文章目录
- Dubbo概念_什么是分布式系统
- 单机架构
- 集群架构
- 分布式架构
- 单机、集群和分布式的区别
- Dubbo概念_什么是RPC
- RPC两个作用:
- 常见 RPC 技术和框架:
- Dubbo概念_简介
- Dubbo能做什么
- Dubbo支持的协议
- Dubbo概念_核心组件
- 注册中心Registry
- 服务提供者Provider
- 服务消费者Consumer
- 监控中心Monitor
- Dubbo配置开发环境_Zookeeper注册中心
- 下载Zookeeper镜像
- 启动运行容器
- 进入容器
- Dubbo配置开发环境_管理控制台
- 下载Dubbo-Admin镜像
- 启动运行容器
- 可视化界面
- Dubbo入门案例_需求介绍
- 单体架构
- 分布式架构
- Dubbo入门案例_服务生产者配置
- 创建SpringBoot项目并引入依赖
- 代码编写
- Dubbo入门案例_服务消费者配置
- 创建SpringBoot项目并引入依赖
- 代码编写
- Dubbo高级特性_序列化协议安全
- Dubbo高级特性_地址缓存
- Dubbo高级特性_超时时间与配置覆盖关系
- 配置超时时间
- 配置覆盖关系
- Dubbo高级特性_重试机制
- 重试机制配置
- Dubbo高级特性_多版本
- 多版本配置
- Dubbo高级特性_负载均衡
- Dubbo内置负载均衡策略
- 负载均衡策略配置
- Dubbo高级特性_集群容错
- 容错模式
- 集群容错配置
- Dubbo高级特性_服务降级
- 服务降级方式
- Dubbo高级特性_服务限流原理
- 限流算法
- 漏桶算法
- 令牌桶算法
- 漏桶 vs 令牌桶的区别
- Dubbo高级特性_服务限流实现
- Dubbo高级特性_结果缓存
- 配置缓存
Dubbo概念_什么是分布式系统
单机架构
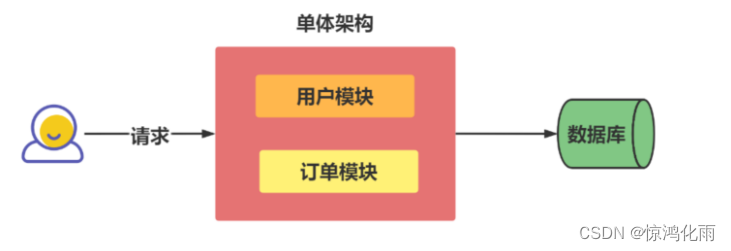
系统业务量很小的时候所有的代码都放在一个项目中,然后这个项目部署在一台服务器上,整个项目所有的服务都由这台服务器提供。
缺点:
- 服务性能存在瓶颈
- 代码量庞大,系统臃肿,牵一发动全身
- 单点故障问题
集群架构
单机处理到达瓶颈的时候,你就把单机复制几份,这样就构成了一个集群。
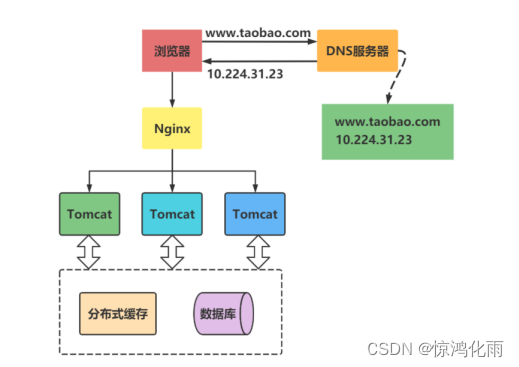
集群存在的问题:
当你的业务发展到一定程度的时候,你会发现一个问题无论怎么增加节点,貌似整个集群性能的提升效果并不明显了。这时候,你就需要使用分布式架构了。
分布式架构
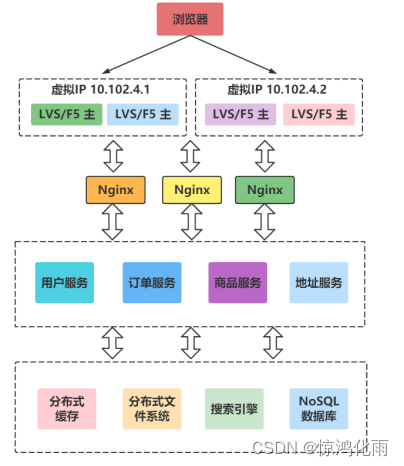
分布式架构就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在分布式结构中,每个子系统就被称为“服务”。这些子系统能够独立运行在web容器中,它们之间通过RPC方式通信。
分布式的优势:
- 系统之间的耦合度大大降低,可以独立开发、独立部署、独立测试,系统与系统之间的边界非常明确,排错也变得相当容易,开发效率大大提升。
- 系统之间的耦合度降低,从而系统更易于扩展。我们可以针对性地扩展某些服务。
- 服务的复用性更高。比如,当我们将用户系统作为单独的服务后,该公司所有的产品都可以
使用该系统作为用户系统,无需重复开发。
单机、集群和分布式的区别
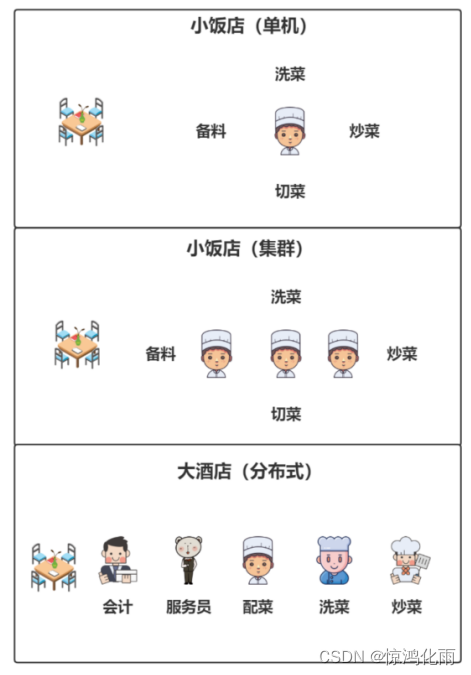
单机就是相当于一个小饭店,在这个饭店里只有一个员工他负责洗菜、做饭和上菜等;
集群就是一个小饭店里面有多个员工负责洗菜、切菜、炒菜和上菜;
分布式就相当于是一个大饭店有专门的人负责会计业务,有专门的服务员负责上菜,有专门的厨师负责炒菜等
