前言
我司第二项目组一直在迭代论文审稿GPT(对应的第二项目组成员除我之外,包括:阿荀、阿李、鸿飞、文弱等人),比如
- 七月论文审稿GPT第1版:通过3万多篇paper和10多万的review数据微调RWKV
- 七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2 7B最终反超GPT4
- 七月论文审稿GPT第2.5和第3版:分别微调GPT3.5、Llama2 13B以扩大对GPT4的优势
所以每个星期都在关注各大公司和科研机构推出的最新技术、最新模型
而Google作为曾经的AI老大,我司自然紧密关注,所以当Google总算开源了一个gemma 7b,作为有技术追求、技术信仰的我司,那必须得支持一下,比如用我司的paper-review数据集微调试下,彰显一下gemma的价值与威力
此外,去年Mistral instruct 0.1因为各种原因导致没跑成功时(详见此文的4.2.2节直接通过llama factory微调Mistral-instruct),我总感觉Mistral应该没那么拉胯,总感觉得多实验几次,所以打算再次尝试下Mistral instruct 0.2
最后,本文只展示部分细节,更多细节则见七月的《大模型商用项目审稿GPT微调实战》——七月论文审稿GPT:微调llama2/mistral/gemma/mixtral 8×7B,历经9个月,连续迭代9个版本,以不断超越GPT4,但如下图所示,过程中也走了不少弯路

第一部分 论文审稿GPT第3.2版:微调Mistral 7B instruct 0.2
1.1 通过5000多条paper-review微调Mistral-7b-Instruct-v0.2
关于Mistral 7B的介绍,请看此文《从Mistral 7B到MoE模型Mixtral 8x7B的全面解析:从原理分析到代码解读》的1.1节Mistral 7B:通过分组查询注意力 + 滑动窗口注意力超越13B模型
1.1.1 Mistral 7B-Instruct:微调时其长度扩展的能力从何而来
由于Mistral 7B-Instruct和Mistral 7B一样,其长下文长度都只有8096,而论文审稿GPT这个项目对模型上下文的长度要求12K以上,故需要扩展Mistral 7B-Instruct的上下文长度,如何扩展呢
考虑到如此文《七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2 7B最终反超GPT4》4.1节所介绍的
- Yarn-Mistral-7b-64k自己实现了modeling,即把mistral的sliding windows attention改了,相当于把sliding windows的范围从滑窗大小直接调到了65536即64K(即直接滑65536那么个范围的滑窗,其实就是全局)
那类似的,给Mistral 7B–Instruct加YaRN行不行?
然问题是不好实现:YaRN-Mistral 7B – Instruct,因为Yarn是全量训的方案,而大滑窗范围+全量很吃资源- 受LongLora LLaMA的启发,既然没法给Mistral 7B–Instruct加YaRN,那可以给其加longlora么?
然问题是mistral又没法享有longlora,因为mistral的sliding windows attention和longlora的shift short attention无法同时兼容,但要对原chat模型的上下文长度进行有效扩展又会需要shift short attention
