论文题目
Aspect-based sentiment analysis with alternating coattention networks
摘要
基于属性的情感分析(ABSA)旨在预测给定文本中特定目标的情感极性。近年来,为了获得情感分类任务中更有效的特征表示,人们对利用注意力网络对目标和上下文进行建模产生了浓厚的兴趣。然而,使用目标的平均向量来计算上下文的注意力分数是不公平的。此外,交互机制也很简单,需要进一步改进。为了解决上述问题,本文首先提出了一种协同注意力(Coattention)机制,该机制对目标层面和上下文层面的注意力进行交替建模,从而关注那些与目标相关的关键词,以学习更有效的上下文表示。在此基础上,我们实现了Coattention-LSTM网络,该网络同时学习上下文和目标的非线性表征,并能从Coattention机制中提取更有效的情感特征。在此基础上,提出了一种采用多跳协同注意机制的Coattention-memnet网络,以改善情感分类结果。最后,提出了一种新的位置加权函数,它考虑了位置信息,以提高共注意机制的性能。在两个公开数据集上的大量实验证明了所有方法的有效性,实验结果为未来使用注意力机制和深度神经网络进行ABSA提供了新的见解。
1.引言
• 近年来,情感分析已经成为 NLP 中最活跃的研究领域之一。它在数据挖掘、信息检索、问题回答、总结、智能推荐系统等方面也有广泛的应用,可以帮助检测用户态度和预测用户需求,促进用户进一步的浏览和消费行为,是帮助用户专注有用信息和缓解信息过载的重要工具。• 然而,传统的情感分析总是一个句子级或文档级的任务,旨在找到与一个实体相关的整体情感,如评论的整体主题 。如果想找到实体的各个属性 (aspect ,例如产品的价格、质量等 ) 的情感,一般的情感分析不能满足这个任务。因此,基于属性的情感分析 (ABSA) 被提出来用于这项任务。• ABSA 旨在推断一个句子对一个目标的情感极性(如积极、消极、中立),该目标是一个特定实体的属性。例如,给定一个句子 “The fish is fresh but the variety of fish is nothing out of ordinary.” ,目标 “Fish” 的极性是积极的,而目标 “Variety of fish” 的极性是消极的。 ABSA 任务包括两个子任务:属性检测和情感分类 。本文中的 ABSA 任务假定属性是已知的,只关注情感分类任务。
