目录
1. memcpy函数详解
情况一:
情况二:
情况三:
情况四:
情况五:
2. memcpy模拟实现
2.1 重叠情况的讨论:
2.2 memcpy函数超出我们的预期
1. memcpy函数详解
头文件<string.h>

这个函数和memcpy有点像,但是它是以字节为单位完成复制的num是要复制的字节数,destination是要复制到的地址,source是数据来源的地址。返回的是destination。函数遇到\0并不会停下。
如果source和destination有任何的重叠 ,复制的结果都是未定义的。
示例
情况一:
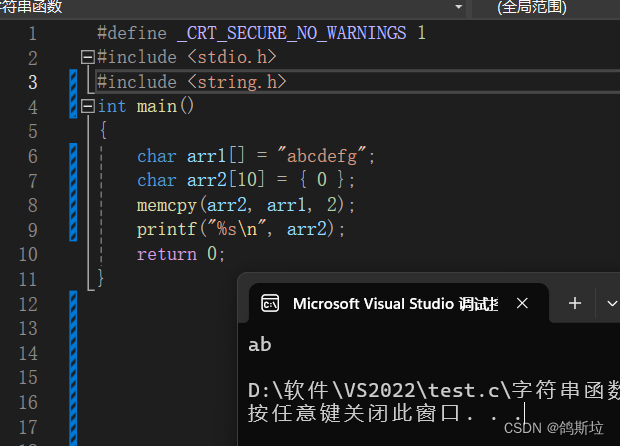
将arr1中两个字节大小的数据拷贝到arr1中,因此arr1中的“ab”被拷贝到arr2中。
情况二:
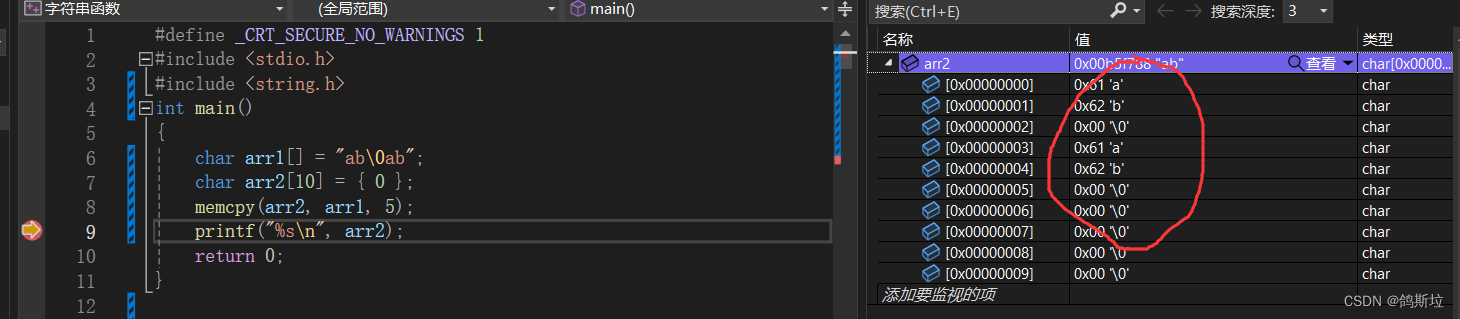
我们可以看到拷贝时遇到arr1中的\0时没有停止拷贝,而是继续拷贝直到拷贝完5个字节的长度。
情况三:
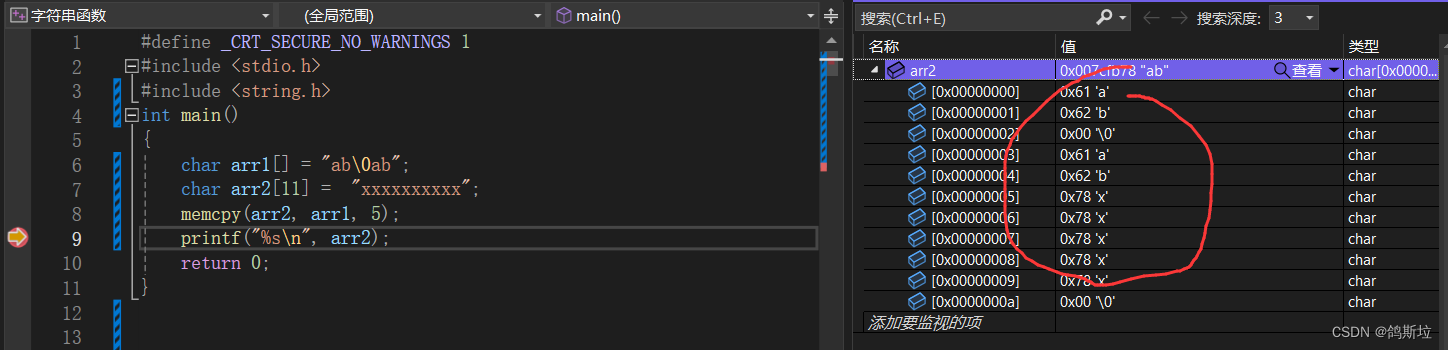
可以看到拷贝完成后不会在arr2后面补上\0。
情况四:
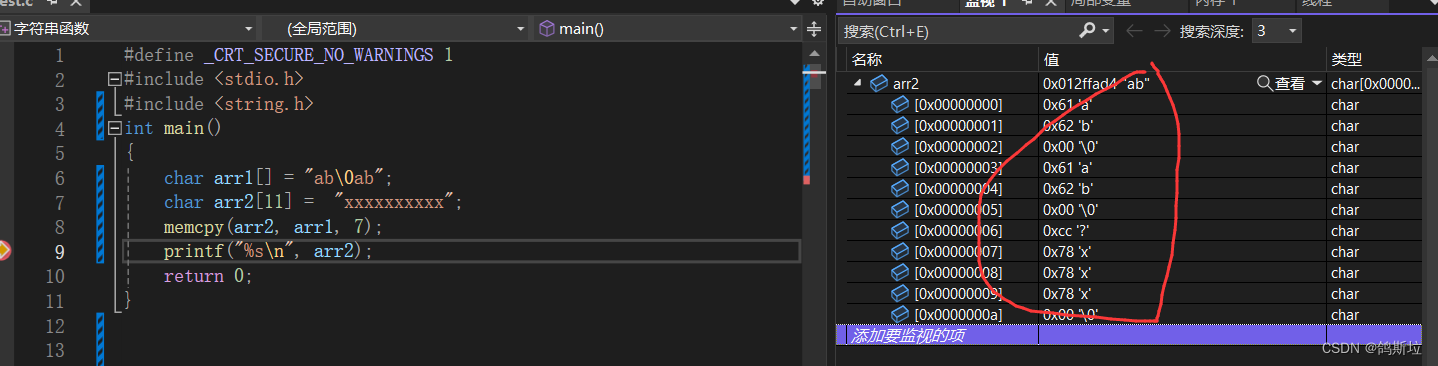
若arr1的大小不足要拷贝的大小,那么会将arr1外面的数据拷过来,产生危险,因此在使用时要考虑好大小关系。
情况五:
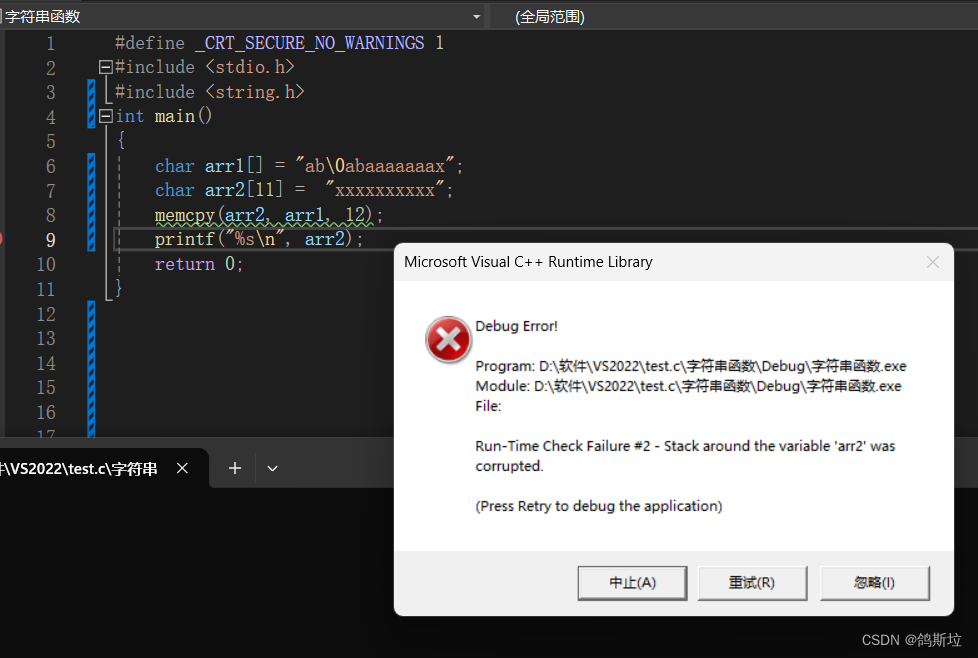
若arr2的大小小于要拷贝的的小,在运行时会报警告,表示arr2周围的堆栈以损坏。我们使用时要避免这样。
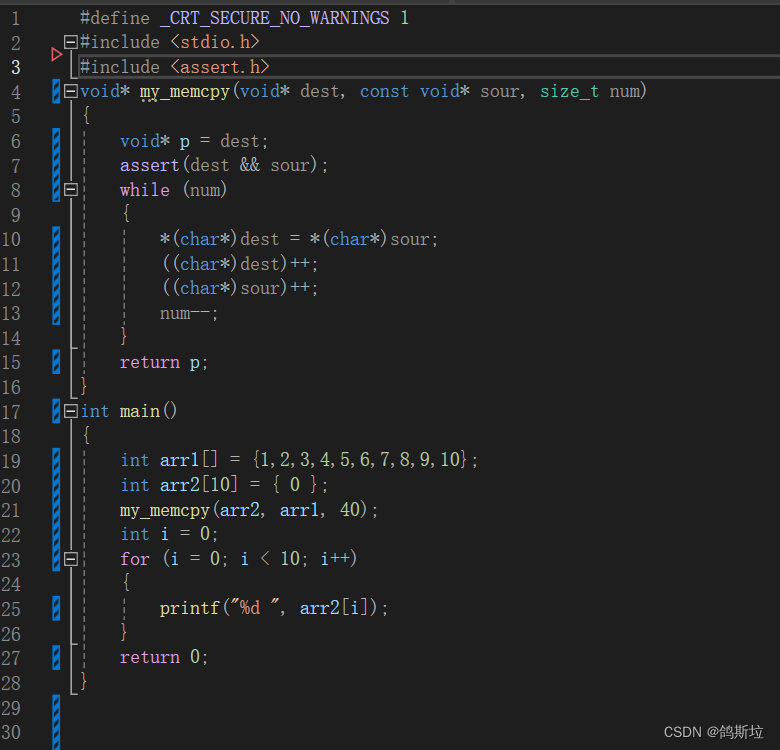
2. memcpy模拟实现
#include <assert.h>
void* my_memcpy(void* dest, const void* sour, size_t num)
{
void* p = dest;
assert(dest && sour);
while (num)
{
*(char*)dest = *(char*)sour;
((char*)dest)++;
((char*)sour)++;
num--;
}
return p;
}因为要实现多种类型的拷贝所以接收参数是void*类型,可以接收任何类型的地址,函数内强制类型转换,进行一个一个字节的拷贝,这样就可以拷贝多种类型数组了。
