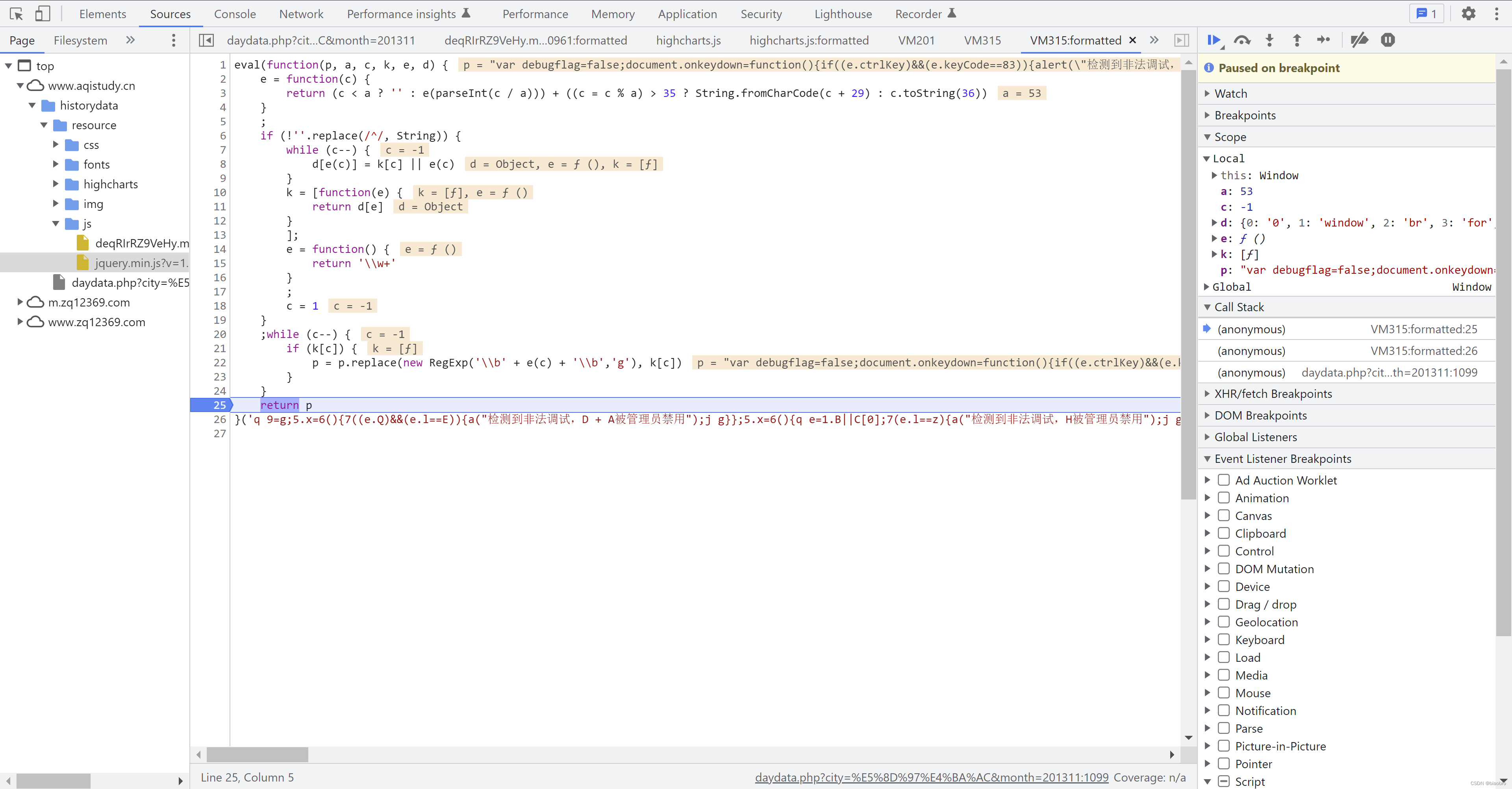
- 把 p 复制出来,看看我们得到了什么。这回是真的眼熟了,前面困扰我们那么久的非法调试处理逻辑,就是在这儿。 可以看到有F12、右键、Ctrl+S, 以及窗口大小变化的处理逻辑。但是哈但是,因为我们最终是通过 python 代码去直接请求接口获取数据,这些限制都不会触犯到,所以这里的代码可以跳过
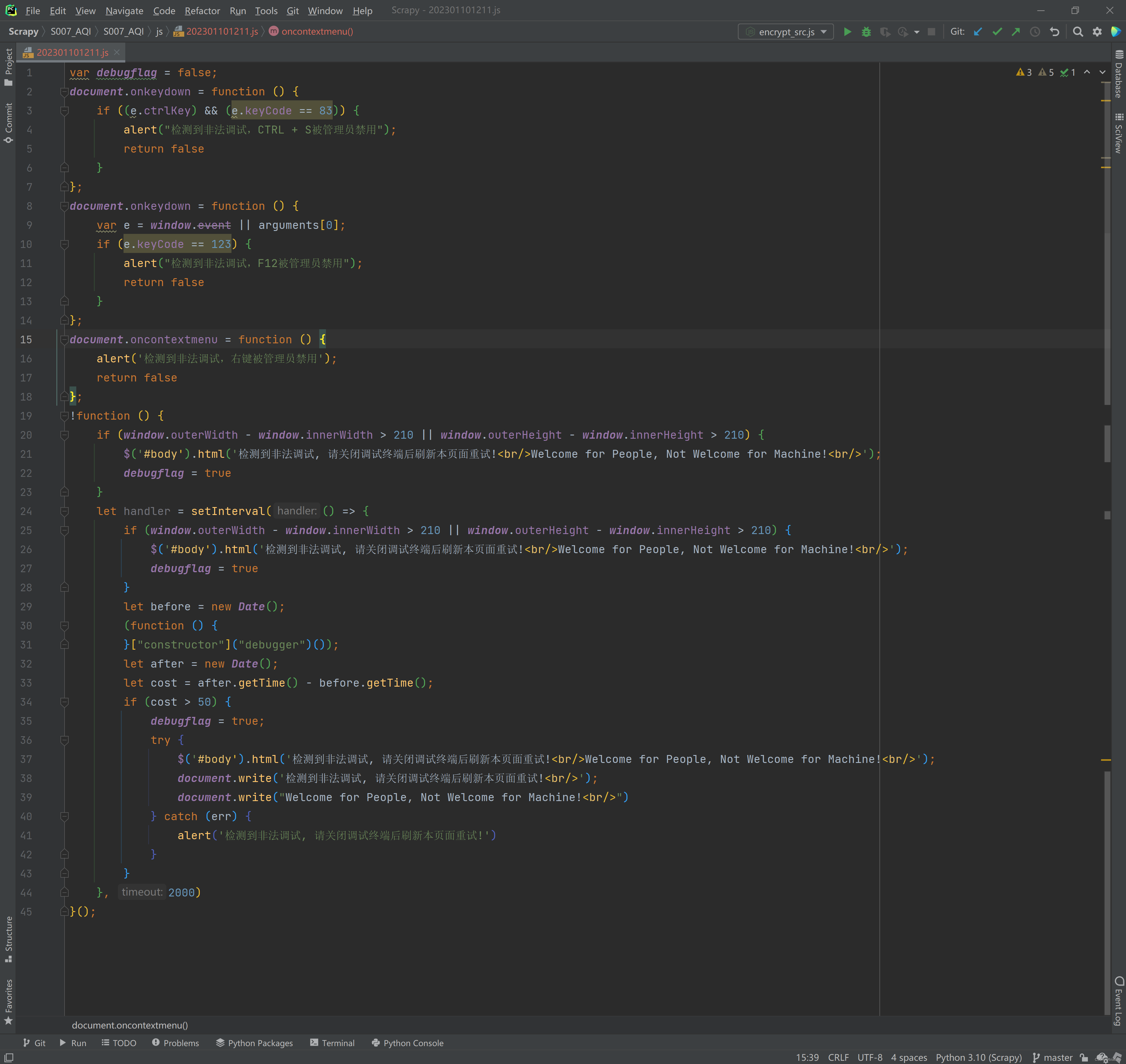
- 继续F8,程序终于来到了最后1个部分,5.2 第 11102 行。在这里按下 F11,进入到DES.decrypt 函数内部的开头处。还是在return 打上断点,看看结果是什么。在这里调试窗口已经能直观看到结果,或者继续F11 进入 decrypt 后代码片段,我们把他命名为 数据获取和展示.代码,
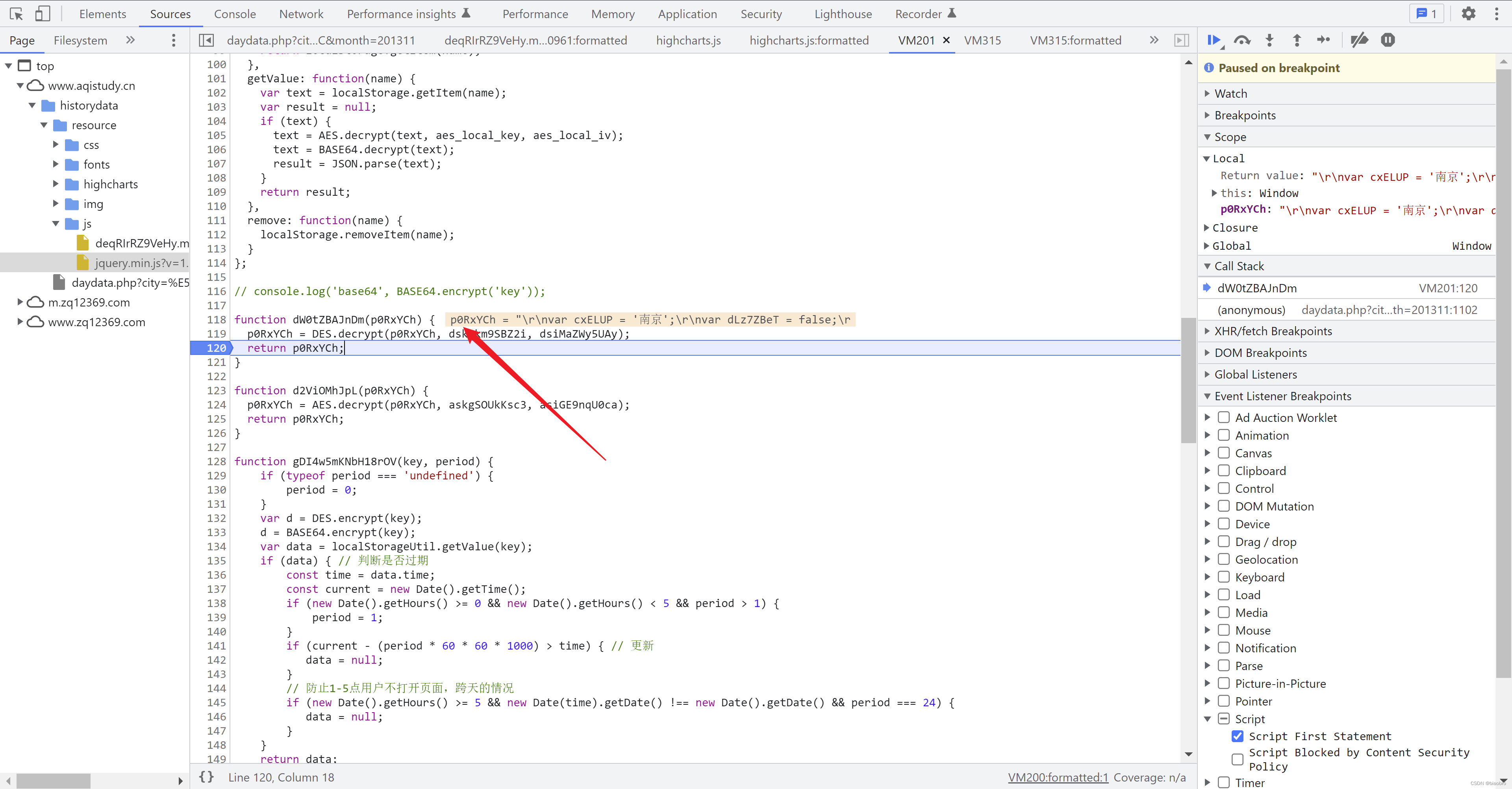
- 我们把这部分代码复制出来,也是很长一段(技巧:在Pycharm 中可以用 Ctrl + Shift + 加号或减号,将代码快速收起或展开),但是对我们的目标来说没有什么用。为什么呢,先来看看他都有哪些部分
- 第1部分,几个参数,包括我们要访问的城市以及月份,还有接口名称("GETDAYDATA",这应该是唯一有用的信息)