• 最近,神经网络由于其自动提取特征的效率,已经成为情感分析的有效解决方案 。基于 CNN 、 LSTM 和注意力网络等神经网络的情感分析的准确性已经达到或超过了依赖于人工特征的方法 ;• 然而, ABSA 任务与一般的情感分类不同。 在 ABSA 任务中,一个句子中可能出现多个目标,并且每个目标都有相关的词来修饰 。在判断当前目标的情感时,其他目标和相关词会成为噪音。因此,在设计神经网络时,需要充分考虑目标词和上下文词之间的关系。同时,利用注意力机制来学习与目标相关的上下文特征进行情感分析,在 ABSA 任务中也显示了其有效性。 (Coattention-LSTM)• 此外, 由于单层注意力网络难以提取与某些目标相关的情感特征 ,以 coattention 机制为基本计算单元,设计了一个名为 Coattention- MemNet 的交互式记忆网络,该网络可以交替学习更有效的目标和上下文特征,并且该模型还可以通过基于记忆网络的迭代机制学习更抽象的特征表示。• 一些工作表明, 位置信息在 ABSA 任务中是有用的 ,可以帮助模型学习更好的文本特征进行分类。为了将位置信息考虑在内,提出了一个位置加权函数的协同注意力机制,并将位置加权函数应用于 Coattention-LSTM 和 Coattention- MemNet 模型。
2.文献回顾
2.1 基于LSTM的ABSA
• ABSA 旨在推断一个句子对目标的情感极性,目标 ( 属性 ) 指评论中一个实体的特征,一个句子中可以出现多个属性。因此, ABSA 任务的主要挑战是如何有效地建立目标和上下文之间的关系 。• 早期的工作主要使用机器学习算法 提取一组特征来描述目标和上下文之间的关系,例如上下文 - 目标二元组和解析路径。然而,除了有效特征提取困难之外,一些有效特征,如解析特征,严重依赖解析工具的性能。• 神经网络,尤其是 LSTM ,可以在没有特征工程的情况下对句子进行编码 ,并已被应用于许多 NLP 任务。然而, LSTM 由于表达灵活,且不能有效地捕获目标与上下文 ( 语境 ) 之间的潜在交互,因此很难根据目标对上下文进行合理划分。• 自从注意力网络在翻译任务上成功应用以来, 很多工作都是利用注意力机制来建立目标和上下文之间的关系 。
2.2 基于MEMNet的ABSA
• 到目前为止,记忆网络已经成功应用于问题回答、语言模型、对话系统和提醒推荐任务 。记忆网络的效率在于它的多计算层( “ 跳层 (hop) ”)结构。记忆网络将输入编码为向量并存储在内存中。查询也被嵌入到向量中,作为初始查询表示向量。每一跳层的功能是从存储器中寻找与查询表示向量有关的证据。• 受到这些工作的启发, Tang 等人( 2016b )首次将记忆网络应用于 ABSA 任务。该模型使用预训练的上下文词的嵌入作为记忆,并将具有平均目标表征的注意力视为计算单元,重复多次跳转,从上下文中寻找与目标相关的证据。 