将一套系统拆分成不同子系统部署在不同服务器上(这叫分布式),然后部署多个相同的子系统在不同的服务器上(这叫集群)。
集群: 多个人在一起作同样的事 。
分布式 : 多个人在一起作不同的事 。
Dubbo概念_什么是RPC
RPC(Remote Procedure Call)远程过程调用,它是一种通过网络从远程计算机程序上请求服务。
RPC两个作用:
- 屏蔽远程调用跟本地调用的区别,让我们感觉就是调用项目内的方法
- 隐藏底层网络通信的复杂性,让我们更加专注业务逻辑。
常见 RPC 技术和框架:
RPC是一种技术思想而非一种规范或协议。
- 阿里的 Dubbo/Dubbox
- Google gRPC
- Spring Cloud。
Dubbo概念_简介
Apache Dubbo是一款高性能、轻量级的开源服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。
Dubbo能做什么
- 透明化的远程方法调用,就像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入。
- 软负载均衡及容错机制,可在内网替代F5等硬件负载均衡器,降低成本,减少单点。
- 服务自动注册与发现,不再需要写死服务提供方地址,注册中心基于接口名查询服务提供者的IP地址,并且能够平滑添加或删除服务提供者
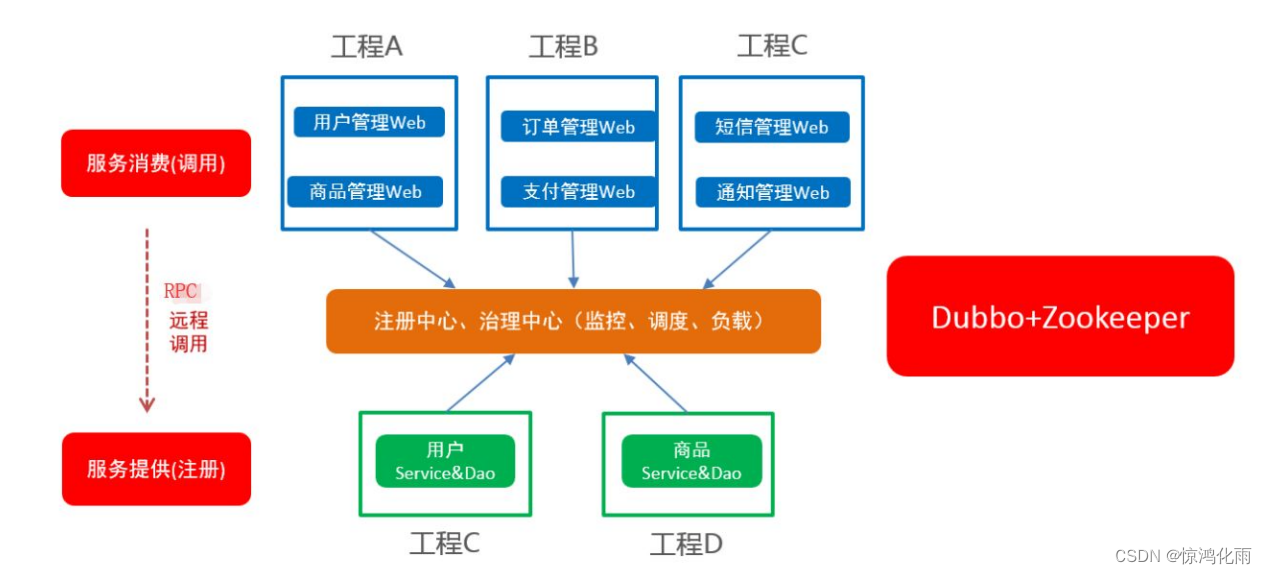
Dubbo采用全Spring配置方式,透明化接入应用,对应用没有任何API侵入,只需用Spring加载Dubbo的配置即可。
Dubbo支持的协议
- Dubbo协议
- Hessian协议
- HTTP协议
- RMI协议
- WebService协议
- Memcached协议
- Redis协议
推荐: 使用Dubbo协议。
Dubbo概念_核心组件
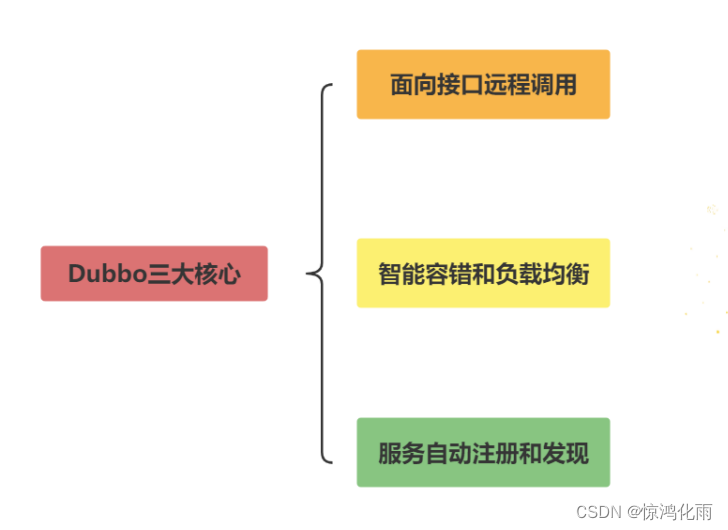
注册中心Registry
在Dubbo微服务体系中,注册中心是其核心组件之一。Dubbo通过注册中心实现了分布式环境中各服务之间的注册与发现,是各个分布式节点之间的纽带。
其主要作用如下:
- 动态加入: 一个服务提供者通过注册中心可以动态地把自己暴露给其他消费者,无须消费者逐个去更新配置文件。
- 动态发现: 一个消费者可以动态地感知新的配置、路由规则和新的服务提供者,无须重启服务使之生效。
- 动态调整: 注册中心支持参数的动态调整,新参数自动更新到所有相关服务节点。
- 统一配置: 避免了本地配置导致每个服务的配置不一致问题。
常见的注册中心有zookeeper 、eureka、consul、etcd。
服务提供者Provider
服务消费者Consumer
监控中心Monitor
主要负责监控统计调用次数和调用时间等。
Dubbo配置开发环境_Zookeeper注册中心
下载Zookeeper镜像
docker pull zookeeper:3.5.9
启动运行容器
docker run --name zk -d -p 2181:2181 zookeeper:3.5.9
参数:
-d:守护进程运行
-p:映射端口号
进入容器
docker exec -it zk /bin/bash
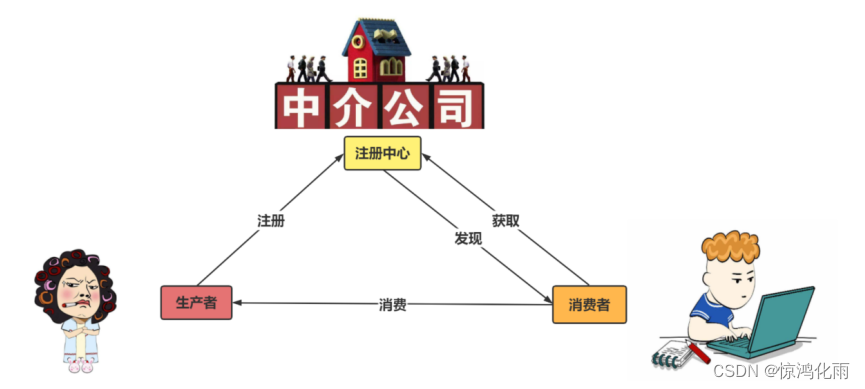
Dubbo配置开发环境_管理控制台
Dubbo-admin管理平台,图形化的服务管理页面,安装时需要指定注册中心地址,即可从注册中心中获取到所有的提供者/消费者进行配置管理。2
下载Dubbo-Admin镜像
docker pull docker.io/apache/dubbo-admin
启动运行容器
docker run -d \
--name dubbo-admin \
-p 9600:8080 \