不得已,故再考察下它所用的RoPE,毕竟RoPE可以使得模型的上下文长度直接外推10-20%
然,在我们后续实际微调Mistral 7B-Instruct 0.2时,实际支持其获得更长上下文能力的还是归结于其滑动窗口注意力(sliding window attention,简称SWA),毕竟SWA可以有效处理任意长度的序列
- 怎么发现的呢?如下图所示的“大海捞针”实验,纵轴是对应语句放在文章中的位置(从头到尾),如果是外推的话 不会有图中那个斜杠(因为外推的话无论输入多长的序列,它的ppl都是稳定的,即右上角应该是绿色才对),故从图中可以很明显的看出来Mistral的window size就是4k(每次只计算4k范围内的注意力)
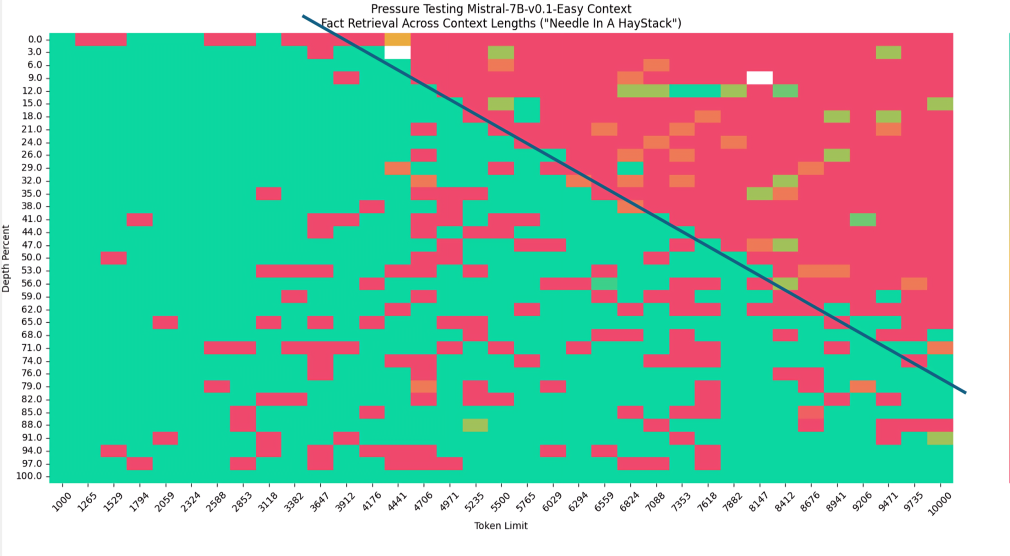
- 总之,对于Mistral或gemma如果通过rope去外推,算是没有办法的办法,但Mistral有滑动窗口注意力的话,反正无论输入长度多长,它每一个token只计算在它之前(含它自己)的4096个token的注意力,相当灵活,故自然也就轮不到用rope去外推了
1.1.2 llama factory微调Mistral-7b-Instruct-v0.2的具体步骤
本次Mistral-7b-Instruct-v0.2的微调主要由我司第二项目组的鸿飞负责
把训练数据,格式是:
{"input":"论文内容", "output": "review data"}}的数据,
按照LLama-Factory目录下面的dataset_info_zh.md中的步骤,把数据整理成为羊驼alpaca的格式以后
- 一开始--per_device_train_batch_size 1设置为1,启动程序,还会发生内存不足的问题
经过检查以后,发现是论文长度比较长,又把论文和review数据截断为12288的数据长度,再放到data目录下面,per_device_train_batch_size设置为3,正常运行,但是内存已经到了47G了,但是早上发现在运行到了晚上4点,程序因为内存不足而退出了 - 断点续跑:
重新启动程序,设置--resume_from_checkpoint checkpoint-660,修改运行的batch_size为2,重新把程序从上次退出的地方跑起来。发现内存占用为33G/48G。剩余时间大约12个小时跑完
以下是训练过程中的其他细节
- 模型超时解决:--ddp_timeout 180000000
- 长度外推方式
目前只支持Linear和dynamic NTK
为了加快训练速度,使用deepspeed s2 + 4bit+NF 量化 - 使用了flash-attn:不过训练速度没有明显地提升
- 租的机器的cuda版本是11.8,安装了最新的torch,发现和cuda不匹配,更新cuda的话太麻烦,所以按照llama factory开发者的建议:
pip uninstall torch torchvision torchaudio
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 - LLamaFactory推荐deepspeed==0.13.5
但运行以后,json.dumps表示不能保存这种数据,怎么办?