然而,这些工作使用传统的注意力作为计算单元,忽略了目标建模的重要性 。这意味着现有的记忆网络只能从上下文记忆中寻找与目标相关的证据,而不能从上下文和目标中交互地寻找证据。在本文中,设计了一个交互式记忆网络,它可以交替地从目标和上下文中学习证据。此外,我们的模型是针对基于句子层面的情感分类任务而提出的,不需要为每个目标选择任何种子词,根据目标记忆向量和历史记忆向量来更新上下文的记忆向量。
2.3 协同注意力网络
• 许多研究已经证明了协同注意力机制在多个领域的有效性 。( VQA 的 coattention 机制,多模态微博的标签推荐,交叉外延记忆网络)所有这些工作的动机是,关注文本和图像对任务来说很重要,而且文本和视觉信息之间存在一些关系,因为它们是相互帮助和关联的。• Xiong 等人 (2017) 介绍了用于机器理解的动态注意力网络( DCN ) 。这项研究是第一项将协同注意力机制引入机器理解的工作,但它是单模的,只涉及文本信息。在某种程度上,机器理解类似于 ABSA 任务,因为上下文和目标(或问题)信息是相互关联和帮助的。与 DCN 类似,我们首先提出了一种交替协同注意力机制来提取目标和上下文的共同依赖表征。与 DCN 采用基于 LSTM 的动态迭代机制进行机器理解不同,我们提出了一种协同迭代机制,在 ABSA 任务中基于记忆网络循环地提取高水平的共同依赖表征。
3.方法
3.1 任务定义和符号
•给定一个由n个词组成的句子s=[wc1, wc2, wc3, ...,wcn],和一个由s句中出现的m个词组成的目标t=[wt1, wt2, wt3, ...,wtm],ABSA任务旨在分析s句对目标t的情感。例如,句子“The fish is fresh but the variety of fish is nothing out of ordinary”。对“Fish”的情感极性是中性的,而对“Variety of fish”的极性是负面的。
3.2 协同注意力网络概述
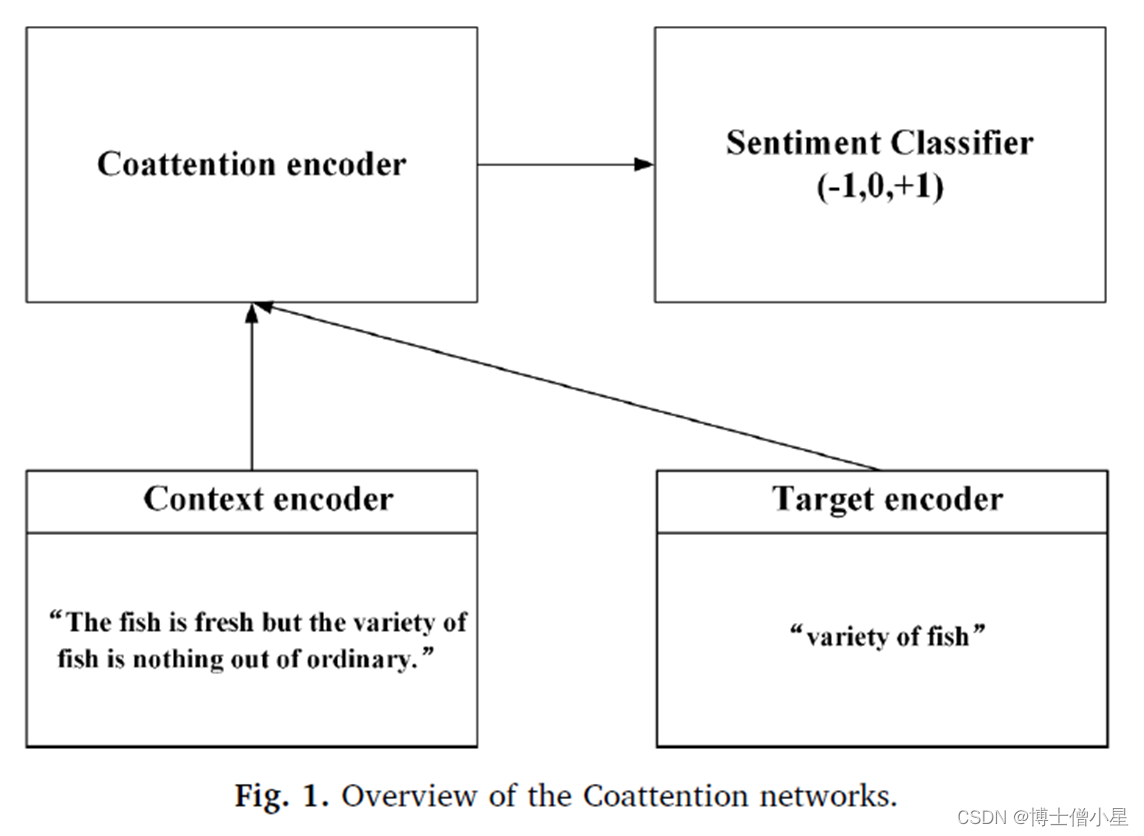
•用于ABSA任务的协同注意力网络包括一个上下文编码器、一个目标编码器、一个协同注意力编码器和一个情感分类器。上下文和目标编码器用于将上下文和目标的单词编码为向量,以捕捉每个单词的特征。协同注意力编码器根据协同效应机制学习捕捉上下文和目标词之间相互作用的表示。最后,情感分类器预测上下文对目标词的情感极性。
本文在LSTM网络和MemNet网络的基础上分别提出了两种具有协同注意力机制的模型,即Coattention-LSTM模型和Coattention-MemNet模型。
