嘿! 您是否曾经感觉自己被淹没在信息的海洋中? 有这么多的书要读,而时间却这么少,很容易就会超负荷,对吧? 但猜猜怎么了? 你可以使用大型语言模型创建自定义聊天机器人,该模型可以帮助您总结 pdf 并根据你上传的 pdf 回答你的问题。 拥有 PDF 摘要生成器就像拥有一个超级聪明的伙伴,他可以阅读那些又长又无聊的文档,并为你提供所需的内容。 不再需要翻阅研究论文或任何报告。 有大量工具可以帮助你总结文档,有些需要付费,有些是免费的。 但是为什么不尝试创建你的 PDF 摘要应用程序并尝试一下最适合你的呢?
在这篇博文中,我将向您展示如何使用 Open AI、Lang chain 和 Stream lit 构建端到端应用程序。 那么,让我们开始吧!
它是如何工作的?

在这个项目中,我们将使用以下内容:
Open AI
Open AI 是一个人工智能研究组织,专注于开发先进的人工智能技术,造福人类。 它的成立是为了负责任地、有益地推进人工智能。 OpenAI 在人工智能的各个领域进行研究,包括自然语言处理、强化学习、机器人技术等。 其主要目标之一是开发能够以类人智能执行各种任务的人工智能系统。 OpenAI 的著名项目和成就之一是语言模型。 OpenAI 开发了大规模语言模型,例如 GPT(生成式预训练转换器)系列,它可以根据提供给它们的输入生成类似人类的文本。 这些模型在自然语言理解、文本生成翻译等领域都有应用。
创建 OpenAI 密钥
要生成 OpenAI API 密钥,请访问网站 https://openai.com/,登录,然后从标记为 “API Keys” 的部分生成一个对每个人来说都是唯一的 API 密钥。 一旦你的 API 密钥生成,它将显示在屏幕上。 复制 API 密钥并安全存储。 将您的 API 密钥视为密码,并避免公开共享。 你现在可以使用 OpenAI API 密钥访问 OpenAI API 并将其集成到你的应用程序、项目或研究中。

LangChain
LangChain 是一个用于构建由语言模型支持的上下文感知推理应用程序的框架。 它使应用程序能够根据上下文理解并做出响应,从而增强决策能力。 LangChain 提供工具、库和预构建组件,用于创建复杂的基于文本的应用程序,包括聊天机器人、数据分析和检索增强生成任务。 其主要目的是使开发人员能够在其应用程序中有效地利用语言模型,使他们能够推理、响应以及与用户或数据进行智能交互。
Streamlit
Streamlit 是一个开源 Python 库,用于为机器学习和数据科学项目构建 Web 应用程序。 它允许开发人员直接直观地编写代码,从而简化了创建交互式 Web 应用程序的过程。 借助 Streamlit,开发人员可以直接从 Python 脚本创建交互式 Web 应用程序,而无需编写 HTML、CSS 或 Javascript 代码。 它提供了易于使用的组件,用于创建交互式小部件、可视化和数据显示。 在此项目中,我们使用 Streamlit 来实现简单的用户界面,你可以在本博客末尾看到。
运行 streamlit 应用可以使用命令:streamlit run app.py
前提条件
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:

为了方便大家学习,我在本次的演示中使用 Elastic Stack 8.12 来进行展示。
安装 Python 依赖包
pip3 install langchain OpenAI PyPDF2 python-dotenv streamlit elasticsearch streamlit-extras tiktoken langchain-community你可以使用 pip install 简单地安装所有这些库。
- Langchain:语言链库,可帮助你完成总结文本、回答问题和生成新句子等操作。
- OpenAI:这有助于与 OpenAI 提供的语言模型进行交互
- PyPDF2:处理 PDF 文件。 启用读取和操作 PDF 文档等任务。
- Python-dotenv:你可以将 API 密钥或数据库凭据等敏感信息存储在名为 .env 的特殊文件中,而不是将它们硬编码到代码中。 这有助于确保敏感信息的安全,并使管理不同环境(如开发、测试和生产)变得更加容易,而无需更改代码。
- Streamlit:用于创建交互式 Web 应用程序的框架。
- elasticsearch:- 用于密集向量的相似性搜索和聚类的高效库。
- Streamlit-extras:一个扩展包,为 Streamlit 添加额外的功能,并提供额外的工具、小部件和功能来增强 Streamlit 应用程序的功能。
拷贝 Elasticsearch 证书到当前的目录中
$ pwd
/Users/liuxg/python/PDF-Summarizer-End-to-End-Project
$ cp ~/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt .
$ ls http_ca.crt
http_ca.crt创建环境变量文件
我们在自己的项目根目录下创建如下的 .env 文件:
.env
ES_USER="elastic"
ES_PASSWORD="q2rqAIphl-fx9ndQ36CO"
ES_ENDPOINT="localhost"
OPENAI_API_KEY="YourOpenAIkey"请记得根据自己的 Elasticsearch 配置及 OpenAI key 进行相应的修改。
创建应用
我们在当前的目录下创建一个叫做 app.py 的文件。
导入依赖项
from dotenv import load_dotenv
import streamlit as st
from PyPDF2 import PdfReader
from streamlit_extras.add_vertical_space import add_vertical_space
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from elasticsearch import Elasticsearch, helpers
from langchain_community.vectorstores import ElasticsearchStore
from langchain.chains.question_answering import load_qa_chain
from langchain_community.llms import OpenAI
from langchain_community.callbacks import get_openai_callback
import os创建 SideBar
# Sidebar contents
with st.sidebar:
st.title('💬PDF Summarizer and Q/A App')
st.markdown('''
## About this application
You can built your own customized LLM-powered chatbot using:
- [Streamlit](https://streamlit.io/)
- [LangChain](https://python.langchain.com/)
- [OpenAI](https://platform.openai.com/docs/models) LLM model
''')
add_vertical_space(2)
st.write(' Why drown in papers when your chat buddy can give you the highlights and summary? Happy Reading. ')
add_vertical_space(2) 上传 PDF 文件
为了方便大家学习,我把一些示例的 PDF 文件进行上传。你可以在地址下载。
我们使用如下的代码来上传 PDF 文件:
pdf = st.file_uploader("Upload your PDF File and Ask Questions", type="pdf")Streamlit 中的 st.file_uploader 功能允许用户上传 PDF 文件,使他们能够交互式地选择和上传 PDF 文档,以便在 Streamlit Web 应用程序中进行进一步处理或分析。
我们使用如下的命令来运行代码:
app.py
from dotenv import load_dotenv
import streamlit as st
from PyPDF2 import PdfReader
from streamlit_extras.add_vertical_space import add_vertical_space
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from elasticsearch import Elasticsearch, helpers
from langchain_community.vectorstores import ElasticsearchStore
from langchain.chains.question_answering import load_qa_chain
from langchain_community.llms import OpenAI
from langchain_community.callbacks import get_openai_callback
import os
# Sidebar contents
with st.sidebar:
st.title('💬PDF Summarizer and Q/A App')
st.markdown('''
## About this application
You can built your own customized LLM-powered chatbot using:
- [Streamlit](https://streamlit.io/)
- [LangChain](https://python.langchain.com/)
- [OpenAI](https://platform.openai.com/docs/models) LLM model
''')
add_vertical_space(2)
