背景:
大模型出来后语音助手借着LLM的语义理解、知识组织能力的提升,升级了一波buffer。然后在使用这些语音助手的时候总觉得缺了点什么,但也讲不出来具体缺了什么。这几天的思考突然有了灵感,其实缺的就是自己的知识内容如何变成语音助手的管理对象,也就是说现在语音助手只是一个内容门户,并且还只服务于已经有的出名的内容APP商。对于用户自己的私域的数据和信息它是不管的,并且这些语音助手其实和内容是很松的耦合关系,这就会带来些问题对内容的理解不够深入,明明图书馆里有很多知识可是就是找产出不了好的科研论文。
找到了这个问题,决定自己做一个属于自己的语音知识管理助手。目标当然是星辰大海要把所有自己私域的知识:娱乐的、学习的、工作的、家庭的、历史事件全部给管理起来,语音作为知识沟通的手段;后面可以的话可以把社交融合进来,这个社交只是亲密关系的lbs粒度的社交属性和soul这种语音社交不同,比如可以做到组会任务的语音安排布置、每天组会成员语音学习论文....
当然虽然牛皮是星辰大海,但是开始的时候还是选了一个具体的落地场景来实现——论文阅读。论文作为科研工作者、技术公司员工每日阅读的必需品;然而现在的论文大部分其实都是英文写的、并且论文数量大、字数多。如果有个产品可以把论文翻译成中文,并且可以阅读出来、可以根据语音提问的方式来回答论文到底写了什么、文章亮点是什么,那是不是一个不错的事情。所以我要做的这件产品第一阶段也就是这么个东西了:
1.选出精品论文——暂时不做,可以通过关注的微信公众号实现论文筛选工作
2.把论文翻译成中文
3.对论文做结构化的解析,整理成知识
4.通过语音方式实现对论文问答
5.把答案通过语音回复
产品技术架构:

翻译模块
这部分实现思路很简单也很粗暴,但是效果还是有保障的。直接用LLM来实现英文到中文的翻译,LLM模型在翻译的表现还是稳定的,所以这部分直接这么用是没问题的。这部分要注意的点有3个:
1.给LLM模型输入的长度需要注意,不要太长了;这部分有几种解决思路:
1.1用可以使用更长token输入的服务,比如llama 32k、chatgpt 16k...或者用最近新出的技术longlora、streamllm来对现有模型改造
1.2 把长的输入文本做改造,切短了,然后输入LLM模型,这么做会增加请求时长以及加重中间结果处理复杂度
2.pdf的论文输入需要做数据预处理,这部分没什么技术含量,但是非常的影响产品使用体感
3.服务稳定性要做保障,对于异常处理要考虑到能用、不漏翻译、如果有漏任务要注意做好问题可快速追溯
下面代码是我给的一个poc的例子,要做到好用产品需要的开发和更细致的思考。
#用langchain接口来读取pdf论文
from langchain.document_loaders import PyPDFium2Loader
loader = PyPDFium2Loader("/root/autodl-tmp/quantum_algorithms.pdf")
data = loader.load()
# -*- coding: utf-8 -*-
import os
import logging
# 指定文件夹路径
folder_path = " article_en"
# 检查文件夹是否存在,如果不存在则创建
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 指定文件夹路径
folder_path_ch = " article_ch"
# 检查文件夹是否存在,如果不存在则创建
if not os.path.exists(folder_path_ch):
os.makedirs(folder_path_ch)
# 设置日志记录
logging.basicConfig(filename='retry.log', level=logging.ERROR)
def translate_article(folder_path,folder_path_ch,content):
# 在新建的文件夹中创建文件并写入英文数据
file_path = os.path.join(folder_path, "example_"+str(i)+".txt")
# 判断文件是否存在
if os.path.exists(file_path):
# 如果文件存在,删除文件
os.remove(file_path)
print(f"文件 {file_path} 存在并已删除。")
# 打开文件并写入英文数据
with open(file_path, "w") as file:
file.write(content.page_content)
# 关闭文件
file.close()
# 在新建的文件夹中创建文件并写入中文数据
file_path_ch = os.path.join(folder_path_ch, "example_"+str(i)+".txt")