图1展示了用于ABSA任务的协同注意力网络的概况,其中包括一个上下文编码器、一个目标编码器、一个协同注意力编码器和一个情感分类器。上下文和目标编码器用于将上下文和目标的单词编码为向量,以捕捉每个单词的特征。协同注意力编码器根据协同效应机制学习捕捉上下文和目标词之间相互作用的表示。最后,情感分类器预测上下文对目标词的情感极性。
本文在LSTM网络和记忆网络的基础上分别提出了两种具有协同注意机制的模型,即coattention -LSTM模型和coattention - memnet模型。
3.3 Coattention-LSTM
•图中,P表示平均集合函数,Cinit是上下文隐藏状态的集合结果。A表示注意力函数,Tr是目标隐藏状态的注意力结果,Cr是上下文隐藏状态的注意力结果。数字表示这些计算单元的顺序。
• 上下文和目标编码器ü 将上下文 s 和目标 t 映射成 两个嵌入矩阵 。 [e c 1 , e c 2 , e c 3 , ..., e c n ] 和 [e t 1 , e t 2 , e t 3 , ..., e t m ] 。每个 e i 都是来自预先训练好的单词矩阵 M v×d 的单词向量, v 表示语料库中单词数量, d 表示向量维度。ü 使用 LSTM 对上下文进行编码并得到每个词的隐藏状态: h c i = LSTM(h c i-1 , e c i ) ,然后将上下文 编码矩阵 定义为 C=[h c 1 , h c 2 , h c 3 , ..., h c n ] ,同理得目标编码矩阵为 T= [h t 1 , h t 2 , h t 3 , ..., h t m ]
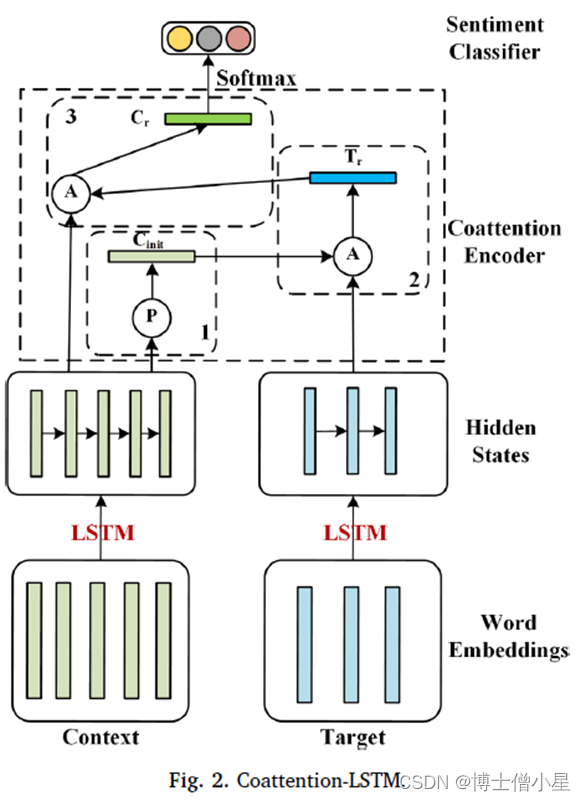
• 协同注意力编码器ü 首先根据上下文编码矩阵 C 得到上下文的初始表示 :ü 为了描述参与过程,定义一个评价函数来描述每个单词在目标上下文中的重要性: ,然后通过 softmax 函数得到目标归一化注意得分 :ü 然后,通过目标隐藏状态的加权组合得到目标注意力表示ü 同样,根据目标注意力表示 T r 计算上下文的注意力得分 :最后,通过上下文隐藏状态的加权组合得到上下文注意力表
示Cr:
ü 使用 C r 作为协同注意力编码器的输出进行情感分类;• 情感分类器 softmax
3.4 Coattention-MemNet