-e admin.registry.address=zookeeper://192.168.52.129:2181 \
-e admin.config-center=zookeeper://192.168.52.129:2181 \
-e admin.metadata-report.address=zookeeper://192.168.52.129:2181 \
--restart=always \
docker.io/apache/dubbo-admin
参数:
- - restart:always 容器退出时总是重启
admin.registry.address:注册中心
admin.config-center:配置中心
admin.metadata-report.address:元数据中心
可视化界面
浏览器输入http://192.168.52.129:9600,用户名root 密码 root
如果出现下面这种现象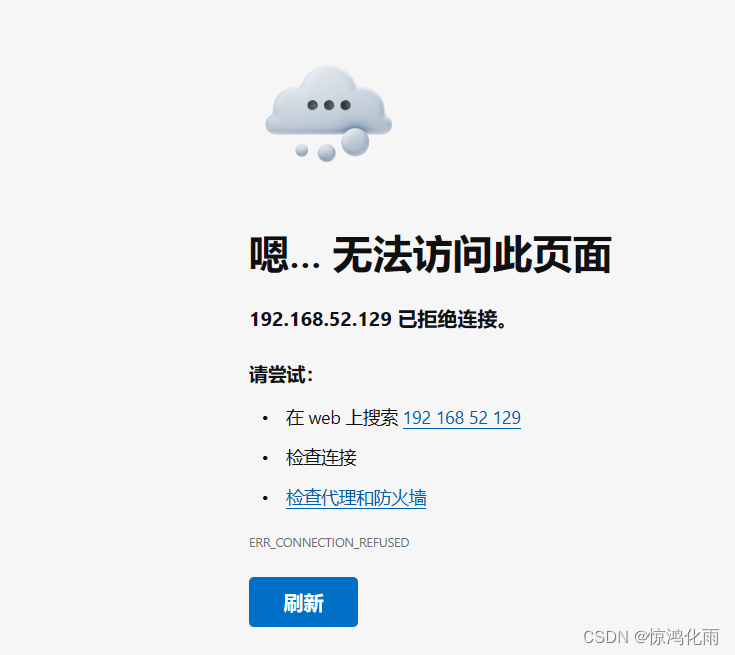
首先先关闭防火墙
# 检查防火墙状态
firewall-cmd --state
# 关闭防火墙服务
systemctl stop firewalld.service
# 禁止开机自启防火墙
systemctl disable firewalld.service
需要更换Docker的源镜像
vim /etc/docker/daemon.json
添加
{
"registry-mirrors": ["https://f9dk003m.mirror.aliyuncs.com"]
}
然后重启Docker服务
service docker restart
然后先删除原有的镜像,重新拉取镜像运行
Dubbo入门案例_需求介绍
单体架构
分布式架构
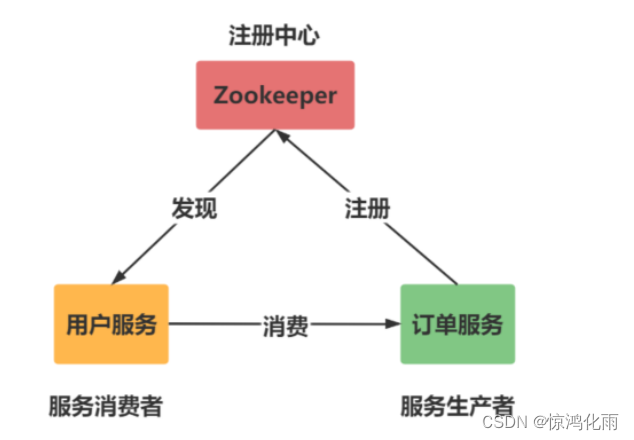
订单服务功能如下:
- 创建订单
- 根据用户id查询订单详情
用户服务功能如下:
- 创建订单
- 根据用户id查询订单详情
Dubbo入门案例_服务生产者配置
创建SpringBoot项目并引入依赖
<!-- 整合dubbo -->
<dependency>
<groupId>io.dubbo.springboot</groupId>
<artifactId>spring-boot-starter-dubbo</artifactId>
<version>1.0.0</version>
</dependency>
<!-- zookeeper客户端 -->
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.7</version>
</dependency>
代码编写
1. 创建订单实体类
/**
* 订单模型
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order implements Serializable {
// 订单id
private Long id;
// 用户id
private Long userId;
// 订单总价格
private Double prict;
// 收货人手机号
private String mobile;
// 收货人地址
private String address;
// 支付类型 1:微信 2:支付宝
private Integer pay_method;
}
2. 编写订单接口
public interface IOrderService {
//创建订单
void createOrders(Order orders);
//根据用户id查询订单详情
Order findByuserId(Long userid);
}
