24 年 2 月,鉴智机器人、剑桥大学和上海交通大学联合发布CVPR'24工作,3DSFLabelling: Boosting 3D Scene Flow Estimation by Pseudo Auto-labelling。
- 提出 3D 场景自动标注新框架,将 3D 点云打包成具有不同运动属性的 Boxes,通过优化每个 Box 运动参数并将源点云 Warp 扭曲到目标点云中,创建了伪 3D 场景流标签。
- 提出 3D 场景流数据增强方法,引入各种场景运动模式,显著提高了3D场景流标签多样性。
Abstract
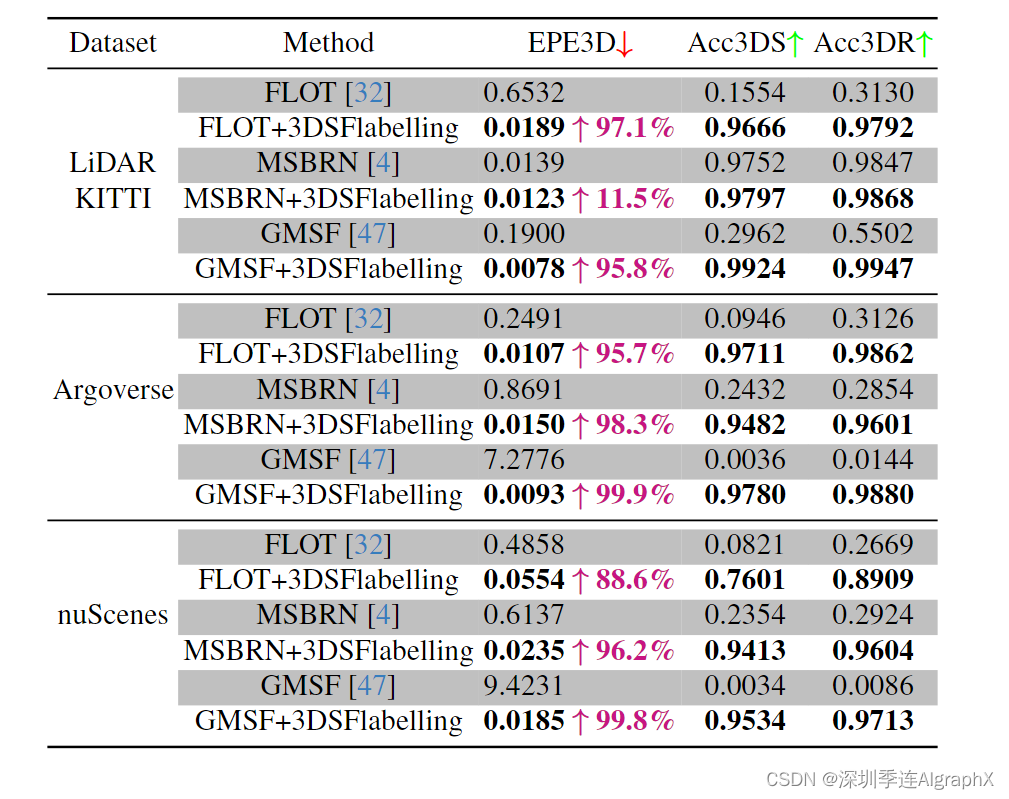
从 LiDAR 点云学习 3D 场景流带来了重大困难,包括从合成数据集到真实场景泛化能力差、缺少现实世界 3D 标签以及在真实稀疏 LiDAR 点云上性能差。我们从自动标注角度提出了一种新方法,旨在为真实世界 LiDAR 点云生成大量 3D 场景流伪标签。具体来说,我们采用刚体运动假设来模拟自动驾驶场景中潜在的对象级刚体运动。通过更新 anchor boxes 不同运动属性,得到整个场景刚体运动分解。此外,我们开发了一种新的用于全局和本地运动 3D 场景流数据增强方法。通过基于增强运动参数完美地合成目标点云,我们可以很容易地获得点云中大量与真实场景高度一致的 3D 场景流标签。在包括 LiDAR KITTI、nuScenes 和 Argoverse 在内的多个真实世界数据集上,我们的方法在不需要手工标注情况下优于所有以前有监督和无监督方法。令人印象深刻的是,我们的方法在LiDAR KITTI数据集上实现了EPE3D度量的十倍减少,将误差从0.190m减少到仅0.008m。
https://github.com/jiangchaokang/3DSFLabelling.
