Perl 官网 www.cpan.org
从 https://strawberryperl.com/ 下载网速太慢了
建议从 https://download.csdn.net/download/qq_36286161/87892419
下载 strawberry-perl-5.32.1.1-64bit.zip 约105MB
解压后安装.msi,装完后有520MB+,建议安装在D:盘。
运行 cmd
cpan
install XML::DOM
在云计算中,解析XML元素和属性是一种常见的操作,因为XML是一种常见的数据交换格式,可以用来表示各种不同的数据结构和信息。Perl 是一种过去流行的脚本语言,可以用来处理各种文本数据,包括XML数据。
在Perl 中,可以使用各种模块和函数来解析 XML元素和属性。其中,常用的模块是 XML::DOM,它提供了一组完整的XML解析和处理函数,可以方便地解析XML文档中的元素和属性。
例如,下面是一个使用 XML::DOM 模块 解析 XML元素和属性 的示例代码:
先编写一个测试程序 test_xml_dom.pl 如下
#!/usr/bin/perl
use 5.010;
use strict;
use warnings;
use utf8;
use XML::DOM;
use Data::Dumper;
if ($#ARGV != 0){
die "You must specify a file.xml to parse";
}
my $file = shift @ARGV;
my $parser = new XML::DOM::Parser;
my $doc = $parser->parsefile($file)
or die "cannot read file.xml\n";
my $f2 = $file .'.txt';
# 写入文件
open(my $fw, '>:encoding(UTF-8)', $f2) or die "cannot open file '$f2' $!";
# print all TEXT attributes of all node elements
my $nodes = $doc->getElementsByTagName('node');
my $n = $nodes->getLength;
for (my $i=0; $i < $n; $i++)
{
my $node = $nodes->item ($i);
my $TEXT = $node->getAttributeNode('TEXT');
print $fw $TEXT->getValue ."\n";
}
close($fw);
# Avoid memory leaks - for garbage collection
$doc->dispose;
运行 perl test_xml_dom.pl your_test.xml
再编写 xml_dom_parser.pl 如下
#!/usr/bin/perl
use 5.010;
use strict;
use warnings;
use utf8;
use XML::DOM;
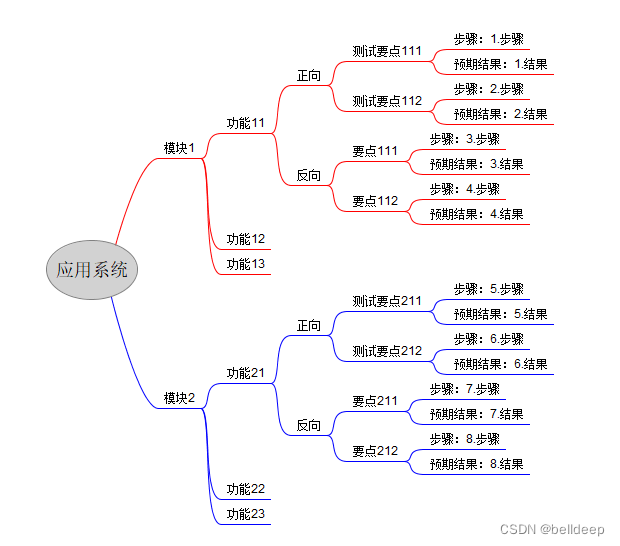
# 解析 Freeplane.mm文件,生成测试用例.csv文件
# xt: 应用系统名的英文或拼音缩写
# zd?: 字段?的拼音缩写
# zd1: 模块名
# zd2: 功能名
# zd3: 正向 或 反向
# zd4: 测试要点
# zd5: 执行步骤
# zd6: 预期结果
# csylms:测试用例描述
if ($#ARGV != 0){
die "You must specify a file.xml to parse";
}
my $file = shift @ARGV;
my $parser = new XML::DOM::Parser;
my $doc = $parser->parsefile($file)
or die "cannot read file.xml\n";
my $f2 = $file .'.csv';
# 写入文件
open(my $fw, '>:encoding(UTF-8)', $f2) or die "cannot open file '$f2' $!";
print $fw "应用系统名,模块名,测试用例描述,正反向,执行步骤,预期结果\n";
# 要检查一个字符串是否以另一个字符串开始,可使用字符串比较:
sub startsWith {
my ($str, $prefix) = @_;
return substr($str,0, length($prefix)) eq $prefix;
}
# 获取根节点
my $root = $doc->getFirstChild;
my $nodes = $root->getElementsByTagName('node');
my $node = $nodes->item(0);
say ref($node);
my $xt = $node->getAttributeNode('TEXT')->getValue;
my ($zd1,$zd2,$zd3,$zd4,$zd5,$zd6,$txt,$csylms);
$zd5 =''; $zd6 ='';
foreach my $node1 ($node->getChildNodes){
if($node1->getNodeType == ELEMENT_NODE and $node1->getTagName eq 'node'){
my $t1 = $node1->getAttributeNode('TEXT');
if ($t1){ $zd1 = $t1->getValue;}
foreach my $node2 ($node1->getChildNodes){
if($node2->getNodeType == ELEMENT_NODE and $node2->getTagName eq 'node'){
my $t2 = $node2->getAttributeNode('TEXT');
if ($t2){ $zd2 = $t2->getValue;}
foreach my $node3 ($node2->getChildNodes){
if($node3->getNodeType == ELEMENT_NODE and $node3->getTagName eq 'node'){
my $t3 = $node3->getAttributeNode('TEXT');
if ($t3){ $zd3 = $t3->getValue;}
foreach my $node4 ($node3->getChildNodes){
if($node4->getNodeType == ELEMENT_NODE and $node4->getTagName eq 'node'){
my $t4 = $node4->getAttributeNode('TEXT');
if ($t4){ $zd4 = $t4->getValue;}
foreach my $node5 ($node4->getChildNodes){
if($node5->getNodeType == ELEMENT_NODE and $node5->getTagName eq 'node'){
my $t5 = $node5->getAttributeNode('TEXT');
if ($t5){ $txt = $t5->getValue;
if (startsWith($txt, '步骤:')){
$zd5 = substr($txt, 3);
} elsif (startsWith($txt, '预期结果:')){
$zd6 = substr($txt, 5);
$csylms = $zd2 .'-'. $zd4; # 测试用例描述
print $fw "$xt,$zd1,$csylms,$zd3,$zd5,$zd6\n";
} else {
$zd5 =''; $zd6 ='';
}
}
}}
}}
}}
}}
}}
close($fw);
# Avoid memory leaks - for garbage collection
$doc->dispose;
运行 perl xml_dom_parser.pl your_test.mm
应用系统名,模块名,测试用例描述,正反向,执行步骤,预期结果
应用系统,模块1,功能11-测试要点111,正向,1.步骤,1.结果
应用系统,模块1,功能11-测试要点112,正向,2.步骤,2.结果
应用系统,模块1,功能11-要点111,反向,3.步骤,3.结果
应用系统,模块1,功能11-要点112,反向,4.步骤,4.结果
应用系统,模块2,功能21-测试要点211,正向,5.步骤,5.结果
应用系统,模块2,功能21-测试要点212,正向,6.步骤,6.结果
应用系统,模块2,功能21-要点211,反向,7.步骤,7.结果
应用系统,模块2,功能21-要点212,反向,8.步骤,8.结果
参阅:XML::DOM - A perl module for building DOM Level 1 compliant document structures - metacpan.org