NoSQL是什么
NoSQL : Not Only SQL , 本质也是一种数据库的技术,相对于传统数据库技术,它不会遵循一些约束,比如
: sql 标准、 ACID 属性,表结构等。
NoSQL分类
| 类型 | 应用场景 | 典型产品 |
|---|---|---|
| Key-value存储 | 缓存,处理高并发数据访问 | Redis memcached |
| 列式数据库 | 分布式文件系统 | Cassandra Hbase |
| 文档型数据库 | Web应用,并发能力较强,表结构可变 | mongoDB |
| 图结构数据库 | 社交网络,推荐系统,关注构建图谱 | infoGrid Neo4J |
MongoDB是什么
MongoDB 是一个文档数据库(以 JSON 为数据模型),由 C++ 语言编写,旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
文档来自于“JSON Document”,并非我们一般理解的 PDF、WORD 文档。
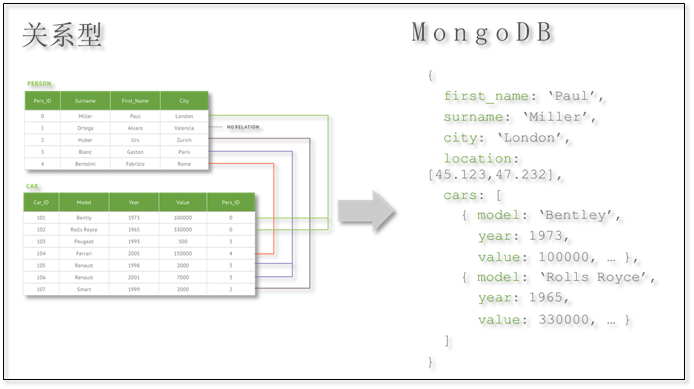
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,数据格式是 BSON,一种类似 JSON 的二进制形式的存储格式,简称 Binary JSON,和 JSON 一样支持内嵌的文档对象和数组对象,因此可以存储比较复杂的数据类型。Mongo 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。原则上 Oracle 和 MySQL 能做的事情,MongoDB 都能做(包括 ACID 事务)。
基础概念
-
数据库(database):最外层的概念,可以理解为逻辑上的名称空间,一个数据库包含多个不同名称的集合。
-
集合(collection):相当于SQL中的表,一个集合可以存放多个不同的文档。
-
文档(document):一个文档相当于数据表中的一行,由多个不同的字段组成。
-
字段(field):文档中的一个属性,等同于列(column)。
-
索引(index):独立的检索式数据结构,与 SQL 概念一致。
-
_id:每个文档中都拥有一个唯一的 _id 字段,相当于 SQL 中的主键(primary key)。
-
视图(view):可以看作一种虚拟的(非真实存在的)集合,与 SQL 中的视图类似。从 MongoDB3.4 版本开始提供了视图功能,其通过聚合管道技术实现。
