问题:当增加输入图像的分辨率时,例如DeiT 从 224 到 384,一般来说会保持 patch size(例如9),因此 patch 的数量 N 会发生了变化。那么视觉transformer是如何处理变长序列输入的?
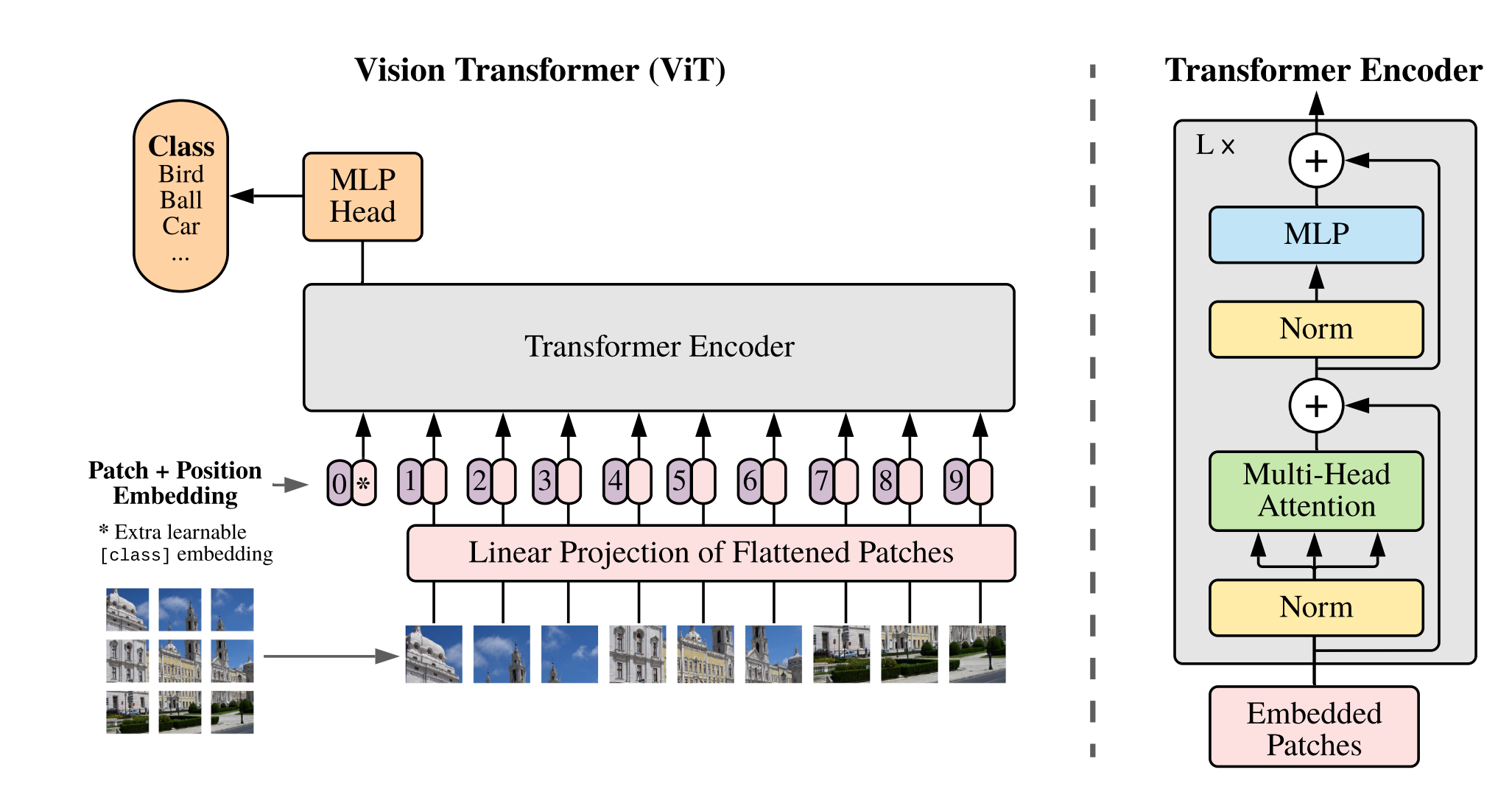
回答:
在讨论视觉ViT中,对于图像分类任务,不管序列多长(所有patches加起来的长度),一般是在输入序列的开始添加一个特殊的cls token,这个cls token 不对应图像中的任何一个具体的 patch,而是作为一个全局的表示,用于汇总整个图像的信息。在经过 Transformer 层处理之后,这个 class token 被用来代表整个图像的特征(只取这个latent token用于MLP),用于最终的分类任务。这意味着不管输入的图像分辨率如何变化,从而导致序列的长度(即 patch 的数量)如何变化,模型总是会关注这一个特定的 token 来进行分类判断。意思就是不管你切分为多少个patches,这些patches进入transformer encoder得到latent token,我们只取第0个token(cls token)用于分类任务,剩余的token都不使用。
Transformer 架构中的MLP(多层感知机)和FFN(前馈神经网络)是共享的,这意味着模型中的所有tokens(在图像处理上下文中,可以认为是图像被分割成的小块或"patches")通过相同的MLP和FFN进行处理。无论输入序列的长度(即tokens总共的数量)如何变化,每个token都会被相同的MLP和FFN处理。这是因为MLP和FFN在Transformer架构中是以相同的方式应用于序列中的每一个元素,而不依赖于序列的总长度。这种设计允许Transformer模型处理可变长度的输入序列,因为每个token的处理方式是一样的。
但是由于提高输入图像的分辨率会增加序列的长度(因为 patch 的数量增多),原有的位置编码(position embedding)无法直接适用于新的序列长度。你只需要对现有的位置编码进行插值,以生成适应新序列长度的位置编码,然后通过微调(fine-tune)这些插值生成的编码,便可以使模型能够适应新的输入分辨率。
插值方式可以看VAE的实现:
interpolate_pos_embed(model, checkpoint_model)
这个过程确保了视觉 Transformer 模型可以处理不同分辨率的输入图像,同时保持了使用单一的 class token 来汇总和利用全图信息进行分类的策略。
归根到底:
在ViT(Vision Transformer)的上下文中,模型处理的输入维度会因为图像分辨率大小的不同而导致patch数量的变化,从而影响到位置编码层的输入维度。
然而,ViT的核心Transformer架构设计为处理任意长度的序列。这意味着无论patch的数量如何,Transformer的主体结构(多头自注意力机制和MLP)都能够处理。这是因为这些组件是基于序列中的每个patch独立操作的,而不是依赖于整个序列的维度。因此,Transformer核心是不直接受图像大小影响的。
可以看到下面的示例中“整个ViT过程中image-size只会影响PE的维度大小,而不会影响其他的任何参数,所以只需要在新的分辨率的图像来的时候,修改PE的维度就可以了(加大或减小到patch的长度)
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
num_patches = (image_height // patch_height) * (image_width // patch_width)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches+1, dim))整个修改流程:
- 加载在低分辨率下的图像训练好的pretrain-checkpoint
- 修改低分辨率下的pretrain-checkpoint的PE维度,从而适应当前分辨率下的维度
- 保存修改后的pretrain-checkpoint
- 加载高维度下的model
- 将修改后的pretrain-checkpoint的用在高维度下的model(load_state_dict)
- 微调就可以了
代码实现:
下面的代码实现是256-->512维度的变化,类似于MAE的训练的时候用unmask的patch,微调的时候使用unmask+mask的patch
1、基本的ViT的实现:
import torch
from torch import nn, einsum, optim
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
from tqdm import tqdm
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
def pair(t):
return t if isinstance(t, tuple) else (t, t)
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout),
