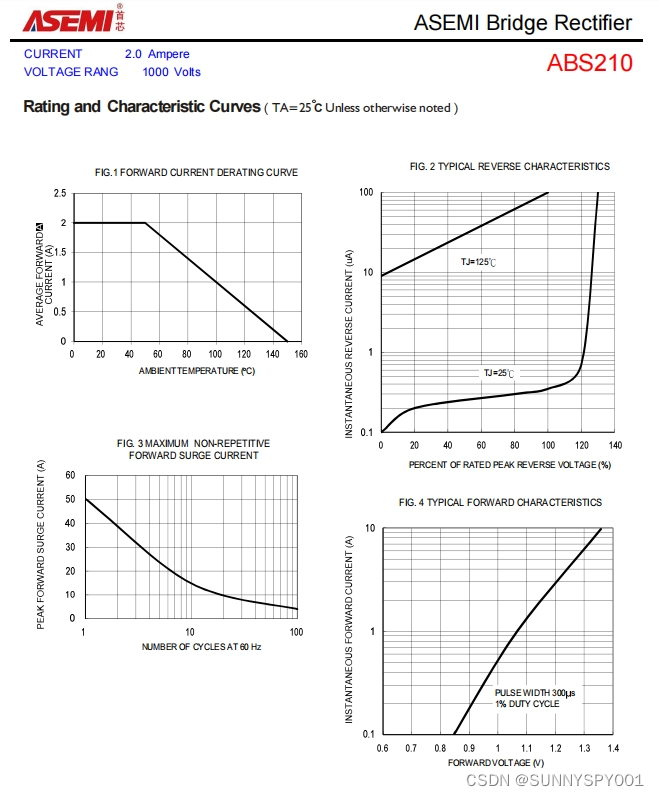
一、insert-on-duplicate语句语法
注意:ON DUPLICATE KEY UPDATE只是 MySQL的特有语法,并不是SQL标准语法!
INSERT INTO … ON DUPLICATE KEY UPDATE 是 MySQL 中一种用于插入数据并处理重复键冲突的语法。
这个语法适用于在 insert的时候,如果insert的数据会引起唯一索引(包括主键索引)的冲突,即唯一值重复了,则不会执行insert操作,而执行后面的update操作。
基本语法为:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...)
ON DUPLICATE KEY UPDATE column1 = value1, column2 = value2, ...;
-- 一般 Update子句可以使用 VALUES(col_name)获取 insert部分的值
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...)
ON DUPLICATE KEY UPDATE column1 = VALUES(column1), column2 = VALUES(column2), ...;
说明:
- table_name 是要插入数据的表名。
- (column1, column2, …) 是要插入的列名列表。
- (value1, value2, …) 是要插入的对应列的值列表。
- ON DUPLICATE KEY UPDATE 子句后面指定了在冲突时需要执行的更新操作。
- column1 = value1, column2 = value2, … 是要更新的列和对应的新值。
- column1 = VALUES(column1), column2 = VALUES(column2), … 是要更新的列和对应的新值(insert部分的值)。
insert-on-duplicate语句处理逻辑:
语句是根据唯一索引判断记录是否重复的。当执行插入操作时,如果唯一键不冲突(表中不存在记录),则执行插入操作;如果遇到唯一键冲突(表中存在记录),则会执行更新操作,使用给定的新值来更新冲突行中的列。
- 如果不存在记录,插入,则影响的行数为1;
- 如果存在记录,可以更新字段,则影响的行数为2;
- 如果存在记录,并且更新的值和原有的值相同,则影响的行数为0。
注意:如果表同时存在多个唯一索引,只会根据第一个在数据库中存在相应value的列唯一索引做duplicate判断。
二、示例表操作使用
t_user表结构:表中有一个主键id、一个唯一索引idx_name;
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_name` varchar(30) NOT NULL COMMENT '用户名',
