在人工智能领域,强化学习(Reinforcement Learning, RL)一直是实现智能体自主学习的关键技术之一。通过与环境的交互,智能体能够自我优化其行为策略,以获得更多的奖励。然而,当涉及到复杂的人类偏好时,传统的强化学习方法面临着挑战。这些挑战主要源于人类监督信号的不一致性和稀疏性,这使得智能体难以准确地对齐人类的期望。
为了解决这一问题,研究者们提出了从人类反馈中学习的强化学习(Reinforcement Learning from Human Feedback, RLHF)方法。RLHF通过利用人类标注的比较数据来微调大语言模型(LLMs),以更好地与人类偏好对齐。然而,人类标注在评估两个或更多模型输出时可能存在不一致和不可靠的问题。这些问题导致了RLHF中不稳定的奖励信号,而稳定的奖励是成功强化学习的关键。
为了应对这些挑战,本文介绍了一种新的框架——ALARM(Align Language Models via Hierarchical Rewards Modeling),它是首个在RLHF中模拟层次化奖励的框架。ALARM通过整合整体奖励和特定方面的奖励,提供了更精确和一致的指导,特别是在复杂和开放的文本生成任务中。通过采用一种基于一致性过滤和组合多个奖励的方法,ALARM为改善模型对齐提供了可靠的机制。通过在长篇问答和机器翻译任务中的应用,验证了该方法的有效性,并展示了与现有基线相比的改进。
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
论文标题:
ALaRM: Align Language Models via Hierarchical Rewards Modeling
论文链接:
https://arxiv.org/pdf/2403.06754.pdf
ALARM框架的动机与设计
1. 框架动机
ALARM框架的设计动机源于对当前强化学习中人类反馈(RLHF)的限制的认识。这些限制包括人类监督信号的不一致性和稀疏性,这在复杂的开放式文本生成任务中尤为突出。为了解决这些问题,ALARM框架提出了一种整合全面奖励和特定方面奖励的方法,以提供更精确和一致的指导,从而更好地与人类偏好对齐。
在实际应用中,例如长篇问答和机器翻译任务,传统的RLHF方法面临着奖励信号不稳定的挑战。例如,即使是人类专家也难以为复杂任务编写足够好的示范,而从众包平台获得的模型生成对比评价则显示出注解的不一致性和不可靠性。ALARM框架通过筛选和组合多个奖励信号来提供更可靠的模型对齐机制。
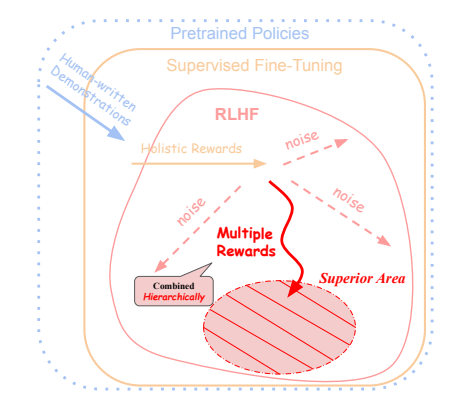