• 如图所示,与 Tang 等人( 2016b )使用的深度记忆网络类似,我们使用嵌入层作为上下文和目标编码器,上下文的编码结果被堆积为外部记忆。不同的是,目标是通过注意力函数而不是平均方法获得的。我们用 coattention 机制来代替传统的注意力,这样 Coattention- MemNet 就可以从目标和上下文中交替学习重要的特征。• 上下文和目标编码器ü 上下文 嵌入矩阵 C= [e c 1 , e c 2 , e c 3 , ..., e c n ] ,目标词嵌入矩阵 T= [e t 1 , e t 2 , e t 3 , ..., e t m ] ,每个 e i 来自矩阵 M v×d 的单词向量, v 表示词数, d 表示向量维度。
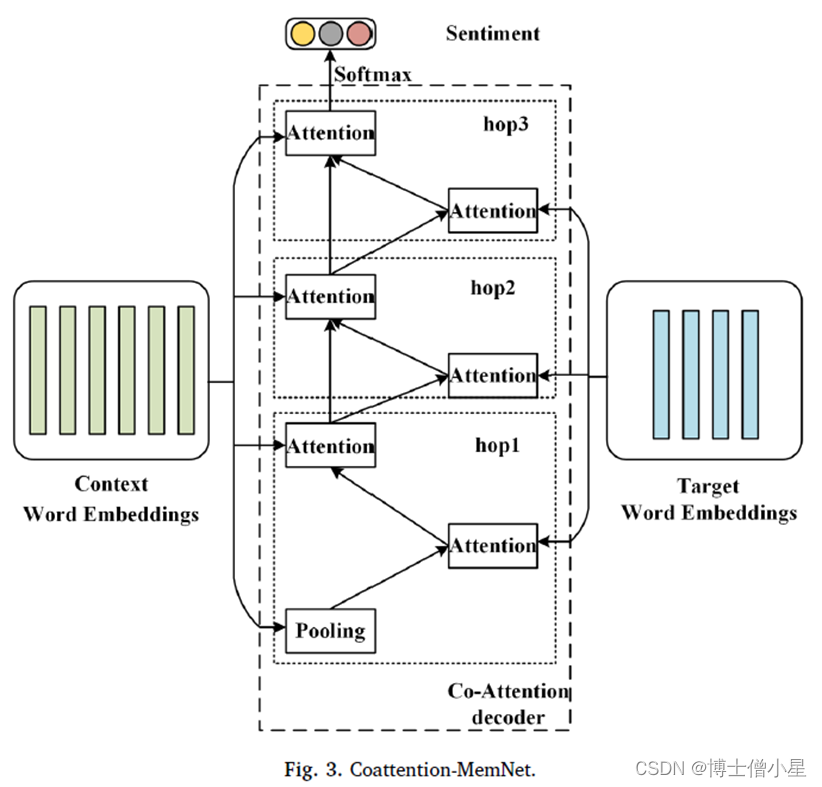
• 协同注意力编码器ü hop 1 层的计算过程与 Coattention-LSTM 相同。在 hop 1 层之后,当前上下文向量是最后一层输出的上下文表示,上下文注意力表示是基于上下文记忆、更新的目标特征和使用历史上下文信息更新的当前上下文特征计算的。ü 为了更具体地解释协同注意力编码器,将 C hop 和 T hop 分别定义为上下文向量表示和当前跳层的目标注意力表示。将 C hop_att 定义为基于 C hop 和 T hop 计算的上下文注意力表示。ü 具体来说,首先定义一个评价函数来描述每个目标词和上下文向量表示之间的关系。在这里,采用加法注意力,因为它在高维度上具有良好的性能:ü 然后通过 softmax 函数得到目标的归一化注意力分数。
• 协同注意力编码器ü 同样,根据目标注意表示 T hop 计算上下文的注意分数。üüü 如图 3 所示,在 hop1 层,上下文嵌入的平均池化结果用于初始化当前上下文表示。在计算目标注意力表示和上下文注意力表示之后,将当前层的最终上下文注意力结果作为下一层的上下文向量表示。这意味着与目标相关的上下文证据将被传递到下一层。在第 1 层之后,首先使用当前上下文表示获得当前层的目标注意力表示,然后结合计算的目标注意力表示计算上下文的注意力分数。ü 因此,第 1 跳层后的目标注意力表示的计算方法与 1 跳层相同:
• 协同注意力编码器ü 虽然跳层会重复多次,但每个跳层的参数都是共享的;ü 最后,使用从最后一跳层得到的上下文注意表示 C lasthop_att 作为共同注意力表示进行分类。• 情感分类器ü Softmax
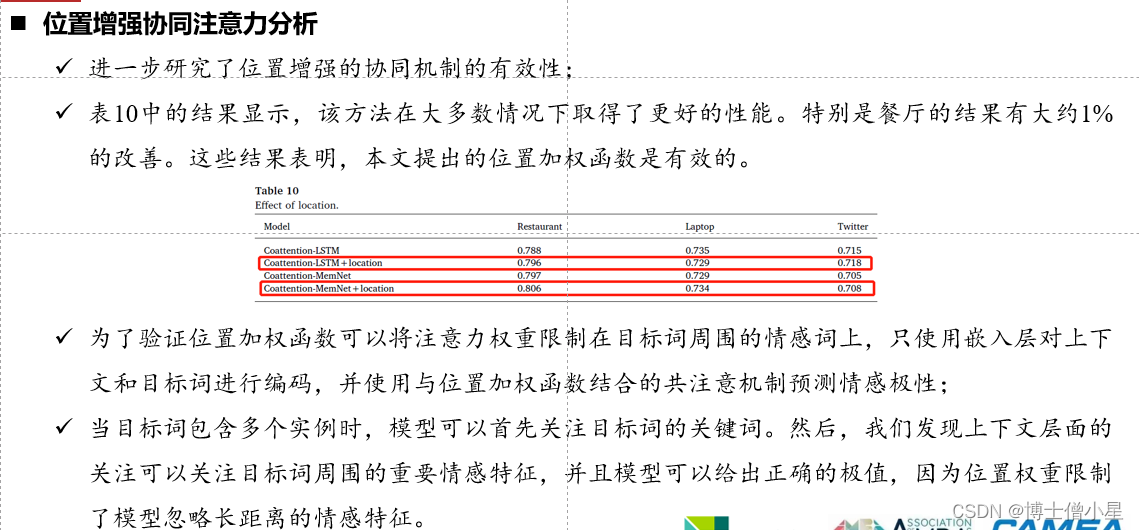
3.5 Location-enhanced coattention
