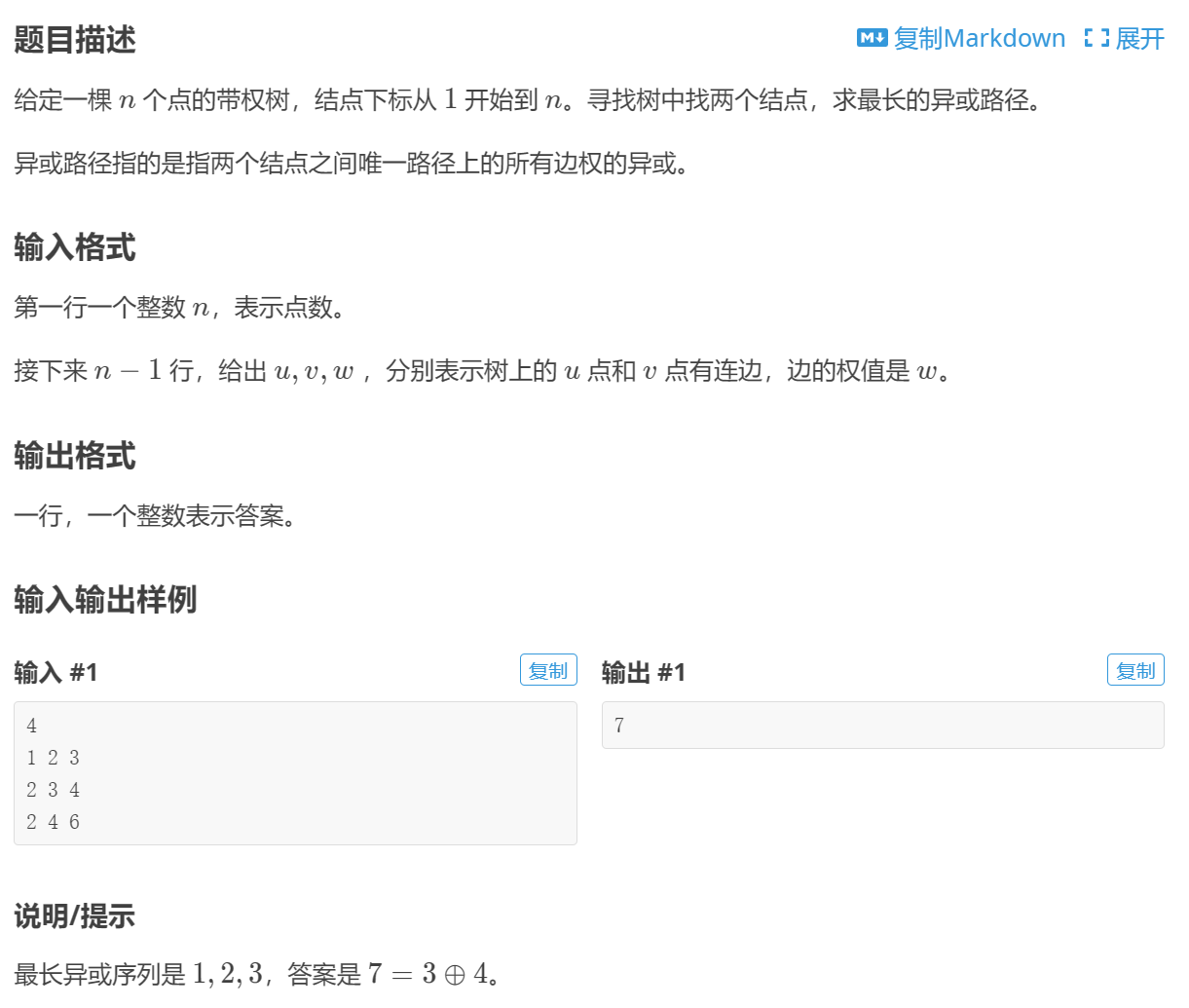
Swin Transformer
使用了移动窗口的层级式的Vit(Hierarchical Vision Transformer using Shifted Windows)
总体来说:Swin Transformer想让Transformer像卷积神经网络一样,可以分为多个block,可以做层级式特征提取,从而提取得到的特征具有多尺度的概念。
1、Abstract
- 难点:
1、尺度问题,eg:一张街景图片,有很多的车和行人,但是对于同一语义的行人、车,具有不同的尺度,这与NLP不同。
2、分辨率太大,不可能以像素点输入,要么使用特征图,要么使用Patch。