2. 框架设计
ALARM框架的设计基于两个核心思想:首先,通过对不同错误类型的细分,实现更精确和容易的注解;其次,采用分层强化学习中的任务分解方法来克服稀疏奖励问题。
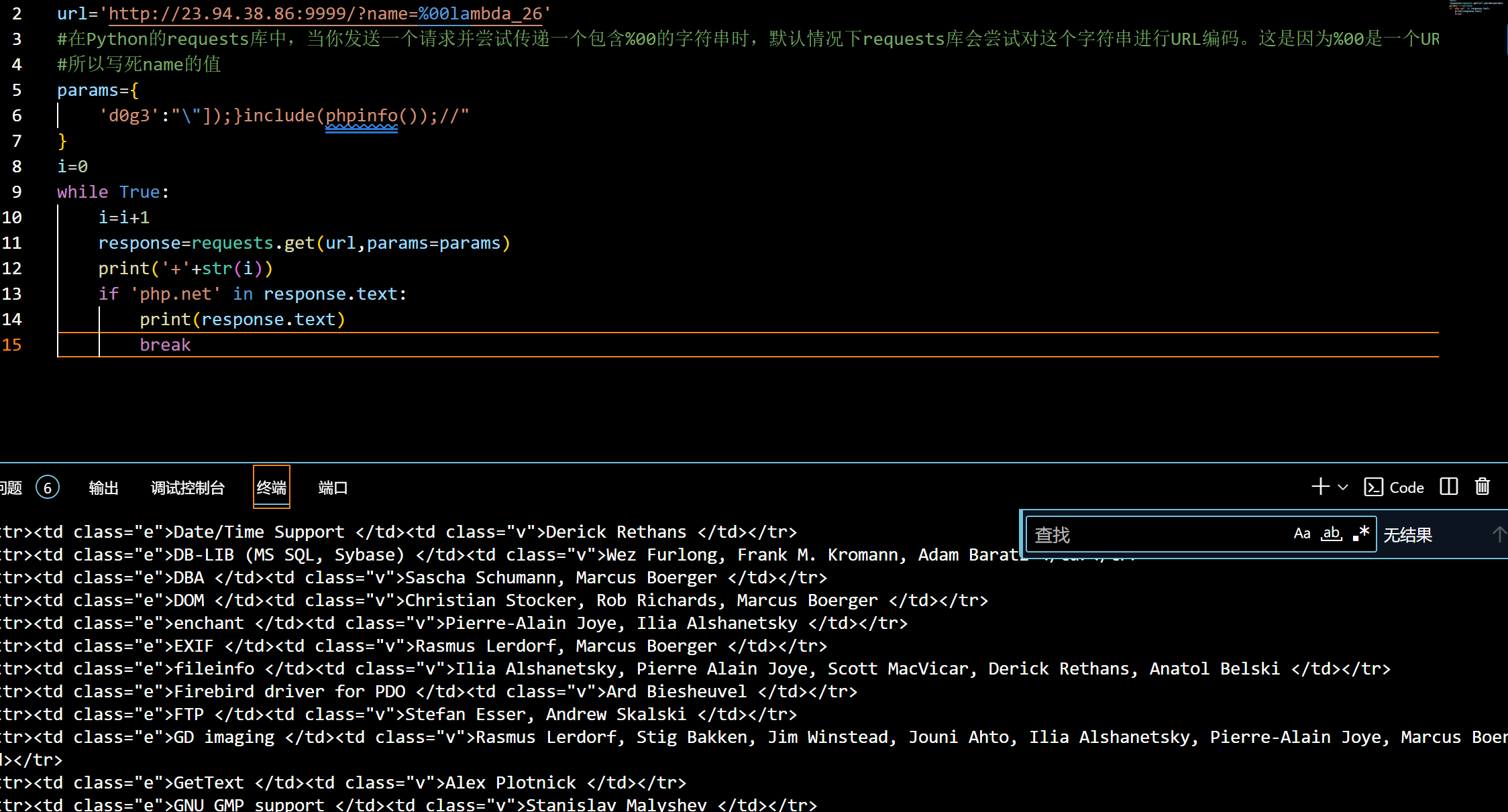
框架的核心是寻求更强的监督信号:仅使用全面奖励很难达到更好地与人类偏好对齐的“优越区域”。因此,ALARM采用分层方式组合多个奖励,以稳定优化方向,更准确和一致地指导模型进入优越区域。
在实际操作中,首先列出与任务相关的多个特定方面奖励,并通过成对比较的方式选择与全面奖励一致性较高的奖励。在RLHF训练过程中,当生成的样本获得高于某一阈值的全面奖励时,选定的特定方面奖励将与全面奖励一起作为整体奖励进行组合。
这些特定方面奖励可以来自于在特定维度上注解的比较数据集上训练的奖励模型,也可以是简单的工具计算指标(如令牌计数),其密度可以在令牌级别或序列级别任意设置。
▲框架图示
层次化奖励建模的核心原理
1. 奖励选择
在特定维度上对模型生成进行评估,而不是评估总体质量,已被证明对奖励建模来说噪声更小、更准确。因此,为了获得更准确和一致的监督信号,首先直观地列出与特定任务相关的多个特定方面奖励。然而,人类偏好复杂,不同分解的方面相互联系,甚至可能相互冲突。为了平衡它们,通常的方法是加权求和方法,这需要基于训练期间的表现或成对比较的准确性来为每个特定方面奖励仔细选择权重。
然而,这种方法仍然存在过度优化问题,即模型丢失了来自每个单独特定方面奖励的个体信息,无法将组合奖励中的变化归因于任何一个方面。因此,ALARM框架通过丢弃冲突的奖励,选择与全面奖励最一致的奖励,以此来解决这一挑战。
2. 分层奖励建模
分层强化学习在广泛的决策任务中取得了显著进展,它将复杂且具有挑战性的优化目标分解为更简单的子任务。与此相反,现有的RLHF工作通常采用简单的奖励策略,即线性分配单一的全面奖励或固定组合的特定方面奖励,这不仅在长期优化中带来稀疏奖励的问题,而且忽视了全面奖励与特定方面奖励之间的紧密关系。
基于这些动机,ALARM提出了一种新方法,利用全面和特定方面奖励。通过这种方式,将语言模型与人类偏好对齐的优化目标视为一个具有挑战性的决策任务,并将这个任务分解为两个较不复杂的子任务,这两个子任务应该依次解决:
-
直接遵循全面奖励,直到模型生成获得高全面奖励,表明生成物在较高水平上符合人类偏好;
-
优化全面奖励和特定方面奖励的组合,作为整体提供更准确和一致的监督信号,指向优越区域。
与整个训练过程中都应用组合奖励的简单加权求和方法不同,ALARM方法更为微妙。主要遵循全面奖励的监督,并在仅依靠全面奖励无法达到优越区域时,轻轻转动方向盘。