`age` int NOT NULL DEFAULT '0' COMMENT '年龄',
`height` int DEFAULT '0' COMMENT '身高cm',
`type` int(1) DEFAULT NULL COMMENT '类型',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_name` (`user_name`) USING BTREE,
KEY `idx_type` (`type`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表';
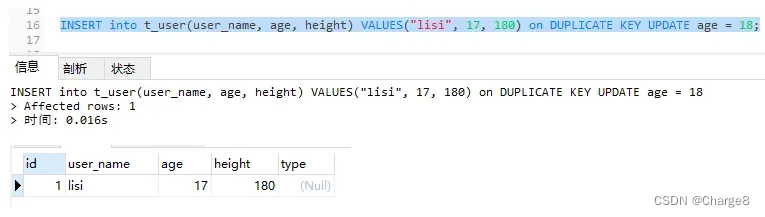
1、不存在记录,插入的情况
INSERT into t_user(user_name, age, height) VALUES("lisi", 17, 180) on DUPLICATE KEY UPDATE age = 18;
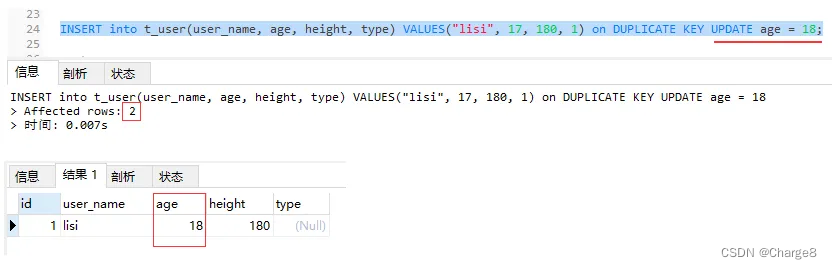
2、存在记录,可以更新字段的情况
INSERT into t_user(user_name, age, height) VALUES("lisi", 17, 180) on DUPLICATE KEY UPDATE age = 18;
3、存在记录,不可以更新字段的情况
INSERT into t_user(user_name, age, height, type) VALUES("lisi", 18, 180, 1) on DUPLICATE KEY UPDATE age = 18;
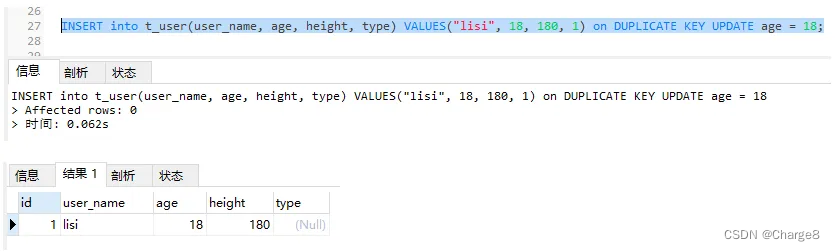
4、存在多个唯一索引时
如果表同时存在多个唯一索引,只会根据第一个在数据库中存在相应value的列唯一索引做duplicate判断。
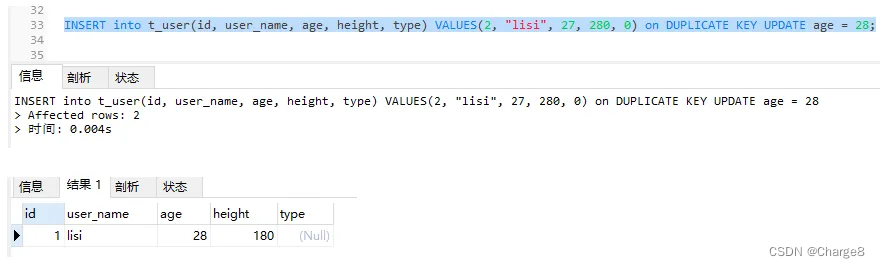
1)数据库中id = 2的记录不存在,user_name="lisi"的记录存在,所以会根据第二个唯一索引 user_name做duplicate判断:执行 update操作。
INSERT into t_user(id, user_name, age, height, type) VALUES(2, "lisi", 27, 280, 0) on DUPLICATE KEY UPDATE age = 28;
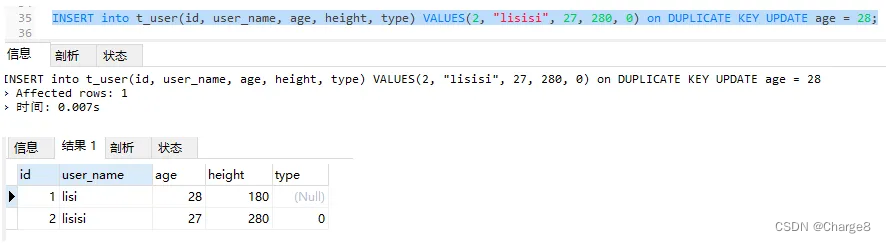
2)数据库中id = 2的记录不存在,user_name="lisisi"的记录不存在,所以不存在重复键冲突:执行 insert操作。
