理解字符编码,请参考:unicode ucs2 utf16 utf8 ansi GBK GB2312 CSDN博客
了解windows字符显示必须了解locale概念 参考:揭密 Windows 上的各种 locale - 知乎
汉字(或者说多字节字符)的存放需求,是计算机中各种编码问题的最直接原因。如果程序不直接使用汉字,或间接在所有操作步骤中统一使用utf-8编码,就不需要考虑字符编码的问题。
将所有内容文件、源文件全部采用带BOM的utf8编码,编译器设置成使用utf8编码,setlocal设置成使用utf8编码,是解决乱码、汉字字符串导致跨平台编译不通过 以及 汉字信息遗失的最有效手段。utf8在网络传输时也不需要去考虑大小端字节序问题(所以互联网普遍采用utf8)。
1、qt ide 默认新建文件存储为utf8,mingw编译器默认输入为utf8,编译器输出的字符也默认为utf8。
2、在vs2015及以下,默认文件存储为ansi,编译器默认输入为ansi,编译器默认输出的字符也是ansi。VS2015(Visual Studio 2015 Update 2)及以上版本,可以使用无BOM的utf8编码。
如果将带有中文字符(包括中文注释)的 无BOM 的 utf8 字符编码的源码文件放到vs下编译,基本都会碰到编译器报错的问题。
3、vs2015默认采用ansi(GB2312)编码,vs2022默认采用utf8编码。可以通过指定source-charset编译参数告诉编译器 工程 源码所使用的 字符编码(参见下方的 编译器对文字编码处理 章节)。
一、源文件编码、编译器对文字编码处理、最终的IDE显示字符编码
首先要明确区分源文件编码、IDE显示字符编码、编译器对文字编码处理是三个不同的分割独立的操作阶段。程序正确显示汉字,需要这三个阶段的字符编码都明确的正确的对接。
一个程序三个独立的字符编码阶段:

1、源文件编码
是写入源文件时就设定好的,指定了字符存放到文件中的字符编码方式。vs2015保存文件时(在中文环境下)默认使用ansi(GB2312)编码,vs2022保存文件时,默认使用带BOM的utf8编码。vs IDE上只有一个 高级保存选项 来逐个文件进行更改编码的操作:vs高级保存选项在哪-CSDN博客 。另外还有一个安装Force UTF-8 插件的操作可以让保存的文件为utf8编码保存。
qt中默认保存源码文件的字符编码可以自己设置,默认为utf-8+bom存在则保留。最好配置成utf-8+ "如果编码是utf-8则添加",这样可以使含有中文的代码在vs编译器下也能进行编译。也可以通过 编辑->select encoding来进行逐个文件更改编码操作。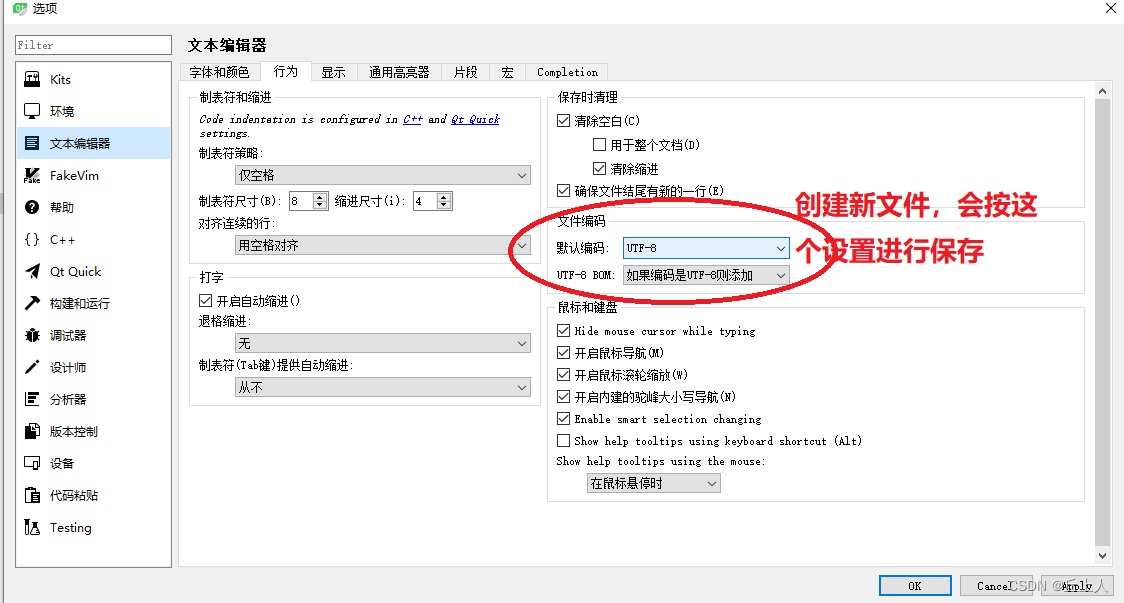
需要注意的是编译器未能正确识别到文件编码时,中文注释也能影响编译器对源文件进行解析。
2、编译器对文字编码处理、自主或第三方库强制使用字符编码
这个阶段的处理过后,字符会按 编译器对文字编码处理结果 或者 自主/第三方库强制使用字符编码 将存在的多字节字符 存放到.obj以及后续的exe文件中。这些操作控制着程序运行时内存中的字符编码,明确了解这个阶段的字符编码对程序正确使用多字节编码极为重要。
编译器对文字编码处理
1、vs 编译器: vs ide中在工程->属性->配置属性->C/C++->命令行->其它选项 中加入下面设置源码文件编码和执行文件编码的参数: /source-charset:GB18030 /execution-charset:utf-8