# 判断文件是否存在
if os.path.exists(file_path_ch):
# 如果文件存在,删除文件
os.remove(file_path_ch)
print(f"文件 {file_path_ch} 存在并已删除。")
#请求openapi把英文翻译成中文
try:
import openai
openai.api_base = ''
openai.api_key = ''
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=[
{"role": "system", "content": "你是一个专业翻译机器人,可以把论文翻译的准确表述流畅,严格执行人类指令"},
{"role": "user", "content": content.page_content+"\n把上面论文片段翻译成中文"},
])
# 打开文件并写入中文数据
with open(file_path_ch, "w") as file:
file.write(response["choices"][0]["message"]["content"])
except Exception as e:
pass
# 关闭文件
file.close()
for i in range(len(data)):
# 最大重试次数
max_retries = 3
retry_count = 0
while retry_count < max_retries:
try:
#print(data[i])
translate_article(folder_path,folder_path_ch,data[i])
# 如果操作成功,退出循环
break
except Exception as e:
# 操作失败,记录异常到日志
logging.error(f"操作失败: {e}")
# 增加重试次数
retry_count += 1
if retry_count < max_retries:
print(f"操作失败,重试中 ({retry_count}/{max_retries})...")
print(data[i])
# 等待一段时间后重试
#time.sleep(1)
else:
# 达到最大重试次数,抛出异常
raise
# 提示操作完成
print("文件夹和文件创建完成。")附注:openapi的接口可以在OpenAI兼容接口 | CloseAI到这个链接注册申请,付费使用;国内也可以使用,不需要翻。
或者还可以通过fastapi方式来部署自己的符合openai接口的LLM服务,这样可以完全省去接口调用费用,当然为了保证速度你需要有一台自己的相对高性能的GPU。
'''
以qwen为例讲解如何部署自己服务,和如果请求服务
#下载qwen项目代码
git clone
#安装用到的三方包
pip install fastapi uvicorn openai "pydantic>=2.3.0" sse_starlette
#起服务https://github.com/QwenLM/Qwen.git
python openai_api.py
'''
#客户端请求代码如下
import openai
openai.api_base = "http://localhost:8000/v1"
openai.api_key = "none"
# 使用流式回复的请求
for chunk in openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "system", "content": "你是一个专业翻译机器人,可以把论文翻译的准确表述流畅,严格执行人类指令"},
{"role": "user", "content": data[0].page_content+"\n把上面论文片段翻译成中文"},
],
stream=True
# 流式输出的自定义stopwords功能尚未支持,正在开发中
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
# 不使用流式回复的请求
response = openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "system", "content": "你是一个专业翻译机器人,可以把论文翻译的准确表述流畅,严格执行人类指令"},
{"role": "user", "content": data[1].page_content+"\n把上面论文片段翻译成中文"},
],
stream=False,
stop=[] # 在此处添加自定义的stop words 例如ReAct prompting时需要增加: stop=["Observation:"]。
)
print(response.choices[0].message.content)底下图展示的是LLM翻译的效果