) if project_out else nn.Identity()
def forward(self, x):
b, n, _, h = *x.shape, self.heads
qkv = self.to_qkv(x).chunk(3, dim=-1) # (b, n(65), dim*3) ---> 3 * (b, n, dim)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=h), qkv) # q, k, v (b, h, n, dim_head(64))
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = self.attend(dots)
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout=dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
class ViT(nn.Module):
def __init__(self, *, image_size=256, patch_size=8, num_classes=1000, dim=1024, depth=6, heads=16, mlp_dim=2048, pool='cls', channels=3, dim_head=64, dropout=0., emb_dropout=0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height ==0 and image_width % patch_width == 0
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_height, p2=patch_width),
nn.Linear(patch_dim, dim)
)
# 当image-size改变的时候,只会影响pos_embedding的维度,所以当图像分辨率变化的时候,只有这一个地方需要修改
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches+1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img) # b c (h p1) (w p2) -> b (h w) (p1 p2 c) -> b (h w) dim
b, n, _ = x.shape # b表示batchSize, n表示每个块的空间分辨率, _表示一个块内有多少个值
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b) # self.cls_token: (1, 1, dim) -> cls_tokens: (batchSize, 1, dim)
x = torch.cat((cls_tokens, x), dim=1) # 将cls_token拼接到patch token中去 (b, 65, dim)
x += self.pos_embedding[:, :(n+1)] # 加位置嵌入(直接加) (b, 65, dim)
x = self.dropout(x)
x = self.transformer(x) # (b, 65, dim)
x = x.mean(dim=1) if self.pool == 'mean' else x[:, 0] # (b, dim)
x = self.to_latent(x) # Identity (b, dim)
return self.mlp_head(x) # (b, num_classes)
2、训练的代码
# ============================== begin train ==============================
model = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 模拟训练数据
train_data = torch.randn(16, 3, 256, 256) # 示例数据,16个样本
train_labels = torch.randint(0, 1000, (16,)) # 示例标签,1000个类
# 训练模型
def train(model, data, labels, criterion, optimizer, epochs=1):
model.train()
for epoch in tqdm(range(epochs)):
for i in range(len(data)):
optimizer.zero_grad()
output = model(data[i].unsqueeze(0)) # 前向传播
loss = criterion(output, labels[i].unsqueeze(0)) # 计算损失
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item()}")
# 训练模型
train(model, train_data, train_labels, criterion, optimizer, epochs=10)