-
聚合操作($lookup):MongoDB 用于实现“类似”表连接(tablejoin)的聚合操作符。
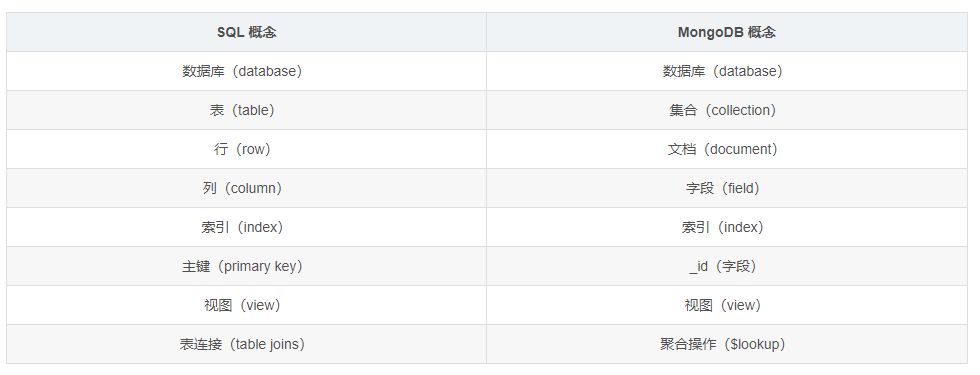
尽管这些概念大多与 SQL 标准定义类似,但 MongoDB 与传统 RDBMS 仍然存在不少差异,包括:
半结构化
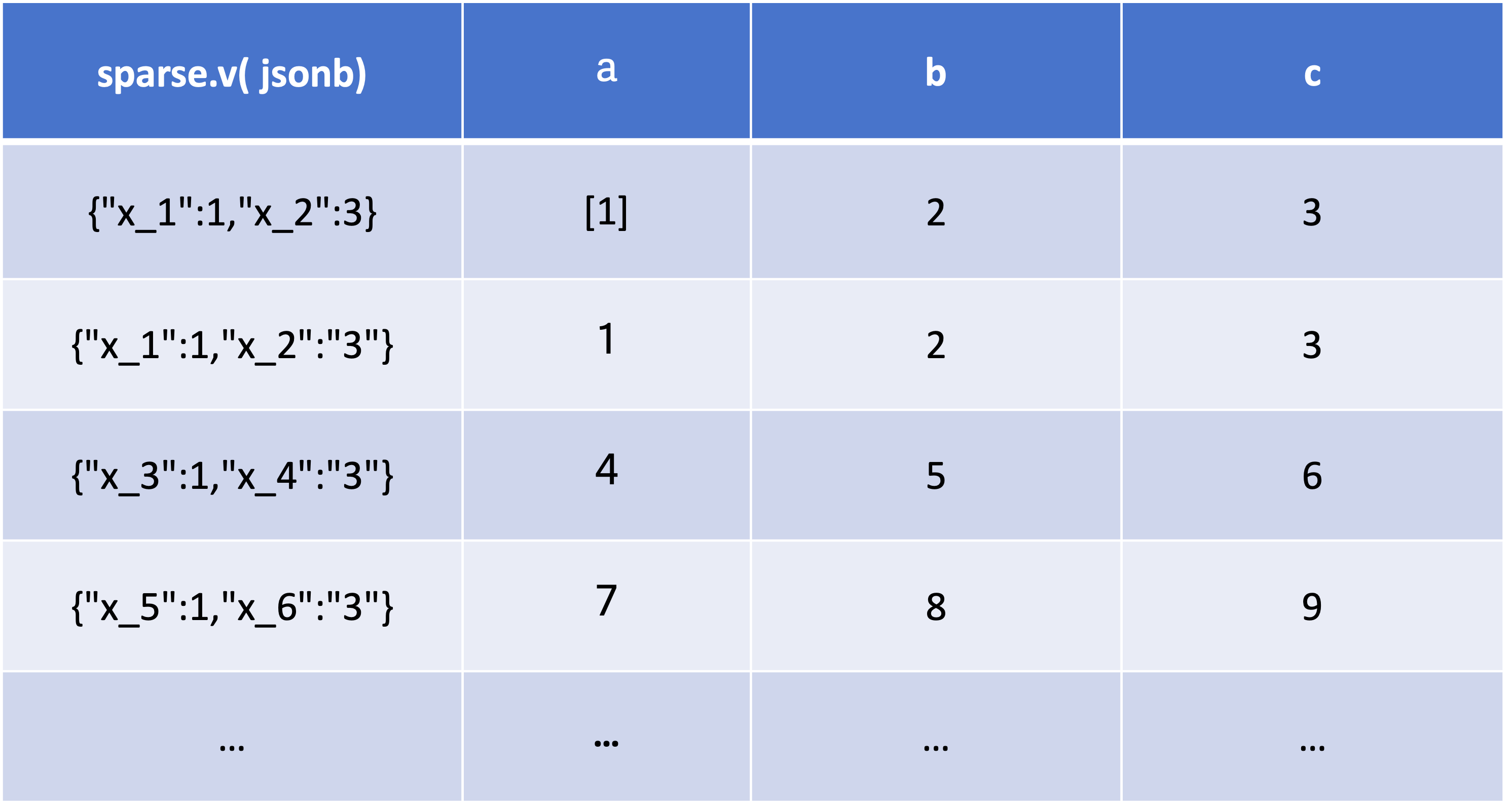
在一个集合中,文档所拥有的字段并不需要是相同的,而且也不需要对所用的字段进行声明。因此,MongoDB 具有很明显的半结构化特点。除了松散的表结构,文档还可以支持多级的嵌套、数组等灵活的数据类型,非常契合面向对象的编程模型。
弱关系
MongoDB 没有外键的约束,也没有非常强大的表连接能力。类似的功能需要使用聚合管道技术来弥补。
技术优势
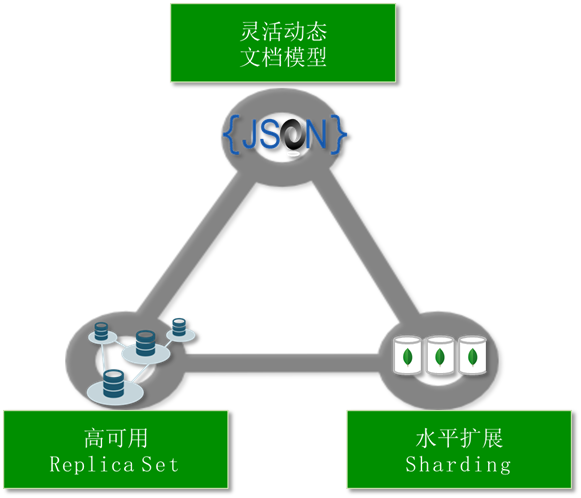
MongoDB 基于灵活的 JSON 文档模型,非常适合敏捷式的快速开发。与此同时,其与生俱来的高可用、高水平扩展能力使得它在处理海量、高并发的数据应用时颇具优势。
-
JSON 结构和对象模型接近,开发代码量低
-
JSON 的动态模型意味着更容易响应新的业务需求
-
复制集提供 99.999% 高可用
-
分片架构支持海量数据和无缝扩容
应用场景
从目前阿里云 MongoDB 云数据库上的用户看,MongoDB 的应用已经渗透到各个领域:
-
游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新;
-
物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来;
-
社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能;
-
物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析;
-
视频直播,使用 MongoDB 存储用户信息、礼物信息等;
-
大数据应用,使用云数据库 MongoDB 作为大数据的云存储系统,随时进行数据提取分析,掌握行业动态。
MongoDB存储原理
MongoDB从3.0开始引入可插拔存储引擎的概念。目前主要有MMAPV1、WiredTiger存储引擎可供选择。在3.2版本之前MMAPV1是默认的存储引擎,其采用linux操作系统内存映射技术,但一直饱受诟病;3.4以上版本默认的存储引擎是wiredTiger。