source-charset告诉编译器你的所有源文件使用了什么编码,如果这个参数不设置,编译器会根据bom头进行识别,如果无BOM头vs 2015编译器默认为GB13080编码(vs2022默认保存文件为带BOM的utf8编码,而无BOM头的文件也会被认为是GB13080编码)。vs编译器需要根据BOM头来识别是unicode的utf8编码、还是unicode的utf16(大小端)编码。
execution-charset告诉编译器你要将字符串编译后的存放成什么编码,vs2015默认使用GB2312(这种情况下,你会看到"𬌗"字在文件中正常,但调试时内存中却不见了。对于超出GB2312字符集的文字,会被编译器认为不可识别,编译器(vs2015)将会用值为0x3f3f的两个字节去替换而导致文字遗失),vs2022默认使用utf8。
windows下所有charset的名称都可以在vs ide的文件->高级保存选项->编码中找到,也可以在官网找:代码页标识符 - Win32 apps | Microsoft Learn
2、gcc编译器:gcc或者类似gcc的编译器则在编译选项中加入这两个参数: -finput-charset=UTF-8 -fexec-charset=UTF-8
道理与上面类似。区别是input-charset默认是utf-8;exec-charset默认是utf-8。
在qt中,通过.pro工程文件中设置QMAKE_CXXFLAGS参数来设置这两个编码,针对使用不同编译器要用不同的参数,比如使用gcc会类gcc编译器时,需要在工程.pro文件中加入下面参数
QMAKE_CXXFLAGS+=-finput-charset=UTF-8
QMAKE_CXXFLAGS+=-fexec-charset=GB18030如果希望字符串不按照编译器整体的编译方案走,比如vs编译器采用默认ansi(GB2312)编码存放字符串,而你非要强制指定某个字符串以utf8的编码方式存入变量,则需要在字符串前加入u8;如果希望强制以utf16(宽字符)的编码方式将字符保存到wchar_t类型中,则在字符串前面加 L 。
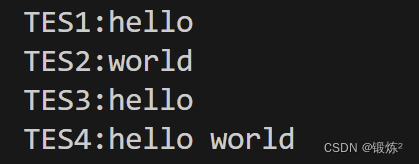
下面是使用qt中mingw编译器编译后的,字符串中存放的编码(看调试结果中的p1、p2、p3的值)。(GB2312中没有”𬌗“字,所以让编译器以GB18030的编码方式存放字符串)
当在qt使用vs的编译器时,qt的对源文件的处理会与在vs ide中对源文件处理操作是一致。
在vs ide中,源文件中有中文时,可以将源文件保存为默认的GB2312编码。如果要指定用utf8编码保存文件,则必须要为utf8的源文件加入BOM头,否则极有可能会因为有中文而出现编译错误。
下面的案例中(在qt5中使用vs2015编译器,未设置input-charset 和exec-charset值),main.cpp不管是GB18030还是带BOM的utf-8编码,编译和运行时都会有这个结果,pstr1以ansi编码保存了字符串,pstr2以utf8编码保存了字符串。对应的编译后的main.obj文件以及exe中也会保存这样的结果。(如果文件以utf-8无BOM保存,这个例子中的"哦" 字会导致vs 2015/ vs2022的编译器编译失败)
vs2015默认是用ansi(2312)编码保存(vs2022默认是utf8编码),用默认的ansi编码保存源文件最大问题就是会导致不在GB2312编码中的中文文字信息的丢失!!!比如下面的 "𬌗" 字,不在GB2312范围内,而在GB18030范围内。