- 解决:
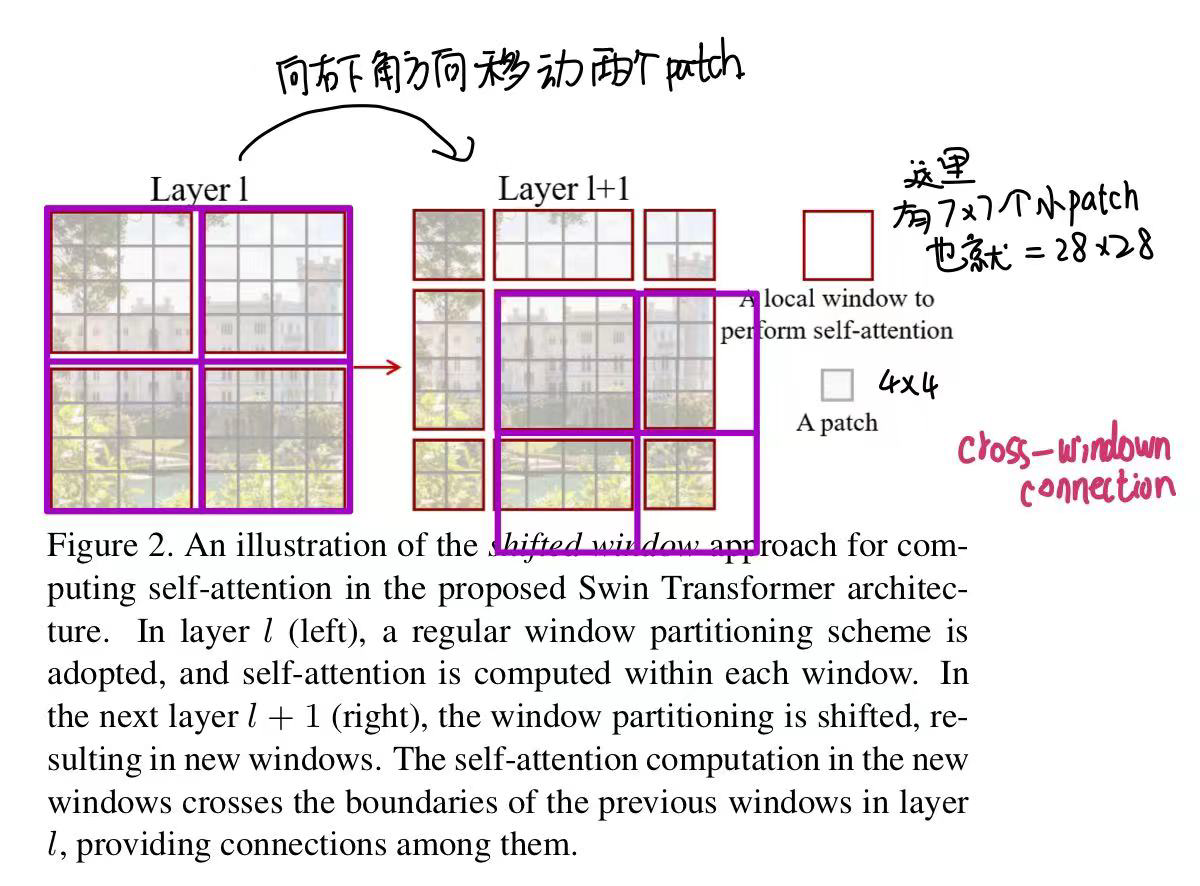
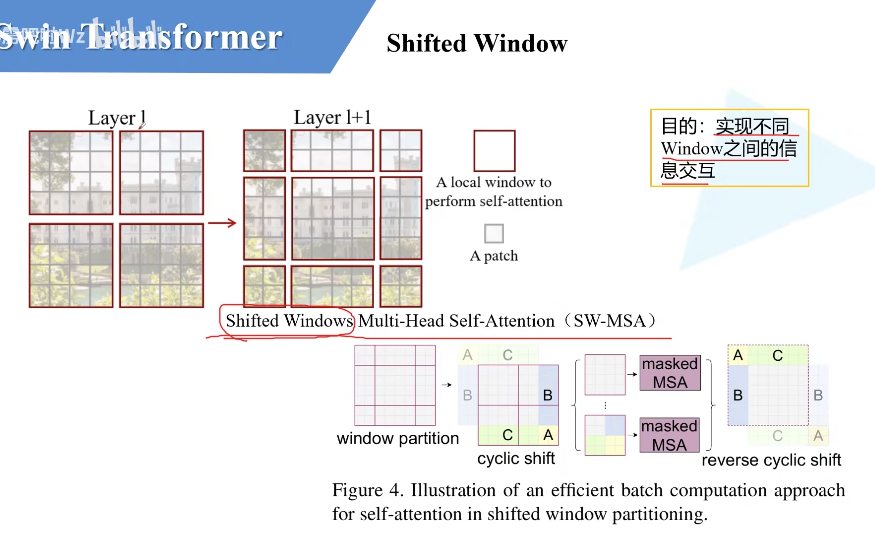
使用Shifted windows。将自注意力计算限制到一个windows内,导致序列长度的大幅降低,其次通过移动操作,使得相邻窗口可以交互,所以上下文之间就有cross-window connection。达到了层级式建模能力。
- 层级式结构的好处:
灵活,可以提供各个尺度的信息。而且由于使用了windows,所以计算量是随着image size线性增长,而非平方式增长。
2、Introduction
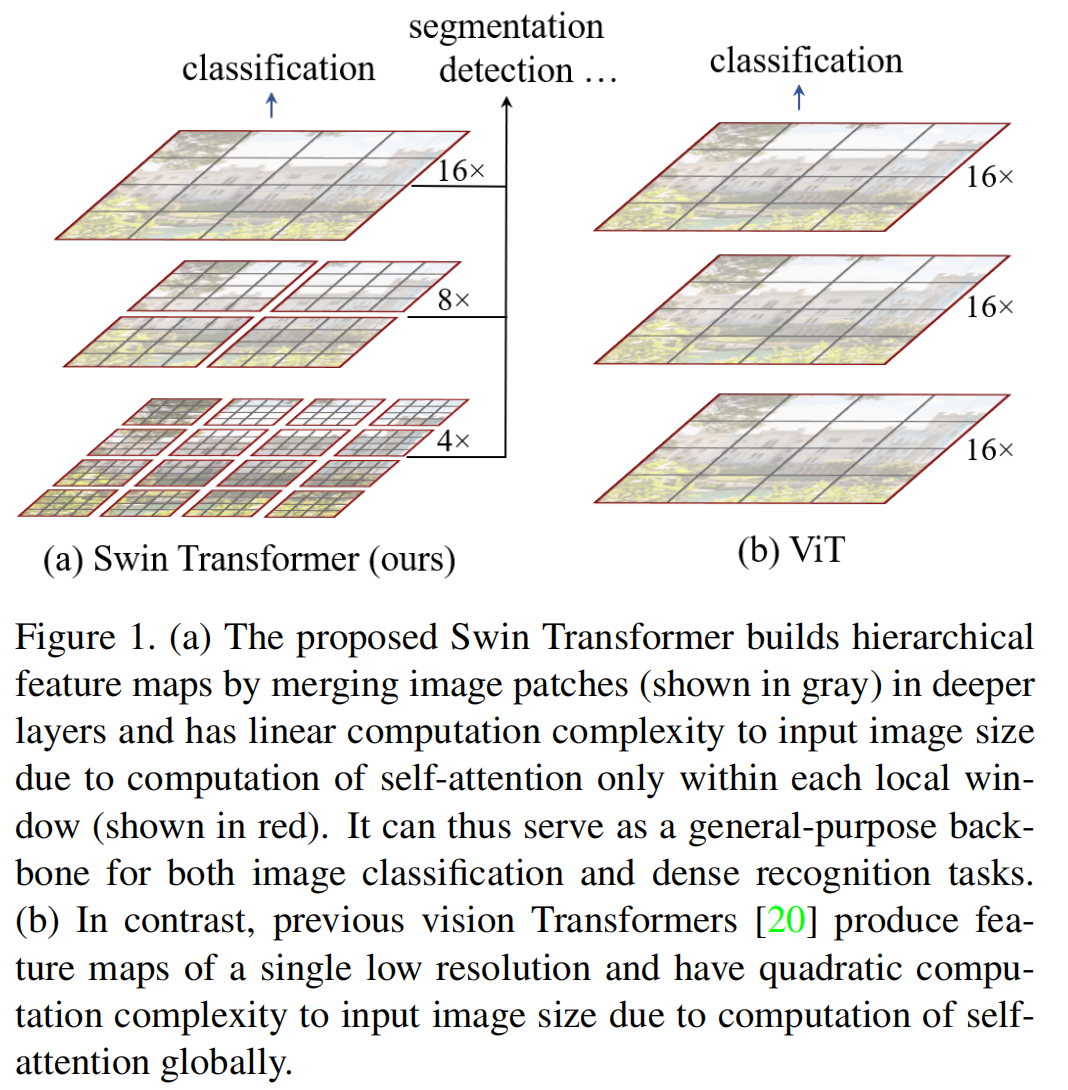
目的:想将Transformer变成一个通用的骨干网络框架
常用的检测、分割当中,有多尺寸的特征是至关重要的。但在Vit中,都是单一尺寸,16倍的下采样率,而且处理的图片也都是低分辨率的,对于目标密集的检测、分割任务可能不太适合。由于Vit的自注意力都是寻找每个patch和整幅图像的关系,所以其计算复杂度是随着图像尺寸平方倍的增长的。所以提出了Swin Transformer。
Swin Transformer是通过windows,计算windows之内的自注意力,只要窗口大小固定,其计算复杂度就是固定的,与图片大小呈线性关系。这也是用到了卷积神经网络的局部性的先验知识。
- 如何生成多尺度特征?