n 位置增强协同注意力• 上面介绍的注意力过程包括两个步骤 。首先通过具有平均上下文的目标级注意力来获取目标的重要特征。然后,基于上下文级别的注意力提取与参与目标信息相关的关键情感特征。• 目标层注意力和上下文层注意力分别存在一个缺陷 。• 在目标级别的注意力中,我们的方法使用平均上下文计算注意力,这导致不同的目标特征由相同的上下文向量表示计算。此外,具有全局注意力的上下文级注意力并不总是能很好地发挥作用,尤其是在一个句子中出现多个具有不同极性的方面的情况下。“ great food but the service is dreadful !”句中“ great” 可修饰“ food” 和“ service” ,注意力难区分哪个情感词与特定方面更相关。• 为了解决这两个问题,尝试将位置先验信息加入到两个注意力过程中,认为一个词越接近目标,其对分类的贡献就越高 。一方面,在目标级注意力中加入位置先验信息,使模型更多地依赖于特定目标周围的上下文单词来计算目标的关键特征 ; 另一方面,在上下文级注意中加入位置先验信息将引导模型关注目标词周围的情感词,而不是全局词。

4.实验
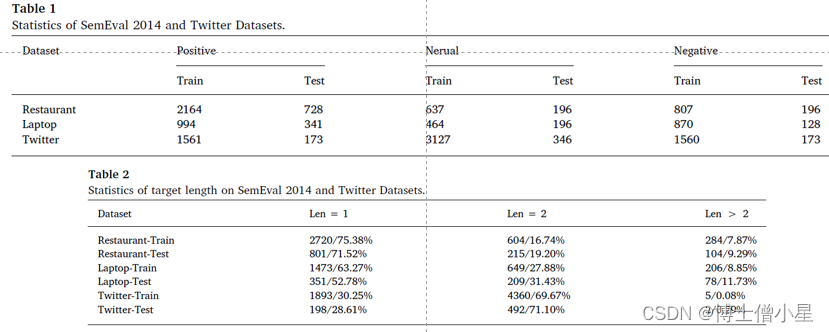
n 数据集ü SemEval 2014 和 Twitter 数据集(均为三种情绪极性);ü SemEval 2014 包括餐厅和笔记本电脑两个类别评论;ü 餐厅、笔记本电脑和 Twitter 数据集上,分别有超过 1/4 、 1/3 和 2/3 的目标词包含多个单词。
n 评价指标和参数ü Accuracy ( 指正确分类的样本占所有样本的比例 )ü 使用 300 维的 Glove 向量来初始化词嵌入,这些词嵌入是由网络数据训练出来的,词汇量为 1.9M ;ü 所有的权重都以均匀分布 U (-0.01, 0.01) 初始化,所有的偏置项都被设置为 0 ;ü 隐藏状态的维度被设置为 128 ;ü 用随机梯度下降训练模型,学习率被设置为 0.01 ;n 比较算法ü Majority ( 一种基线方法,将训练集中最大的情绪极性分配给测试集中的每个样本 )ü LSTM / TD-LSTM / AE-LSTM / ATAE-LSTM / AF-LSTMü IAN ( 交互学习上下文和目标中的注意,并分别为目标和上下文生成表示 )ü MemNet ( 多次应用注意力 (attention) ,最后一层注意的输出被输入 softmax 进行预测 )
4.1 网络分析 - Coattention-LSTM分析
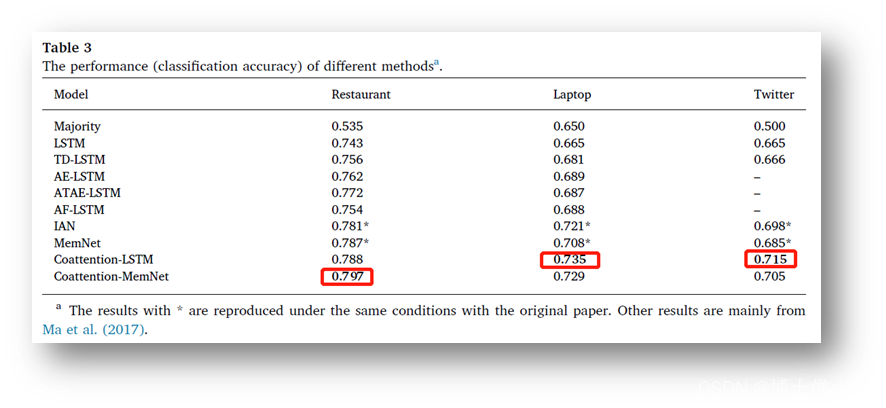
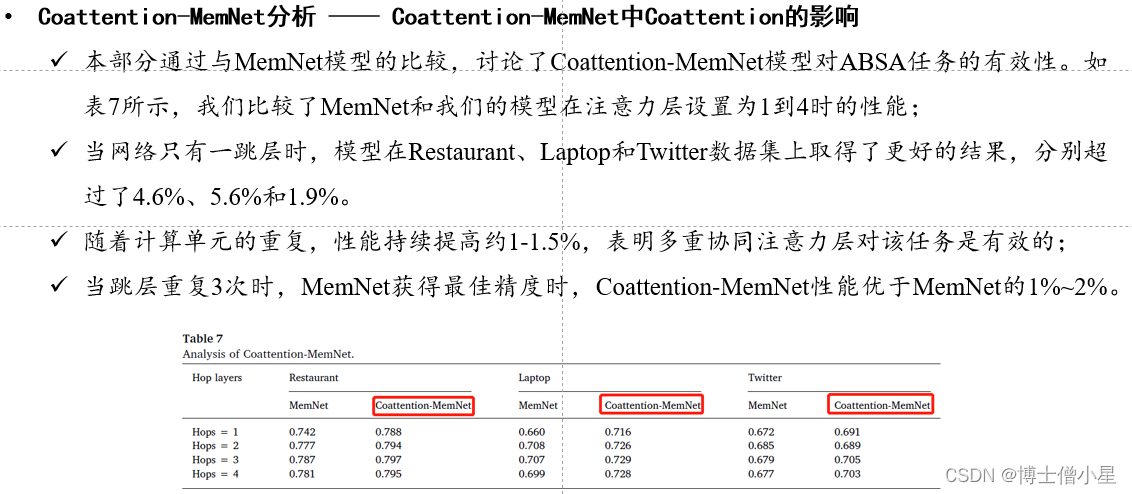
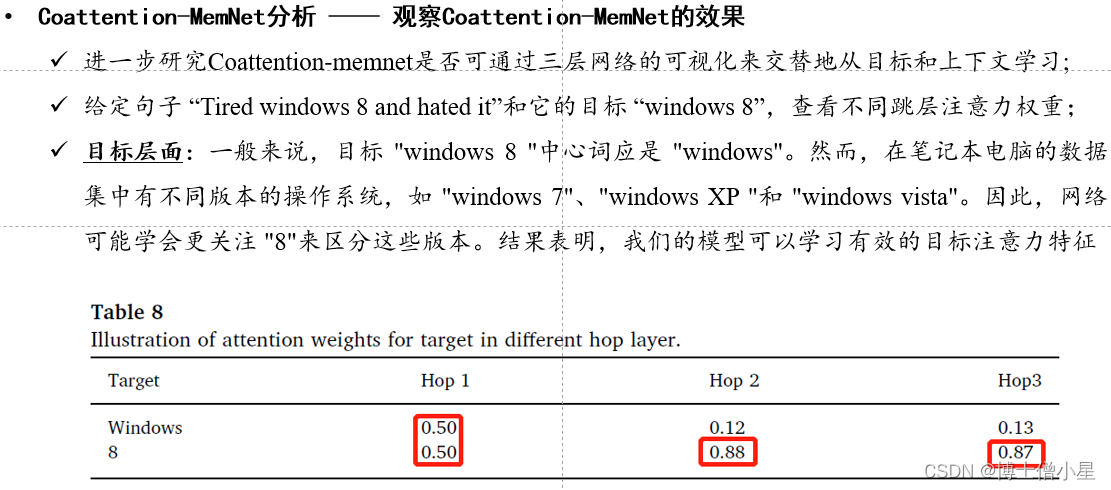
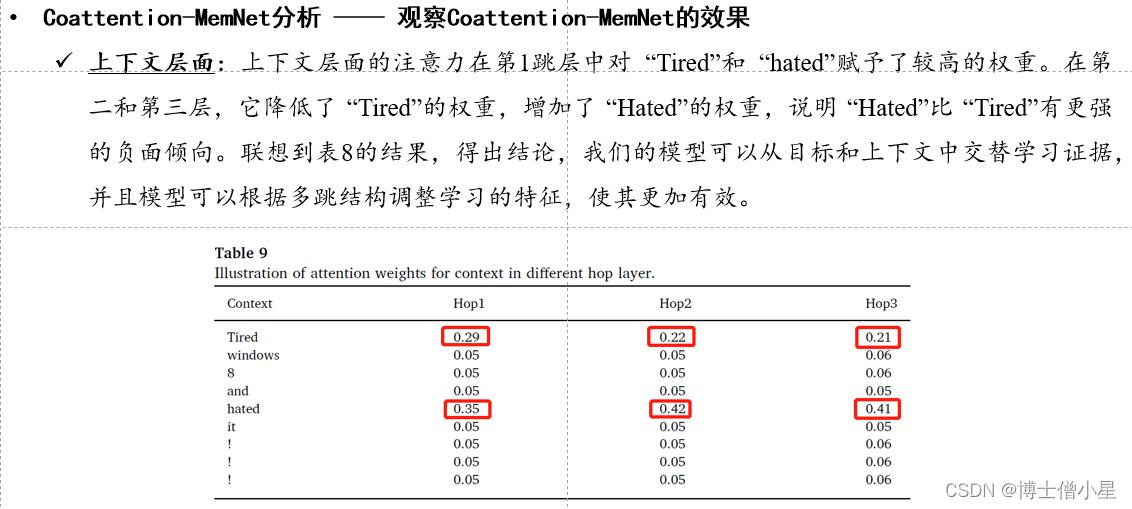