Introduction
通过从连续的点云帧推导出逐点运动场进行三维场景流估计,各种应用中发挥着关键作用。
- 运动预测
- Motion Inspired Unsupervised Perception and Prediction in Autonomous Driving
- MotionNet: Joint Perception and Motion Prediction for AutonomousDriving Based on Bird's Eye View Maps
- 异常检测
- Detection of Abnormal Motion by Estimating Scene Flows of Point Clouds for Autonomous Driving
- 目标检测
- 3D Object Detection with a Self-supervised Lidar Scene Flow Backbone
- SDP-Net: Scene Flow Based RealTime Object Detection and Prediction from Sequential 3D Point Clouds
- 动态点云积累
- Dynamic 3D Scene Analysis by Point Cloud Accumulation
随着PointNet等点云深度学习的发展,许多工作发展了基于学习的方法来从三维点云估计每个点的运动。
- #Multi-Scale Bidirectional Recurrent Network with Hybrid Correlation for Point Cloud Based Scene Flow Estimation
- #Self-Supervised 3D Scene Flow Estimation Guided by Superpoints
- #GMSF: Global Matching Scene Flow
- PT-FlowNet: Scene Flow Estimation on Point Clouds With Point Transformer
- Deformation and Correspondence Aware Unsupervised Synthetic-toReal Scene Flow Estimation for Point Clouds
- Learning Scene Flow in 3D Point Clouds.
- FLOT: Scene Flow on Point Clouds Guided by Optimal Transport
前面3个#最先进方法在KITTI场景流数据集(立体KITTI)上将平均3D EndPoint Error(EPE3D)降低到几厘米。然而,由于场景流标签的稀缺性,这些方法严重依赖于合成数据集,如FlyingThings3D (FT3D)进行网络训练。
在立体KITTI数据集上进行评估时,PV-RAFT平均EPE3D仅为0.056m。然而,当在Argoverse数据集上进行评估时,EPE3D度量惊人地超过10m。因此,在合成数据集上学习3D场景流与实际应用有很大的差距。Deformation and Correspondence Aware Unsupervised Synthetic-to.Real Scene Flow Estimation for Point Clouds 最近引入了一种新合成数据集GTA-SF,模拟自动驾驶激光雷达扫描。他们提出了一个teacher-student域适应框架来减少合成数据集和真实数据集之间的差距,并提高 3D 场景流估计的一些性能。然而,由于不切实际的传感器模型和缺乏场景多样性,它们在实际激光雷达数据中的性能仍然很差。真实情况下,模型应该从自动驾驶领域真实传感器数据中学习。但是为 3D 场景流任务标注每个点 3D 运动矢量非常昂贵。