3.创建统一返回结果集实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class CommonResult <T> implements Serializable {
// 返回结果编码
private Integer code;
// 返回结果描述
private String message;
// 数据
private T data;
private CommonResult(Integer code,String message) {
this(code, message, null);
}
}
4. 编写订单业务实现类
import com.alibaba.dubbo.config.annotation.Service;
@Service // 将这个类提供的方法 对外发布,将访问的地址 IP 端口 路径注册到注册中心
public class IOrderServiceImpl implements IOrderService {
@Override
public CommonResult createOrders(Order orders) {
CommonResult commonResult = new CommonResult();
// 返回结果编码
commonResult.setCode(200);
// 返回结果描述信息
commonResult.setMessage("创建成功");
return commonResult;
}
@Override
public CommonResult findByuserId(Long userid) {
//TODO 模拟数据库操作
CommonResult commonResult = new CommonResult();
// 返回结果编码
commonResult.setCode(200);
// 返回结果描述信息
commonResult.setMessage("查询成功");
// 返回结果集
Order orders = new Order();
orders.setId(1L);
orders.setUserId(1L);
orders.setPrict(121.1);
orders.setMobile("18588888888");
orders.setAddress("北京市海淀区中关村");
orders.setPay_method(1);
commonResult.setData(orders);
return commonResult;
}
}
@Service 这个不是Spring里面的注解而是 Dubbo里面的注解
Dubbo 的 @Service 注解是 将这个类提供的方法(服务) 对外发布。将访问的地址 ip 端口 路径 注册到注册中心
Spring的 @Service 注解是 将该类的对象创建出来放到spring的IOC容器中。 bean定义
5. 服务生产者编写配置文件
# 端口号
server.port=9090
# 1. 配置项目名称
spring.dubbo.application.name=order-service
# 2. 配置注册中心地址
spring.dubbo.registry.address=zookeeper://192.168.52.129
spring.dubbo.registry.port=2181
# 3. 指定dubbo使用的协议、端口
spring.dubbo.protocol.name=dubbo
spring.dubbo.protocol.port=20880
# 4. 指定注册到zk上超时时间,ms
spring.dubbo.registry.timeout=10000
# 5. 配置Dubbo包扫描
spring.dubbo.scan=com.gb.service
Dubbo入门案例_服务消费者配置
创建SpringBoot项目并引入依赖