应用场景与实验设置
1. 应用场景
ALARM框架通过整合整体奖励和特定方面的奖励,解决了当前对齐方法中人类监督信号不一致和稀疏的问题。该框架在复杂和开放的文本生成任务中,特别是长篇问答和机器翻译任务中得到了应用和验证。
2. 实验设置
2.1 任务设置
在长篇问答(QA)任务中,使用了QA-Feedback数据集,初始策略模型为经过监督微调的T5-large,以及三个细粒度的奖励模型。这些奖励模型分别代表不同的错误类型,在不同层次上进行预测。
在机器翻译(MT)任务中,使用了Europarl数据集,该数据集包含欧洲议会会议的记录。初始策略模型为mT5-base,并在训练集上进行了监督微调。此外,列出了三个特定方面的奖励,包括语法奖励、语言信心和可读性奖励,这些奖励通过工具包计算得出。
2.2 奖励选择
在奖励选择方面,首先列出了与任务相关的几个特定方面的奖励。然后,通过成对比较来计算这些候选奖励与整体奖励的不一致性,以筛选出最能辅助整体奖励的奖励。例如,在长篇问答任务中,事实性奖励的不一致性最低,因此被选为层次化奖励建模的“副驾驶”。在机器翻译任务中,语法奖励因其较低的不一致性和更好的胜率而被选中。
2.3 奖励建模
在奖励建模方面,对整体奖励进行z标准化,并使用sigmoid函数对特定方面的奖励进行正值转换,以确保层次结构。设置了一个阈值,当生成的样本获得高于该阈值的整体奖励时,将整体奖励与选定的特定方面的奖励结合起来。在强化学习训练中,采用纯采样策略,并使用贪婪解码进行开发集和测试集评估。
实验结果与分析
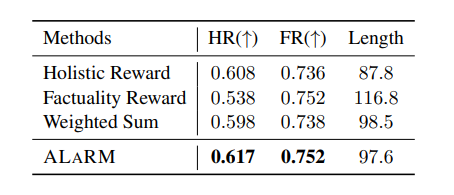
在长篇问答任务的测试集上,ALARM在整体奖励的平均值和事实性率方面均显著高于其他方法。除ALARM外,仅使用整体奖励的方法获得了最高的整体奖励值,而仅使用事实性奖励的方法获得了最高的事实性率。权重求和方法则平衡了这两个奖励。在不同模型之间的成对比较中,ALARM在所有三种不同的度量标准下均表现最佳,这进一步表明ALARM提供了比其他方法更强的监督信号。
在机器翻译任务中,ALARM在整体奖励的平均值、语法错误率和gpt-3.5-turbo评估方面的结果也强烈支持了该框架的有效性。
消融研究:验证ALARM组件的重要性
1. 无选择的消融研究
在不进行奖励选择的情况下,研究者对ALARM进行了一系列实验,将初始奖励池中的每个奖励分别应用于两个任务。主动选择的奖励在整体奖励和gpt-3.5-turbo的评估中表现出领先的性能,这证明了奖励选择的有效性。