许多工作推动了 3D 场景流的无监督或自监督学习。
- Self-Supervised Scene Flow Estimation with 4D Automotive Radar
- RigidFlow: Self-Supervised Scene Flow Learning on Point Clouds byLocal Rigidity Prior
- Learning Scene Flow in 3D Point Clouds.
- Just Go with the Flow: Self-Supervised Scene Flow Estimation
- Self-Supervised 3D Scene Flow Estimation Guided by Superpoints
- SFGAN: Unsupervised Generative Adversarial Learning of 3D SceneFlow from the 3D Scene Self
尽管这些方法取得了合理的准确性,但它们仍然落后于监督方法,突出了真实传感器数据和相应 3D 场景流标签的重要性。
在这项工作中,我们解决了自动驾驶领域三个关键挑战:
- 对合成数据集的依赖,这些数据集在现实场景中仍然泛化能力较差
- 实际驾驶场景中场景流标签的稀缺
- 现有3D场景流估计网络在真实激光雷达数据上的性能较差
受RigidFlow和RSF刚性运动假设启发,我们提出了一种新的场景流自动标注方法,该方法利用自动驾驶场景中普遍存在的刚性运动特征(图1)。
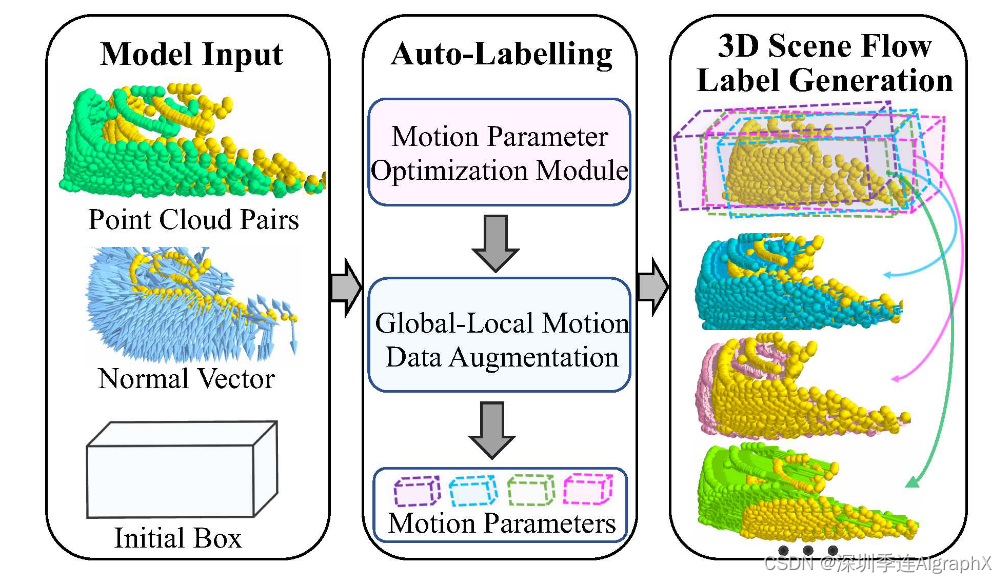
图1所示。三维场景流伪自动标注框架。给定点云和初始边界框,迭代优化全局和本地运动参数。通过随机调整这些运动参数来增强不同的运动模式,从而为3D场景流估计模型的训练创建多样化和逼真的运动标签集。
具体来说,我们利用 3D anchor boxes 来分割点云中 3D 对象。每个对象级框属性不仅包括位置和大小,还有旋转、平移、运动状态和法向量属性。通过利用box参数和帧间关联的约束损失函数,我们优化了box属性,然后将这些参数与源点云相结合,生成真实的目标点云。重要的是,生成的目标点云与源点云保持一一对应,能够有效地生成伪3D场景流标签。
为了捕捉多样化的运动模式,我们引入了一种新的 3D 场景流自动标注数据增强策略。利用每个box属性,我们模拟了向自车和周围环境的旋转、平移和运动状态属性添加高斯噪声。因此,我们获得了许多与现实场景非常相似的具有不同运动的3D场景流标签,为神经网络提供了丰富的真实训练数据,并显着提高了基于学习方法的泛化能力。
实验结果验证了我们的伪标签生成策略在各种模型和数据集上都能获得最先进的场景流估计结果(图2)。
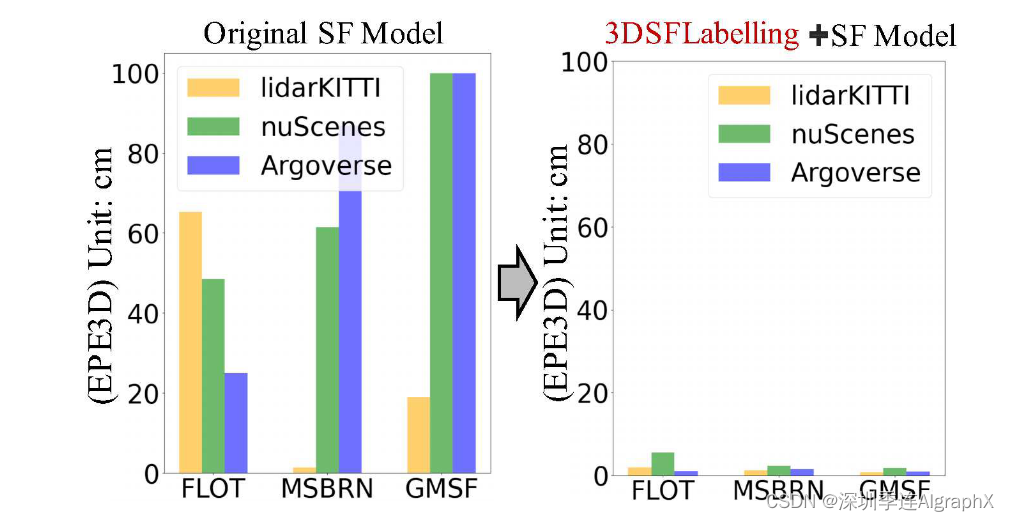
图2。我们提出的3D伪自动标注方法提高了准确性,在各自数据集上达到了低于2cm的EPE3D。
总之,我们的贡献如下:
- 我们为 3D 场景流伪标签的自动标注提出了一个新框架,显著提高了当前场景流估计模型的准确性,并有效地解决了自动驾驶中 3D 流标签的稀缺性。
- 我们提出了一种具有多个运动属性的通用 3D boxes 优化方法。在此基础上,我们进一步引入了一个即插即用的3D场景流增强模块,该模块具有全局-本地运动状态。这允许灵活调整自车运动和动态环境,为场景流数据增强设置一个新基准。