<!-- 整合dubbo -->
<dependency>
<groupId>io.dubbo.springboot</groupId>
<artifactId>spring-boot-starter-dubbo</artifactId>
<version>1.0.0</version>
</dependency>
<!-- zookeeper客户端 -->
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.7</version>
</dependency>
代码编写
1. 创建用户实体类
/**
* 用户模型
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable {
//用户id
private Long id;
// 用户名字
private String name;
}
2. 编写用户接口
/**
* 用户接口
*/
public interface IUserService {
//根据用户id查询订单详情
CommonResult<Order> findByUserId(Long id);
}
3. 编写用户接口实现类
@Service // 这个注解是Spring的注解 需要放到容器中
public class UserServiceImpl implements IUserService {
/**
* 1. 从Zookeeper注册中心获取IOrderService 的访问url
* 2. 进行远程调用RPC
* 3. 将结果封装为一个代理对象,交给这个变量赋值
*/
@Reference
//引入订单服务
private IOrderService iOrderService;
/**
* 根据用户ID查询用户详情
* @param id 用户id
* @return
*/
@Override
public CommonResult findByUserId(Long id) {
return iOrderService.findByuserId(id);
}
}
3. 编写用户控制层
@RestController
public class UserController {
@Autowired
private IUserService iUserService;
@GetMapping("/findByUserId")
public CommonResult findByUserId(Long userId){
CommonResult byUserId = iUserService.findByUserId(userId);
return byUserId;
}
}
4. 加入Dubbo配置
# 端口号
server.port=8080
# 1. 配置项目名称
spring.dubbo.application.name=user-service
# 2. 配置注册中心地址
spring.dubbo.registry.address=zookeeper://192.168.52.129
spring.dubbo.registry.port=2181
# 3. 指定dubbo使用的协议、端口
spring.dubbo.protocol.name=dubbo
spring.dubbo.protocol.port=20881
# 4. 指定注册到zk上超时时间,ms
spring.dubbo.registry.timeout=10000
# 5. 配置Dubbo包扫描
spring.dubbo.scan=com.gb.service
Dubbo高级特性_序列化协议安全
为什么需要序列化
网络传输的数据必须是二进制数据,但调用方请求的出入参数都是对象。
Dubbo高级特性_地址缓存
面试题: 注册中心挂了,服务是否可以正常访问?