最后通过安装 deepspeed==0.13.1 解决{ 'loss': 1.9611, 'grad_norm': tensor(4.6666), 'learning_rate': 2.5e-05, 'epoch': 0.0 },
如鸿飞如说
- 运行程序的时候,尽量留够一定的内存空间,否则会出现中途退出的问题
- 对于一些特定的错误,不会解决的时候,最好找LLama-Factory的开发者去解决,否则自己很难定位出错误的位置。trick: LLama-Factory上面的多加几个群,这样子可以多学习官方人员的解决思路
- 机器cuda与python的版本号最好是一致的。
- 量化后的模型与主模型不能合并。量化模型不能合并
更多见七月的《大模型商用项目审稿GPT微调实战》
1.2 对「Mistral-7b-Instruct-v0.2微调版本」的评估
// 待更
第二部分 论文审稿GPT第3.5版:微调Google gemma
2.1 Google推出gemma,试图与llama、Mistral形成三足鼎立之势
Google在聊天机器人这个赛道上,可谓被双向夹击
- 闭源上被OpenAI的ChatGPT持续打压一年多(尽管OpenAI用的很多技术比如transformer、CoT都是Google发明的,尽管Google推出了强大的Gemini)
- 开源上则前有Meta的llama,后有Mistral的来势汹汹
终于在24年2.21,按耐不住推出了开源模型gemma(有2B、7B两个版本,这是其技术报告,这是其解读之一),试图对抗与llama、Mistral在开源场景上形成三足鼎立之势

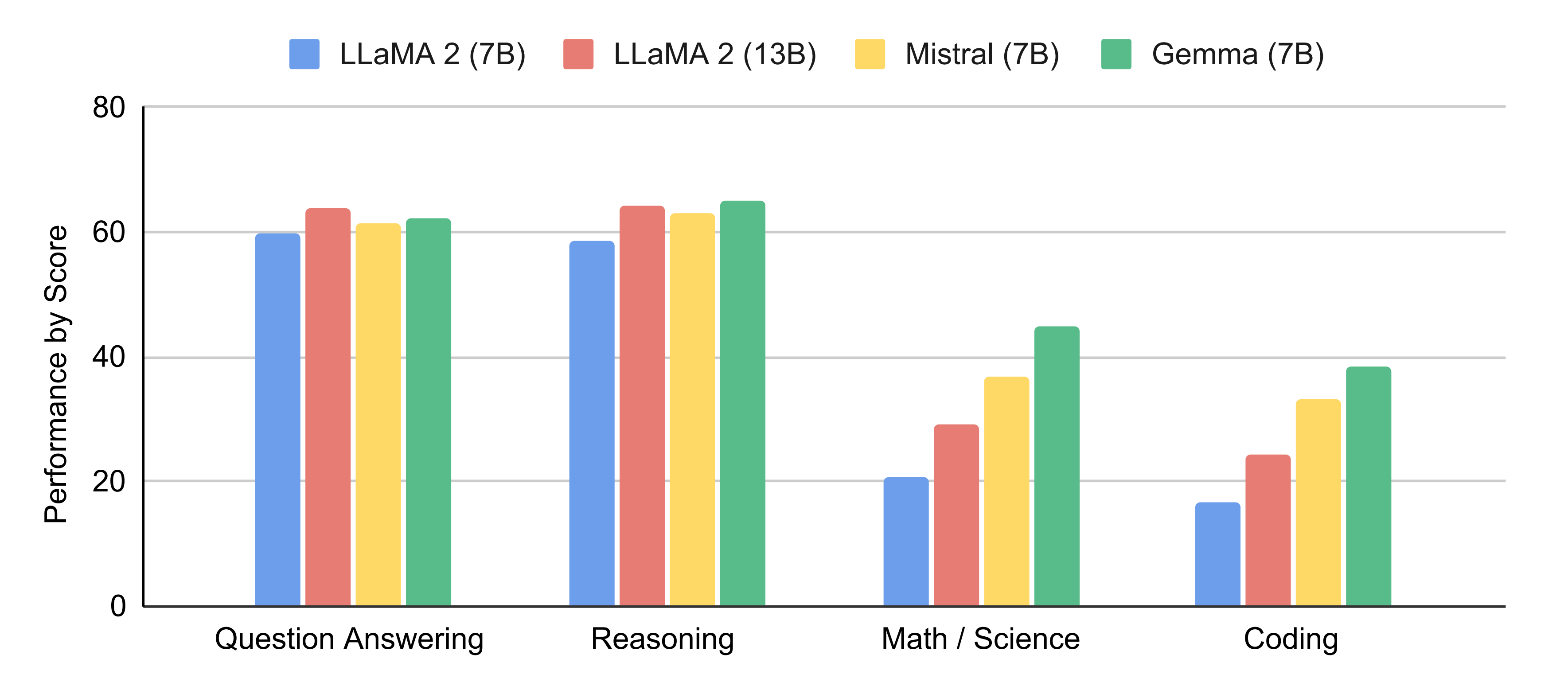
2.1.1 gemma 7B的性能:比肩Mistral 7B、超越llama 7B
Gemma 7B在 18 个基于文本的任务中的 11 个上优于相似参数规模的开放模型,例如除了问答上稍逊于llama 13B,其他诸如常识推理、数学和科学、编码等任务上的表现均超过了llama2 7B/13B(关于llama2的介绍请看此文的第三部分)、Mistral 7B
2.1.2 模型架构:基于transformer解码器、多头/多查询注意力、RoPE、GeGLU