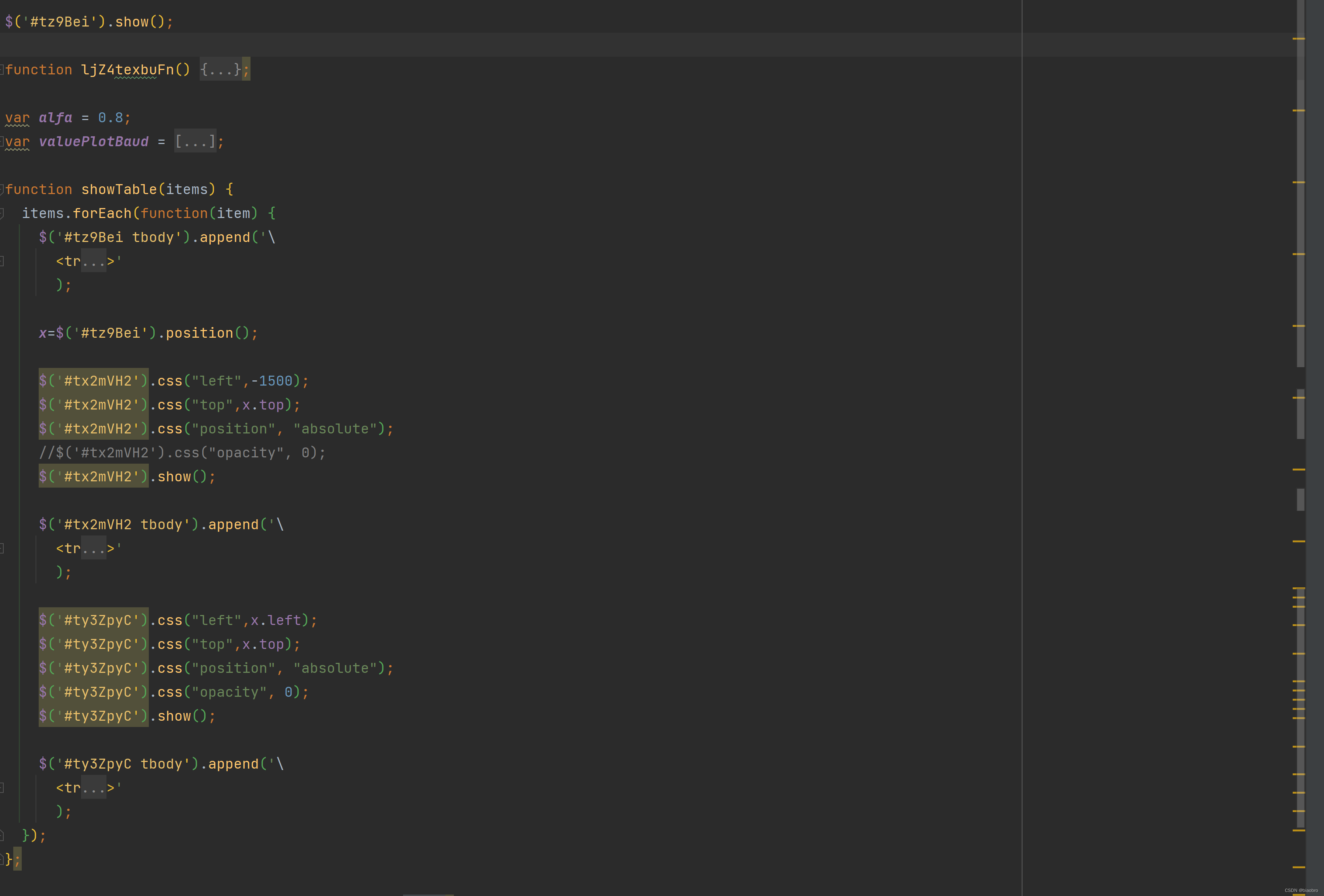
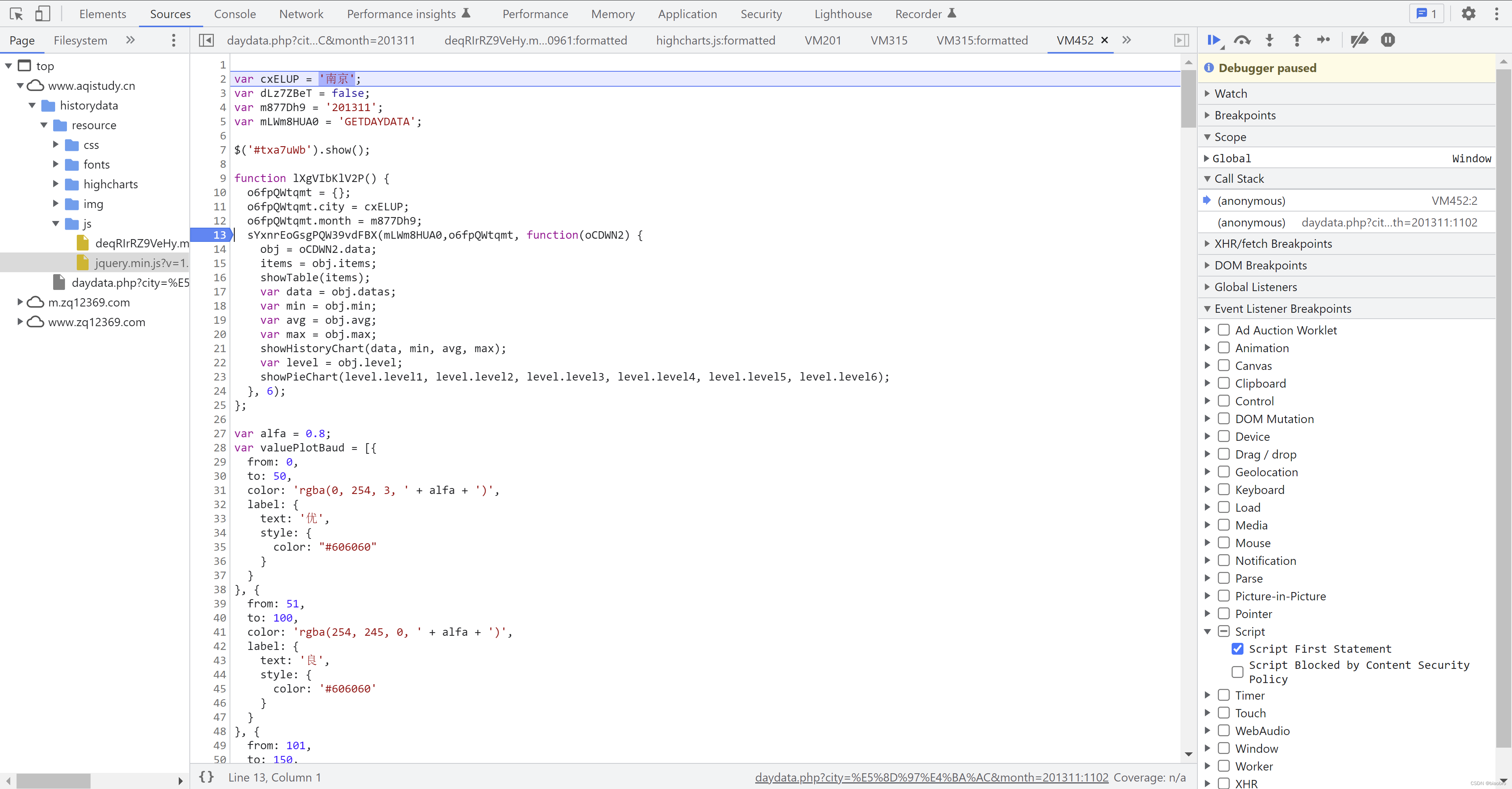
- 第2部分,本文刚开始的时候我们提到,虽然页面只展示1个表格,但是在 daydata.php 源代码中发现了3个 Table 标签,到底是怎么玩儿的 —— 就是通过这里的 $('#txa7uWb').show() 来控制的
- 第3部分,这个 function lXgVIbKlV2P() 对参数进行封装,然后调用在 终极数据编码和解码以及发送请求.代码 得到的发送 ajax 的函数sYxnrEoGsgPQW39vdFBX() ,得到返回后提取其中的 items,然后调用showTable、 showHistoryChart 和 showPieChart 函数,将数据展示
- 接下来是展示函数的实现细节,图形化展示部分有调用到前面提到的 highchart
- 倒数第2个,也是我特别注意到的部分,checkwebdriver 这个函数,里面有些检测 window.navigator 的逻辑,也是用来反爬的 —— 如果使用Selenium,可能会触碰到这个限制
- 最后这部分,判断开头定义的变量(值为False) 和 checkwebdriver 的返回,决定是否调用 function lXgVIbKlV2P()