在windows+qt+vs 编译器的场景下,如果因为 无BOM的utf8编码的源码文件中 有汉字 导致编译不通过,可以按下面的步骤将源文件转变成带BOM的utf8编码的源文件。

qt的ui文件和qrc文件都只能使用utf-8编码,因为qmake对这些文件进行处理时无法识别其他编码。
自主或第三方库强制使用字符编码
C++11中引入了L操作符,将字符串强制转换成unicode的utf16编码保存在编译后的文件中。
C++17中引入了u8操作符,将字符串强制转换成unicode的utf8编码保存在编译后的文件中。
char str1[]=u8"你好𬌗"; //告诉编译器,这个字符串强制保存成unicode的utf8编码的字符串。obj文件和exe文件以及运行时内存中存放的字符编码都是unicode的utf8编码,E4BDA0 E5A5BD F0AC8C97
wchar_t str2[]=L"你好𬌗";//告诉编译器,这个字符串强制保存成unicode的utf16编码的字符串,obj文件和exe文件以及运行时内存中存放的字符编码都是unicode的utf16编码 ,4F60 597D D870DF17第三方库进行字符转换:
iconv进行字符编码的的显示转换:https://www.cnblogs.com/demon90s/p/7493566.html
QString和QTextCodec进行字符编码的显示或隐式转:QString 与 字符编码 QTextCodec
windows的widechartomultibyte和multibytetowidechar的字符转换:unicode ucs2 utf16 utf8 ansi GBK GB2312 互转 及 渲染_ucs2编码转换-CSDN博客
为编译器错误指定源码文件编码
需要注意的通过语法层面强制的编码并不能保证一定正确,比如你保存了源文件为ansi,而给编译器指定了错误的输入文件编码方式,比如在qt中设置了QMAKE_CXXFLAGS += "/source-charset:utf-8"(vs编译器)/"-finput-charset=UTF-8"(gcc或类gcc编译器)。那么编译器对源文件解释的时候就出错了,读入内存中的字符编码自然也不是预期的。另外编译器有对字符的检测功能,指定的字符编码中被认为非法字符时,编译器就会发出编译错误。下面是我挑选的两个编译能通过的汉字,可以按照这里说的做个尝试。会发现编译器会将ansi当做utf8编码而存入内存。像这种问题在vs/qt混用,特别是有新手的时候的时候应该能被无意触发的。
#include <iostream>
int main(int argc, char *argv[])
{
char str1[16] = "a忙毛";
char str2[16] = u8"a忙毛";
wchar_t str3[8] = L"a忙毛";
int buffer1[4] = {};
int buffer2[4] = {};
int buffer3[4] = {};
memcpy(buffer1, str1, 16);
memcpy(buffer2, str2, 16);
memcpy(buffer3, str3, 16);
return 0;
}