- 我们的方法在KITTI、nuScenes和Argoverse LiDAR数据集上实现了最先进的性能。令人印象深刻的是,我们的方法超越了所有有监督和无监督的方法,不需要任何合成数据和手动场景流标签。
Related Work
Supervised 3D Scene Flow Learning
近年来,基于点云深度学习三维场景流方法性能已经超越了传统方法。
- Learning Scene Flow in 3D Point Clouds
- DELFlow: Dense Efficient Learning of Scene Flow for Large-Scale Point Clouds
- Hierarchical Attention Learning of Scene Flow in 3D Point Clouds
FlowNet3D开创了点云学习3D场景流端到端方法。
一些工作利用 PWC 结构以从粗到细的方式学习 3D 场景流。
- HALFlow
- 3DFlow
- PointPWC
- WSAFlowNet
一些方法通过体素化点云并使用稀疏卷积或体素相关场来学习 3D 场景流来解决点的无序性。
- PV-RAFT
- DPV-RAFT
- SCTN
其他工作通过迭代程序细化估计场景流。
- MSBRN提出了双向门控循环单元,用于迭代估计场景流。
- GMSF和PT-FlowNet将点云transformer引入3D场景流估计网络中。
这些用于 3D 场景流的监督学习方法严重依赖于地面真值,均在 FT3D 数据集上进行训练,并在 StereoKITTI 上进行评估以进行网络泛化测试。
Unsupervised 3D Scene Flow Learning
- JGwF和PointPWC最初提出了几种自监督学习损失,如循环一致性损失和倒角损失。
- EgoFlow将3D场景流分为自车运动流和剩余的非刚性流,实现了基于时间一致性的自监督学习。
- SFGAN将生成对抗概念引入到三维场景流的自监督学习中。
- R3DSF、RigidFlow和LiDARSceneFlow等工作通过引入本地或对象级刚性约束大大提高了3D场景流估计的准确性。
- RigidFlow通过将源点云分解为多个超体素,显式地在超体素区域内强制刚性对齐。
- R3DSF分别考虑了背景和前景对象级别的3D场景流,依赖于分割和里程计任务(查看R3DSF原文,该方法能实现,需要in conjunction with other 3D tasks)。
3D Scene Flow Optimization
3D场景流优化技术表现出了卓越的泛化能力,近年来吸引了大量的学术研究。
- Graph prior通过使用点云的拉普拉斯来优化场景流尽可能平滑。
- NFSP引入了一种新的隐式正则化器——神经场景流先验,它主要取决于运行时优化和鲁棒正则化。
- RSF将全局自车运动与特定对象的刚性运动相结合,以优化 3D 边界框参数和计算场景流。
- FastNSF也采用了神经场景流先验,与学习方法相比,它在处理密集激光雷达点方面显示出了更多优势。
- SCOOP在运行时阶段,使用自监督目标直接优化流细化模块。
尽管基于优化方法用于 3D 场景流估计已经显示出令人印象深刻的准确性,但它们通常涉及高计算成本。
3DSFLabelling

与之前的自监督学习方法相比,我们提出了bounding box边界框元素优化,从原始未标注的点云数据中获取boxes和box运动参数。然后,我们使用object-box-level运动参数和全局运动参数,将每个box点和整个点云warp扭曲到目标点云,生成相应的伪3D场景流标签。