# 保存模型checkpoint
torch.save({
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, 'vit_model_checkpoint.pth')
3、修改PE维度并用在不一样的分辨率下的图像上
这里“resize_pos_embedding”我直接固定了,有更优雅的实现方式,懒得写了
# --------------------------------------------------------
# Interpolate position embeddings for high-resolution
# References:
# DeiT: https://github.com/facebookresearch/deit
# --------------------------------------------------------
def resize_pos_embedding(checkpoint_model, new_image_size, patch_size=32):
num_patches = (new_image_size // patch_size) ** 2
new_num_tokens = num_patches + 1 # 加上一个cls_token
old_pos_embedding = checkpoint_model['pos_embedding']
old_num_tokens, embedding_dim = old_pos_embedding.shape[1], old_pos_embedding.shape[2]
# # 插值pos_embedding
# new_pos_embedding = F.interpolate(
# old_pos_embedding.permute(0, 2, 1).reshape(1, embedding_dim, int(old_num_tokens ** 0.5), int(old_num_tokens ** 0.5)),
# size=int(new_num_tokens ** 0.5),
# mode='bilinear',
# align_corners=False
# ).reshape(1, embedding_dim, new_num_tokens).permute(0, 2, 1)
#
# # 更新模型的pos_embedding
# checkpoint_model['pos_embedding'] = nn.Parameter(new_pos_embedding)
new_pos_embedding = nn.Parameter(torch.randn(1,257,1024))
checkpoint_model['pos_embedding'] = new_pos_embedding
# ============================== begin test ==============================
image_size = 512
# Step 1: 加载新尺寸下的模型
model = ViT(
image_size = image_size,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
# Step 2: 加载原来小尺寸下训练好的checkpoint
checkpoint_model = torch.load('vit_model_checkpoint.pth')
# Step 3: interpolate position embedding,这是新分辨率下模型中唯一需要修改的地方
model_state = checkpoint_model['model_state_dict']
resize_pos_embedding(model_state, image_size)
# Step 4: 加载新分辨率下的模型
model.load_state_dict(model_state)
# 准备评估数据
test_loader = DataLoader(datasets.FakeData(size=16, image_size=(3, image_size, image_size), num_classes=1000, transform=transforms.ToTensor()), batch_size=16, shuffle=True)
model.eval()
correct = 0
total = 0
with torch.no_grad():
for imgs, labels in test_loader:
outputs = model(imgs)
_, predicted = torch.max(outputs.data, 1)
print(predicted)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the model on the test images: {16 * correct / total}%')ViT、Deit这类视觉transformer是如何处理变长序列输入的? - 知乎