不管是qt ide 还是vs ide 。不管采用哪种编译器,编译器的source-input是对整个工程全局有效的,工程下不同文件采用不同的字符编码方式,也会出现这样的问题。最简单的就是全部统一采用带BOM的utf8编码。指定输入为utf8,指定内存中存放也使用utf8。
3、IDE显示时使用的字符编码
是IDE的显示和编辑字符时采用的编码,这是与制作IDE输入框的图形开发套装(GUI库)有关的,更与字库有关。字符从内存到显示,首先要从当前使用的字库中找到字符的显示信息然后进行逐个文字渲染成图像。
字库中存放 所支持的字符集的 所有文字的显示信息,有的字库只支持ascii字符集,有的字库只支持gb2312字符集,有的字库能支持gb18030L3级别的字符集,有的字库只支持日文相关的字符集,有的字库只支持韩文相关的字符集等等。字库中可能存放文字的点阵(单字缩放时会产生锯齿),也可能存放文字的矢量信息。但最关键的是字库为了能在所有系统中都通用,需要采用unicode字符集的编排方式进行排列,需要能快速通过unicode编码快速找到字符的显示信息。另外字库会支持单字节ASCII码的查询,专用于ASCII码的快速显示。
鉴于这个原因,有大量文字显示的场景,应该尽可能将字符串采用unicode的utf16编码存放到内存中,以提升效率。毕竟utf8编码会多一个转码成utf16的过程。
关于文字的渲染,不管底层使用windows 的GDI还是directx,还是第三方库opengl+freetype、qt、gtk,主流的都是支持输入Unicode的utf16编码。可能有一些开发板还使用点阵字库,可能只有2字节的gb2312编码,甚至只支持ascii编码。
15.5 文本渲染 - 知乎
如何在OpenGL中显示unicode文本?_如何在文本框中迭代Unicode?腾讯云
控制台显示字符
另外控制台输出和显示还有另外的问题,简体中文版的windows的控制台默认支持GB2312字符的显示。控制台不支持显示utf16或utf32这样的不兼容单字节的ascii编码的宽字节unicode的编码方案,但是支持兼容asii编码的unicode的utf8编码方案!!!(猜测很多命令行命令并没有做宽字符输出的功能,因为宽字符输出要求字母也是用两个字节)控制台是支持兼容ascii编码的ansi编码和utf8编码的显示的。
通过加入下面的代码设置控制台支持哪种字符编码
#include <windows.h>
//控制台同一时刻只能支持一种编码
system("chcp 936"); //设置控制台接下来 支持GB2312编码 的字符的显示。
system("chcp 65001"); //设置控制台接下来 支持utf8编码 的字符的显示。
#include <windows.h>
#include <wincon.h>
SetConsoleOutputCP(65001);//设置控制台接下来支持utf8编码 //https://learn.microsoft.com/zh-cn/windows/console/setconsoleoutputcp 控制台同一时刻只能支持显示一种字符编码。 通过控制台的右键->属性->选项可以进行查看
通过setlocale()设置也可以设置控制台支持的显示的字符编码。
windows下的locale揭秘 跳出抽象名词的泥潭, 揭密 Windows 上的各种 locale - 知乎
用于设置C语言底层库的
通过setlocale()有效设置为非"C"之后,chcp的操作会失效。

//vs下 设置的字符串不用考虑大小写。
