目录
一、排序算法概述
二、初级排序算法
三、进阶排序算法
四、分治思想排序
五、哈希思想排序
六、分割思想排序
一、排序算法概述
在C语言中,通常需要手写排序算法实现对数组或链表的排序,但是在C++中,标准库中的<algorithm>头文件中已经实现了基于快排的不稳定排序算法 std::sort() ,以及稳定的排序算法 std::stable_sort() 。
排序算法通常会伴随着容器使用,当然有些时候,我们也可以直接通过容器的特性来实现对元素的去重和排序,比如 map 和 unordered_map 底层的红黑树,就可以在插入数据的时候实现排序。
虽然C++标准库中已经封装有了现成排序算法了,那么我们为何还要学习排序算法呢?
对于应聘者而言,排序算法无论是笔试还是面试,都是常考点,所以我们需要掌握排序算法的算法原理与代码实现,通过学习排序算法,能够加深我们对于代码的复杂度分析,同时也能加深我们对于数据的稳定性分析。
复杂度分为时间复杂度和空间复杂度,在早期的程序中,内存往往是限制程序运行的关键因素,因此在算法设计的时候,都会尽可能在考虑代码效率的同时去考虑节约内存,从而做到时间复杂度和空间复杂度的相对平衡,但是随着硬件技术的发展,计算机的内存越来越大,已经不再是紧缺资源了,所以如今的算法设计,会尽可能地优先考虑时间复杂度,在最大化地降低时间复杂度之后,才会考虑去节约内存,甚至有些算法会考虑牺牲空间复杂度来提高效率,比如归并排序。
稳定性在排序算法中也是需要重点考虑的一个因素,稳定性是指在排序过程中,两个等值的元素它们的相对位置是否会在排序过程中改变,如果它们的位置不变,即这是稳定的排序算法,否则就是不稳定的排序算法。
排序算法经历了长远的发展历程,到如今最广为人知的排序算法有:冒泡排序、插入排序、选择排序、希尔排序、桶排序、归并排序、快速排序、计数排序、基数排序、桶排序、外排序……
从算法思维进行分类的话,可以分为以下几类:
- 暴力求解思想:冒泡排序
- 基于插入思想:插入排序、希尔排序
- 基于选择思想:选择排序、堆排序
- 基于分治思想:归并排序、快速排序
- 基于哈希思想:计数排序、基数排序
- 基于分割思想:桶排序、外排序
从算法稳定性进行分类的话,可以进行如下分类:
- 稳定:冒泡排序、插入排序、归并排序、基数排序
- 不稳定:选择排序、希尔排序、堆排序、计数排序、快速排序
- 不确定:桶排序、外排序
二、初级排序算法
初级排序算法是指冒泡排序、插入排序、选择排序。
初级排序算法时间复杂度高,很少会在项目中直接使用,但是初级排序算法的算法思想是其他排序算法的基础,我们可以做了解,以此来对比出其他排序算法的高效性。
// 冒泡排序
// 每次遍历都将最值移动到数组末端
// 时间复杂度:O(N^2)
void BubbleSort(std::vector<int>& arr) {
int n = arr.size();
for (int i = 0; i < n-1; i++) {
bool swapped = false;
for (int j = 0; j < n-i-1; j++) {
if (arr[j] > arr[j+1]) {
std::swap(arr[j], arr[j+1]);
swapped = true;
}
}
if (!swapped) {
break;
}
}
}// 插入排序
// 每次遍历都将当前元素往前进行比较,找到它适合插入的位置
// 时间复杂度和数组的原始有序度有关,为 O(N) ~ O(N^2)
void InsertSort(std::vector<int>& arr) {
int n = arr.size();
for (int i = 1; i < n; i++) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j+1] = arr[j];
j = j - 1;
}
arr[j+1] = key;
}
}// 选择排序
// 每次遍历会找到最小值和最大值将其放入数组的最前端和最后端
// 只是简单实现的话,可以每次遍历只选择一个最值进行交换
// 同时选择最小值和最大值进行交换,提高了效率
// 时间复杂度:O(N^2)
void SelectSort(std::vector<int>& arr) {
int n = arr.size();
for (int i = 0; i < n / 2; i++) {
int minIndex = i;
int maxIndex = i;
for (int j = i + 1; j < n - i; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
if (arr[j] > arr[maxIndex]) {