Gemma 模型架构基于 Transformer 解码器
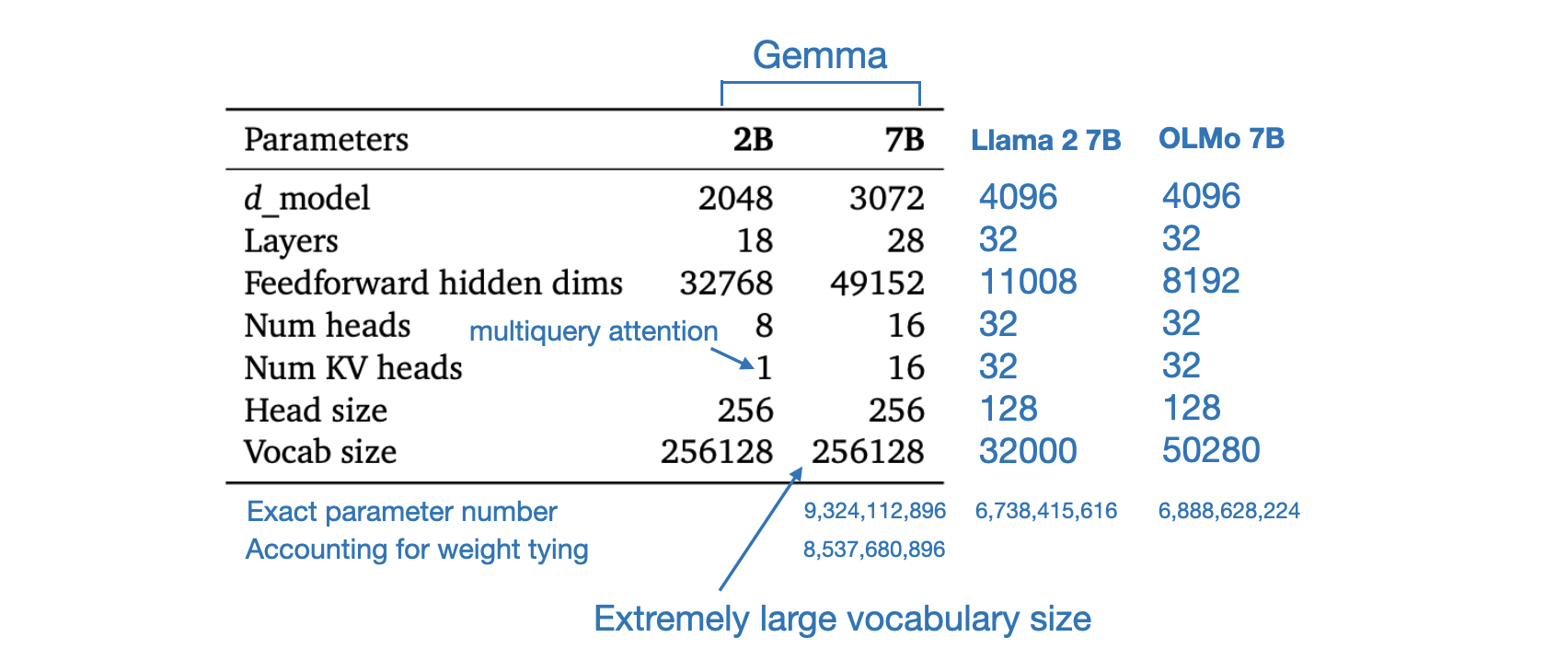
- 模型训练的上下文长度为 8192 个 token
- 其词表则比llama2 所用的32K大太多了,为 256k个token(导致我们微调gemma 7b时,在论文审稿所需要的理想长度12K之下且在已经用了qlora和flash attention的前提之下,48g显存都不够,详见下文)
- 至于训练数据集达到6万亿个token(即We trained Gemma models on up to 6T tokens of text,而llama2的训练集只有2万亿个token)
此外,gemma还在原始 transformer 论文的基础上进行了改进,改进的部分包括:
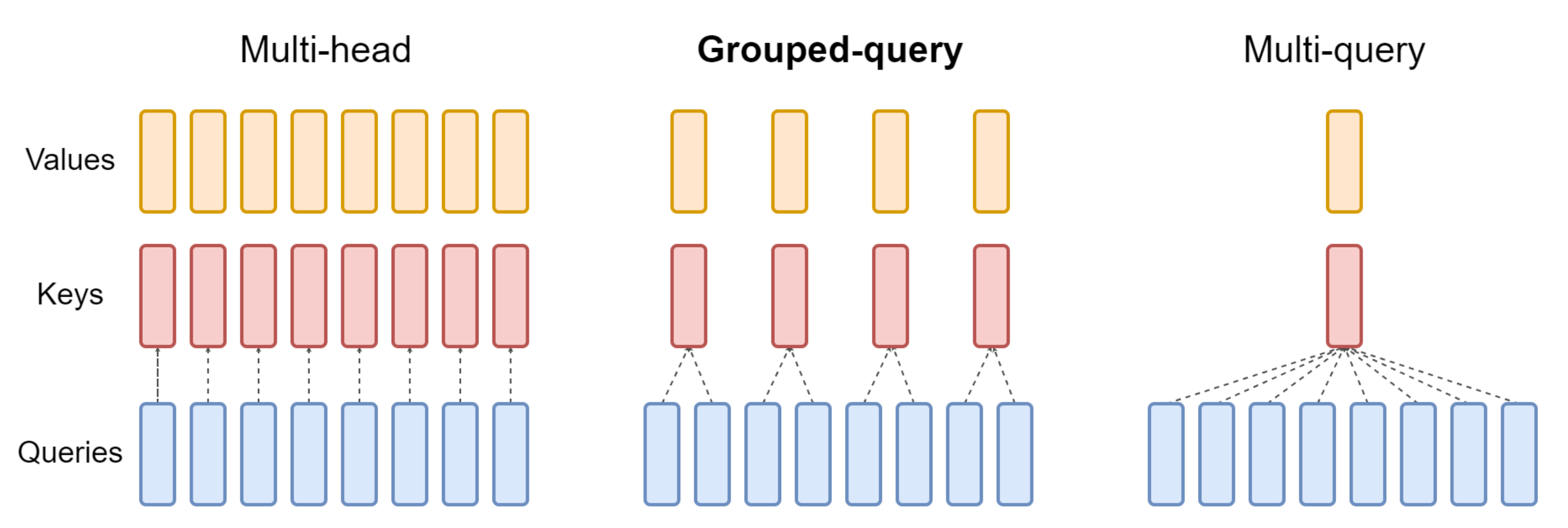
- 多查询注意力:7B 模型使用多头注意力(即MHA,如下图左侧所示),而 2B 检查点使用多查询注意力(即MQA,如下图右侧所示,𝑛𝑢𝑚_𝑘𝑣_ℎ𝑒𝑎𝑑𝑠 = 1,关于GQA的更多介绍,请参见《一文通透各种注意力:从多头注意力MHA到分组查询注意力GQA、多查询注意力MQA》)
- RoPE 嵌入:Gemma 在每一层中使用旋转位置嵌入,而不是使用绝对位置嵌入;此外,Gemma 还在输入和输出之间共享嵌入,以减少模型大小
- GeGLU 激活:GeGLU 激活函数(其对应的论文为Google发的这篇《GLU Variants Improve Transformer》),取代传统的 ReLU 非线性函数
GeGLU是GeLU(Gaussian Error Linear Unit) 的门线性单元变体,而GeLU与ReLU不允许负值不同,其允许为负输入值执行梯度传播
总之,GeGLU 的激活被分割为两部分,分别是 sigmoid 单元和线性映射单元(它与 sigmoid 单元的输出逐元素相乘),使得其与Llama 2和Mistral等用的SwiGLU极其类似(关于SwiGLU的细致介绍请看此文《LLaMA的解读与其微调:Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙/LLaMA 2》的1.2.3节:SwiGLU替代ReLU)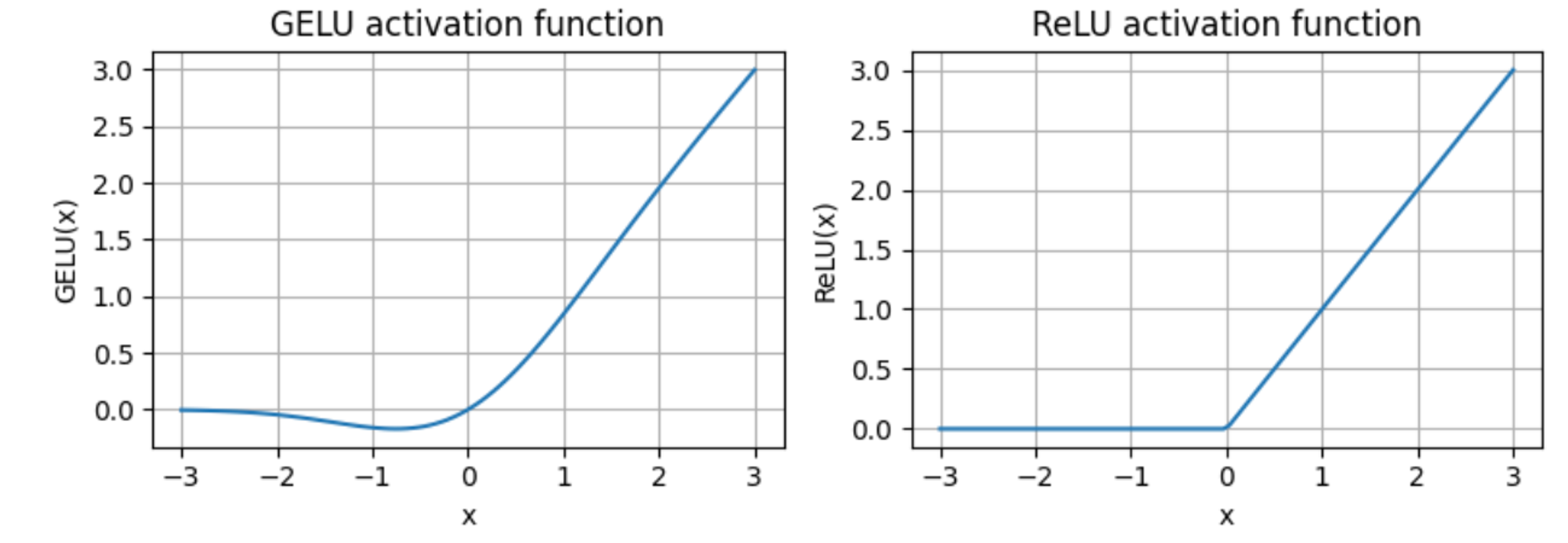