st.write(' Why drown in papers when your chat buddy can give you the highlights and summary? Happy Reading. ')
add_vertical_space(2)
def main():
load_dotenv()
OPENAI_API_KEY= os.getenv("OPENAI_API_KEY")
ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
ES_ENDPOINT = os.getenv("ES_ENDPOINT")
elastic_index_name='pdf_docs'
#Main Content
st.header("Ask About Your PDF 🤷♀️💬")
# upload file
pdf = st.file_uploader("Upload your PDF File and Ask Questions", type="pdf")
if __name__ == '__main__':
main()streamlit run app.py
提前文本并写入到 Elasticsearch
app.py
from dotenv import load_dotenv
import streamlit as st
from PyPDF2 import PdfReader
from streamlit_extras.add_vertical_space import add_vertical_space
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from elasticsearch import Elasticsearch, helpers
from langchain_community.vectorstores import ElasticsearchStore
from langchain.chains.question_answering import load_qa_chain
from langchain_community.llms import OpenAI
from langchain_community.callbacks import get_openai_callback
import os
# Sidebar contents
with st.sidebar:
st.title('💬PDF Summarizer and Q/A App')
st.markdown('''
## About this application
You can built your own customized LLM-powered chatbot using:
- [Streamlit](https://streamlit.io/)
- [LangChain](https://python.langchain.com/)
- [OpenAI](https://platform.openai.com/docs/models) LLM model
''')
add_vertical_space(2)
st.write(' Why drown in papers when your chat buddy can give you the highlights and summary? Happy Reading. ')
add_vertical_space(2)
def main():
load_dotenv()
OPENAI_API_KEY= os.getenv("OPENAI_API_KEY")
ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
ES_ENDPOINT = os.getenv("ES_ENDPOINT")
elastic_index_name='pdf_docs'
#Main Content
st.header("Ask About Your PDF 🤷♀️💬")
# upload file
pdf = st.file_uploader("Upload your PDF File and Ask Questions", type="pdf")
# extract the text
if pdf is not None:
pdf_reader = PdfReader(pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
# split into chunks
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
# Make a connection to Elasticsearch
url = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"
connection = Elasticsearch(
hosts=[url],
ca_certs = "./http_ca.crt",
verify_certs = True
)
print(connection.info())
# create embeddings
embeddings = OpenAIEmbeddings()
if not connection.indices.exists(index=elastic_index_name):
print("The index does not exist, going to generate embeddings")