- 回到开头,为什么说这部分代码没用,
- 首先我们目的是获取数据,不关心图形展示。
- 其次接口名称虽然有用,但是名称固定(到目前为止没有发现有变过),记下来就好,请求哪个城市哪个月份的数据我们自己肯定是知道的,所以,参数我们自己封装就好。如果某天发现接口名称也开始变化了,那就把这个文件抓出来提取,也能来得及
- 调用包含 ajax 请求的函数,从哪里调都行,没必要必须从这个代码里开始
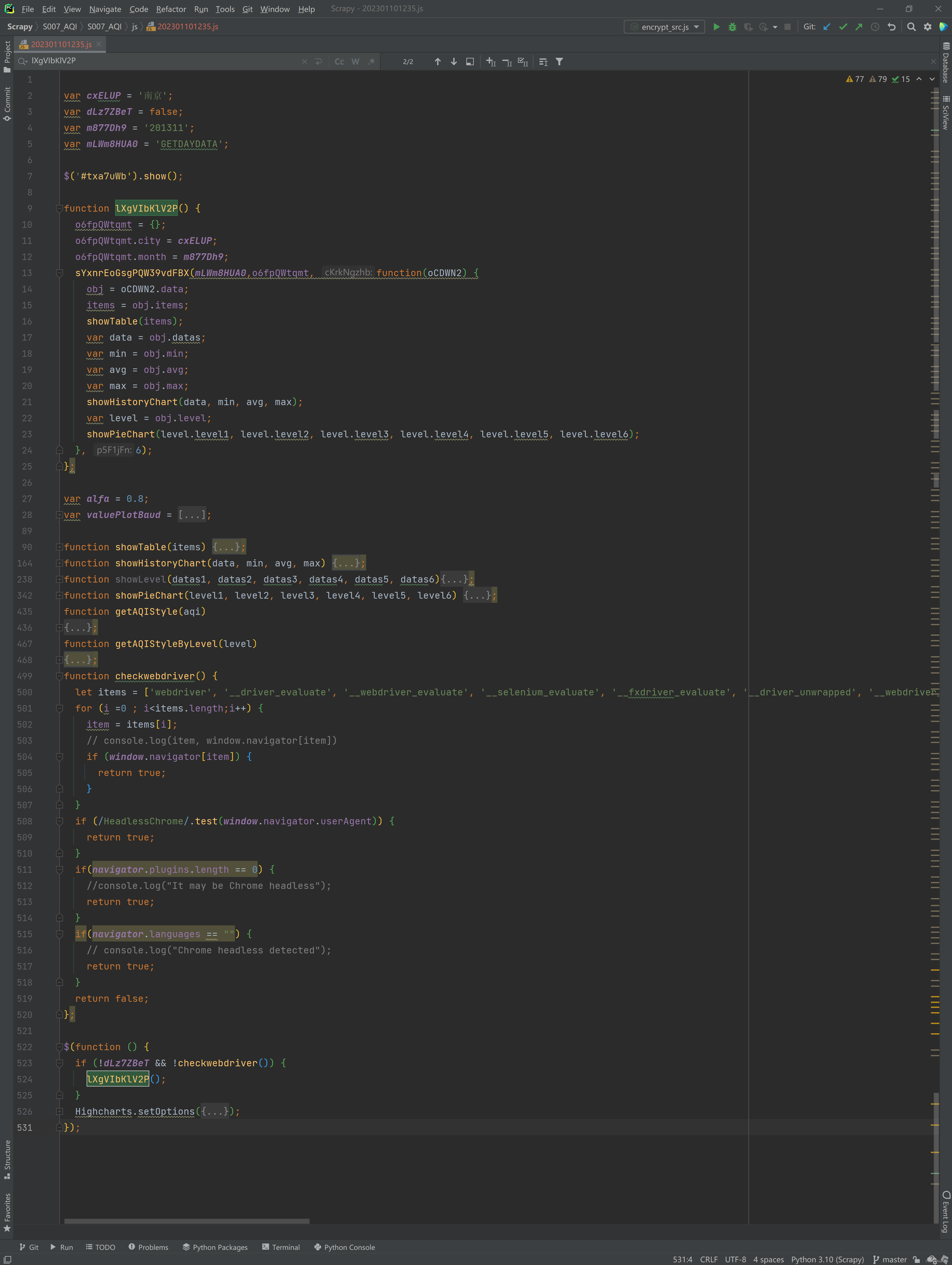
- 到这里,整体的逻辑已经梳理完成。我们继续按下F8,把第5.2 这段代码跑完,可以看到他回到了 终极数据编码和解码以及发送请求.代码 得到的 ajax 函数这里,发出了ajax 请求
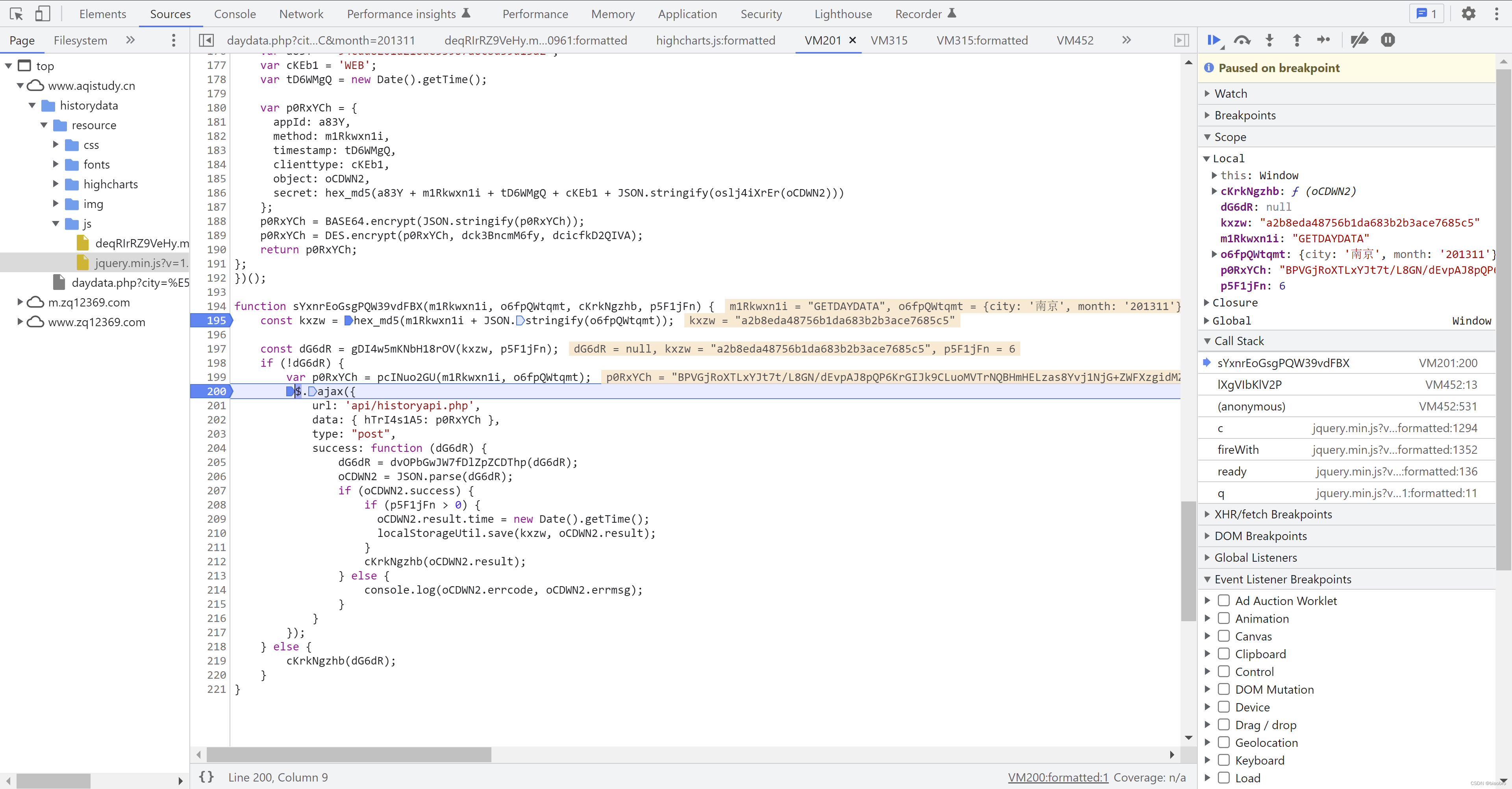
- 并且成功拿到了数据 —— 为了截图,我重新跑了一遍 —— 关注逻辑,忽略变化的函数名和变量
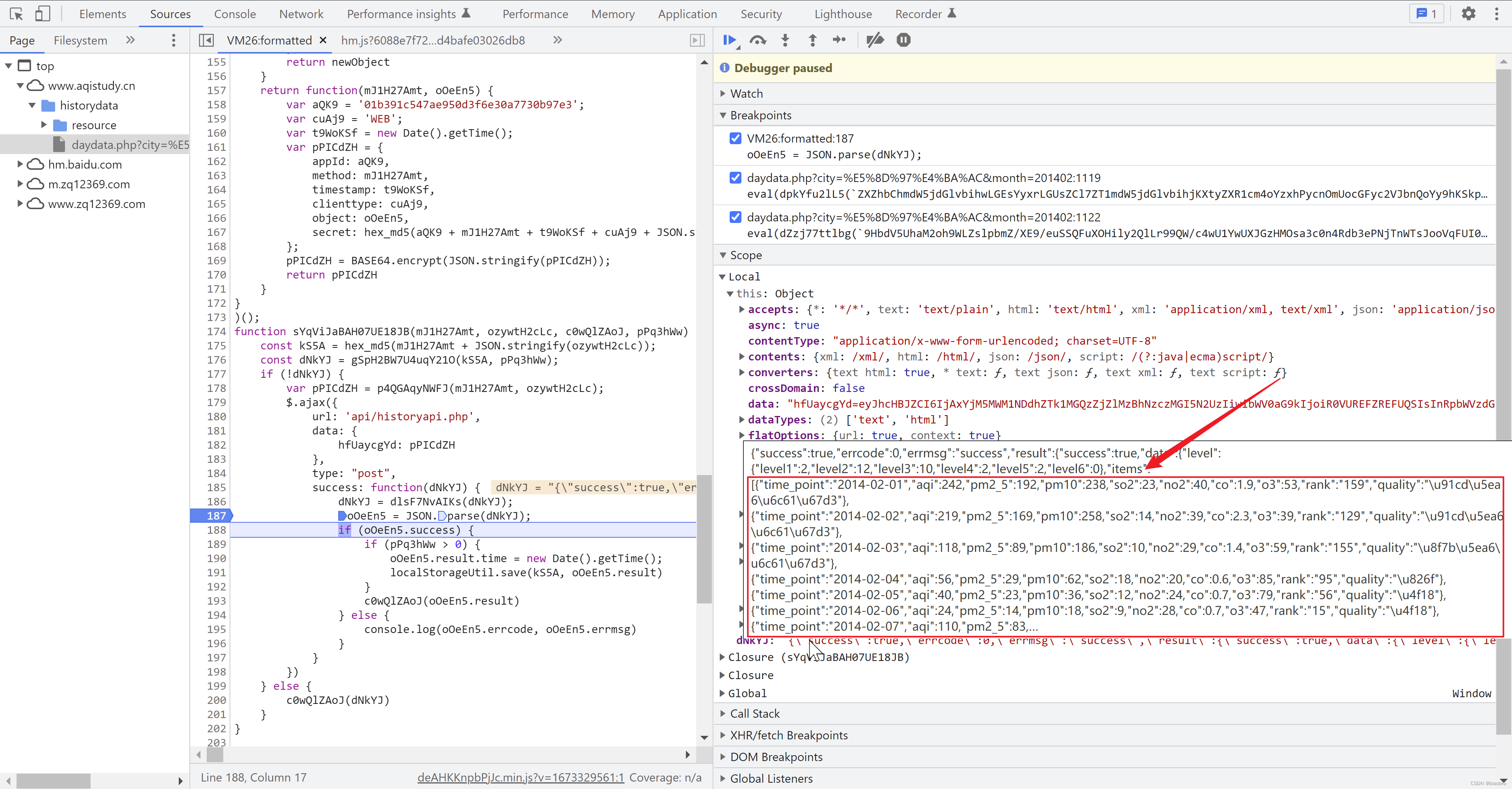
- 在 network 栏中也看到发出的请求,其中method 为 POST,payload 为加密后得到的 data: { hTrI4s1A5: p0RxYCh }。但是Response 没展示,不知道为什么,不过也是不重要了,无关大局,毕竟我们已经拿到了数据