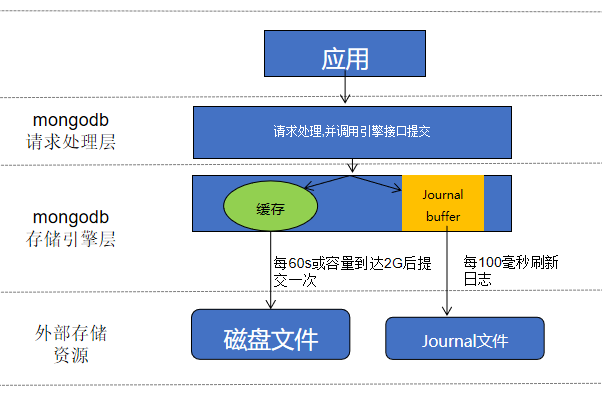
WiredTiger 写入数据的流程:
-
应用向 MongoDB 写入数据(插入、修改或删除)。
-
数据库从内部缓存中获取当前记录所在的页块,如果不存在则会从磁盘中加载(Buffer I/O)。
-
WiredTiger 开始执行写事务,修改的数据写入页块的一个更新记录表,此时原来的记录仍然保持不变。
-
如果开启了 Journal 日志,则在写数据的同时会写入一条 Journal 日志(Redo Log)。该日志在最长不超过 100ms 之后写入磁盘。此外,Journal 日志达到 100MB,或是应用程序指定,写操作都会触发日志的持久化。
-
数据库每隔 60s 执行一次 CheckPoint 操作,此时内存中的修改会真正刷入磁盘。
MongoDB索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。索引主要用于排序和检索
单键索引
在某一个特定的属性上建立索引,例如:db.users. createIndex({age:-1});
-
mongoDB在ID上建立了唯一的单键索引,所以经常会使用id来进行查询;
-
在索引字段上进行精确匹配、排序以及范围查找都会使用此索引;
复合索引
在多个特定的属性上建立索引,例如:db.users. createIndex({username:1,age:-1,country:1});
-
复合索引键的排序顺序,可以确定该索引是否可以支持排序操作;
-
在索引字段上进行精确匹配、排序以及范围查找都会使用此索引,但与索引的顺序有关;
-
为了性能考虑,应删除存在与第一个键相同的单键索引
多键索引
在数组的属性上建立索引,例如:db.users. createIndex({favorites.city:1});
-
针对这个数组的任意值的查询都会定位到这个文档,既多个索引入口或者键值引用同一个文档。
地理空间索引
在移动互联网时代,基于地理位置的检索(LBS)功能几乎是所有应用系统的标配。MongoDB 为地理空间检索提供了非常方便的功能。地理空间索引(2dsphereindex)就是专门用于实现位置检索的一种特殊索引。db.users.createIndex({location : "2dsphere"})
全文索引
MongoDB 支持全文检索功能,可通过建立文本索引来实现简易的分词检索。db.users.createIndex( { comments: "text" } )。