docsearch = ElasticsearchStore.from_texts(
chunks,
embedding = embeddings,
es_url = url,
es_connection = connection,
index_name = elastic_index_name,
es_user = ES_USER,
es_password = ES_PASSWORD
)
else:
print("The index already existed")
docsearch = ElasticsearchStore(
es_connection=connection,
embedding=embeddings,
es_url = url,
index_name = elastic_index_name,
es_user = ES_USER,
es_password = ES_PASSWORD
)
if __name__ == '__main__':
main()我们使用如下的部分来提取 pdf 文件:
if pdf is not None:
pdf_reader = PdfReader(pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()它首先检查 PDF 文件是否已上传(即变量 pdf 是否不是 None)。 如果确实上传了 PDF 文件,则会创建一个 PdfReader 对象来读取 PDF 文件的内容。 然后,它迭代 PDF 文档的每个页面,使用 extract_text() 方法从每个页面中提取文本,并将所有页面中的文本连接到一个名为 text 的字符串变量中。
我们使用如下的代码把文档分成 chunk:
# split into chunks
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
“chunks”变量表示从 PDF 文件中提取的文本的分段部分。 将文本拆分为块至关重要,因为它有助于更有效地处理大型文档,因为一次处理整个文本可能会消耗过多的内存和处理资源。 通过将文本分成更小的片段,应用程序可以更有效地管理和分析数据。 对文本进行分段可以更好地组织并有助于有针对性地分析或处理文档的特定部分。
我们使用如下的代码来生成嵌入:
ElasticsearchStore.from_texts(
chunks,
embedding = embeddings,
es_url = url,
es_connection = connection,
index_name = elastic_index_name,
es_user = ES_USER,
es_password = ES_PASSWORD
)嵌入是对象的数字表示,通常用于捕获它们在数学空间中的语义或上下文。 词嵌入是高维空间中单词、短语或文档的向量表示,其中相似的单词彼此更接近。 在此代码片段中,嵌入是使用 OpenAIEmbeddings() 函数创建的,该函数可能为从 PDF 文件中提取的文本数据生成嵌入(向量表示)。 这些嵌入捕获有关文本的语义信息,使应用程序能够更有效地理解和处理内容。
随后,使用 ElasticsearchStore.from_texts() 函数构建知识库,该函数根据之前分段的文本块创建可搜索索引或结构。 该知识库使用 Elasticsearch 库实现,可根据文本片段的嵌入进行高效的相似性搜索和检索。
成功运行上面的脚本后,我们可以到 Elasticsearch 中进行查看:

连接 LLM OpenAI
llm = OpenAI()
chain = load_qa_chain(llm, chain_type="stuff")
with get_openai_callback() as cb:
response = chain.run(input_documents=docs, question=user_question)
print(cb)
st.write(response)此代码初始化并利用 OpenAI 语言模型 (LLM) 创建问答 (Q&A) 系统。 它使用 LLM 加载预训练或自定义问答模型,设置回调管理以处理问答过程中的事件,对输入文档和用户问题执行模型,并使用 Streamlit 显示生成的响应以进行用户交互。
最终的完整 app.py 如下:
app.py
from dotenv import load_dotenv
import streamlit as st
from PyPDF2 import PdfReader
from streamlit_extras.add_vertical_space import add_vertical_space
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from elasticsearch import Elasticsearch, helpers
from langchain_community.vectorstores import ElasticsearchStore
from langchain.chains.question_answering import load_qa_chain
from langchain_community.llms import OpenAI
from langchain_community.callbacks import get_openai_callback
import os