- 到这里,网页代码逻辑分析就做完了,很长,很复杂。再一次向该网站的程序员致敬。也感谢我没有放弃。
Python 实现
你说都已经把网站逻辑研究到如此透彻了,实现起来还不是手拿把纂,轻而易举?但实际上在Python 实现上花的时间并没有比研究网站逻辑更少,而且后期还有很多边实现,边回头重新研究的过程,我只能说:行百里者半九十吧,永远不要想当然,细节是魔鬼。Scrapy 用法不是我这篇文章的重点,我只讲爬取逻辑实现好了
- 第1步,访问城市列表页面,用 xpath 得到所有城市,以及对应的url,请求其中1个 —— 这里再次提醒,最好不要一次性获取全部url_cities 的数据,否则伤害对方网站服务器,你自己也很危险!!!
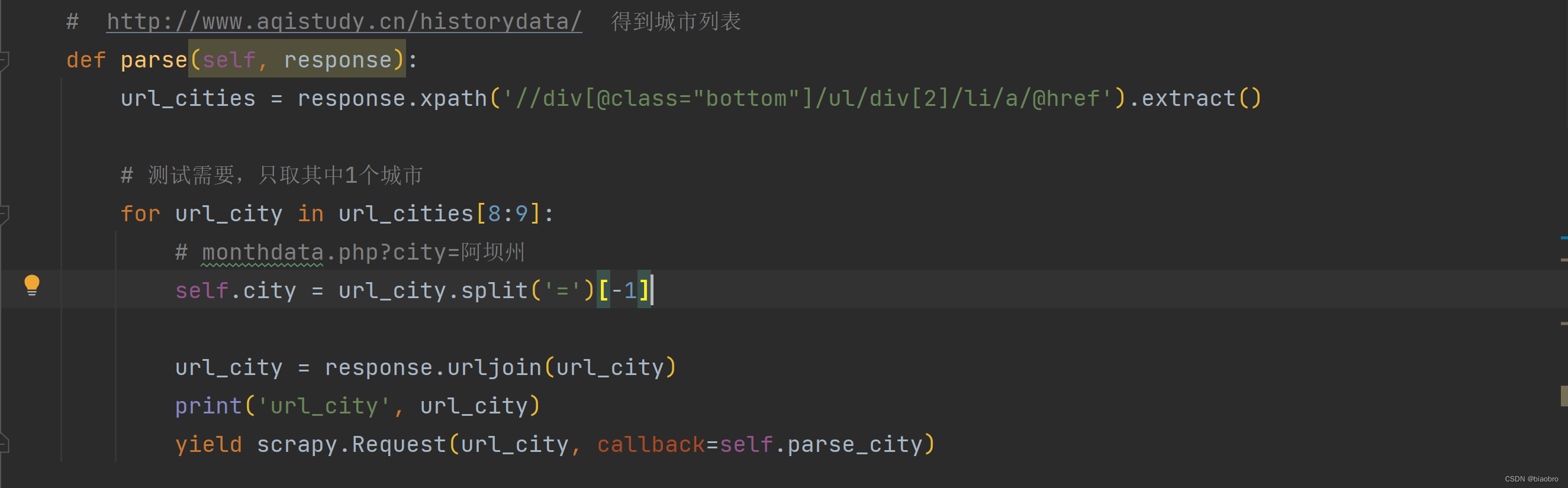
- 第2步,根据得到的城市页面,用 xpath 匹配出月地址,请求其中1个 (他提供的时间范围涵盖了从2013年12月开始到现在)
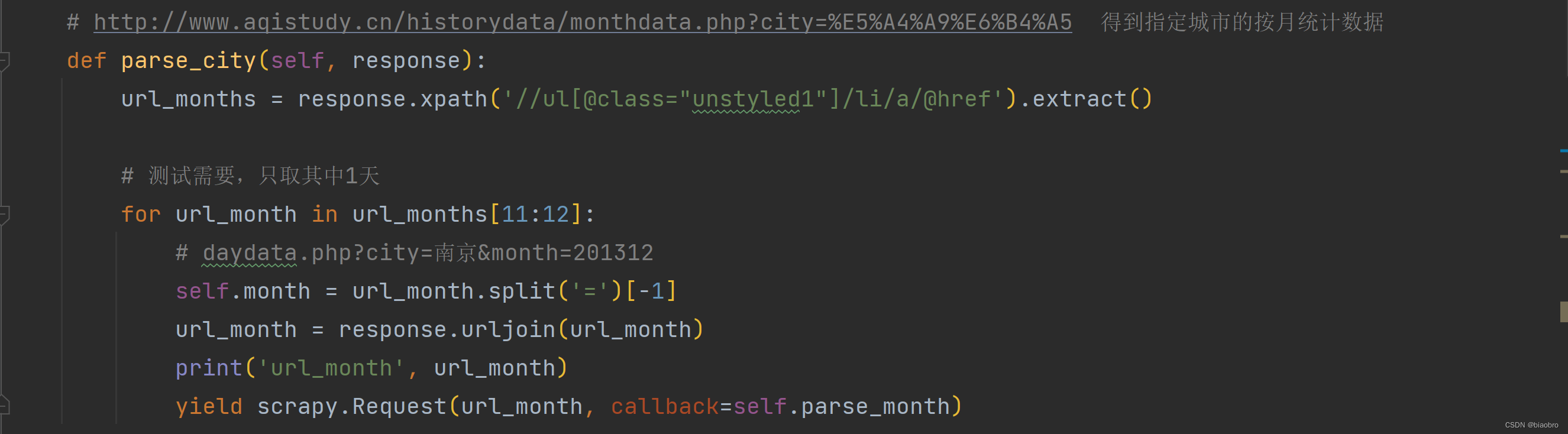
- 第3步,在得到的 日历史数据页面,也就是 daydata.php 页面上,用 xpath 提取到2个 js 文件的地址(内容固定的 jquery.min.js 和 内容变化的 js)为了后续使用方便,对内容会变化的 js 文件地址做了解析,将v后面带的时间戳格式化为本地时间,然后拼接上原始的随机字符串,作为保存到本地时的文件名。 