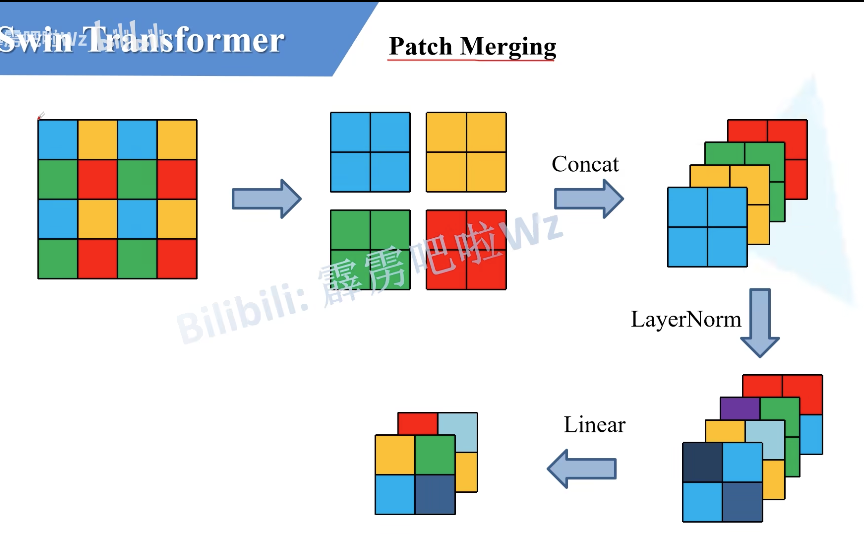
卷积中是因为有池化操作。增大感受野。Swin Transformer也提出类似操作,使用了Patch merging。将很多小Patch合并为一个大Patch。
具有层次性
- Shift windows
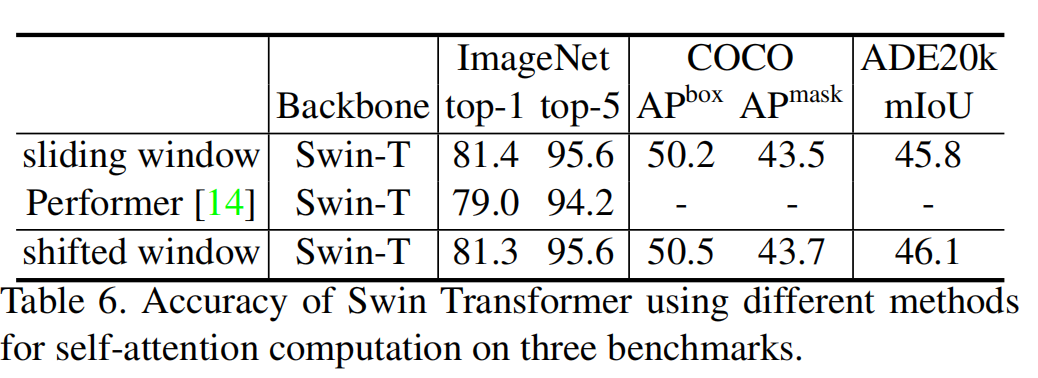