答案:
因为dubbo服务消费者在 第一次调用时 , 会将服务提供方地址缓存到本地 ,以后在调用则不会访问注册中心。服务提供者地址发生变化时,注册中心会通服务消费者。
Dubbo高级特性_超时时间与配置覆盖关系
问题:
服务消费者在调用服务提供者的时候发生了阻塞、等待的情形,这个时候,服务消费者会一直等待下去。在某个峰值时刻,大呈的请求都在同时请求服务消费者,会造成线程的大呈堆积,势必会造成雪崩。
解决办法:
dubbo利用超时机制来解决这个问题,设置一个超时时间,在这个时间段内,无法完成服务访问,则自动断开连接。
配置超时时间
服务生产者端
使用timeout属性配置超时时间,默认值1000,单位毫秒。
@Service(timeout = 3000) //当前服务3秒超时
public class OrderServiceImpl implementsIOrderService {}
服务消费端
@Reference(timeout = 2000)// 远程注入
private IOrderService iOrderService;
配置覆盖关系
如果设置了@Reference(timeout=?)超时时间那么这个超时时间会覆盖掉@Service(timeout = ?)的超时时间
通常开发中只需要配置服务端生产端@Service(timeout = ?)的超时时间,业务上有一些特殊要求才会使用@Reference(timeout=?)
Dubbo高级特性_重试机制
问题:
如果出现网络抖动,则会出现请求失败。
解决办法:
Dubbo提供重试机制来避免类似问题的发生。
重试机制配置
Dubbo在调用服务不成功时,默认会重试2次。如果配置了retries 属性会再去进行重试
@Service(timeout = 3000,retries = 2)
Dubbo高级特性_多版本
Dubbo提供多版本的配置,方便我们做服务的灰度发布,或者是解决不兼容的问题。
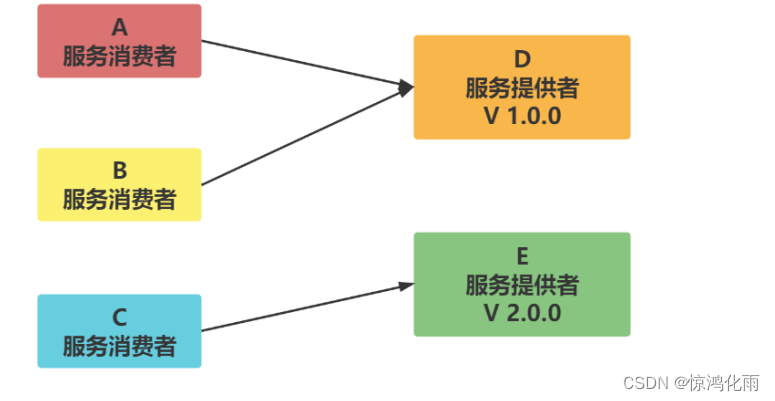
灰度发布(金丝雀发布):
当出现新功能时,会让一部分用户先使用新功能,用户反馈没问题时,再将所有用户迁移到新功能。
多版本配置
// 第一个版本服务
@Service(version = "1.0.0")
// 第二个版本服务
@Service(version = "2.0.0")
// 消费者使用第二个版本服务
@Reference(version = "2.0.0")
// 如果不需要区分版本
@Reference(version = "*")
总共需要三个服务,生产者第一个版本服务,生产者第二个版本服务, 消费者服务
Dubbo高级特性_负载均衡
Dubbo是一个分布式服务框架,能避免单点故障和支持服务的横向扩容。一个服务通常会部署多个实例。
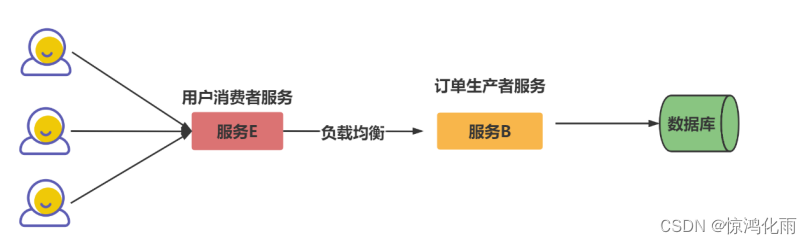
为了避免单点故障会部署多个服务
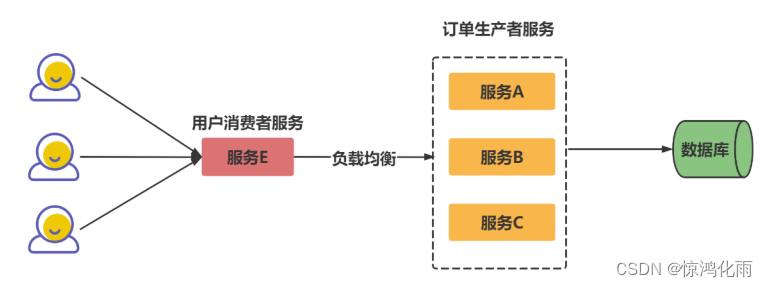
如何从多个服务 Provider 组成的集群中挑选出一个进行调用,就涉及到一个负载均衡的策略。
Dubbo内置负载均衡策略
- RandomLoadBalance:随机负载均衡,随机的选择一个,默认负载均衡。
- RoundRobinLoadBalance:轮询负载均衡。
- LeastActiveLoadBalance:最少活跃调用数,相同活跃数的随机。
- ConsistentHashLoadBalance:一致性哈希负载均衡,相同参数的请求总是落在同一台机器上。
负载均衡策略配置
