1.Hadoop主要有哪些缺点?相比之下,Spark具有哪些优点?
Hadoop主要有哪些缺点:Hadoop虽然已成为大数据技术的事实标准,但其本身还存在诸多缺陷,最主要的缺陷是 MapReduce计算模型延迟过高,无法胜任实时、快速计算的需求,因而只适用于离线批处理的应用场景。总体而言,Hadoop中的MapReduce计算框架主要存在以下缺点:
•表达能力有限。计算都必须要转化成Map和Reduce两个操作,但这并不适合所有的情况,难以描述复杂的数据处理过程;
•磁盘I/O开销大。每次执行时都需要从磁盘读取数据,并且在计算完成后需要将中间结果写 入到磁盘中,I/O开销较大;
•延迟高。一次计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由 于涉及到I/O开销,会产生较高延迟。而且,在前一个任务执行完成之前,其他任务无法开始,因此, 难以胜任复杂、多阶段的计算任务。
Spark在借鉴MapReduce优点的同时,很好地解决了 MapReduce所面临的问题。相比于 MapReduce,Spark主要具有如下优点:
• Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活;
• Spark提供了内存计算,中间结果直接放到内存中,带来了更高的迭代运算效率;
• Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
如图1-6所示,对比Hadoop MapReduce与Spark的执行流程,可以看到,Spark最大的特点就 是将计算数据、中间结果都存储在内存中,大大减少了 VO开销,因而,Spark更适合于迭代运算比较多的数据挖掘与机器学习运算。
使用Hadoop MapReduce进行迭代计算非常耗资源,因为每次迭代都需要从磁盘中写入、读取中 间数据,I/O开销大。而Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结 果作运算,避免了从磁盘中频繁读取数据。
2.请阐述RDD分区的作用。
增加并行度和减少通信开销(连接操作)。RDD 使用分区来分布式并行处理数据,在分布式集群里,网络通信的代价很大,数据分区,减少网络传输可以极大提升性能。
3.请分析Spark SQL出现的原因。
尽管数据库的事务和查询机制较好地满足了银行、电信等各类商业公司的业务数据管理需求, 但是,关系数据库在大数据时代已经不能满足各种新增的用户需求。首先,用户需要从不同数据源 执行各种操作,包括结构化和非结构化数据;其次,用户需要执行高级分析,比如机器学习和图像 处理,在实际大数据应用中,经常需要融合关系查询和复杂分析算法(比如机器学习或图像处理), 但是,一直以来都缺少这样的系统。
Spark SQL的出现,填补了这个空白。首先,Spark SQL可以提供DataFrame API,可以对内部 和外部各种数据源执行各种关系操作;其次,可以支持大量的数据源和数据分析算法,组合使用Spark SQL和Spark MLlib,可以融合传统关系数据库的结构化数据管理能力和机器学习算法的数据处理能 力,有效满足各种复杂的应用需求。
4.请阐述Spark Streaming的基本设计原理。
Spark Streaming是Spark Core API的一种扩展,它可以用于进行大规模、高吞吐量、容错的实时数据流的处理。它支持从很多种数据源中读取数据,比如Kafka、Flume、Twitter、ZeroMQ、Kinesis、ZMQ或者是TCP Socket。并且能够使用类似高阶函数的复杂算法来进行数据处理,比如map、reduce、join和window。处理后的数据可以被保存到文件系统、数据库、Dashboard等存储中。

Spark Streaming基本工作原理
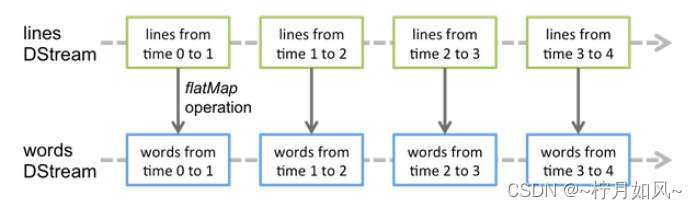
接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。

Spark Streaming DStream
1、Spark Streaming提供了一种高级的抽象,叫做DStream,英文全称为Discretized Stream,中文翻译为“离散流”,它代表了一个持续不断的数据流。DStream可以通过输入数据源来创建,比如Kafka、Flume、ZMQ和Kinesis;也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。
2、DStream的内部,其实一系列持续不断产生的RDD。RDD是Spark Core的核心抽象,即,不可变的,分布式的数据集。DStream中的每个RDD都包含了一个时间段内的数据。

1、对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。但是,在底层,其实其原理为,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。底层的RDD的transformation操作。
2、还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API。