3、Conclusion
Swin Transformer,一个层级式的Transformer,计算复杂度与输入大小呈线性关系。
4、Method
4.1 Overall Architecture
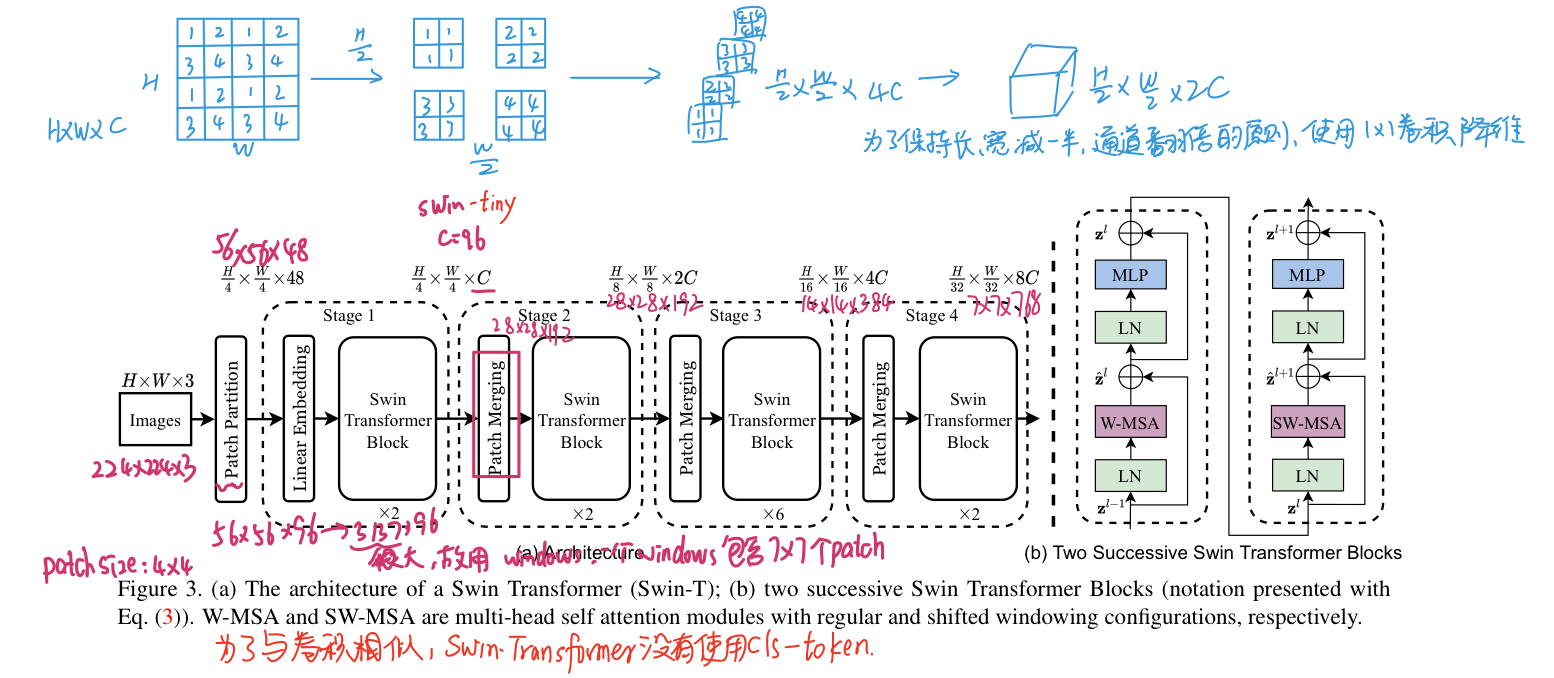