如果不指定负载均衡,默认使用随机负载均衡。我们也可以根据自己的需要,显式指定一个负载均衡。
// 生产者服务
@Service(timeout = 3000,retries =3,loadbalance = "roundrobin")
//消费者服务
@Reference(timeout = 2000,loadbalance ="roundrobin")
参数:
random:随机负载均衡
leastactive:最少活跃调用数,相同活跃数的随机
roundrobin:轮询负载均衡
consistenthash:一致性哈希负载均衡
Dubbo高级特性_集群容错
Dubbo框架为服务集群容错提供了一系列好的解决方案,在此称为dubbo服务集群容错模式。
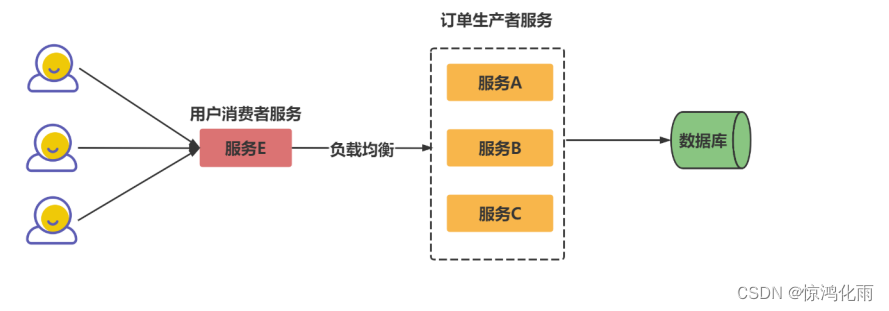
就是如果服务E请求的是服务A出错了的一系列解决方案。
容错模式
- Failover Cluster:失败重试。默认值。当出现失败,重试其它服务器,默认重试2次,使用retries配置。一般用于读操作
- Failfast Cluster : 快速失败,只发起一次调用,失败立即报错。通常用于写操作。
- Failsafe Cluster : 失败安全,出现异常时,直接忽略。返回一个空结果。日志不重要操作。
- Failback Cluster : 失败自动恢复,后台记录失败请求,定时重发。非常重要的操作。
- Forking Cluster:并行调用多个服务器,只要有一个成功即返回。
- Broadcast Cluster:广播调用所有提供者,逐个调用,任意一台报错则报错。 同步要求高的可以使用这个模式。
集群容错配置
failover:
功能:失败自动切换。当调用远程服务失败时,会自动尝试其他可用的服务提供者,通常用于读操作场景。
示例:@Reference(cluster = "failover")
failfast:
功能:快速失败。只要调用失败,立即报错,不进行重试。适合用于非幂等性写操作或其他不允许重试的场景。
示例:@Reference(cluster = "failfast")
failsafe:
功能:失败安全。调用失败时,直接忽略错误,不抛出异常。通常用于那些即使失败也不会影响系统正常运行的操作,如记录日志。
示例:@Reference(cluster = "failsafe")
failback:
功能:失败自动恢复。当调用失败后,会记录失败请求,并定时重试,直到成功为止。适用于网络不稳定但需要最终一致性的场景。
示例:@Reference(cluster = "failback")
forking:
功能:并行调用多个服务提供者,只要有一个成功就返回。这种方式下,可以在配置中设定最大并发数。
示例:@Reference(cluster = "forking")
broadcast:
功能:广播调用所有提供者,所有提供者都会收到请求并执行,通常用于通知所有服务实例更新缓存或其他状态同步场景。
示例:@Reference(cluster = "broadcast")
Dubbo高级特性_服务降级
服务降级,当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
简单来说就是关闭一些不重要的服务来保证核心业务的正常运行
两种场景:
当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度!
当下游的服务因为某种原因不可用,上游主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户!