n 结果比较ü Majority 方法的性能最差;ü 所有神经网络方法中,具有平均池的 LSTM 方法性能最差,因为它忽略了目标信息;ü IAN 优于 ATAE-LSTM 和 AF-LSTM 约 2-3% ,因为它首先考虑用注意力对目标进行建模;ü MemNet 首次将记忆网络引入 ABSA 任务,准确率比 AE-LSTM 提高了约 2% ;ü 本文中提出的 Coattention-LSTM 比 IAN 有大约 1-1.5% 的提高;ü 本文中提出的 Coattention-MemNet 比 MemNet 有大约 1-2% 的改进;n 网络分析• Coattention-LSTM 分析ü 在这一部分,我们设计了多个模型来验证第 3 节中提出的Coattention-LSTM是一个更有效的用于
ABSA任务的交互网络。
4.2 Coattention-LSTM分析 —— Coattention-LSTM中Coattention的影响
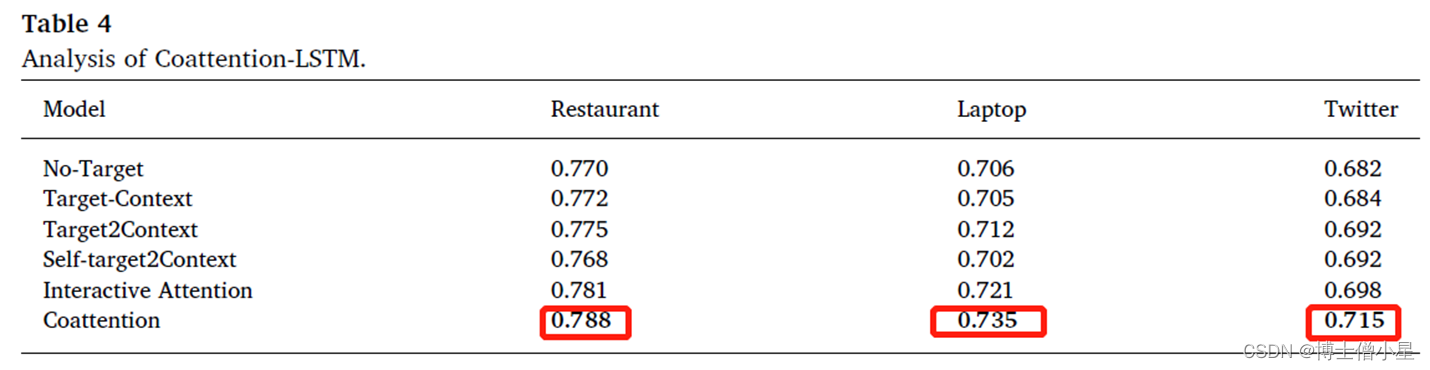
• 对照算法ü No - Target ( 用一个 LSTM 网络对上下文进行建模 )ü Target - Context ( 用两个 LSTM 分别对上下文和目标进行建模,结果拼接 )ü Target2Context ( 用两个 LSTM 分别对上下文和目标进行建模:先目标表示,后生成上下文表示进行分类 )ü Self - Target2Context ( 用两个 LSTM 分别对上下文和目标进行建模:先通过自我局部注意力学习目标表示,后生成上下文表示进行分类 )ü Interactive attention ( 用两个 LSTM 分别对上下文和目标进行建模:先用平均目标表示法生成上下文注意力表示,后用平均上下文表示法生成目标注意力表示法,最后,拼接结果进行分类 )ü Coattention ( 用两个 LSTM 分别对上下文和目标进行建模:先通过平均上下文表征得到目标注意力表征,然后生成上下文注意表征与目标注意力表征进行分类 )
• 结果比较ü No-Target 和 Target-Context 的结果接近,直接在最终表示中加入目标表示只会有微小的改善;ü Target2Context 比 Target-Context 和 No-Target 模型更出色,注意力对 ABSA 任务是有效的;ü Self-Target2Context 的性能最差 ( 没有上下文引导 ) ,上下文有助于目标注意力表征的学习,目标学习也有助于上下文注意力表征的学习;ü Coattention 的性能表现要优于 Target2Context 和 Interactive Attention 的表现;