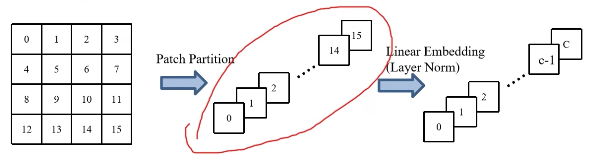
- Patch Partition/Linear Embedding(可以采用卷积操作实现)
- Patch Merging
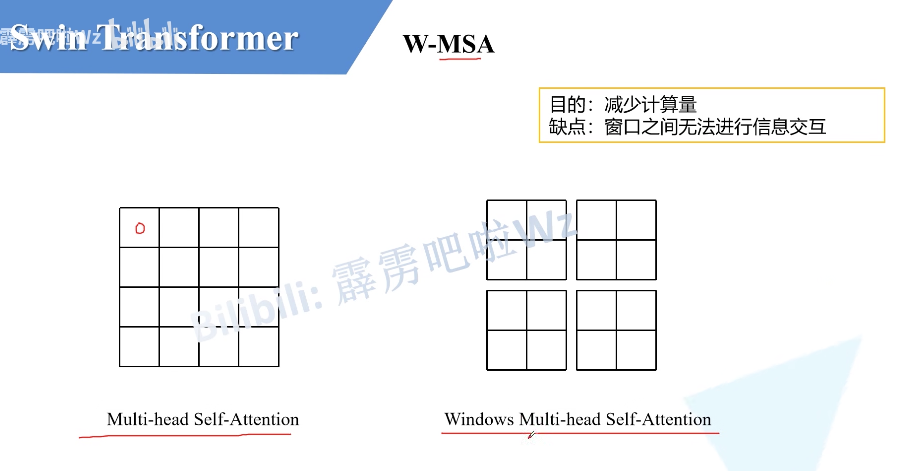
- W-MSA
计算量差异

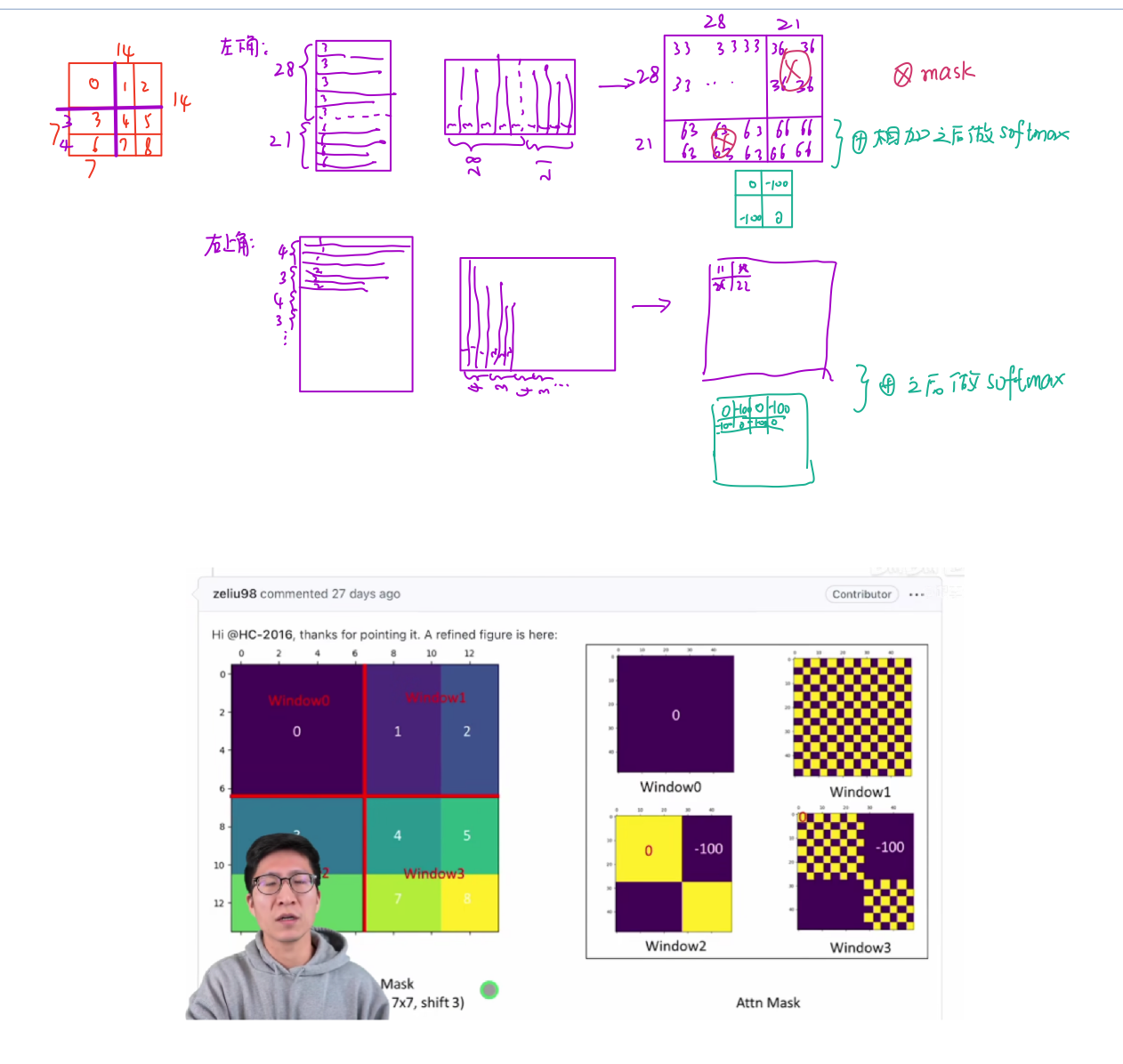
