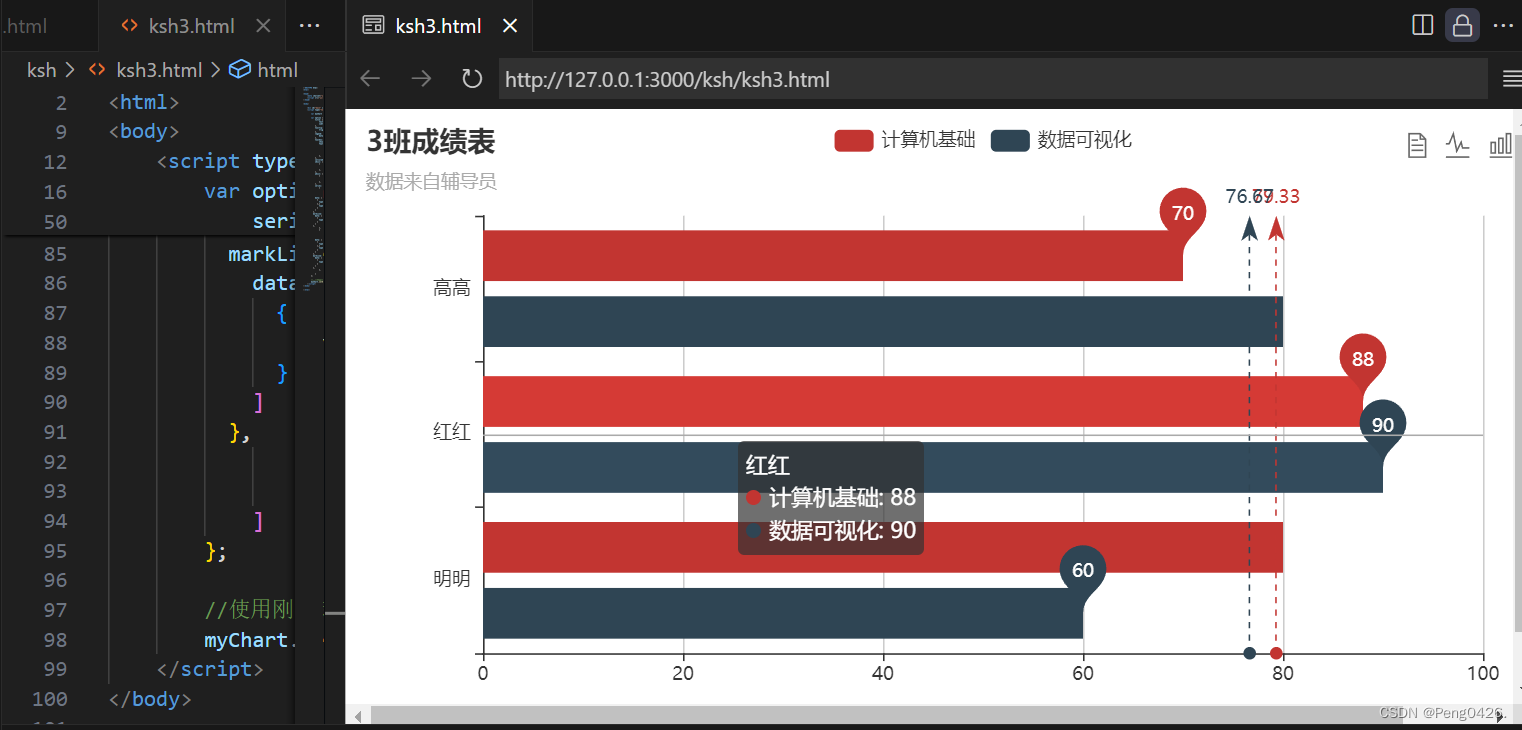
目录
- 中间件
- UA、代理处理---process_request
- UA随机
- 代理处理
- selenium+scrapy
中间件
控制台操作 (百度只起个名
scrapy startproject mid
scrapy genspider baidu baidu.com
setting.py内
ROBOTSTXT_OBEY = False
LOG_LEVEL = "WARNING"
运行
scrapy crawl baidu
middlewares.py 中间件
先看下载器中间件
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
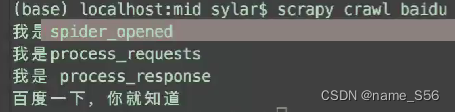
重点在 process_request
在引擎将请求的信息交给下载器之前,自动的调用该方法
process_response…
process_exception 异常 (看名就知道了…)
spider_open 爬虫开始
setting.py内 DOWNLOADER_MIDDLEWARES
运行顺序
UA、代理处理—process_request
process_request 返回值有规定
- 如果返回的 None,不做拦截,继续向后面的中间件执行.(多个中间件,权重大越往后)
- 如果返回的是Request.后续的中间件将不再执行.将请求重新交给引擎.引擎重新扔给调度器
- 如果返回的是Response,后续的中间件将不再执行.将响应信息交给引擎,引擎将响应丢给spider.进行数据处理
一个请求return ;yield一群
弄2个中间件???e.g.权重544 545
UA随机
老样子:
scrapy startproject douban
cd…
scrapy genspider movie douban.com
改settingROBOTSTXT_OBEY = False
LOG_LEVEL = “WARNING”scrapy crawl movie
豆瓣UA 失败
setting 内有
USER_AGENT =
动态UA
可以使用useragentsring.com设置一个USER_AGENT_LIST
middlewares只留process_request即可
def process_request(self, request, spider):
UA = choice(USER_AGENT_LIST)
request.headers['User-Agent'] = UA
return None
开启setting内的
DOWNLOADER_MIDDLEWARES = {
"douban.middlewares.DoubanDownloaderMiddleware": 543,
}
代理处理
setting内
DOWNLOADER_MIDDLEWARES = {
"douban.middlewares.DoubanDownloaderMiddleware": 543,
"douban.middlewares.ProxyDownloaderMiddleware": 545, #加
}
PROXY_IP_LIST = {
"IP:端口","IP:端口"
}
middlewares.py内
from douban.settings import PROXY_IP_LIST
from random import choice #随机
......
class ProxyDOwnloaderMiddleware:
def process_request(self,request,spider)