在这里会通过两个 yield ,发出对两个文件的 Request,据说(待确认)Scrapy 的执行是异步的,所以不确定这两个 Request哪个会先得到响应
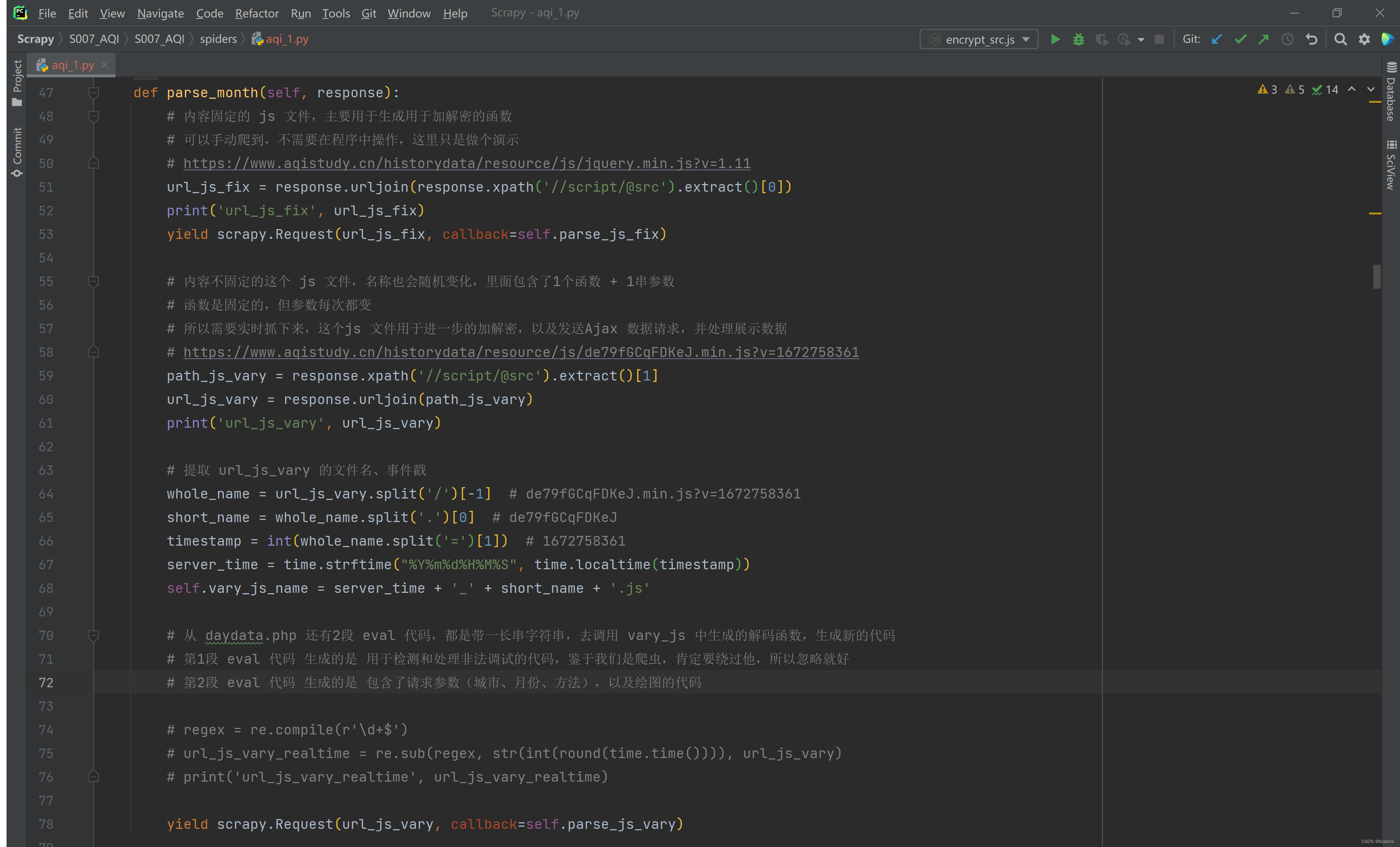
- 第4.x 步,解析得到的 jquery.min.js 文件,将其中的5个 eval 函数部分提取出来执行,得到结果并写入本地文件。如下图1
- 这里显示用正则匹配得到5段 eval ,然后执行
- 执行用到了 ex2js —— 在Python 中执行 js 代码的库,虽然2018年就不维护了,但是还能用,而且很好用没出错。我还尝试了另1个相对较新的库 js2py,一些简单的测试代码可以跑,但对于本案例中遇到的总是大段大段的 js 不灵,也或许还是我姿势不对。 ex2js 和 js2py 有着本质区别,前者是在 node.js 环境中执行,后者是转换成 py 后执行,所以后来放弃 js2py。
- 通过1个计数器控制跳过了第2-4段我们最终不会用到的 eval,只处理第1段 和 第5段
- 最终得到的文件 jquery.min.js 如下图2
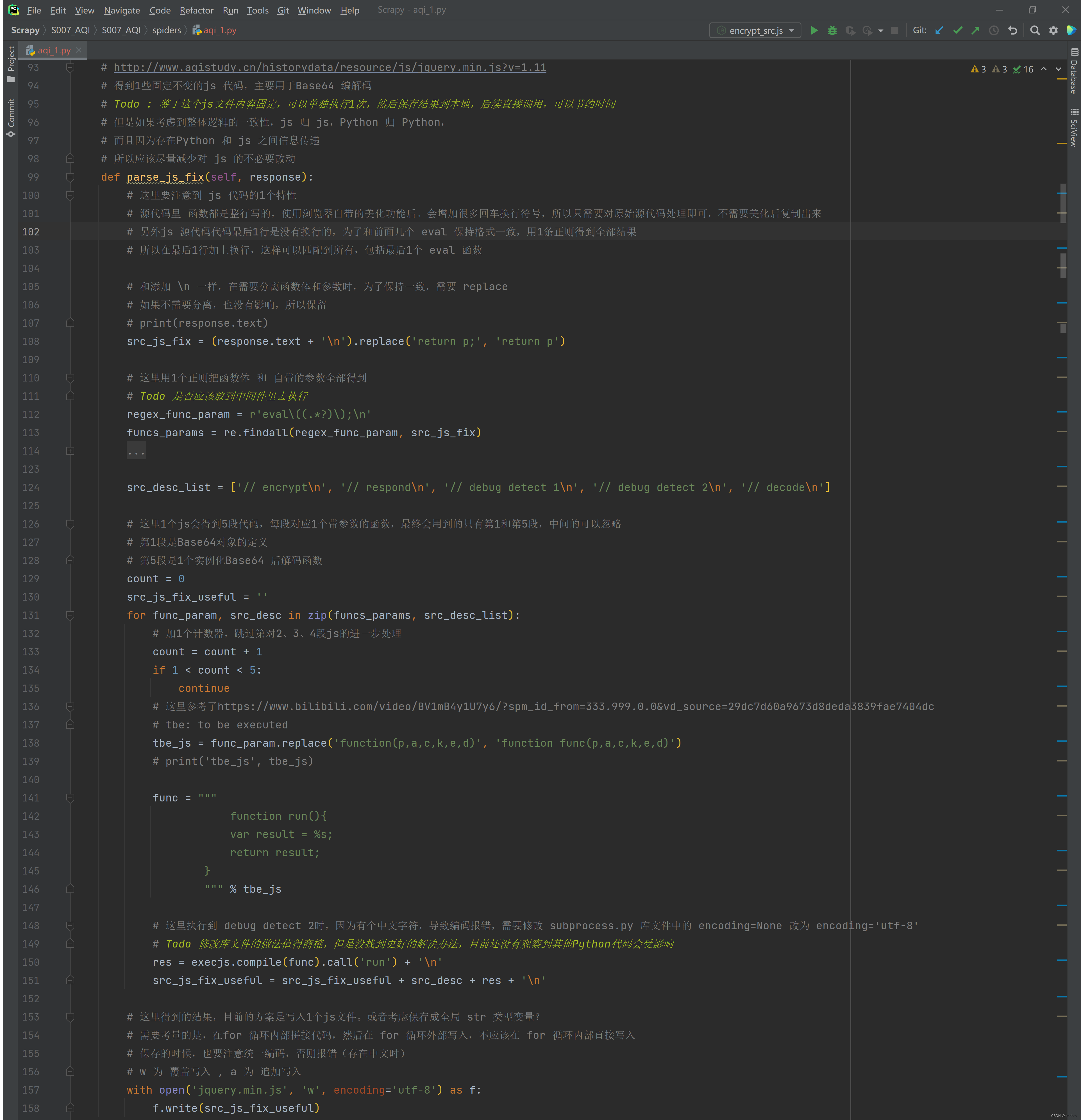