4.3 Coattention-LSTM分析 —— 观察Coattention-LSTM的效果
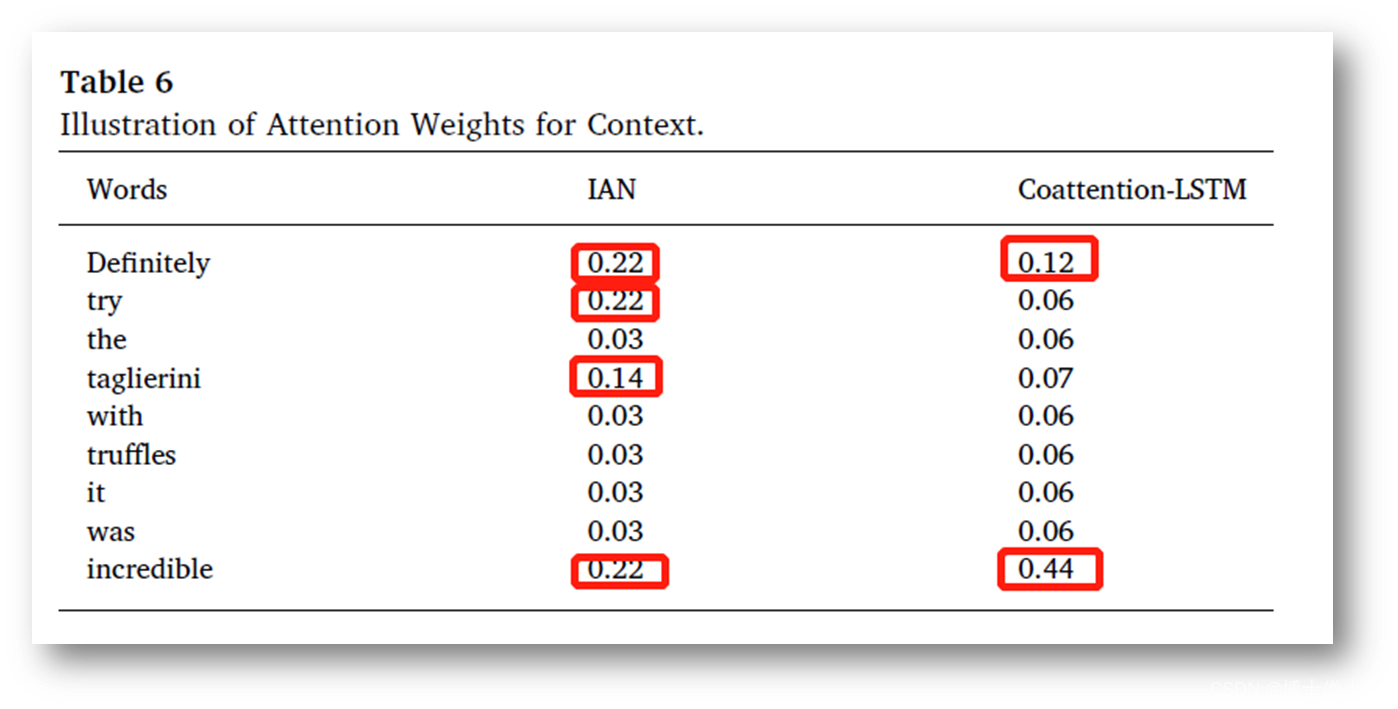
为了证明模型可以减少诸如介词( "in" , "of " 等)等噪音词的影响,并充分利用目标的关键词来学习更有效的上下文表述,比较了 IAN 和我们的模型在给定句子 "Definitely try the taglierini with truffles - it was incredible " 和其目标 "taglierini with truffles " 的可视化效果。很明显, "with " 是一个噪音词,而 "taglierini " 是目标词的中心词,比 "truffles " 更重要。ü 从表 5 的结果可以看出, IAN 和我们的模型都对“ taglierini” 给予了最高的权重。这意味着 IAN 和我们的模型都可以减少噪声的影响,学习目标的关键特征。ü 然而,有效的目标特征直接用于分类,而不是进一步用于与上下文的互动,因此由 IAN 学习的上下文特征的效果比我们的模型要差一些,这一点在表 6 中得到了说明。


5.结论与未来工作
• 提出了基于 coattention 机制的 Coattention-LSTM 网络,该网络可以交替学习目标和上下文的注意力表征,我们表明 Coattention-LSTM 中的 coattention 机制可以减少目标的噪声词的影响,并充分利用目标的关键词来学习更有效的情感分析的上下文表征;• 提出了 Coattention-MemNet ,它可以从目标和上下文中交替学习关键特征,并根据多跳结构调整所学特征,使其更加有效;• 提出了一个基于相对位置信息的 Coattention 机制的位置加权函数,它可以为一条评论中的多个目标生成不同的上下文特征,并限制网络关注目标周围的词语;• 由于使用 LSTM 或单词嵌入层来表示单词,而注意力只是一个加权和函数,它们很难学习单词之间的复杂关系,如否定修饰语和隐含的情感短语。在未来的工作中,计划设计一个上下文学习函数来捕捉局部上下文单词之间的关系,其复杂程度介于单词嵌入和 LSTM 之间。还将考虑在网络中加入外部知识,以解决否定修饰语的建模问题,并识别未知的情感词和短语。











![P8681 [蓝桥杯 2019 省 AB] 完全二叉树的权值:做题笔记](https://img-blog.csdnimg.cn/direct/5c7182cd578a4d289398725c18e9742f.png)