image.png
语音识别模块
这部分其实也很简单,直接找现成的ASR模型来做就好了。在这个项目中我们用的是"openai/whisper-large-v2"这个语音ASR大模型来实现用户语音转文本的功能。其实出来把语音翻译成文本,然后在用LLM模型来实现基于知识的问答外,还有一种思路:直接用语音embedding来做多模态的音-文回答,llasm就是这样思路。
底下是openai/whisper-large-v2应用实现代码,只是实现了wav文件输入、实时语音输入转文本的能力。还没有把转化的文本变成用户问题给LLM模型基于用户问题、pdf翻译文档做问题回复,这部分会在下一篇文章介绍。
import torch
import gradio as gr
import yt_dlp as youtube_dl
from transformers import pipeline
from transformers.pipelines.audio_utils import ffmpeg_read
import tempfile
import os
MODEL_NAME = "openai/whisper-large-v2"
BATCH_SIZE = 8
FILE_LIMIT_MB = 1000
YT_LENGTH_LIMIT_S = 3600 # limit to 1 hour YouTube files
device = 0 if torch.cuda.is_available() else "cpu"
pipe = pipeline(
task="automatic-speech-recognition",
model=MODEL_NAME,
chunk_length_s=30,
device=device,
)
def transcribe(inputs, task):
if inputs is None:
raise gr.Error("No audio file submitted! Please upload or record an audio file before submitting your request.")
text = pipe(inputs, batch_size=BATCH_SIZE, generate_kwargs={"task": task}, return_timestamps=True)["text"]
return text
def _return_yt_html_embed(yt_url):
video_id = yt_url.split("?v=")[-1]
HTML_str = (
f'<center> <iframe width="500" height="320" src="https://www.youtube.com/embed/{video_id}"> </iframe>'
" </center>"
)
return HTML_str
def download_yt_audio(yt_url, filename):
info_loader = youtube_dl.YoutubeDL()
try:
info = info_loader.extract_info(yt_url, download=False)
except youtube_dl.utils.DownloadError as err:
raise gr.Error(str(err))
file_length = info["duration_string"]
file_h_m_s = file_length.split(":")
file_h_m_s = [int(sub_length) for sub_length in file_h_m_s]
if len(file_h_m_s) == 1:
file_h_m_s.insert(0, 0)
if len(file_h_m_s) == 2:
file_h_m_s.insert(0, 0)
file_length_s = file_h_m_s[0] * 3600 + file_h_m_s[1] * 60 + file_h_m_s[2]
if file_length_s > YT_LENGTH_LIMIT_S:
yt_length_limit_hms = time.strftime("%HH:%MM:%SS", time.gmtime(YT_LENGTH_LIMIT_S))
file_length_hms = time.strftime("%HH:%MM:%SS", time.gmtime(file_length_s))
raise gr.Error(f"Maximum YouTube length is {yt_length_limit_hms}, got {file_length_hms} YouTube video.")
ydl_opts = {"outtmpl": filename, "format": "worstvideo[ext=mp4]+bestaudio[ext=m4a]/best[ext=mp4]/best"}
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
try:
ydl.download([yt_url])
except youtube_dl.utils.ExtractorError as err:
raise gr.Error(str(err))
def yt_transcribe(yt_url, task, max_filesize=75.0):
html_embed_str = _return_yt_html_embed(yt_url)
with tempfile.TemporaryDirectory() as tmpdirname:
filepath = os.path.join(tmpdirname, "video.mp4")
download_yt_audio(yt_url, filepath)
with open(filepath, "rb") as f:
inputs = f.read()
inputs = ffmpeg_read(inputs, pipe.feature_extractor.sampling_rate)
inputs = {"array": inputs, "sampling_rate": pipe.feature_extractor.sampling_rate}
text = pipe(inputs, batch_size=BATCH_SIZE, generate_kwargs={"task": task}, return_timestamps=True)["text"]
return html_embed_str, text
demo = gr.Blocks()
mf_transcribe = gr.Interface(
fn=transcribe,
inputs=[
gr.inputs.Audio(source="microphone", type="filepath", optional=True),
gr.inputs.Radio(["transcribe", "translate"], label="Task", default="transcribe"),
],
outputs="text",
layout="horizontal",
theme="huggingface",
title="Whisper Large V2: Transcribe Audio",
description=(
"Transcribe long-form microphone or audio inputs with the click of a button! Demo uses the"
f" checkpoint [{MODEL_NAME}](https://huggingface.co/{MODEL_NAME}) and Transformers to transcribe audio files"
" of arbitrary length."
),
allow_flagging="never",
)
file_transcribe = gr.Interface(
fn=transcribe,
inputs=[
gr.inputs.Audio(source="upload", type="filepath", optional=True, label="Audio file"),
gr.inputs.Radio(["transcribe", "translate"], label="Task", default="transcribe"),
],
outputs="text",
layout="horizontal",
theme="huggingface",
title="Whisper Large V2: Transcribe Audio",
description=(
"Transcribe long-form microphone or audio inputs with the click of a button! Demo uses the"
f" checkpoint [{MODEL_NAME}](https://huggingface.co/{MODEL_NAME}) and Transformers to transcribe audio files"
" of arbitrary length."
),
allow_flagging="never",
)
yt_transcribe = gr.Interface(
fn=yt_transcribe,
inputs=[
gr.inputs.Textbox(lines=1, placeholder="Paste the URL to a YouTube video here", label="YouTube URL"),
gr.inputs.Radio(["transcribe", "translate"], label="Task", default="transcribe")
],
outputs=["html", "text"],
layout="horizontal",
theme="huggingface",
title="Whisper Large V2: Transcribe YouTube",
description=(
"Transcribe long-form YouTube videos with the click of a button! Demo uses the checkpoint"
f" [{MODEL_NAME}](https://huggingface.co/{MODEL_NAME}) and Transformers to transcribe video files of"
" arbitrary length."
),
allow_flagging="never",
)
with demo:
gr.TabbedInterface([mf_transcribe, file_transcribe, yt_transcribe], ["Microphone", "Audio file", "YouTube"])
demo.launch(enable_queue=True)代码运行效果如下,你会得到一个语音输入的界面;右侧output部分就是输出的文本。现在还只能做到单语种效果较好,后面会允许语音问题里面中英文混杂提问。