- 第4.y 步,解析得到的第2个 js 文件,这里是实现过程中我耗费时间最多的部分
- 第0步 将前面拿到的 jquery.min.js 读进来,后面会用到
- 第1步 因为拿到的内容是 eval(function()),所以还是需要通过正则提取出eval 内的部分,然后替换函数名称 —— 转换成可以本地执行的形式,然后执行
- 第2步 前面分析网站逻辑时也提到了,第1步执行结果可能是3种不同的形式,所以要判断,如果是 dweklxde(str...) 或者 dweklxde 嵌套的形式,还需要进一步执行 dweklxde,得到最终的 终极数据编码和解码以及发送请求.代码
- 终极数据编码和解码以及发送请求.代码 拿到后,
- 保存到本地1份(这个操作可选,为了观察和分析的目的,建议保留)
- 从代码中通过正则匹配出我们将要用到的:对参数进行编码的函数名称,data 字典参数中的key,以及对结果进行解码的函数名称 —— 研究正则也耗费了大量时间,因为有时候得到的代码是完整1行,有时候又是格式化后的N行(包含了空格以及换行),需要找到1个能同时适用的表达式。这里推荐在线工具 regex101,很好,很快,很强大
- 将编码函数和参数,拼接成字符串,传入 ex2js 执行,就会得到编码后的,用在 data 字典参数中的 value