唯一的区别是 GeGLU 使用的基础激活函数是 GeLU 而不是 Swish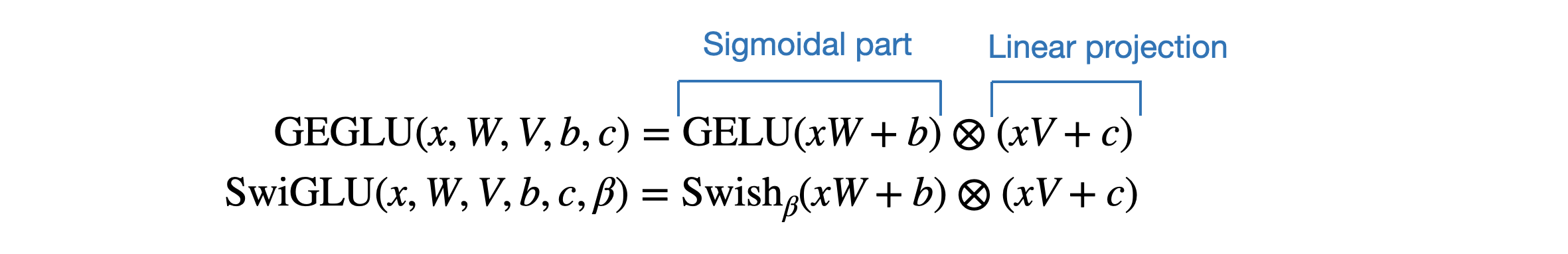
- 归一化:Gemma 对每个 transformer 子层的输入和输出进行归一化,这与仅对其中一个或另一个进行归一化的标准做法有所不同,另,gemma使用RMSNorm 作为归一化层
如国外一开发者Sebastian Raschka所说,“At first glance, it sounds like Gemma has an additional RMSNorm layer after each transformer block. However, looking at the official code implementation, it turns out that Gemma just uses the regular pre-normalization scheme that is used by other LLMs like GPT-2, Llama 2(Gemma 仅仅使用了 GPT-2、Llama 2 等其他 LLM 使用的常规预归一化方案), and so on, as illustrated below”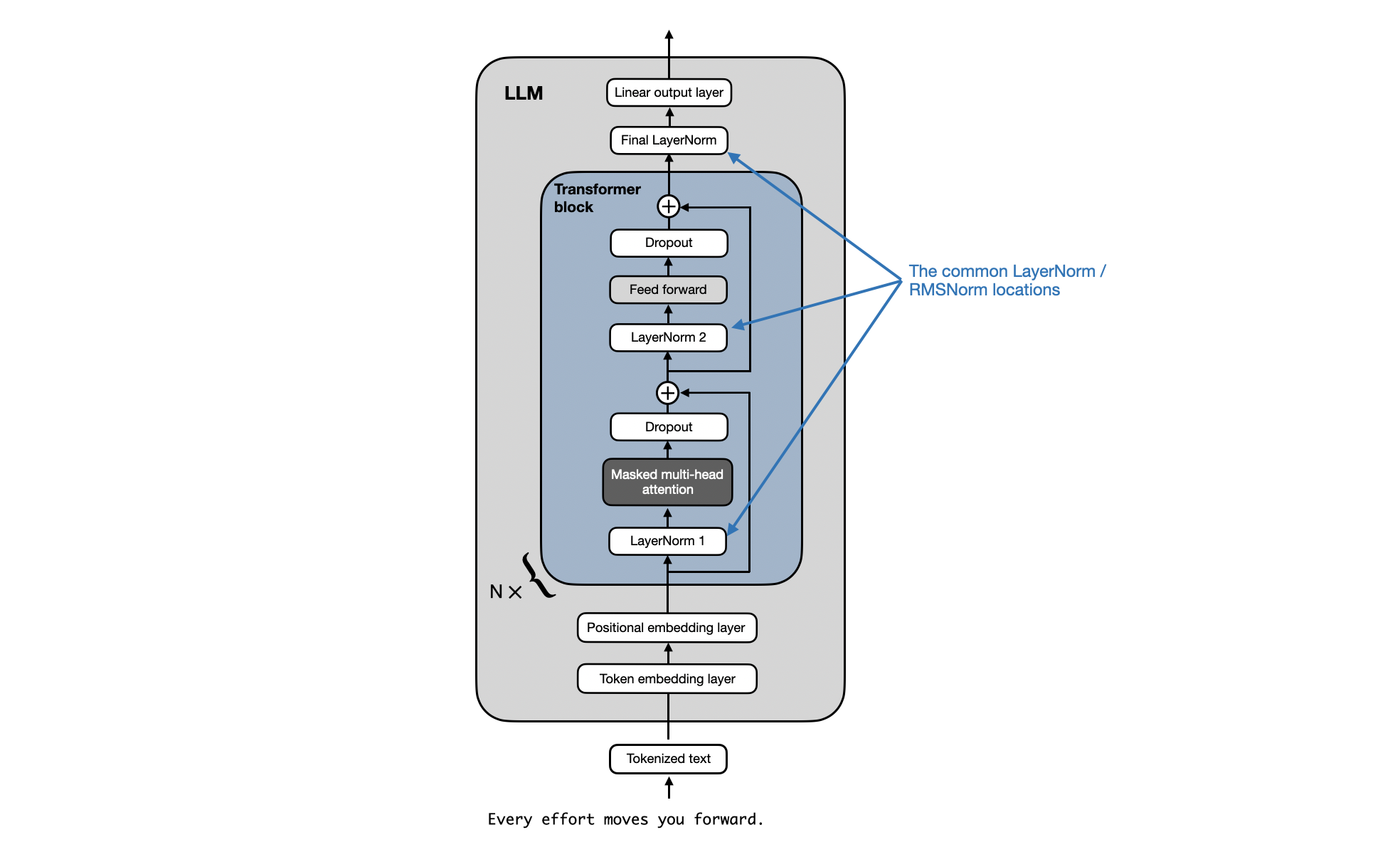
2.1.3 预训练、指令调优、RLHF、监督微调
对于 7B 模型,谷歌在 16 个pod(共计4096 个TPUv5e)上训练模型,他们通过 2 个pod对2B模型进行预训练,总计 512 TPUv5e
在一个 pod 中,谷歌对 7B 模型使用 16 路模型分片和 16 路数据复制,对于 2B 模型,只需使用 256 路数据复制
优化器状态使用类似 ZeRO-3 的技术进一步分片。在 pod 之外,谷歌使用了 Pathways 方法通过数据中心网络执行数据复制还原
- 预训练