setlocale(LC_ALL, ".utf8");//设置成utf8,等效字符串有 ".UTF8" ".UTF-8" ".utf8" ".utf-8" 或者在前面加上chinese_china或者Chinese (Simplified)_China(不区分大小写) ,以及"zh_CN.utf8" "zh_cn.utf8" "en_us.utf8" "ja_JP.Utf-8" , "Chinese (Simplified)_China.65001"
setlocale(LC_ALL, "Chinese (Simplified)_China.936");//设置成gb2312,等效字符串有:"Chinese (Simplified)_China","zh_CN","zh_cn","chinese","chinese.936","Chinese_China.936","chinese_china",
setlocale(LC_ALL, "" );//设置成系统默认的编码,与setlocale( LC_ALL, ".ACP" );等效。windows的简体中文版默认值一般就是chinese_china.936
setlocale(LC_ALL,nullptr);//获取当前的locale
setlocale(LC_ALL,"C");//设置成C locale
mingw编译器中使用的C++库 libstdc++-6 对setlocal中的字符串解释以及功能,没有windows vs提供的C++标准库ucrt.lib+vsruntimelib 库中的setlocale所支持的全面,可能是使用的libstdc++的版本问题。下面是windows下的mingw所支持的编码字符串,不知道为何不支持utf8。
".936" "chinese_china.936" "uk" "us" ".1252" "English_United Kingdom.1252" "English_United States.1252" setlocale成功后,可以将wcout的内容输出到控制台窗口(pp返回字符串查看是否设置成功,下面是vs中的结果,mingw中wcout也仍然无法输出,且mingw的stdlibc++的setlocale不支持设置utf8):
参考:控制台代码页 - Windows Console | Microsoft Learn
setlocale()函数的作用-CSDN博客
std::setlocale详解_setlocale c++-CSDN博客
记录Windows下开发C/C++如何避免乱码 - 知乎
控制台codepage - Windows Console | Microsoft Learn
codepage 标识符 - Win32 apps | Microsoft Learn
How to add Custom Fonts to Command Prompt in Windows 11/10
字符集 - Win32 apps | Microsoft Learn
二、内容文件字符编码与字符编码识别
内容文件编码是外源性的,不同于编程过程中那样可以整个过程明确把控字符编码。然而文件头中并不存放字符编码信息,应用程序想正确获取文件中字符编码,需要做额外的识别工作。
windows下的文本编辑工具大部分默认存放为ansi字符编码,linux下的文本编辑工具大部分默认存放为无BOM的utf8字符编码,一些跨操作系统的软件存放文件也有各自的默认存放设置。而内容文件经常有跨平台访问的需求,且系统文件头中没有广泛通用的存放字符编码的信息规范。这是导致文本字符乱码的一个原因,也因此有了对内容文件字符编码 识别的需求。