此外还观察到,某些奖励在两个评估者的评分中存在冲突。研究者认为这是由于整体奖励的偏见和缺陷造成的,例如持续忽视或过度重视某些方面,这超出了本文的讨论范围。
2. 无组合的消融研究
为了检验ALARM是否通过利用整体奖励和特定方面奖励提供了更准确和一致的监督信号,研究者比较了单独使用各自奖励的方法。结果显示,ALARM在两个维度上都一致地取得了更好的结果。
3. 无层次结构的消融研究
研究者将ALARM框架与传统的加权求和方法进行对比,以突出层次结构的重要性。加权求和方法的结果反映了整体奖励和特定方面奖励之间的妥协,限制了其在两方面都表现出色的能力。相比之下,ALARM利用层次化奖励建模提供了更强大的监督信号,从而在两个维度上都提高了性能。
结论与未来展望
本文介绍了ALARM框架,这是首个在强化学习中从人类反馈(RLHF)中建模层次化奖励的框架,旨在提高大语言模型(LLMs)与人类偏好的一致性。ALARM框架通过整合全局奖励和特定方面的奖励,解决了当前对齐方法中存在的人类监督信号不一致性和稀疏性的问题。
这种整合使得语言模型在复杂和开放式文本生成任务中得到更精确和一致的指导。通过在长篇问答和机器翻译任务中的应用,验证了该方法的有效性,并展示了与现有基线相比的改进。
1. 研究贡献
-
首次提出在RLHF中层次化建模全局和特定方面奖励的框架;
-
探索如何进行奖励选择以减少奖励冲突;
-
通过全面的消融研究和分析,证明了ALARM在追求更准确和一致的监督信号方面的有效性,并为可扩展监督在AI对齐中的潜力提供了启示。
2. 未来工作
尽管ALARM框架在实验中展示了其有效性,但研究者们认识到仍有一些挑战和限制。
-
首先,该框架需要为每个任务专门设计奖励,这在扩大应用场景时构成了挑战。
-
其次,需要改进奖励的自动选择机制。在评估中使用了OpenAI的API,这可能会给常规用户带来额外的成本和响应时间的不稳定性。
3. 伦理和透明度
研究没有涉及直接的人类或动物主体,并且没有明显的伦理问题。使用的数据集和工具包,如QA-Feedback、Europarl、Textstat、Lingua和LanguageTool,都是公开可用的。已经采取措施确保我们的研究透明可复制。确认研究和方法论没有涉及有害的实践和潜在的误用。致力于在工作中维护最高的诚信和伦理责任标准。
综上所述,ALARM框架为强化学习提供了一种新的视角,即通过层次化奖励建模来提高语言模型与人类偏好的一致性。期待未来的研究能够在该工作基础上,进一步探索和扩展这一领域,特别是在提高奖励选择的自动化和减少对外部API依赖方面。此外,鼓励研究社区继续关注AI对齐的可扩展性问题,以实现更广泛的应用和更深入的人类偏好理解。