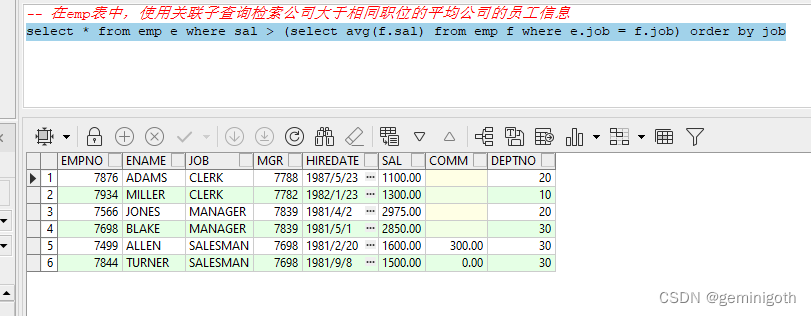
找到字符串中所有字母异位词
- 1. 题目解析
- 2. 讲解算法原理
- 3. 编写代码
1. 题目解析
题目地址:找到字符串中所有字母异位词

2. 讲解算法原理

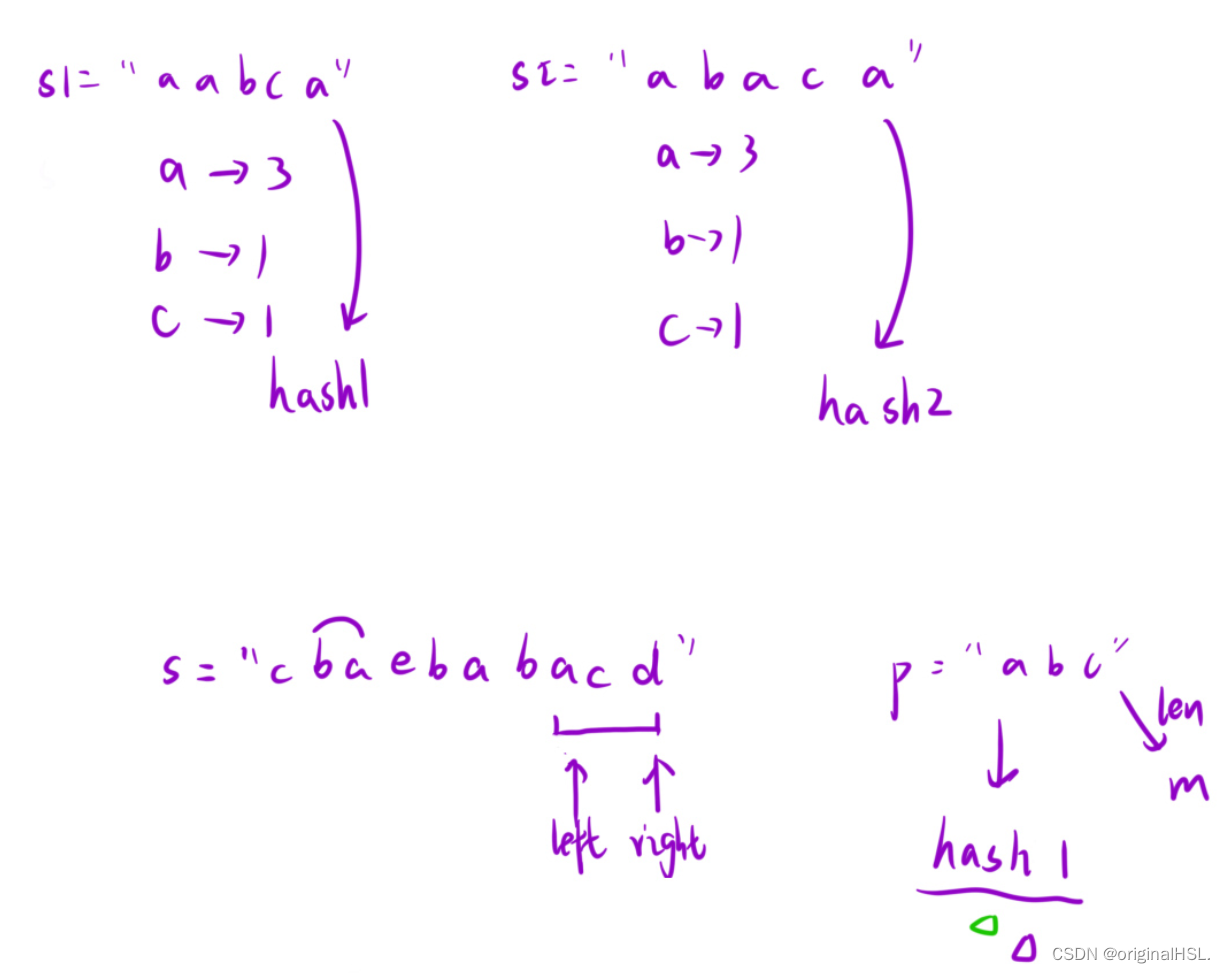

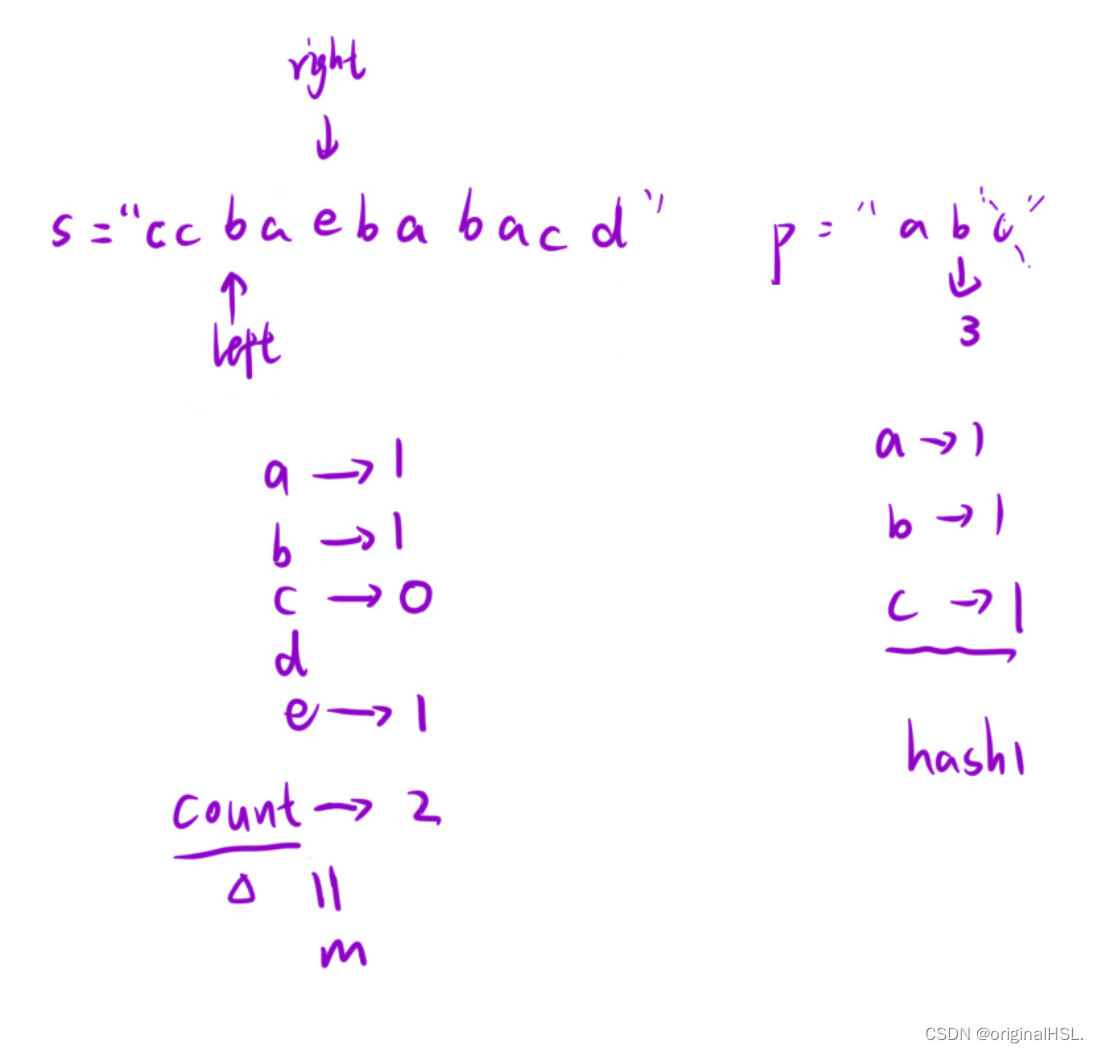
算法的基本思想是使用滑动窗口来遍历字符串s,并利用两个哈希表(hash1和hash2)来统计窗口中字符的频次。
具体的算法步骤如下:
-
初始化两个长度为26的数组hash1和hash2,用于记录字符串的字符频次。初始时,数组中所有元素都为0。
-
遍历字符串p,将其中的字符映射到hash2数组中,并增加相应字符的频次。
-
定义两个指针left和right,初始时都指向字符串s的第一个字符。
-
进入循环,循环条件为right指针小于字符串s的长度。
-
在循环中,首先将当前right指针指向的字符加入窗口,即将hash1数组中对应字符的频次加1。
-
检查加入窗口的字符是否是有效字符,即其频次小于等于hash2数组中对应字符的频次。如果是有效字符,则将计数器count加1。
-
检查窗口大小是否超过了字符串p的长度,即right-left+1是否大于len2。如果超过了窗口大小,则需要移动窗口。
-
移动窗口的过程包括以下几个步骤:
- 检查窗口左侧字符是否是有效字符,即其频次小于等于hash2数组中对应字符的频次。如果是有效字符,则将计数器count减1。
- 将窗口左侧字符从窗口中移除,即将hash1数组中对应字符的频次减1。
- 将左指针left向右移动一位。
-
检查计数器count是否等于字符串p的长度len2。如果相等,则表示当前窗口是一个字母异位词,将左指针left的位置加入结果集ret。
-
将右指针right向右移动一位,继续循环。
-
-
循环结束后,返回结果集ret,其中包含了所有字母异位词的起始位置。
3. 编写代码
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int hash1[26]={0},hash2[26]={0};
int left=0,right=0,len2=p.size(),len1=s.size();
vector<int> ret;
for(auto ch:p)hash2[ch-'a']++;
int count=0;
//利用变量count来统计窗口中“有效字符”的个数
while(right<len1)
{
hash1[s[right]-'a']++;//进窗口
if(hash1[s[right]-'a']<=hash2[s[right]-'a'])
{
count++;
}
if(right-left+1>len2)
{
if(hash1[s[left]-'a']<=hash2[s[left]-'a'])
{
count--;
}
hash1[s[left]-'a']--;
left++;
}
if(count==len2)
ret.push_back(left);
right++;
}
return ret;
}
};