-
MongoDB 的文本索引功能存在诸多限制,而官方并未提供中文分词的功能,这使得该功能的应用场景十分受限。
哈希索引
不同于传统的 B-Tree 索引,哈希索引使用 hash 函数来创建索引。db.users.createIndex({username : 'hashed'})
-
在索引字段上进行精确匹配,但不支持范围查询,不支持多键 hash。Hash 索引上的入口是均匀分布的,在分片集合中非常有用。
MongoDB 索引底层实现原理分析
MongoDB 是文档型的数据库,它使用BSON 格式保存数据,比关系型数据库存储更方便。比如之前关系型数据库中处理用户、订单等数据要建立对应的表,还要建立它们之间的关联关系。但是BSON就不一样了,我们可以把一条数据和这条数据对应的数据都存入一个BSON对象中,这种形式更简单,通俗易懂。MySql是关系型数据库,数据的关联性是非常强的,区间访问是常见的一种情况,底层索引组织数据使用B+树,B+树由于数据全部存储在叶子节点,并且通过指针串在一起,这样就很容易的进行区间遍历甚至全部遍历。MongoDB使用B-树,所有节点都有Data域,只要找到指定索引就可以进行访问,单次查询从结构上来看要快于MySql。
MongoDB部署模型
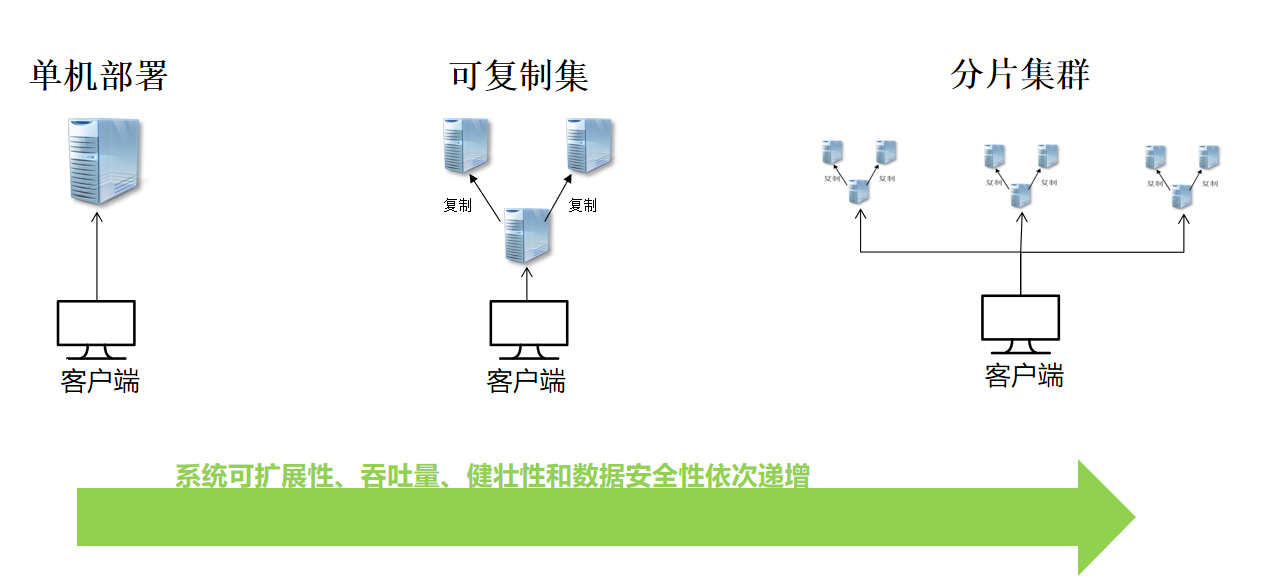
在生产环境中,不建议使用单机版的 MongoDB 服务器。原因如下:
-
单机版的 MongoDB 无法保证可靠性,一旦进程发生故障或是服务器宕机,业务将直接不可用。
-
一旦服务器上的磁盘损坏,数据会直接丢失,而此时并没有任何副本可用。
复制集
MongoDB 复制集(Replication Set)由一组 MongoDB 实例(进程)组成,包含一个 Primary 节点和多个 Secondary 节点,MongoDB Driver(客户端)的所有数据都写入 Primary,Secondary 从 Primary 同步写入的数据,以保持复制集内所有成员存储相同的数据集,提供数据的高可用。复制集提供冗余和高可用性,是所有生产部署的基础。它的现实依赖于两个方面的功能:
-
数据写入时将数据迅速复制到另一个独立节点上
在复制集架构中,主节点与备节点之间是通过 oplog 来同步数据的,这里的 oplog 是一个特殊的固定集合,当主节点上的一个写操作完成后,会向 oplog 集合写入一条对应的日志,而备节点则通过这个 oplog 不断拉取到新的日志,在本地进行回放以达到数据同步的目的。
