word2vec 学习笔记
- 0. 引言
- 1. Word2vec 简介
- 1-1. CBOW
- 1-2. SG
- 2. 实战
0. 引言
最近研究向量检索,看到有同事使用 MeCab、Doc2Vec,所以把 Word2vec 这块知识学习一下。
1. Word2vec 简介
Word2vec 即 word to vector,顾名思义,就是把词转换成向量,该方法在 2013 年由谷歌公司提出并实现。
笼统地说,Word2vec 的原理是根据词语的上下文来提取一个词的语义,在统计上,词义相同的词的上下文也应该比较类似。例如"猫"和"狗"都是人类的宠物,可能会和"喂"“可爱”"粘人"之类的词一起出现,通过这样的规律,我们可以得出"猫"和"狗"这两个词的相似性。
该方法使在深度学习中使用很大的词表成为可能。
Word2vec 可以解决 One-Hot 表示法的词向量维度高且无法体现词语意义的问题,也就是说 One-Hot 表示法的 0 和 1 是无规律的,而 Word2vec 产生的词向量能体现词语间的关系。
该方法有以下特点:
- 第一,算法效率高,可以在百万数量级的词典和上亿规模的数据上训练;
- 第二,得到的词向量可以较好地反映词间的语义关系。
Word2vec 提出两种基本模型:
- CBOW:连续词袋模型
- SG:跳词模型
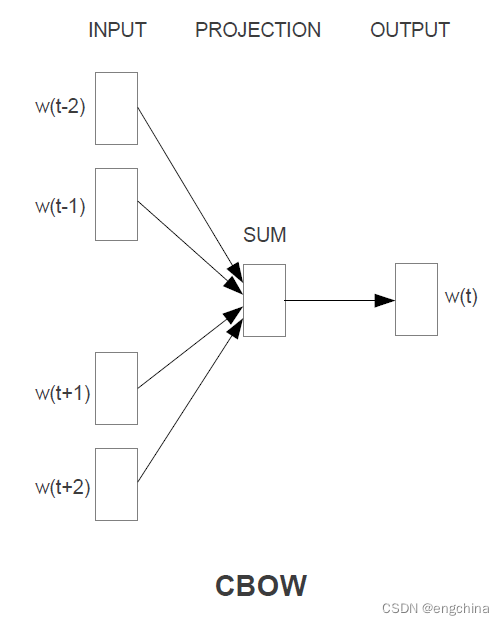
1-1. CBOW
CBOW 即 Continuous Bag-of-Words,是通过一个词的上下文来预测这个词的含义。
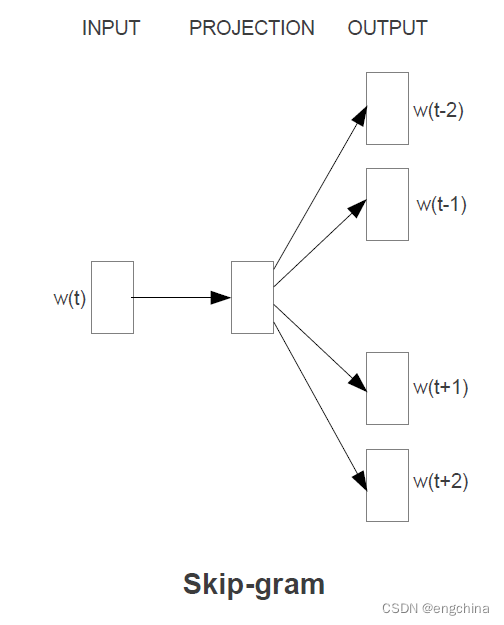
1-2. SG
SG 即 Skip-Gram,是通过一个词语来预测上下文词语。
2. 实战
下面实战的对象语言是日文,如果想尝试中文,请自行搜索其他文档。
安装MeCab,
sudo dnf install mecab
安装词典,
sudo dnf install mecab-ipadic
安装开发包(用于gensim),
sudo dnf install mecab-devel
安装Python绑定,
pip install mecab-python3
安装gensim,
pip install gensim
下载 wiki 记事(日文),
curl https://dumps.wikimedia.org/jawiki/latest/jawiki-latest-pages-articles.xml.bz2
-o jawiki-latest-pages-articles.xml.bz2
整理 wiki 记事,
git clone https://github.com/attardi/wikiextractor; cd wikiextractor
rm -rf .git
vi wikiextractor/extract.py
--- modify
ANCHOR_CLASS = r'[^][\x00-\x08\x0a-\x1F]'
ExtLinkBracketedRegex = re.compile(
'\[((' + '|'.join(wgUrlProtocols) + ')' + EXT_LINK_URL_CLASS + r'+)' +
r'\s*((?:' + ANCHOR_CLASS + r'|\[\[' + ANCHOR_CLASS + r'+\]\])' + r'*?)\]',
re.I | re.S | re.U)
EXT_IMAGE_REGEX = re.compile(
r"""^(http://|https://)([^][<>"\x00-\x20\x7F\s]+)
/([A-Za-z0-9_.,~%\-+&;#*?!=()@\x80-\xFF]+)\.(gif|png|jpg|jpeg)$""",
re.I | re.X | re.S | re.U)
---
refer: https://github.com/attardi/wikiextractor/pull/182/commits/45662a5c914a1fb896bbdbbc26be5b3ea598cc51
python setup.py install
python -m wikiextractor.WikiExtractor ../jawiki-latest-pages-articles.xml.bz2
# 该命令将从指定目录中提取所有包含 "wiki" 的文本文件并将其合并到一个名为 "wiki.txt" 的文件中。
find text/ | grep wiki | awk '{system("cat "$0" >> wiki.txt")}'
# 下面这个过程比较花时间
mecab -Owakati wiki.txt -o wiki_wakati.txt
nkf -w --overwrite wiki_wakati.txt
训练,
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus('./wiki_wakati.txt')
model = word2vec.Word2Vec(sentences, size=200, min_count=20, window=15)
model.save("./wiki.model")
推理1,在推理过程中,可以提取与指定为正向的词语相似的词语。
from gensim.models import word2vec
model = word2vec.Word2Vec.load("./wiki.model")
results = model.wv.most_similar(positive=['講義'])
for result in results:
print(result)
推理2,如果指定多个正向词语,可以提取与这些词语语义相近的词语。
from gensim.models import word2vec
model = word2vec.Word2Vec.load("../../dataset/w2v_wiki/wiki.model")
results = model.wv.most_similar(positive=['メジャー',"野球"])
for result in results:
print(result)
推理3,通过指定正向和反向词语,可以进行语义消减。
from gensim.models import word2vec
model = word2vec.Word2Vec.load("../../dataset/w2v_wiki/wiki.model")
results = model.wv.most_similar(positive=['東京',"ロンドン"],negative=["日本"])
for result in results:
print(result)
完结!