- 组装ajax 请求用到的 url,data ,同时利用Scrapy 的meta 机制,将解码函数名称向后传递。然后临门一脚,发出最终的获取数据请求 —— 这里有特别需要注意的2个巨坑
- 必须使用 FormRequest,而不是普通的Request,
- 参数的封装形式,该加引号的地方,1个都不能少
- 这里需要补充的1点是,为什么没有直接使用 js 代码内的 ajax 函数,而是在 Python Scrapy 实现。如果你在网页端单步调试的话,会看到这个 ajax 是在 jquery.min.js 文件中,而且他依赖浏览器的 window 和 document,是不能在本地 js 中直接调用执行的。我也尝试了通过本地 js 代码使用Fetch 方法 和 Formdata 发送请求,也成功得到了数据,但是1个是改动挺大,另外数据还是要回到Python,与其这样,还不如直接使用现成的 Scrapy FormRequest
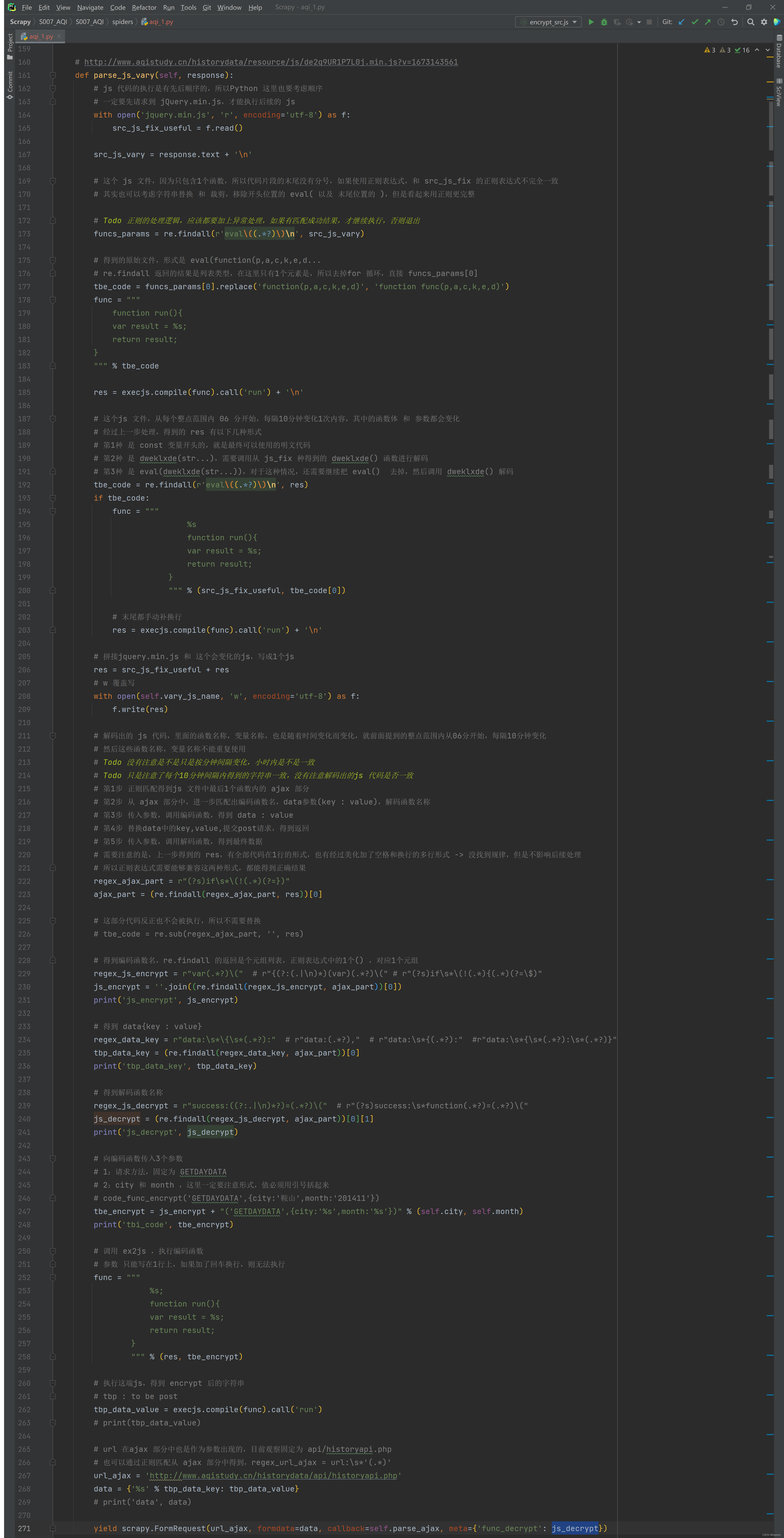
- 第5步, 对 ajax 请求返回的数据进行解码。
- 第1步 解码也是通过调用 终极数据编码和解码以及发送请求.代码 执行的,所以,还是要先把这部分代码读进来
- 第2步 拼接从 meta 中得到的 解码函数名和参数,得到字符串形式的 js 代码
