说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。
知乎专栏地址:
语音生成专栏
系列文章地址:
【GPT-SOVITS-01】源码梳理
【GPT-SOVITS-02】GPT模块解析
【GPT-SOVITS-03】SOVITS 模块-生成模型解析
【GPT-SOVITS-04】SOVITS 模块-鉴别模型解析
【GPT-SOVITS-05】SOVITS 模块-残差量化解析
【GPT-SOVITS-06】特征工程-HuBert原理
1.概述
SOVIT 模块的主要功能是生成最终的音频文件。
GPT-SOVITS的核心与SOVITS差别不大,仍然是分了两个部分:
- 基于 VAE + FLOW 的生成器,源代码为 SynthesizerTrn
- 基于多尺度分类器的鉴别器,源代码为 SynthesizerTrn
针对鉴别器相较于SOVITS5做了一些简化,主要的差异是在在生成模型处引入了残差量化层。
在训练时进入先验编码器的是经过残差量化层的 quatized 数据。
在推理时,用的是AR模块推理出的 code,然后用code直接生成 quatized 数据,再进入先验编码器。
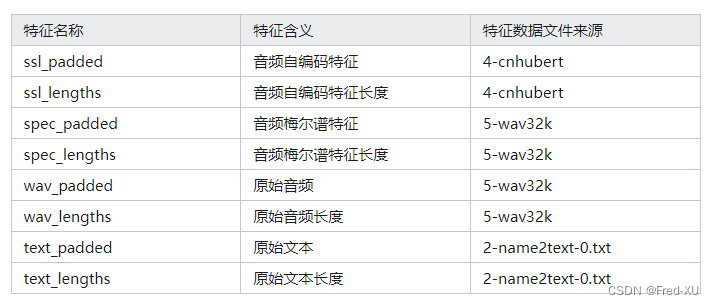
训练所涉及特征包括:
2.训练流程
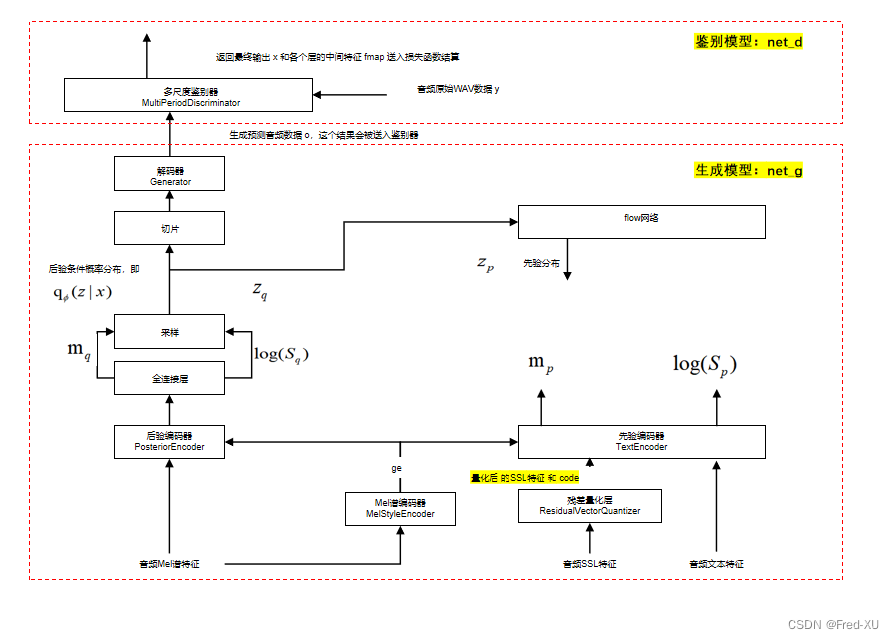
- 如概述所注,在训练时SSL特征经过残差量化层中会产生量化编码 code 和数据 quatized。
- 这个 code 也会作为 AR,即GPT模块训练的特征
- 在推理时,这个code 就由 GPT 模块生成
- 损失函数如下:
y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat)
with autocast(enabled=False):
loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
loss_fm = feature_loss(fmap_r, fmap_g)
loss_gen, losses_gen = generator_loss(y_d_hat_g)
loss_gen_all = loss_gen + loss_fm + loss_mel + kl_ssl * 1 + loss_kl
3.推理流程
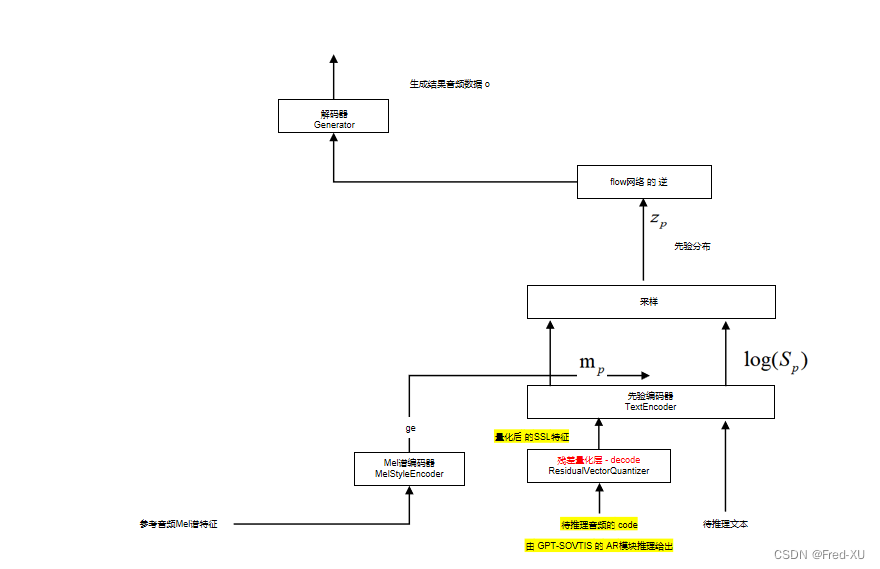
推理时直接通过先验编码器,通过FLOW的逆,进入解码器后输出推理音频
4.调试代码参考
import os,sys
import json
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from torch.utils.data import DataLoader
from vof.vits.data_utils import (
TextAudioSpeakerLoader,
TextAudioSpeakerCollate,
DistributedBucketSampler,
)
from vof.vits.models import SynthesizerTrn
from vof.script.utils import HParams
now_dir = os.getcwd()
root_dir = os.path.dirname(now_dir)
prj_name = 'project01' # 项目名称
prj_dir = root_dir + '/res/' + prj_name + '/'
with open(root_dir + '/res/configs/s2.json') as f:
data = f.read()
data = json.loads(data)
# 新增其他参数
s2_dir = prj_dir + 'logs' # gpt 训练用目录
os.makedirs("%s/logs_s2" % (s2_dir), exist_ok=True)
