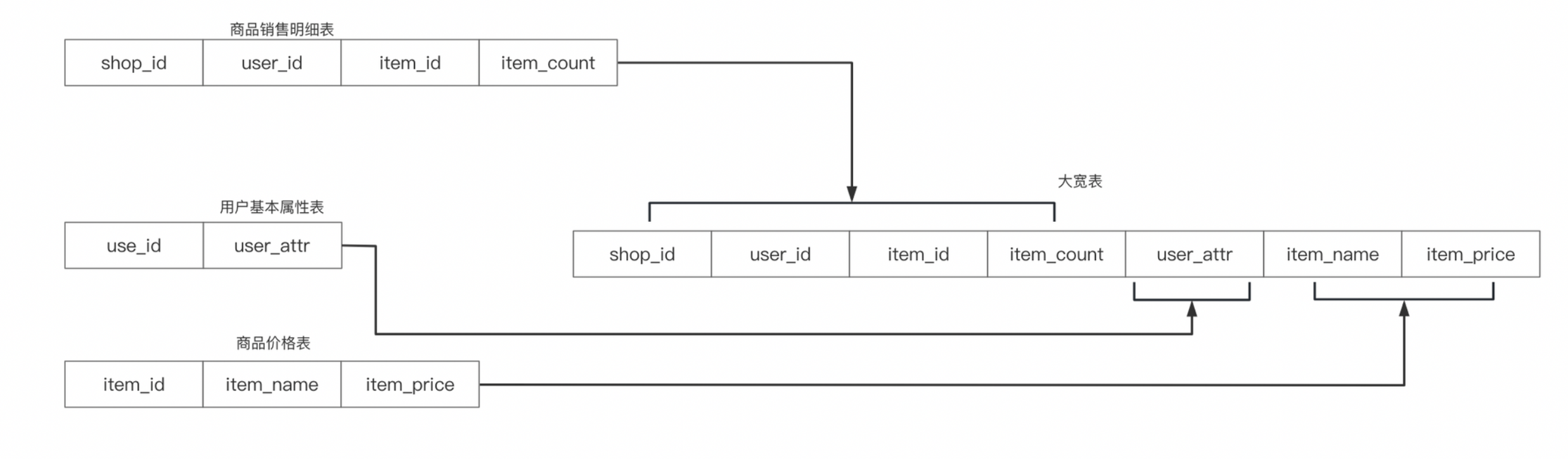
数据科学开发工具
anaconda:管理开发环境
jupyter:编写整个数据处理流程
pycharm:远程编写调试代码
ipdb:pycharm dubug时偶尔出现一些bug,可以用结合ipdb补充解决
数据开发六步
data
数据的获得、清洗、特征工程等预处理在这一步做,最后有一点是共同的,就是把准备好的数据进行“批量化”,因为训练模型时必须把数据批量化,最好的方法是生成数据迭代器,供后面训练时使用。
# data
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
model
模型的定义、初始化。
model = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
model.apply(init_weights)
loss
定义损失函数,本质上是两个向量之前的距离,度量 y , y ^ y,\hat y y,y^ 之间的差距,可以从几何角度、熵的角度考虑,大部分可以证明是与概率极大似然等价的。
# loss
loss = nn.CrossEntropyLoss(reduction='none')
optimization
优化算法
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
train
这一步综合了前面的步骤,有几个要点:
1
。
1^。
1。 固定套路:两层循环,外层循环控制整个训练集使用的轮数,内层循环控制batch;
2
。
2^。
2。 为了便于调试超参数,需要可视化训练过程,在训练过程中需要计算train loss、train acc、test acc,并以num_epochs作为横坐标,可视化整个流程。具体图例如下:
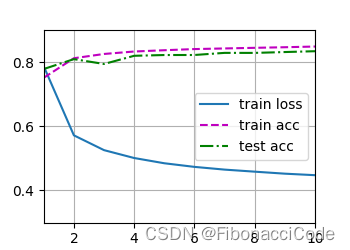
3
。
3^。
3。 这里可视化训练过程使用了Animator、Accumulator两个类,在另外一篇博客中分析。
num_epochs = 10
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
# Set the model to training mode
if isinstance(model, torch.nn.Module):
model.train()
# Sum of training loss, sum of training accuracy, no. of examples
metric = Accumulator(3)
for X, y in train_iter:
# Compute gradients and update parameters
y_hat = model(X)
l = loss(y_hat, y)
if isinstance(optimizer, torch.optim.Optimizer):
# Using PyTorch in-built optimizer & loss criterion
optimizer.zero_grad()
l.mean().backward()
optimizer.step()
else:
# Using custom built optimizer & loss criterion
l.sum().backward()
optimizer(X.shape[0])
metric.add(float(l.sum()), d2l.accuracy(y_hat, y), y.numel())
# get training loss and training accuracy
train_metrics = metric[0] / metric[2], metric[1] / metric[2]
test_acc = d2l.evaluate_accuracy(model, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
d2l.plt.show()



](https://img-blog.csdnimg.cn/8b67be67d0914fe1975858410531041e.png)