4.2 Shifted Window based Self-Attention
全局自注意力机制太贵了,所以使用了窗口自注意力
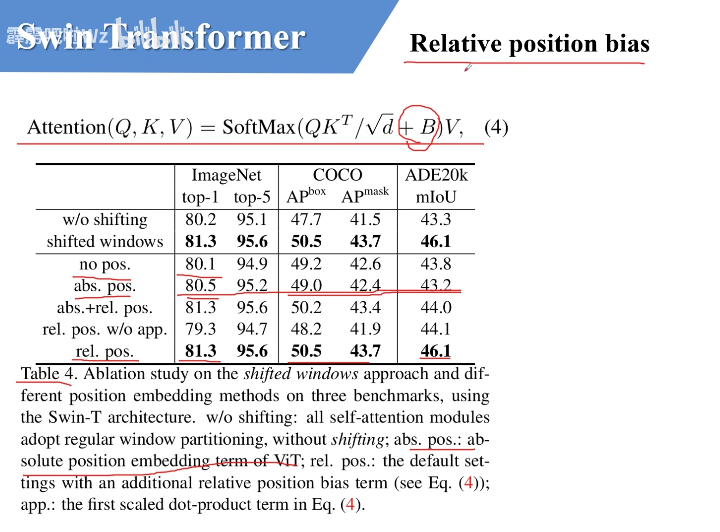
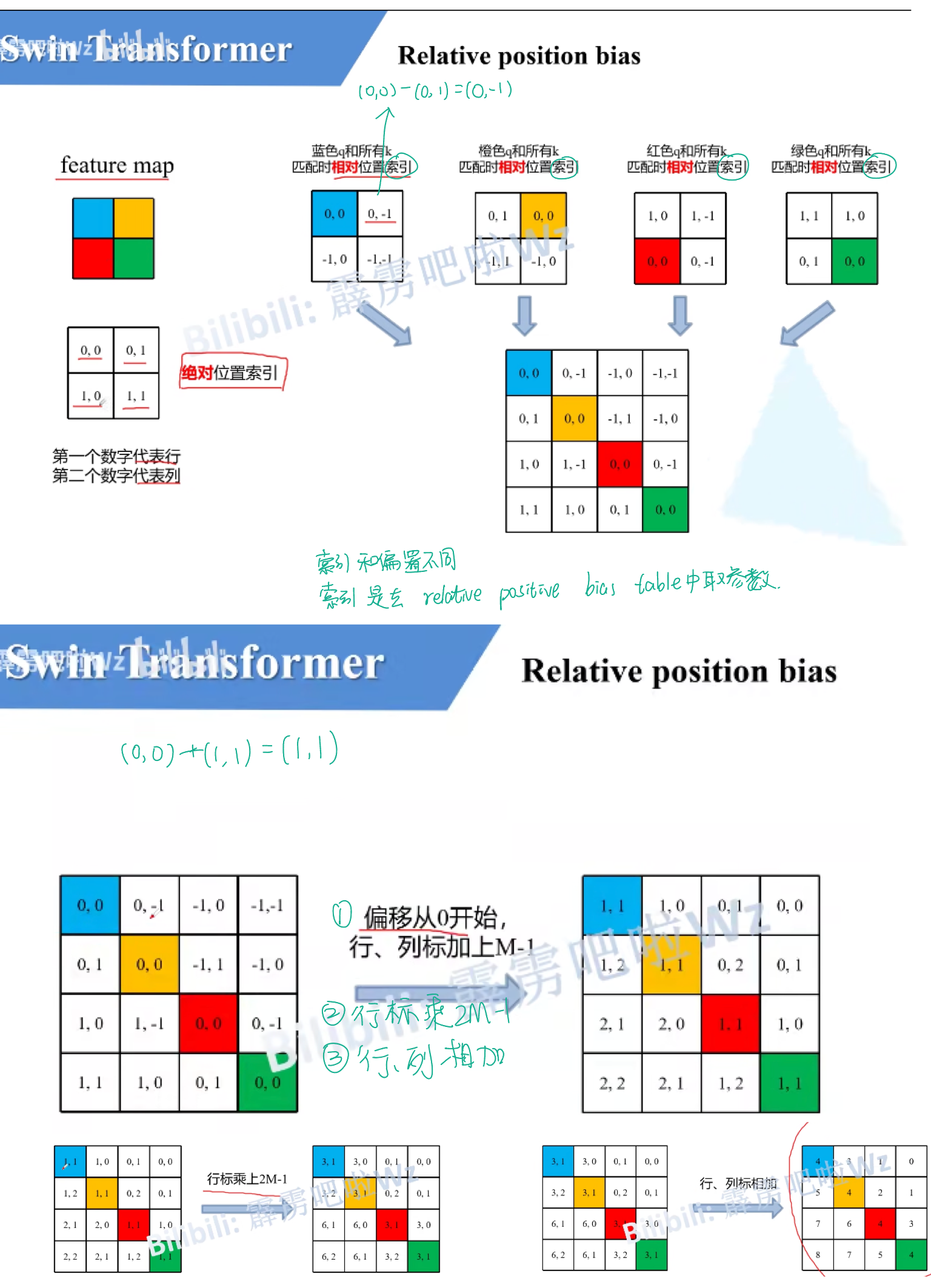
相对位置偏置