oplog是什么
-
MongoDB oplog 是 Local 库下的一个集合,用来保存写操作所产生的增量日志(类似于 MySQL 中 的 Binlog)。
-
它是一个 Capped Collection(固定集合),即超出配置的最大值后,会自动删除最老的历史数据, MongoDB 针对 oplog 的删除有特殊优化,以提升删除效率。
-
主节点产生新的 oplog Entry,从节点通过复制 oplog 并应用来保持和主节点的状态一致。
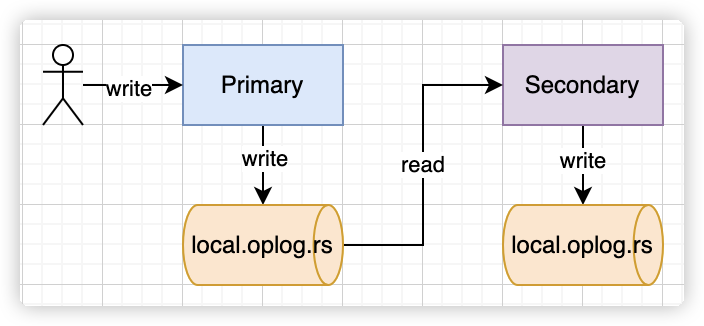
-
在接受写入的节点发生故障时自动选举出一个新的替代节点
MongoDB 的复制集选举使用 Raft 算法(https://raft.github.io/)来实现,选举成功的必要条件是大多数投票节点存活。
分片集群
分片(shard)是指在将数据进行水平切分之后,将其存储到多个不同的服务器节点上的一种扩展方式。分片在概念上非常类似于应用开发中的“水平分表”。不同的点在于,MongoDB 本身就自带了分片管理的能力,对于开发者来说可以做到开箱即用。
为什么要使用分片?
MongoDB 复制集实现了数据的多副本复制及高可用,但是一个复制集能承载的容量和负载是有限的。在你遇到下面的场景时,就需要考虑使用分片了:
-
存储容量需求超出单机的磁盘容量。
-
活跃的数据集超出单机内存容量,导致很多请求都要从磁盘读取数据,影响性能。
-
写 IOPS 超出单个 MongoDB 节点的写服务能力。
垂直扩容(Scale Up) VS 水平扩容(Scale Out):
-
垂直扩容:用更好的服务器,提高 CPU 处理核数、内存数、带宽等;
通过增加单个服务器的能力来实现,例如使用更强大的CPU,增加更多的内存或存储空间量。由于现有技术的局限性,不能无限制地增加单个机器的配置。此外,云计算供应商提供可用的硬件配置具有严格的上限。其结果是,垂直扩展有一个实际的最大值。
-
水平扩容:将任务分配到多台计算机上;
分片集群架构
MongoDB 分片集群(Sharded Cluster)是对数据进行水平扩展的一种方式。MongoDB 使用分片集群来支持大数据集和高吞吐量的业务场景。在分片模式下,存储不同的切片数据的节点被称为分片节点,一个分片集群内包含了多个分片节点。当然,除了分片节点,集群中还需要一些配置节点、路由节点,以保证分片机制的正常运作。
本文由 mdnice 多平台发布