在每个object box warping过程中,我们建议增加每个对象运动属性和整个场景。这种多样性有助于网络捕获更广泛的运动行为。
Prerequisites
除了两个输入点云外,我们不需要任何额外的标签,例如对象级跟踪和语义信息,或自车运动标签。为了加强伪标签生成模块中的几何约束,我们使用 Open3D 生成粗略的逐点法线。尽管这些法线并不完全准确,但它们很容易获得,可以提供有用的几何约束。最后,根据输入点的范围,我们建立了具有特定中心 (x, y, z)、宽度 w、长度 l、高度 h 和旋转角 θ 的初始 3D anchor boxes。如图3所示,模型输入由初始anchor boxe集、PCs、PCt和点云法线Ns组成。
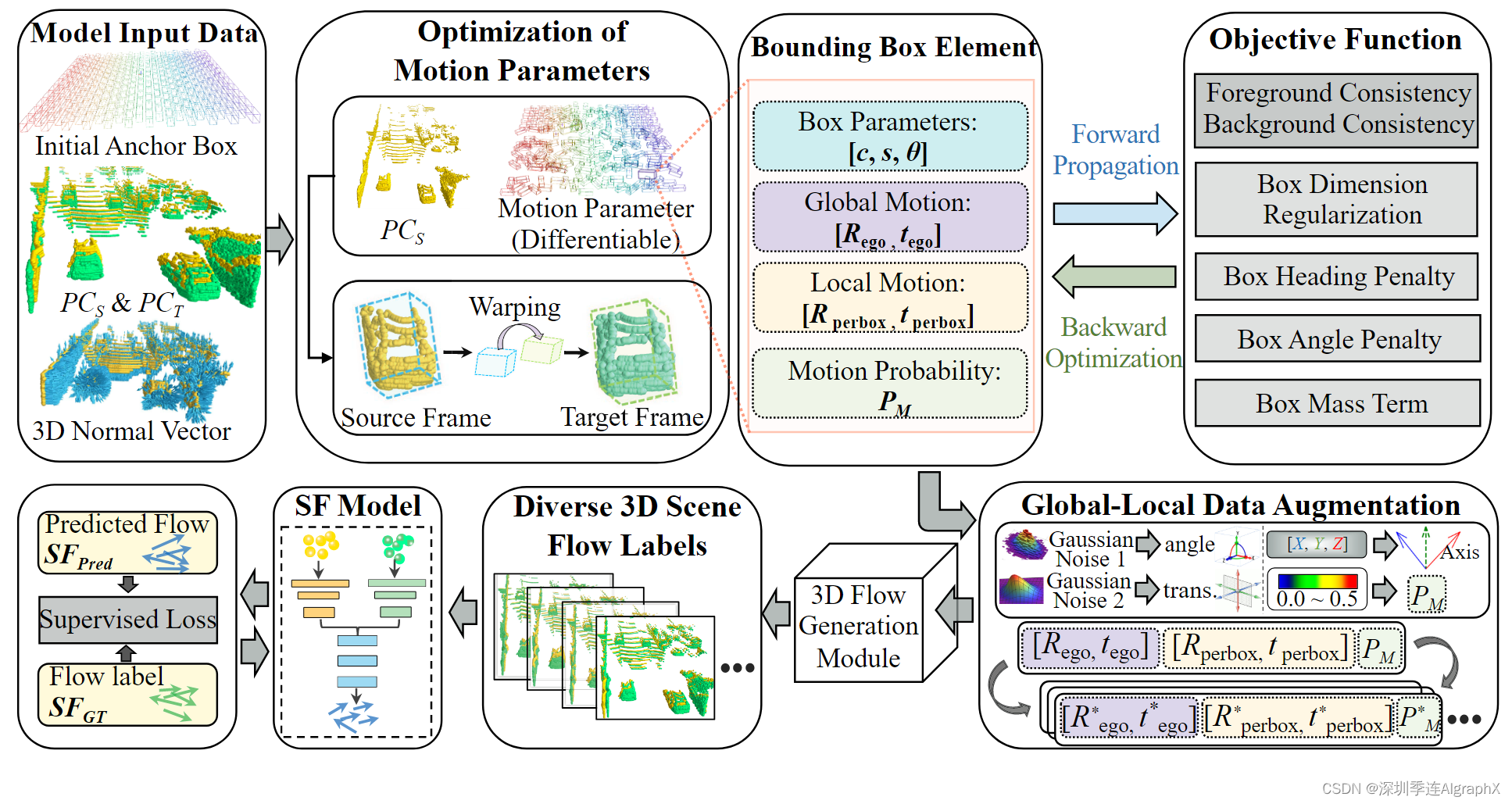
图3。提出了伪三维场景流自动标注学习框架。输入包括三维Anchor Box、一对点云及其对应的粗法向量。运动参数的优化主要更新边界框参数、全局运动参数、本地运动参数和框的运动概率。通过对6个目标函数的反向优化,更新箱体的属性参数。优化后,运动参数使用全局-本地数据增强模块模拟各种类型运动。单源帧点云,随着增强的运动参数,产生不同的3D场景流标签。这些标签用于指导监督神经网络学习逐点运动。
Motion Parameter Optimization Module
如图 3 所示,我们通过更新四组参数来展示模拟点云在实际自动驾驶中的运动过程:
- 可微边界框 Φ = [c, s, θ]
- 全局运动参数 Θ = [Rego, t ego]
- 每个框动参数 [Rperbox, t perbox]
- 每个框运动概率 Pm
变量 c、s 和 θ 分别表示 3D 框中心坐标、大小和方向。
受RSF启发,我们使用object-level bounding boxes对象级边界框的运动来表示逐点的3D运动,并通过sigmoid近似使step-like boxes可微。
通过将各个点转换为边界框,我们对场景引入了对象级感知,从而能够更自然地捕捉刚性运动。
这种方法在自动驾驶场景中被证明是有利的,其中大多数对象主要表现出刚性行为。此外,在自动驾驶背景下,大多数场景运动通常由自车运动引起。因此,需要设置全局运动参数来模拟整个场景的全局一致刚性运动。为了辨别每个盒子的运动是由自车运动引起的,我们还为每个边界框设置了一个运动概率。在初始一组四个运动参数的情况下,将源点云扭曲到目标帧,如下所示:
![]()
其中 Θ 表示全局运动参数,Φ表示每个边界框运动参数,Ω1和Ω2分别是背景和前景扭曲函数,生成扭曲的点云 PCΘ/T 和 PCΦ/T。Υ 表示删除点数太少的框。
基于真实目标帧和生成的目标帧 PCΘ/T 和 PCΦ/T ,我们定义损失函数来更新和优化框属性。我们分别计算背景和前景损失:
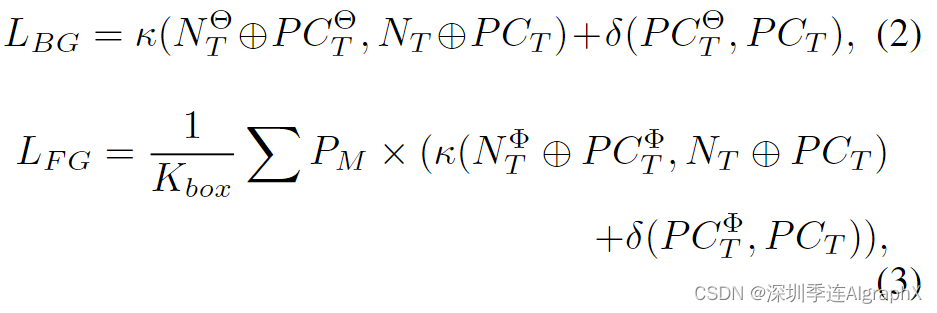
其中 κ 是计算变换点云和目标点云之间最近邻匹配的函数。δ是具有位置编码的成对距离函数。Kbox 是框的数量,Pm 是每个框的运动概率,术语 Nt ⊕ PCt 表示目标点云的法线和位置的串联。至于每个盒子的运动概率 Pm:
![]()
其中 σ(x) 表示 sigmoid 函数,α 是 sigmoid 中的超参数“斜率”,β 表示边界框的 3D 尺寸 w、l 和 h 向量的一半大小。
- 通过运动框参数Φ将源点云中的坐标值γ扭曲到目标点云。对于每个动态框,计算每个点与框中心的相对位置。更高的运动概率Pm被分配给更接近中心点。