# Sidebar contents
with st.sidebar:
st.title('💬PDF Summarizer and Q/A App')
st.markdown('''
## About this application
You can built your own customized LLM-powered chatbot using:
- [Streamlit](https://streamlit.io/)
- [LangChain](https://python.langchain.com/)
- [OpenAI](https://platform.openai.com/docs/models) LLM model
''')
add_vertical_space(2)
st.write(' Why drown in papers when your chat buddy can give you the highlights and summary? Happy Reading. ')
add_vertical_space(2)
def main():
load_dotenv()
OPENAI_API_KEY= os.getenv("OPENAI_API_KEY")
ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
ES_ENDPOINT = os.getenv("ES_ENDPOINT")
elastic_index_name='pdf_docs'
#Main Content
st.header("Ask About Your PDF 🤷♀️💬")
# upload file
pdf = st.file_uploader("Upload your PDF File and Ask Questions", type="pdf")
# extract the text
if pdf is not None:
pdf_reader = PdfReader(pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
# split into chunks
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
# Make a connection to Elasticsearch
url = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"
connection = Elasticsearch(
hosts=[url],
ca_certs = "./http_ca.crt",
verify_certs = True
)
print(connection.info())
# create embeddings
embeddings = OpenAIEmbeddings()
if not connection.indices.exists(index=elastic_index_name):
print("The index does not exist, going to generate embeddings")
docsearch = ElasticsearchStore.from_texts(
chunks,
embedding = embeddings,
es_url = url,
es_connection = connection,
index_name = elastic_index_name,
es_user = ES_USER,
es_password = ES_PASSWORD
)
else:
print("The index already existed")
docsearch = ElasticsearchStore(
es_connection=connection,
embedding=embeddings,
es_url = url,
index_name = elastic_index_name,
es_user = ES_USER,
es_password = ES_PASSWORD
)
# show user input
with st.chat_message("user"):
st.write("Hello World 👋")
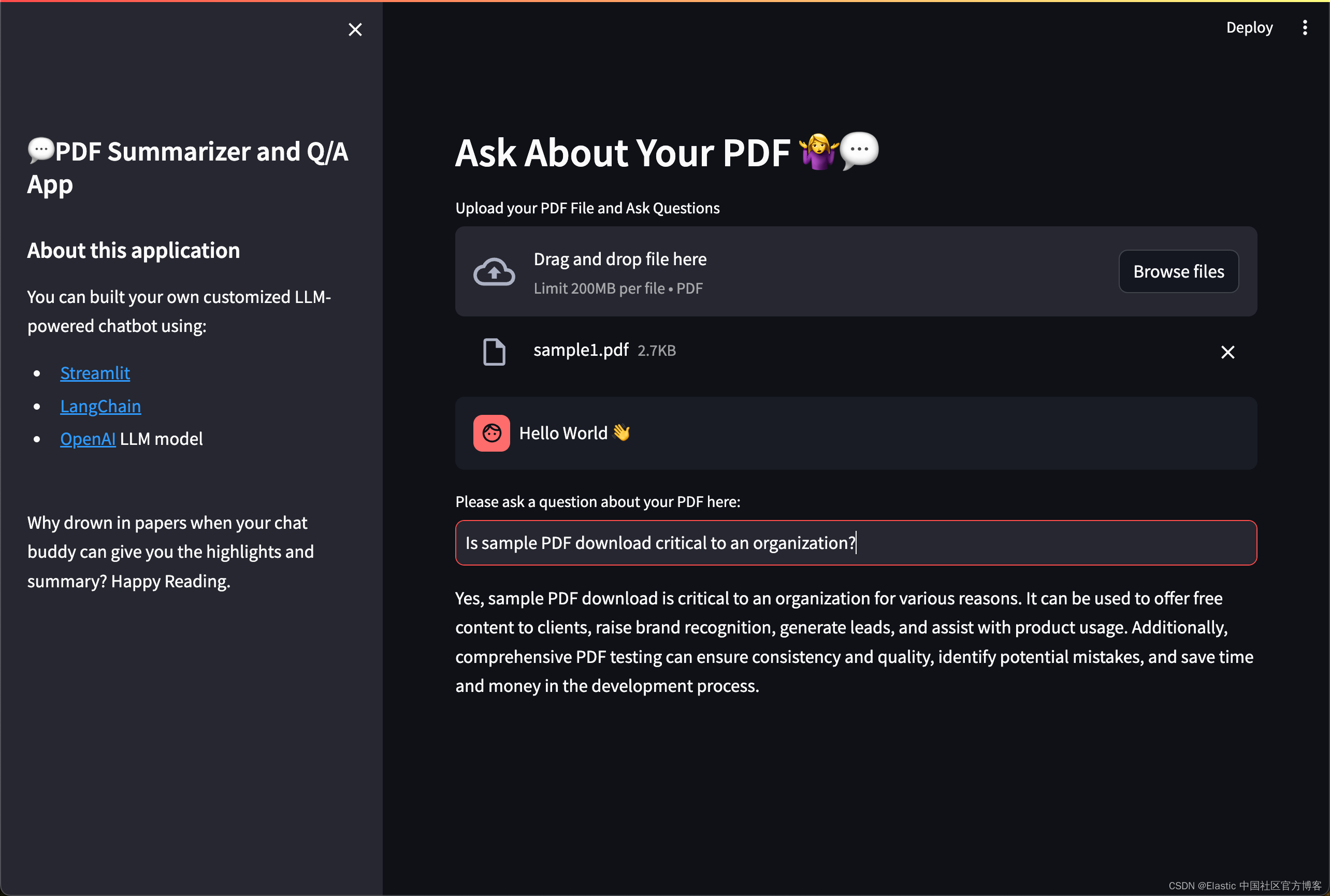
user_question = st.text_input("Please ask a question about your PDF here:")
if user_question:
docs = docsearch.similarity_search(user_question)
llm = OpenAI()
chain = load_qa_chain(llm, chain_type="stuff")
with get_openai_callback() as cb:
response = chain.run(input_documents=docs, question=user_question)
print(cb)
st.write(response)
if __name__ == '__main__':
main()我们可以针对文章进行总结:

我们也可以针对文章进行搜索:
整个项目的源码可以在地址 GitHub - liu-xiao-guo/PDF-Summarizer-End-to-End-Project 进行下载。