INSERT into t_user(id, user_name, age, height, type) VALUES(2, "lisisi", 27, 280, 0) on DUPLICATE KEY UPDATE age = 28;
3)数据库中 id = 2的记录存在,user_name="lisisi"的记录存在,所以会根据第一个唯一索引id做duplicate判断:执行 update操作。
INSERT into t_user(id, user_name, age, height, type) VALUES(2, "lisisi", 37, 380, 1) on DUPLICATE KEY UPDATE age = 38;

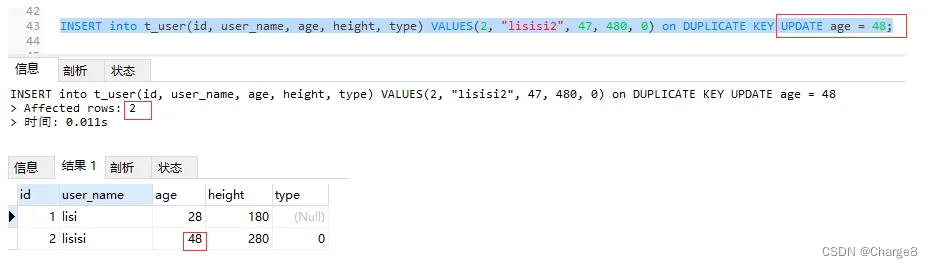
4)数据库中 id = 2的记录存在,user_name="lisisi2"的记录不存在,所以会根据第一个唯一索引id做duplicate判断:执行 update操作。
INSERT into t_user(id, user_name, age, height, type) VALUES(2, "lisisi2", 47, 480, 0) on DUPLICATE KEY UPDATE age = 48;
5、VALUES(col_name)使用
一般 Update子句可以使用 VALUES(col_name)获取 insert部分的值。也是项目中使用最多的方式。
注意:VALUES()函数只在INSERT…UPDATE语句中有意义,其它时候会返回NULL。
INSERT into t_user(id, user_name, age, height, type) VALUES(2, "lisisi", 57, 480, 0) on DUPLICATE KEY UPDATE age = VALUES(age) + 100;

6、批量操作
批量操作之前表中数据如下:

批量语句如下:
INSERT INTO t_user(user_name, age, height, type)
VALUES
("lisi", 71, 701, 0),
("lisisi", 72, 280, 1),
("zhangsan", 73, 703, 0),
("wangwu", 74, 704, null),
("laoliu", 75, null, null)
ON DUPLICATE KEY UPDATE
user_name = VALUES(user_name),
age = VALUES(age),
height = VALUES(height),
type = VALUES(type);
批量语句执行操作之后表中数据如下:

参考文章:
- 官方文档:https://dev.mysql.com/doc/refman/5.7/en/insert-on-duplicate.html
– 求知若饥,虚心若愚。