- 一个固定的超参数 α,控制运动概率,可能无法有效地响应多样化和复杂的自动驾驶场景。因此,我们采用基于上一代迭代点最近邻一致性损失方差自适应计算 α。背景中不同点的最近邻一致性损失方差意味着场景中动态对象的分布。在方差较低运动物体较少的情况下,α应自适应减小,倾向于为点产生较低的运动概率Pm。
- 除了Lbg和Lfg外,我们还引入了box dimension正则化、航向项和角度项来约束边界框在合理范围内的维度、航向和旋转角。
- 我们还引入了一个质量项,以确保box内有尽可能多的点,使box估计运动参数更加稳健。
备注:软件工程量着实不少。
Data Augmentation for 3D Flow Auto-labelling
现有数据增强实践PointPWC-Net,向输入点添加一致随机旋转和噪声偏移,这确实产生了一定的好处。然而,在自动驾驶场景中,多个对象往往存在各种复杂的运动模式。为了使模型学习复杂场景运动规则,我们提出了一种新的数据增强方法,用于全局和本地级别运动场景流标注。我们的方法模拟了广泛的 3D 场景流数据变化,源自自车运动和动态对象运动,从而为保护丰富 3D 场景流标签提供了有希望的解决方案。
如图3所示,随机噪声分别应用于全局或本地运动参数。我们使用随机噪声为旋转方向生成随机旋转角度α和随机单位向量u。它们用于创建李代数 ξ。随后,利用Rodrigues旋转公式将李代数ξ转换为旋转矩阵M,并将其应用于原始旋转矩阵R,得到一个新的旋转矩阵R*,如下所示:
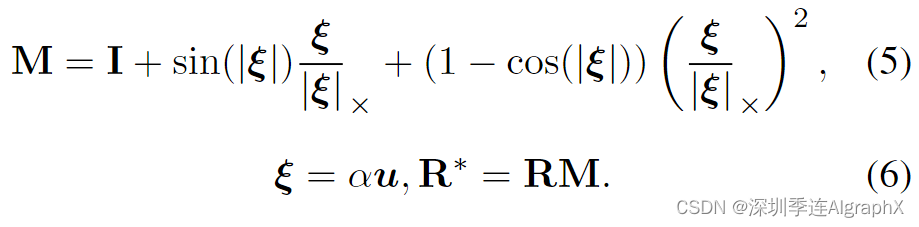
李代数元素ξ是标量α与单位向量u的乘积,表示旋转的大小和方向,α和u分别表示旋转的角度和轴。I是单位矩阵,ξ×是ξ的反对称矩阵。李代数直观方便地表示小SO(3)群变化。Rodrigues的旋转公式,从李代数映射到李群,有助于将基于角度的噪声转换为直接适用于旋转矩阵的形式。这种转换带来了数学上的方便,使旋转矩阵更新更简洁更高效。
备注:求解机器人位姿需要迭代法,并且表示机器人位姿的旋转群是连续群,然而差分是不连续的,在旋转群上不封闭,需要考虑连续群的性质来计算求导过程,完成迭代求解。所以引出用李代数来表示位姿。李群就是连续的群,特殊正交群SO(3)和特殊欧式群SE(3)都是李群中的一种。李代数可定义于李群的正切空间上,描述李群中元素局部性质。
重要的是,数据增强目标是动态移动的对象,因为不断向被视为静态对象的边界框添加不同的运动噪声可能会破坏原始数据分布。此外,还增强了平移和运动概率。如图3所示,我们在适当的范围内生成噪声,并直接将其添加到平移矩阵或运动概率中,从而产生增强的平移和运动概率。
Pseudo Label Generation for 3D Scene Flow
将运动参数输入到伪标签生成模块中,得到逐点的3D场景流标签。
标签生成模块的具体过程如图4所示。
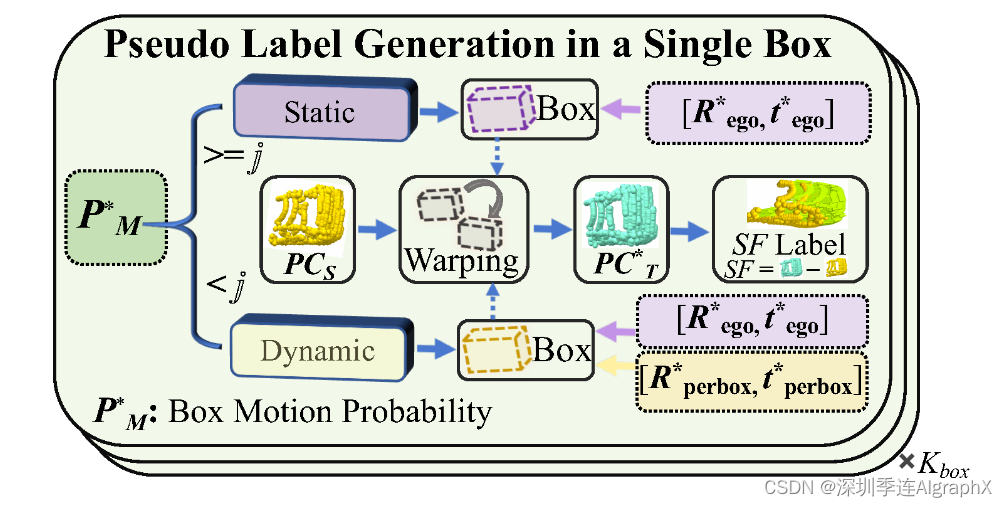
图4。提出伪标签生成模块。以扩大的运动概率P*/M,将边界框分为动态和静态两类。利用全局和本地运动参数,将PCs扭曲到目标点云PC*/T。最后,根据PC*/T和PCs之间的对应关系,导出了伪三维场景流标签SF。Kbox表示boxes数量。
我们通过运动概率 Pm 确定 3D 边界框运动状态。
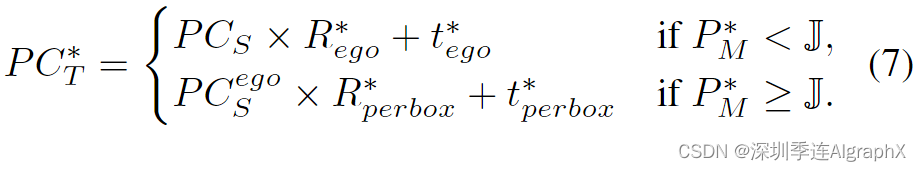
PCego/S是来自源点云动态框中的点,通过全局旋转和平移进行变换。当 Pm 小于阈值 J 时,当前边界框被认为是静态的。相反,如果 Pm 超过预定义的阈值 J,则当前边界框被认为是动态的。对于静态框,基于现有的全局运动,我们对所有静态框应用均匀噪声来模拟各种自车运动模式。通过将微小噪声添加到每个box运动概率Pm中,我们可以构造各种运动状态,并显示各种各样的场景运动。