对于使用unicode字符编码的内容文件,unicode规范给出了明确的编码字符识别建议,就是在文件开头加入BOM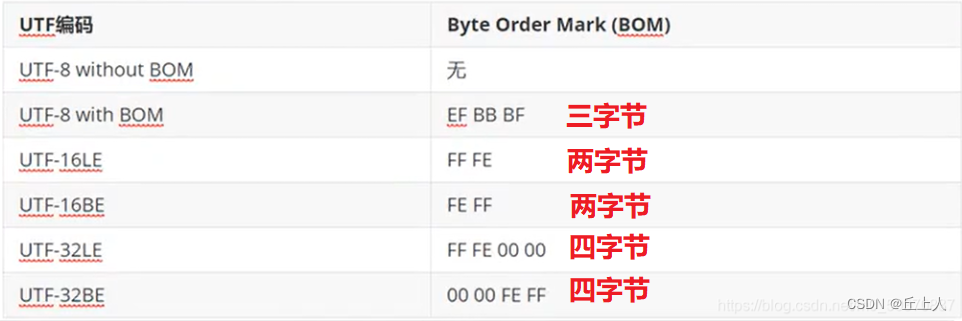
对于有存放BOM头的内容文件,很容容易就能识别出来文件采用的字符接是unicode,编码是unicode的BOM对应的编码方案。
对于没有存放BOM头的内容文件,就需要预读内容,逐个字节进行识别解析,来判断是采用了哪种编码。为了了解这个识别过程,需要了解文字在计算机中实际存储的值,需要了解各种编码方案的差异,下面是各种编码:
ASCII编码:ASCII码对照表-BeJSON.com
GB2312编码:完全兼容ASCII码,范围是 高字节(A1-FE)低字节(A1-FE)(双字节)+ ASCII(单字节) ,其中汉字的编码范围是 高字节(B0-F7)低字节(A1-FE) 。 GB2312汉字编码字符集对照表BeJSON.com
GBK编码:完全兼容GB2312编码,范围是 高字节(81-FE)低字节(40-FE) 双字节)+ ASCII(单字节) ,其中不包括低字节为7F的组合(也就是说 xx7F的编码都被排除)。
最全面的GBK编码表/GBK字符集 - 常用参考表对照表
ascii中0x08表示回退,向前删除一个字符;0x7f表示向后删除一个字符,所有与ascii兼容的字符编码(机器码),都需要排除这两个字符。
GBK 编码中低位字节0x40~0x7E 0x80~0xFE 为什么要剔除xx7F? - 知乎
GB18030编码:完全兼容GBK编码,是一字节或两字节或四字节编码。
UTF8编码:完全兼容ASCII编码,是一字节或多字节编码,且多字节编码中不存在0x7f或0x08这样的字符,编码方案如下:
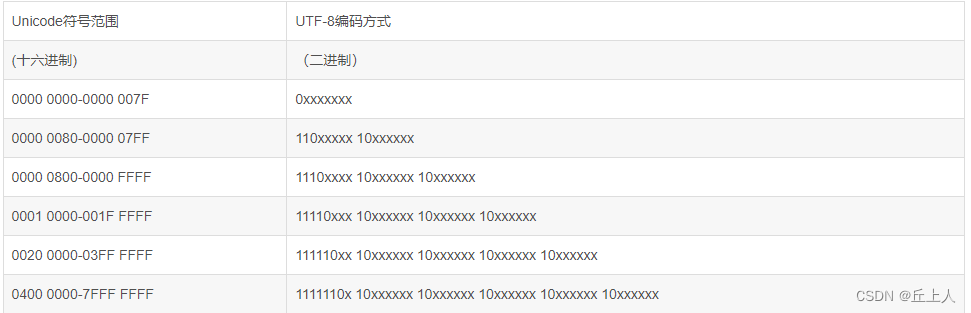
可以看到UTF8的编码 ,多字节编码时,每个字节开头是有严格规律的,这样的字节流在GB系列字符编码中是不容易出现的。正是这个现象,识别GB系列编码还是UTF8编码时,都是先认定为UTF8编码,逐个字节读取,如果遇到非法字节,或者字符解析出的结果非法,就断定不是UTF8编码。就可以重新开始尝试GB2312,如果在GB2312中非法,就尝试GBK,依此类推。
识别到外源性的内容文件编码后再按照程序预先的方案将字符串对字符串进行处理。
unicode 第0个平面 字符编码 及 分区 - 365建站网
杂谈
VS IDE 工程的属性->常规->字符集中的 “使用 Unicode 字符集” 与 “使用多字节字符集” 的使用场景如下:
#include <tchar.h>
.....
TCHAR str[]=_T("你好");使用TCHAR这样的宏来将 底层使用char类型的多字节编码(MBCS) 还是wchar_t类型的utf16编码(unicode) 进行包装,并对 相关的有字符参数的程序接口 进行包装,比如windows的接口OutputDebugStringW()和OutputDebugStringA() 用通过宏包装成OutputDebugString()。在工程->属性->常规->字符集 中选择 ”使用 Unicode 字符集“, 编译器会为工程添加 _UNICODE 宏;选择“使用多字节字符集” ,编译器会为工程添加 _MBCS 宏
#define _T(x) __T(x)
#define _TEXT(x) __T(x)
#ifdefine _UNICODE
....