Gemma 2B 和 7B 分别在来自网络文档、数学和代码的 2T 和 6T 主要英语数据上进行训练。与 Gemini 不同的是,这些模型不是多模态的,也不是为了在多语言任务中获得最先进的性能而训练的
为了兼容,谷歌使用了 Gemini 的 SentencePiece tokenizer 子集。它可以分割数字,不删除多余的空白,并对未知 token 进行字节级编码 - 指令调优与RLHF
谷歌通过在仅文本、仅英语合成和人类生成的 prompt 响应对的混合数据上进行监督微调即SFT,以及利用在仅英语标记的偏好数据和基于一系列高质量 prompt 的策略上训练的奖励模型进行人类反馈强化学习即RLHF,对 Gemma 2B 和 Gemma 7B 模型进行微调
具体而言gemma根据基于 LM 的并行评估结果来选择自己的混合数据,以进行监督微调。给定一组留出的(heldout) prompt, 让测试模型生成response,并让基线模型生成相同prompt下的response,然后让规模更大的高性能模型来预测哪个response更符合人类的偏好
2.2 gemma-7b-it模型微调
本次gemma 7B的微调由我司第二项目组的阿李负责
2.2.1 通过TRL包对gemma-7b-it进行微调的关键结论/细节与环境配置
以下是一些关键结论
- 使用TRL的SFT Trainer对gemma-7b-it进行微调(关于TRL包的介绍请看此文的第一部分)
- 其中模型的max_seq_length设置为1024*8,也就是没有外推,直接使用默认8K。
- 在train阶段没有对input进行截断,在inference有对input截断1024*7
以下是一些关键的微调细节
- 微调参考gemma官方在huggingface公布的微调样例代码:https://huggingface.co/google/gemma-7b/blob/main/examples/example_sft_qlora.py
本质是用trl的SFT Trainer和transformers的模型加载,写一个微调脚本 - 主要修改点是dataset的适配以及超参数
- 主要难点是解决python包的冲突(官网案例只有代码没有环境),以及预测时候的维度不一致的问题解决