image.png
TTS回复模块
把文本装成语音输出,这个项目用的是最近新出的大模型bark。可以支持多种语言,多人声可选择。这个模型对后续做扩展做人声克隆支持力度也是非常好,只要改很少几行代码就可以支持。这个阶段先选择现成的人声来做语音合成,后面如果需要更个性化和更精细化的产品开发,可以基于模型做更细致的开发。
和语音识别一样,这篇文章只给出了我的技术选型和简单的实现。还没有把这些技术整合到项目中。下篇文章会把这部分代码整合到项目中。
from transformers import AutoProcessor, AutoModel
processor = AutoProcessor.from_pretrained("suno/bark",cache_dir="./")
model = AutoModel.from_pretrained("suno/bark",cache_dir="./")
inputs = processor(
text=["Hello, my name is Suno. And, uh — and I like pizza. [laughs] 你是谁,上帝嘛。还是海的女儿."],
return_tensors="pt",
)
speech_values = model.generate(**inputs, do_sample=True)
#在jupyter notebook中直接交互
from IPython.display import Audio
sampling_rate = model.generation_config.sample_rate
Audio(speech_values.cpu().numpy().squeeze(), rate=sampling_rate)后续产品会开一个tab来做语音播放,大致效果如下:

image.png
基于知识问答
一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
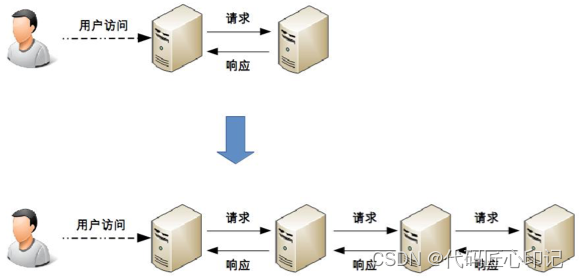
实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。

image.png
这部分实现的功能就是把翻译好的论文通过向量知识库的方式存储到向量知识库。然后通过知识库中知识作为上下文来回答问题。其实这和真正的文档问答还是有些许的区别,也就是说后续如果要文档问答效果好还是要对这个项目做些扩展和改造。这个问题在哪呢,基于向量检索的方式把和问题相似的内容召回,然后作为上下文回答问题。这个前提假设是问题中必须出现和文章里面相关的信息才能检索到信息作为上下文;且还有一个隐性假设是这个答案只是和相关信息的附近信息相关有很强近场效应。
然而对于全局性问题前面的两个假设是不成立的。比如“这篇文章主题是什么”、“这篇文章介绍了什么技术点”、“这篇文章结构是怎么样”......对于这些全局性问题向量检索召回上下文就不能很好回答问题,必须要对全文信息有通篇阅读才能很好回答。要对通篇文章阅读就需要很长的输入token或者有很强的层级化的总结整理知识能力。这些都需要较费时间的prompt工程、系统话产品工程支持。
参考项目代码:GitHub - chatchat-space/Langchain-Chatchat: Langchain-Chatchat(原Langchain-ChatGLM)基于 Langchain 与 ChatGLM 等语言模型的本地知识库问答 | Langchain-Chatchat (formerly langchain-ChatGLM), local knowledge based LLM (like ChatGLM) QA app with langchain
modelscope/examples/pytorch/application/qwen_doc_search_QA_based_on_langchain.ipynb at master · modelscope/modelscope
知识抽取模块
这块其实是包括两个层次,所谓的知识抽取就是说:
1.提前把论文中常要了解的问题汇总,把畏难而退结果整理成简要方式给到用户;比如论文主题是什么、论文研究了什么问题、论文提出了什么新想法、论文解决思路是什么、论文做了什么实验研究、论文的实验结果是什么
2.对论文做知识抽取,把关键词、相关信息整理成图谱形式,在后续用户提问的时候可以做语义补充、可以把用户畏难而退没有相关信息召回不到信息,通过图谱关键信息方式提前召回,保证基于知识问答的准确性
对于第1个问题其实就是提前把通用的问题整理成prompt模版,这部分就是所谓prompt工程的事。对于第2个问题设计到信息解析、知识图谱抽取构建的事,当然我们不会做的那么重,只是会简单的基于LLM的方式来阅读全文给出较简单概要性的知识图谱。第一个问题相对零散这篇文章不会做过多介绍,下面部分主要会介绍如何基于LLM模型来抽取知识图谱。
具体模型结构如下,本部分选择智析、GollIE大模型抽取知识

image.png
产品对话运行效果示意图

image.png
GitHub - zjunlp/KnowLM: An Open-sourced Knowledgable Large Language Model Framework.
https://github.com/hitz-zentroa/GoLLIE/blob/main/notebooks/Relation%20Extraction.ipynb
小结:
本文介绍了做一个属于自己的语音知识管理助手的想法,并选择了论文阅读作为落地场景。计划通过选出精品论文、将论文翻译成中文、对论文进行结构化解析、通过语音方式实现对论文问答、将答案通过语音回复等步骤来实现这个产品。在实现过程中,提到了需要注意的问题,包括输入文本长度、pdf论文输入的数据预处理、服务稳定性等。
文章把开发论文语音助手腰用到的技术做了简单介绍,并基于过往经验给出了美国模块的实现技术选型。给出了初步的产品技术框架,在下一篇文章会介绍更详细的技术细节,后续会把项目代码汇总到:https://github.com/liangwq/Chatglm_lora_multi-gpu
1.翻译模块:pdf数据处理+LLM翻译
2.语音识别:openai/whisper-large-v2
3.TTS回复:bark后续会做语音clone
4.基于知识问答:langchain-向量库-大模型上下文问题回答改造
5.知识抽取:基于LLM模型的知识抽取模块,智析、GollIE