#define __T(x) L ## x
....
typedef wchar_t WCHAR; // wc, 16-bit UNICODE character
....
typedef WCHAR TCHAR, *PTCHAR;
....
#endif
#ifdefine _MBCS
....
typedef char TCHAR, *PTCHAR;
....
#define __T(x) x
....QString 与 字符编码 QTextCodec-CSDN博客
vs qt 调试 输出 打印 到输出窗口 或控制台窗口_qt输出信息到窗口-CSDN博客
vs2015使用utf-8编码的源文件时,必须要使用utf-8 with BOM,否则会出现编译错误。
//windows下的测试代码:
#include <iostream>
#include <stdio.h>
#include <Windows.h>
using namespace std;
std::string wideCharToUtf8(std::wstring s_unicode)
{
#ifdef WIN32
std::string dest;
int len = WideCharToMultiByte(CP_UTF8 //传入数据的编码方案 https://docs.microsoft.com/zh-cn/windows/desktop/api/stringapiset/nf-stringapiset-multibytetowidechar
, 0, s_unicode.c_str(), -1, NULL, 0, NULL, NULL);
if (len <= 0)
{
return dest;
}
char* pbuffer = (char*)malloc(sizeof(char) * len);
memset(pbuffer, 0, sizeof(char) * len);
WideCharToMultiByte(CP_UTF8, 0, s_unicode.c_str(), s_unicode.size(), pbuffer, len, NULL, NULL);
dest = pbuffer;
free(pbuffer);
return dest;
#endif
}
void SetFont(int size = 90) {//hello imX2G
CONSOLE_FONT_INFOEX cfi; //hello imX2G
cfi.cbSize = sizeof cfi; //hello imX2G
cfi.nFont = 0; //hello imX2G
cfi.dwFontSize.X = 24; //hello imX2G
cfi.dwFontSize.Y = 24; //设置字体大小
cfi.FontFamily = FF_DONTCARE; //hello imX2G
cfi.FontWeight = FW_NORMAL; //字体粗细 FW_BOLD
wcscpy_s(cfi.FaceName, L"新宋体"); //设置字体,必须是控制台已有的 //Arial
SetCurrentConsoleFontEx(GetStdHandle(STD_OUTPUT_HANDLE), FALSE, &cfi); //hello imX2G
HANDLE handle = GetStdHandle(STD_OUTPUT_HANDLE); //hello imX2G
CONSOLE_FONT_INFO consoleCurrentFont; //hello imX2G
GetCurrentConsoleFont(handle, FALSE, &consoleCurrentFont); //hello imX2G
}//hello imX2G
int main()
{
wchar_t ptr1[8] = L"A你哦𬌗";
char ptr2[16] = "A你哦𬌗";
char ptr3[16] = u8"A你哦𬌗";
int p1[4] = {};
int p2[4] = {};
int p3[4] = {};
memcpy(&p1, ptr1, 16);
memcpy(&p2, ptr2, 16);
memcpy(&p3, ptr3, 16);
//char* p = setlocale(LC_ALL, "Unicode");
//printf("%s\n", p);
string str = wideCharToUtf8(ptr1);
int p4[4] = {};
memcpy(&p4, str.c_str(), str.size());
//wprintf(L"%s\n", ptr1);
system("chcp 65001");
cout << ptr2 << endl;
SetFont();
//SetCurrentConsoleFontEx()
//printf("%s\n", str.c_str());
//printf("%s\n", ptr3);
return 0;
}
如何让C语言编译器在处理字符的时候使用Unicode编码? - 知乎
libiconv - GNU Project - Free Software Foundation (FSF)
unicode ucs2 utf16 utf8 ansi GBK GB2312 互转 及 渲染_ucs2编码转换-CSDN博客
QString 与 字符编码 QTextCodec-CSDN博客