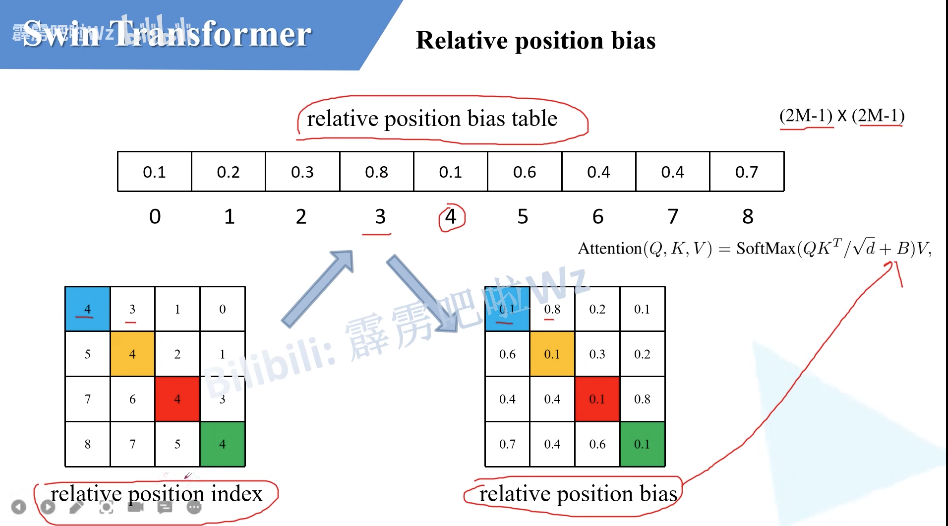
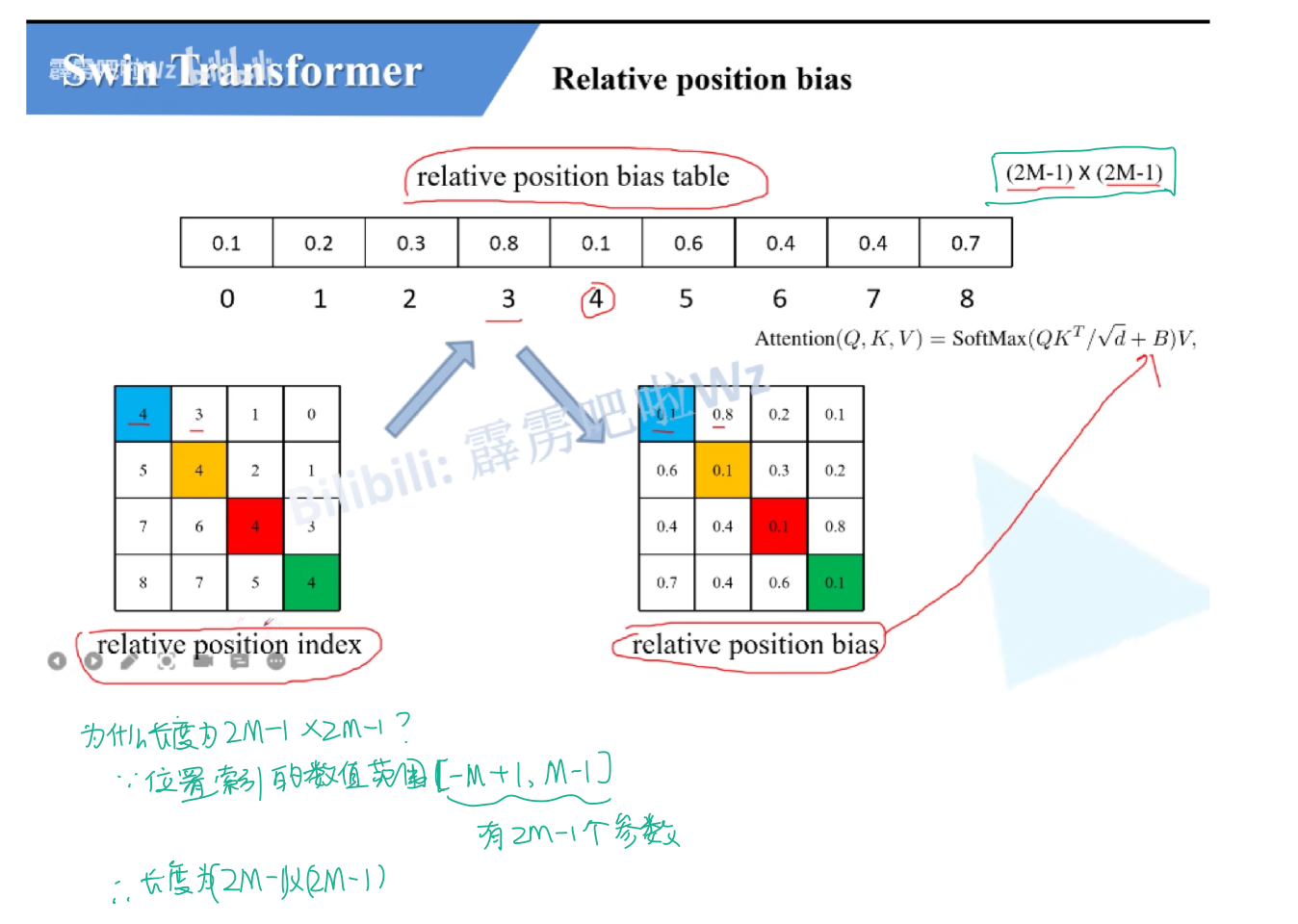
研究动机:想要一个层级式的Transformer,所以提出了Patch Merging结构,为了减少计算复杂度,争取做视觉里的密集预测任务,所以提出了窗口自注意力和移动窗口自注意力。