服务降级方式
//表示消费方对该服务的方法调用都直接返回null值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。
@Reference(mock ="force:return null")
//表示消费方对该服务的方法调用在失败后,再返回null值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响。
@Reference(mock ="fail:return null")
Dubbo高级特性_服务限流原理
限流算法
漏桶算法
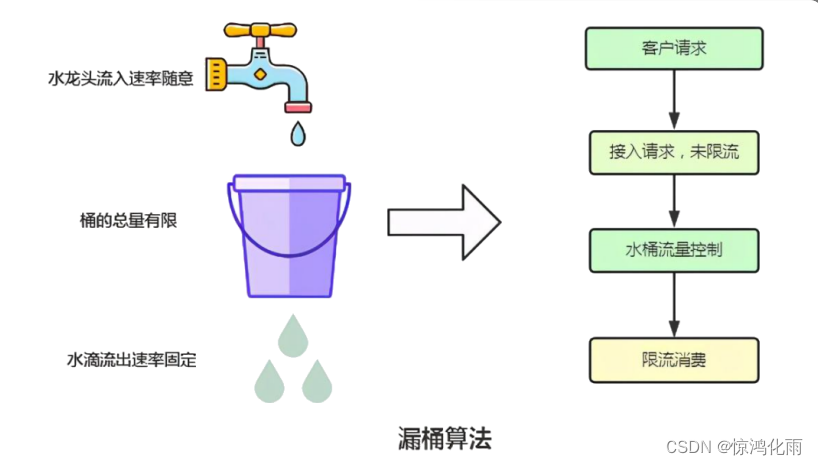
原理:
漏桶算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
令牌桶算法
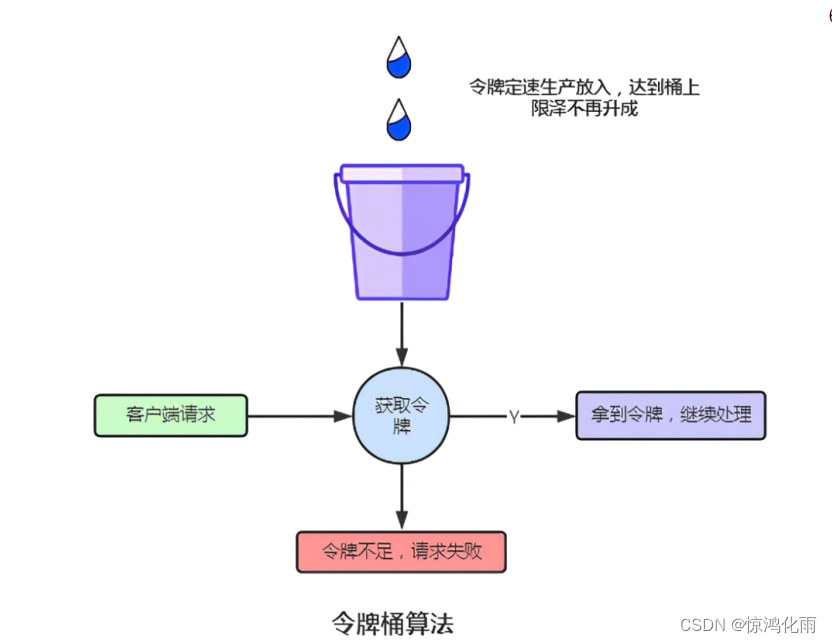
原理:
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
漏桶 vs 令牌桶的区别
漏桶的天然特性决定了它不会发生突发流量,就算每秒1000个请求到来,那么它对后台服务输出的访问速率永远恒定。而令牌桶则不同,其特性可以“预存”一定量的令牌,因此在应对突发流量的时候可以在短时间消耗所有令牌,其突发流量处理效率会比漏桶高,但是导向后台系统的压力也会相应增多。
Dubbo高级特性_服务限流实现
为了防止某个消费者的QPS或是所有消费者的QPS总和突然飙升而导致的重要服务的失效,系统可以对访问流量进行控制,这种对集群的保护措施称为服务限流。
//第一种并发控制,服务端并发执行(或占用线程池线程数)不能超过10个
@Service(executes = 10)
//第二种连接控制,占用连接的请求的数不能超过10个。
@Service(actives= 10)
这个配置的@Service是在消费者服务中 属于Dubbo包的@Service
Dubbo高级特性_结果缓存
结果缓存,用于加速热门数据的访问速度,Dubbo提供声明式缓存,以减少用户加缓存的工作量。
Dubbo提供了三种结果缓存机制:
- lru: 基于最近最少使用原则删除多余缓存,保持最热的数据被缓存-—…_
- threadlocal: 当前线程缓存,比如一个页面渲染,用到很多portal,每个portal都要去查用户信
息,通过线程缓存,可以减少这种多余访问。 - jcache: 与JSR107集成,可以桥接各种缓存实现。
配置缓存
// 在消费者服务中配置
@Reference(cache="lru")
生产者服务可以使用Redis缓存
![[ C++ ] STL---string类的使用指南](https://img-blog.csdnimg.cn/direct/7b8abf46fa334913a51aae7b7138afc4.png)