LLM其实就是large language model,大语言模型。
AGI其实就是Artificial General Intelligence,通用人工智能。
如果对“最终任务”进一步进行分类,又大致可以分为两大不同类型的任务:自然语言理解类任务和自然语言生成类任务。如果排除掉“中间任务”的话,典型的自然语言理解类任务包括文本分类、句子关系判断、情感倾向判断等,这种任务本质上都是分类任务,就是说输入一个句子(文章),或者两个句子,模型参考所有输入内容,最后给出属于哪个类别的判断。自然语言生成也包含很多NLP研究子方向,比如聊天机器人、机器翻译、文本摘要、问答系统等。生成类任务的特点是给定输入文本,对应地,模型要生成一串输出文本。这两者的差异主要体现在输入输出形式上
NLP各种任务其实收敛到了两个不同的预训练模型框架里:
- 对于自然语言理解类任务,其技术体系统一到了以Bert为代表的“双向语言模型预训练+应用Fine-tuning”模式;
- 对于自然语言生成类任务,其技术体系统一到了以GPT 2.0为代表的“自回归语言模型(即从左到右单向语言模型)+Zero /Few Shot Prompt”模式。
如果是以fine-tuning方式解决下游任务,Bert模式的效果优于GPT模式;若是以zero shot/few shot prompting这种模式解决下游任务,则GPT模式效果要优于Bert模式。
ChatGPT向GPT 3.5模型注入新知识了吗?应该是注入了,这些知识就包含在几万人工标注数据里,不过注入的不是世界知识,而是人类偏好知识。所谓“人类偏好”,包含几方面的含义:首先,是人类表达一个任务的习惯说法。比如,人习惯说:“把下面句子从中文翻译成英文”,以此表达一个“机器翻译”的需求,但是LLM又不是人,它怎么会理解这句话到底是什么意思呢?你得想办法让LLM理解这句命令的含义,并正确执行。所以,ChatGPT通过人工标注数据,向GPT 3.5注入了这类知识,方便LLM理解人的命令,这是它“善解人意”的关键。其次,对于什么是好的回答,什么是不好的回答,人类有自己的标准,例如比较详细的回答是好的,带有歧视内容的回答是不好的,诸如此类。这是人类自身对回答质量好坏的偏好。人通过Reward Model反馈给LLM的数据里,包含这类信息。总体而言,ChatGPT把人类偏好知识注入GPT 3.5,以此来获得一个听得懂人话、也比较礼貌的LLM。
可以看出,ChatGPT的最大贡献在于:基本实现了理想LLM的接口层,让LLM适配人的习惯命令表达方式,而不是反过来让人去适配LLM,绞尽脑汁地想出一个能Work的命令(这就是instruct技术出来之前,prompt技术在做的事情),而这增加了LLM的易用性和用户体验。是InstructGPT/ChatGPT首先意识到这个问题,并给出了很好的解决方案,这也是它最大的技术贡献。相对之前的few shot prompting,它是一种更符合人类表达习惯的人和LLM进行交互的人机接口技术。
LLM从海量文本中学习到了什么:
1. 学到了“语言类知识”
语言类知识指的是词法、词性、句法、语义等有助于人类或机器理解自然语言的知识。关于LLM能否捕获语言知识有较长研究历史,自从Bert出现以来就不断有相关研究,很早就有结论,各种实验充分证明LLM可以学习各种层次类型的语言学知识,这也是为何使用预训练模型后,各种语言理解类自然语言任务获得大幅效果提升的最重要原因之一。另外,各种研究也证明了浅层语言知识比如词法、词性、句法等知识存储在Transformer的低层和中层,而抽象的语言知识比如语义类知识,广泛分布在Transformer的中层和高层结构中。
2. 学到了“世界知识”
世界知识指的是在这个世界上发生的一些真实事件(事实型知识,Factual Knowledge),以及一些常识性知识(Common Sense Knowledge)。比如“拜登是现任美国总统”、“拜登是美国人”、“乌克兰总统泽连斯基与美国总统拜登举行会晤”,这些都是和拜登相关的事实类知识;而“人有两只眼睛”、“太阳从东方升起”这些属于常识性知识。关于LLM模型能否学习世界知识的研究也有很多,结论也比较一致:LLM确实从训练数据中吸收了大量世界知识,而这类知识主要分布在Transformer的中层和高层,尤其聚集在中层。而且,随着Transformer模型层深增加,能够学习到的知识数量逐渐以指数级增加(可参考:BERTnesia: Investigating the capture and forgetting of knowledge in BERT)。其实,你把LLM看作是一种以模型参数体现的隐式知识图谱,如果这么理解,我认为是一点问题也没有的。
“When Do You Need Billions of Words of Pre-training Data?”这篇文章研究了预训练模型学习到的知识量与训练数据量的关系,它的结论是:对于Bert类型的语言模型来说,只用1000万到1亿单词的语料,就能学好句法语义等语言学知识,但是要学习事实类知识,则要更多的训练数据。这个结论其实也是在意料中的,毕竟语言学知识相对有限且静态,而事实类知识则数量巨大,且处于不断变化过程中。而目前研究证明了随着增加训练数据量,预训练模型在各种下游任务中效果越好,这说明了从增量的训练数据中学到的更主要是世界知识。
LLM的知识到底存储到了网络中的什么地方:
比如 “中国的首都是北京”这条知识,以三元组表达就是<北京,is-capital-of,中国>,其中“is-capital-of”代表实体间关系。这条知识它存储在LLM的哪里呢?
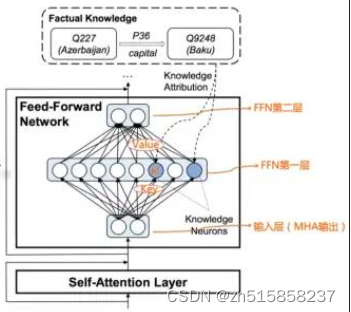
“Transformer Feed-Forward Layers Are Key-Value Memories”给出了一个比较新颖的观察视角,它把Transformer的FFN看成存储大量具体知识的Key-Value存储器。FFN的第一层是个MLP宽隐层,这是Key层;第二层是MLP窄隐层,是Value层。FFN的输入层其实是某个单词对应的MHA的输出结果Embedding,也就是通过Self Attention,将整个句子有关的输入上下文集成到一起的Embedding,代表了整个输入句子的整体信息。
参考文档
- https://mp.weixin.qq.com/s/eMrv15yOO0oYQ-o-wiuSyw



![[数据库迁移]-LVM逻辑卷管理](https://img-blog.csdnimg.cn/c23844536fa0482a9dfe24fa6954c814.png#pic_center)

![websocket创建时附加额外信息 [如自定义headers信息(利用nginx)]](https://img-blog.csdnimg.cn/7b24f40dab04435eac4fe9b6dcd8e425.png)