ip = choice(ProxyDOwnloaderMiddleware)
request.meta['proxy'] = "https://"+ip
return None #放行
selenium+scrapy
selenium作为下载器
由于想要替换掉原来的downloader,原中间件无意义
原最大中间价最大优先级100
DOWNLOADER_MIDDLEWARES = {
"zhipin.middlewares.ZhipinDownloaderMiddleware": 99,
}
如果有多个spider,替换掉的下载器可能占全局
想办法适配判断是否使用selenium 处理请求
新建request.py
from scrapy import Request
class SeleniumRequest(Request): #继承Request ,导致功能与scrapy一致
pass
爬虫内
from typing import Iterable
import scrapy
from zhipin.request import SeleniumRequest
class ZpSpider(scrapy.Spider):
name = "zp"
allowed_domains = ["zhipin.com"]
start_urls = ["https://zhipin.com"]
def start_requests(self):
yield SeleniumRequest(
url=self.start_urls[0],
callback=self.parse
)
def parse(self, response):
pass
middleware
from zhipin.request import SeleniumRequest
......
def process_request(self, request, spider):
#所有请求都回到这里
#需要进行判断。判断出是否需要用selenium来处理请求
#开始selenium的操作,返回页面源代码组装的response
#isinstance 判断xxx , 是不是 xxx类型
if isinstance(request,SeleniumRequest):
pass
else:
return None
return None
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:
- type() 不会认为子类是一种父类类型,不考虑继承关系。
- isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
不能以原来的思路写selenium because只有3个返回值–None Request Response
封装一个响应对象
在middlewares.py 导入一个类
from scrapy.http.response.html import HtmlResponse
......
def process_request(self, request, spider):
if isinstance(request,SeleniumRequest):
self.web.get(request.url)
page_source = self.web.page_source
return HtmlResponse(
url = request.url,
status=200,
headers=None,
body=page_source,
flags=None,
request=request,
Encoding = "utf-8"
) #来源于父类
return None