data["train"]["batch_size"] = 3
data["train"]["epochs"] = 15
data["train"]["text_low_lr_rate"] = 0.4
data["train"]["pretrained_s2G"] = root_dir + '/res/pretrained_models/s2G488k.pth'
data["train"]["pretrained_s2D"] = root_dir + '/res/pretrained_models/s2D488k.pth'
data["train"]["if_save_latest"] = True
data["train"]["if_save_every_weights"] = True
data["train"]["save_every_epoch"] = 5
data["train"]["gpu_numbers"] = 0
data["data"]["exp_dir"] = data["s2_ckpt_dir"] = s2_dir
data["save_weight_dir"] = root_dir + '/res/weight/sovits'
data["name"] = prj_name
data['exp_dir'] = s2_dir
hps = HParams(**data)
print(hps)
"""
self.path2 = "%s/2-name2text-0.txt" % exp_dir
self.path4 = "%s/4-cnhubert" % exp_dir
self.path5 = "%s/5-wav32k" % exp_dir
"""
train_dataset = TextAudioSpeakerLoader(hps.data)
"""
ssl hubert 特征 [1,768,195]
spec [1025,195]
wav [1,124800]
text [14,]
"""
train_sampler = DistributedBucketSampler(
train_dataset,
hps.train.batch_size,
[
32,
300,
400,
500,
600,
700,
800,
900,
1000,
1100,
1200,
1300,
1400,
1500,
1600,
1700,
1800,
1900,
],
num_replicas=1,
rank=0,
shuffle=True,
)
collate_fn = TextAudioSpeakerCollate()
train_loader = DataLoader(
train_dataset,
batch_size=1,
shuffle=False,
pin_memory=True,
collate_fn=collate_fn,
batch_sampler=train_sampler
)
def _model_forward(ssl, y, y_lengths, text, text_lengths):
net_g = SynthesizerTrn(
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,
**hps.model,
)
net_g.forward(ssl, y, y_lengths, text, text_lengths)
for data in train_loader:
ssl_padded = data[0]
ssl_lengths = data[1]
spec_padded = data[2]
spec_lengths = data[3]
wav_padded = data[4]
wav_lengths = data[5]
text_padded = data[6]
text_lengths = data[7]
_model_forward(ssl_padded, spec_padded, spec_lengths, text_padded, text_lengths)