- 另外网上还有一种方案:clone trl的github的框架代码,然后在这个项目框架里面写微调样例,这个方案在环境配置的时候总有包版本冲突,故该方案暂时搁置
以下是本次微调所涉及到的环境配置
conda create -n gemma python=3.9 pip
source activate
conda activate gemma
pip install torch==1.13.0+cu117 torchvision==0.14.0+cu117 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu117
pip install accelerate==0.27.2 trl==0.7.11 transformers==4.38.2 datasets==2.16.0 peft==0.9.02.2.2 微调代码修改
- 超参数
per_device_train_batch_size=1 per_device_eval_batch_size=1 gradient_accumulation_steps=16 learning_rate=2e-4 max_grad_norm=0.3 weight_decay=0.001 lora_alpha=16 lora_dropout=0.1 lora_r=64 max_seq_length=1024*8 dataset_name="./data/paper_review/paper_review_data_longqlora_15565.jsonl" fp16=False bf16=True packing=False gradient_checkpointing=True use_flash_attention_2=True optim="paged_adamw_32bit" lr_scheduler_type="constant" warmup_ratio=0.03 save_steps=10 save_total_limit=3 logging_steps=10 num_train_epochs=2 - 模型加载和量化以及lora配置,代码见七月的《大模型商用项目审稿GPT微调实战》
- 数据集加载格式定义以及prompt设置