- 第3步 调用 ex2js,传入这2段代码执行,就能得到最终的数据返回
- 第4步 将返回数据转换成 json,判断是否成功,并解析数据
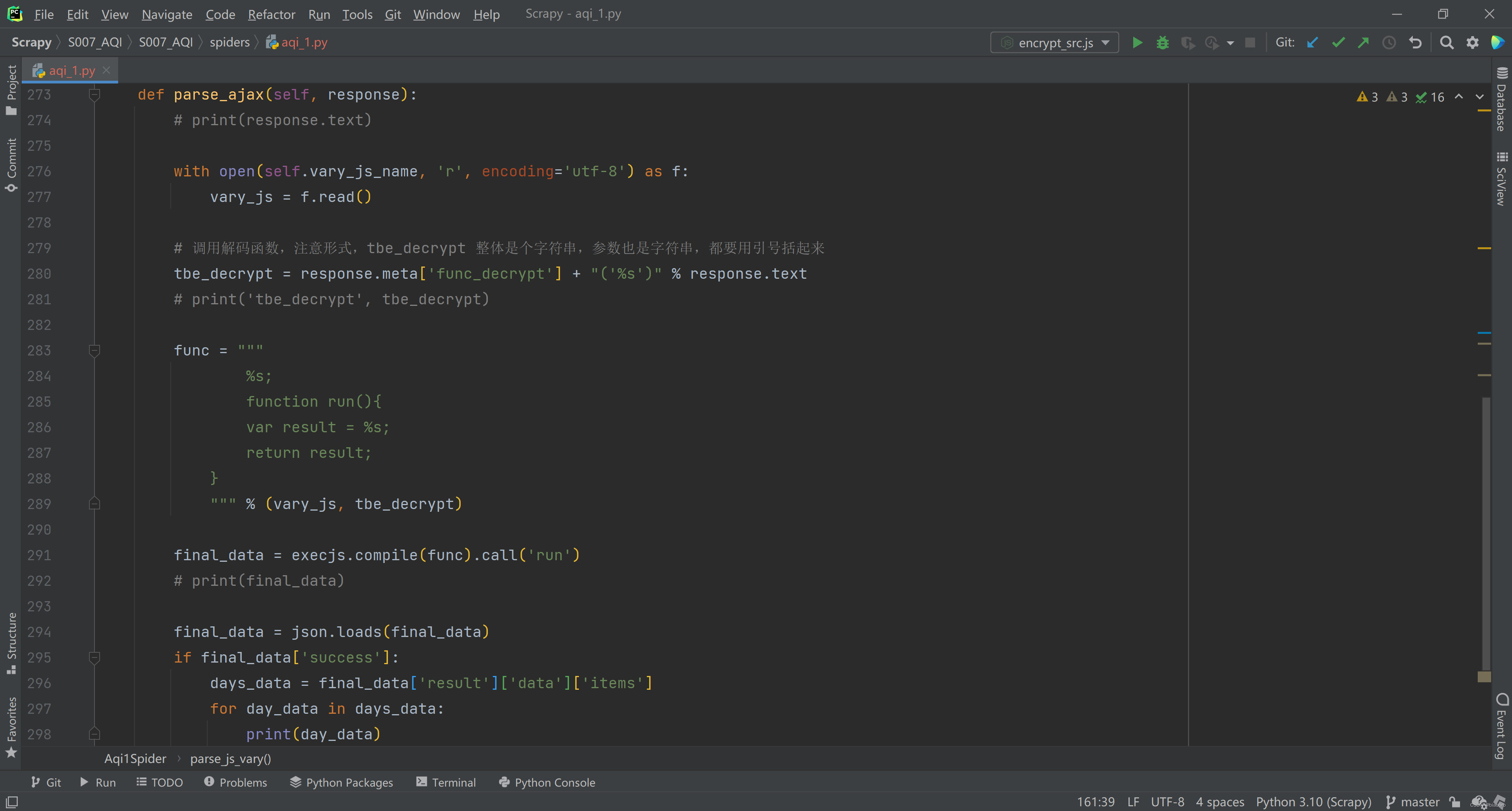
- 第6步,我做到这里就停了,因为已经拿到数据。接下来是写入 json 文件、还是 csv文件,还是写入数据库,可以根据自己的需要,在 Scrapy 的 pipeline 里实现。
成果展示
这里创建的 Scrapy 爬虫名字叫 aqi_1,cd 进入项目目录,scrapy crawl aqi_1 --nolog 运行爬虫,--nolog 是让Scrapy 不输出中间的调试日志。
- 爬取1个城市,1个月份下的数据
- 爬取2个城市,3个月份下的数据
后续 Todo
- 只对比了整点范围内10分钟间隔 js 文件的变化,没注意是不是每个小时同1个分钟间隔内 js 文件是否一致
- js_fix : jquery.min.js 在整个项目过程中,其实只需要爬1次
- js_vary : 随时间变化的这个js,在同时请求多个不同城市、不同月份时,也应该时根据时间间隔来限制获取次数
- 写到最后突然发现,Scrapy 的请求有个重复过滤器,除法显示地增加参数 dont_filter = Ture,否则重复的请求会被过滤,不会发出。这么一看,简直完美