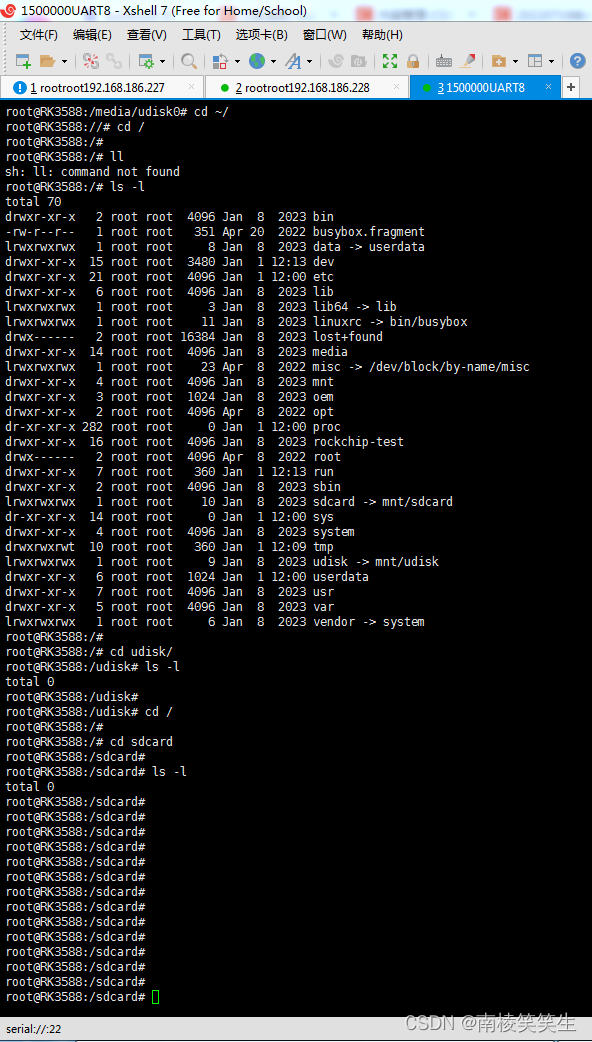
FLOPs :整个网络要计算多少个浮点运算
卷积层的浮点运算等价于
输入的高*输入的宽*通道数*输出通道数再乘以卷积核的高和宽再加上全连接的一层
我们发现训练的时候的精度是要比测试精度来的高的在一开始,这是因为训练的时候用了数据增强
使得训练误差相对比较大,而测试的时候并没有做数据增强,噪声比较低

箭头的含义是学习率的降低
如果跳太早 后期收敛会无力
晚一点跳比较好
而且 如果有了残差连接 收敛也会相应的快很多
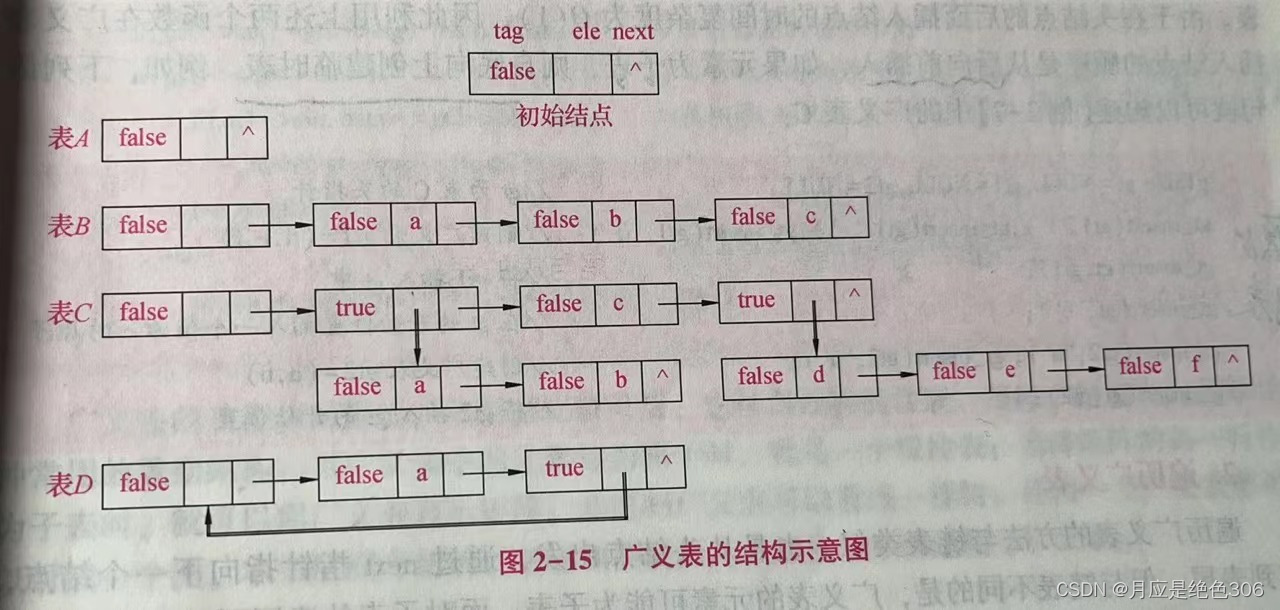
输入输出不一样的时候怎么办
之前 笔记不全
补充第三条
给所有的连接做投影(成本很高 不推荐)带来了 大量的计算复杂度
当设计 更深的网络的时候,会引入一个bottleneck的设计

通道数是64的时候进了3*3的
当channel是256的时候 当很深的时候 可以学到东西更多 对应的通道数也就越多
而随之就要面临计算复杂度变高
所以想用1*1的卷积给它reshape回64
在做3*3的通道数不变的卷积
再1*1卷积reshape回256 (先降维,再升维)
这样做 就和之前的复杂度差不多
总结一下 层数变多 直接通道数翻四倍+bottleneck的设计
正是有了残差连接residual connection 存在,当加入的层过多时,当结果趋向于理想了,此时往后加再多的层效果都是不尽人意——>0学不到什么东西了

一篇文章 不要放太多的数据

当我们的层数变多的时候
相当于嵌套函数 的求导 链式求导法则 就是一个连乘 那自然而然就会变小
而梯度是在0附近的高斯分布 自然得到的结果也会变较小
加了res结构之后(蓝色部分)
 前面的部分很容易导致梯度消失
前面的部分很容易导致梯度消失
但是这个蓝色的额外部分的浅层网络 会上为大一些 就可以训练的动了
这个是训练的收敛比较快的原因
sgd不叫收敛 叫做 训练不动了 嘿嘿 有点尴尬
SGD的精髓就是梯度够大 能一直跑下去
所以加了之后 梯度还是可以的 可以符合sgd 的精髓 能一直跑效果不错哦哦
现如今的transform 参数那么多 层数那么深
为什么不过拟合嘞 很有意思哈哈
表面上加了残差之后 结构复杂了
但从本质结构上看 模型的复杂度其实降低了的
模型复杂度降低: 你能找到一个很低的不那么复杂的模型去拟合你的数据
residual 在标号上做 ————叫什么 gradient boosting
而这里 residual是在feature 维度上做




![[教程]一文搞懂STM32使用DHT11采集温湿度](https://img-blog.csdnimg.cn/3194a49fb94f41568c8c43d2994b2540.png)