在转换动态框之前,需要对所有点进行先验全局转换。对于动态边界框,我们在现有运动中添加了各种噪声,生成新的旋转和平移,从而创建了各种运动模式。一旦确定了每个box运动状态和参数,我们使用box运动参数将每个box内的源点云扭曲到目标帧,得到伪目标点云PC*/T。
生成的伪目标点云 PC*/T 和真实源帧点云 PCs 具有完美的对应关系。因此,通过从 PC*/T 直接减去 PCs 可以很容易地获得 3D 场景流标签:
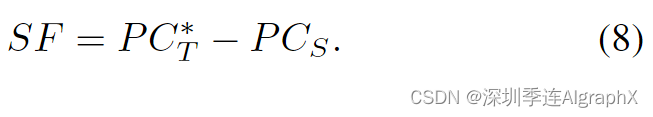
生成的场景流标签从真实的自动驾驶场景中捕获各种运动模式。他们帮助模型理解和调整复杂的驾驶条件。这提高了模型在不熟悉真实场景中的泛化能力。
Experiments
Datasets
Test Datasets: Graph prior 引入了两个自动驾驶数据集,Argoverse场景流和nuScenes场景流数据集。数据集中的场景流标签来自LiDAR点云、对象轨迹、地图数据和车辆姿态。数据集包含 212 和 310 个测试样本。R3DSF引入了激光雷达KITTI,它与StereoKITTI共享142个场景,通过Velodyne64光束激光雷达收集。与FT3D和StereoKITTI不同,激光雷达KITTI点云分布稀疏。请注意,LiDAR 场景流地面真值包含错误。我们通过将ground truth与第一个点云融合,为网络输入创建一个校正的第二帧来缓解这个问题。
Training Datasets used in previous methods: FT3D和StereoKITTI是用于训练先前3D场景流模型的常用数据集。FT3D 由 19,640 个训练对组成,而 StereoKITTI 包含 142 个密集点云,其中前 100 帧用于一些工作中的模型微调。一些作品在2,691对Argoverse 数据和1,513对nuScenes数据上训练他们的模型,3D场景流标注遵循Graph prior图先验设置。R3DSF训练集利用FT3D和语义KITTI数据集,依赖于语义KITTI的自车运动标签和语义分割标签。
Training Datasets used in our methods: 因为我们不需要训练数据任何标签,所以我们使用从原始数据中采样的 LiDAR 点云。为了在激光雷达KITTI上进行测试,我们使用KITTI里程计数据集序列00到09的LiDAR点云进行自动标注和训练。为了在nuScenes场景流数据集上进行测试,我们从nuScenes sweep 数据集350,000个LiDAR点云中随机抽取50,000对。为了在Argoverse场景流数据集上进行测试,我们使用Argoverse 2传感器数据集序列01到05的LiDAR点云进行自动标注和训练。在训练数据选择中,我们排除了测试场景。
Implementation Details
本文使用FLOT、MSBRN和GMSF三个著名的深度学习模型,证明了自动标注框架的有效性。这些模型分别使用最优传输理论、从粗到细的策略和transformer架构。在训练过程中采用了与原始网络一致的超参数。随机采样输入点云,从中过滤地面点,合并成 8192 个点。KITTI LiDAR点云数据仅限于前视图视角,保持了与以往研究的一致性。此外,我们利用四个场景流评估指标:平均端点误差(EPE3D)、ACC3DS、ACC3DR和异常值。
备注:感觉最优传输理论和共行几何特别有意思,计算共形几何 - 知乎.