def formatting_func(example): # text = f"### USER: {example['data'][0]}\n### ASSISTANT: {example['data'][1]}" text = """ Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: You are a professional machine learning conference reviewer who reviews a given paper and considers 4 criteria: ** importance and novelty **, ** potential reasons for acceptance **, ** potential reasons for rejection **, and ** suggestions for improvement **. The given paper is as follows. ### Input: {paper} ### Response: {review} """.format(example[0],example[1]) return text - 微调和保存,代码见七月的《大模型商用项目审稿GPT微调实战》
2.2.3 评估结果:审稿效果超越GPT4不少
最终的评估结果告诉我们,大家不要小看Google的gemma,在同样的论文审稿场景下、同样的数据集下,微调后取得了目前最好的效果
且略微超过之前微调llama2的结果(在GPT4-1106做裁判的情况下,之前微调过后的llama2 7B对GPT4-1106的胜率仅为63.16%,微调过后的llama2 13B对GPT4-1106胜率仅为75.44%)
所以,当微调后审稿效果超过GPT4 1106(裁判也使用的gpt-4-1106-preview),则很自然了




![[JavaWeb学习日记]Vue工程,springboot工程整合Mybatis,数据库索引](https://img-blog.csdnimg.cn/direct/686a7e5bfe6c4547ad1208b67d19fcf5.png)