下面我们来使用以下my_memcpy函数:
运行结果:
可见我们的代码实现了拷贝,函数模拟实现完成。
2.1 重叠情况的讨论:
若destination与source有重叠的部分会怎么样呢?
运行一下:
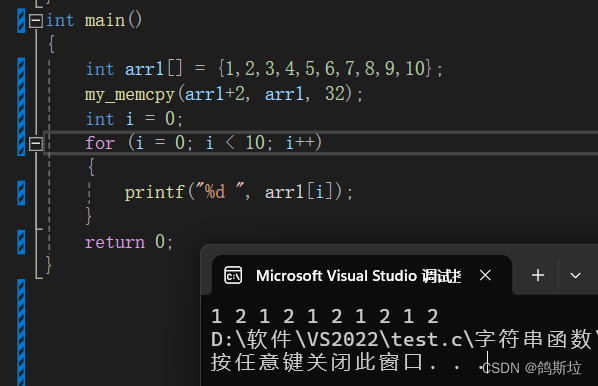
我们预期的输出结果是:1 2 1 2 3 4 5 6 7 8。但实际与我们的预期截然不同,这是为什么呢?
想一想,arr1+2,会从第三个元素开始覆盖,覆盖时arr1自身会改变,当source向后找时会遇到前面刚复制过去的‘1’与‘2’会再次向后复制,因此会产生这种效果。
2.2 memcpy函数超出我们的预期
我们再来看一下库函数的执行结果是:
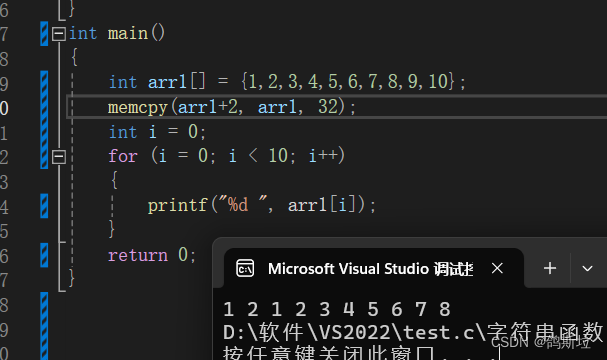
我们前面不是说:如果source和destination有任何的重叠 ,复制的结果都是未定义的。
其实库函数的实现超出了我们的预期,虽然它可以完成数据有重叠时的拷贝但是我们还是要使用memmove()函数;他可以完美处理这种重叠情况。
在下一篇博客我将详解memmove函数并完成其模拟实现。。。。
感谢观看,欢迎在评论区讨论