Quantitative Results
实验结果如表1所示。我们在表中列出了性能最好的优化、自我监督和监督模型。我们的方法在所有数据集上都取得了很好的性能和指标。特别是,与基线GMSF相比, EPE3D值在大多数数据集上减少了一个数量级。所提出的自动标注方法生成有效的场景流标签,完美地模拟了现实世界中各种物体刚性运动。全局-本地数据增强进一步扩展了3D场景流标签。

我们还将这种即插即用的自动标注框架应用于三个现有模型,如表2所示。该方法显著提高了这些模型中3D场景流估计的准确性。
此外,许多现有的作品利用大量的模型参数或在测试过程中采用优化方法对三维场景流进行更精确的估计。这些方法非常耗时,并且在减少模型参数时无法确保准确性。我们提出的 3DSF 标注有效地解决了这一挑战。在表 3 中,通过使用小参数模型 FLOT (iter=1) 结合自动标注框架,我们超越了所有当前的监督、无监督、弱监督和优化方法。这有力地验证了生成现实世界标签在解决挑战方面的有效性。
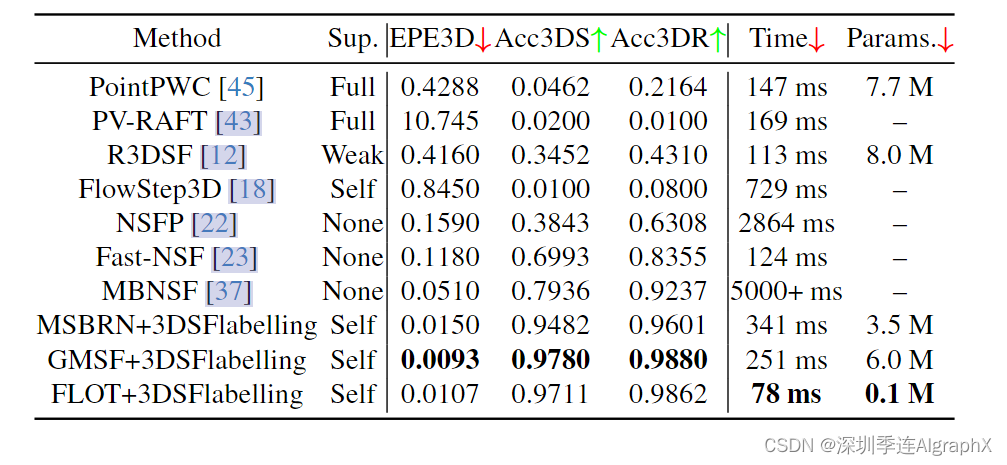
表3。Argoverse数据集上模型比较。'M'表示数百万个参数,时间以毫秒为单位。
Visualization
可同时参照消融实验内容。
Ablation Study
本节探讨了全局-本地数据增强的优势。在表 5 中,我们将现有 3D 场景流数据增强与我们提出的全局数据-本地增强方法进行了比较。我们的增强策略在所有评估指标中显示出显著增强。这归因于通过全局-本地数据增强对自动驾驶中各种运动模式的有效模拟。各种运动转换的引入充分利用了有限的训练数据来扩展各种3D场景流样式。更多的消融研究参考补充材料。

图5。我们的方法(GMSF+3DSFlabelling)与基线在LiDAR KITTI和Argoverse数据集上的配准可视化结果。通过三维场景流将源点云PCs变形为目标点云,得到估计目标点云PCsw。PCsw(蓝色)与目标点云PCt(绿色)重叠越大,场景流预测精度越高。为了更好地观察,局部区域被放大了。我们的3D场景流估计显著提高了性能。
Conclusion
我们将 3D 点云打包成具有不同运动属性boxes。通过优化每个box运动参数并将源点云扭曲到目标点云中,创建了伪3D场景流标签。我们还设计了一种全局-本地数据增强方法,引入各种场景运动模式,显著提高3D场景流标签的多样性和数量。对多个真实世界数据集测试表明,我们的 3D 场景流自动标注显著提高了现有模型性能。重要的是,这种方法消除了依赖手动标注需求。