maxIndex = j;
}
}
if (minIndex != i) {
std::swap(arr[i], arr[minIndex]);
}
if (maxIndex == i) {
maxIndex = minIndex;
}
if (maxIndex != n - i - 1) {
std::swap(arr[n - i - 1], arr[maxIndex]);
}
}
}
// void SelectionSort(std::vector<int>& arr) {
// int n = arr.size();
// for (int i = 0; i < n-1; i++) {
// int minIndex = i;
// for (int j = i+1; j < n; j++) {
// if (arr[j] < arr[minIndex]) {
// minIndex = j;
// }
// }
// std::swap(arr[i], arr[minIndex]);
// }
// }三、进阶排序算法
进阶排序算法是指在初级排序算法上进行了升级,从而实现的算法,如:希尔排序、堆排序。
希尔排序是插入排序的升级,堆排序是选择排序的升级。
插入排序的时间复杂度受原始数组有序度的影响,所以希尔排序的核心思想就是先提高原始数组的有序度,然后再采用插入排序,所以对于希尔排序的具体实现就是先将原始数组的元素按照一个间隔进行分组,先确保每个分组的有序,最后不断缩小这个间隔,最后以此间隔为1,那么就是在进行插入排序了,这既是预排序机制。
堆排序利用二叉树的思想来实现对于数组最值的寻找,在进行升序排序的时候建大根堆,在进行降序排序的时候建小根堆,在建堆的时候,从后往前的父节点进行向下调整,在进行排序的时候,将最值范围内最后的元素交换,再不断降低排序范围从根节点往下进行调整。
堆排序常常用于解决Top-K的问题,若要从海量的数据中寻找K个最大值,我们可以建立一个空间复杂度为O(1)的小根堆,然后遍历海量数据,只要出现比堆顶元素大的数据,则删去堆顶元素,该数据入堆,时间复杂度是O(N)。
// 希尔排序
// 时间复杂度无法准确计算,在O(N)~O(N^2)之间,但远低于O(N^2)
void ShellSort(std::vector<int>& arr) {
int n = arr.size();
for (int gap = n / 2; gap > 0; gap /= 2) {
for (int i = gap; i < n; i++) {
int temp = arr[i];
int j;
for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {
arr[j] = arr[j - gap];
}
arr[j] = temp;
}
}
}// 堆排序
// 向下调整可以采用循环或者递归都可以
// 时间复杂度:O(N * log N)
void DownAdjust(int* arr, int parent, int n) {
int child = parent * 2 + 1;
while (child < n) {
if (child + 1 < n && arr[child] < arr[child + 1])
child++;
if (arr[parent] < arr[child]) {
Swap(&arr[parent], &arr[child]);
parent = child;
child = child * 2 + 1;
}
else {
break;
}
}
}
void HeapSort(int* arr, int n) {
int parent = (n - 2) / 2; // 最后一个节点的父节点
while (parent >= 0) {
DownAdjust(arr, parent, n);
--parent;
}
while (--n) {
Swap(&arr[0], &arr[n]);
DownAdjust(arr, 0, n);
}
}
四、分治思想排序
分治思想的排序是指归并排序和快速排序,它们的算法逻辑受二分法影响。
归并排序和快速排序算法各有优缺点,分不清孰优孰劣,只是应用场景不同。
在排序算法中,通常将额外消耗掉内存空间视为空间复杂度,大多数排序算法不会消耗额外的内存空间,即空间复杂度为O(1),但是归并排序的空间复杂度为O(N),从内存损耗的角度来看,快速排序算法更优,但是归并排序是稳定的排序算法,从稳定性来说,归并排序更优。
归并排序是先将数组无限分割,然后再将一块块分割后的数据进行填入额外开辟的空间中,再用额外空间中已经合并好的有序数据对原数组进行copy覆盖,先无限分割、再合并为一,最后实现了数组的排序。
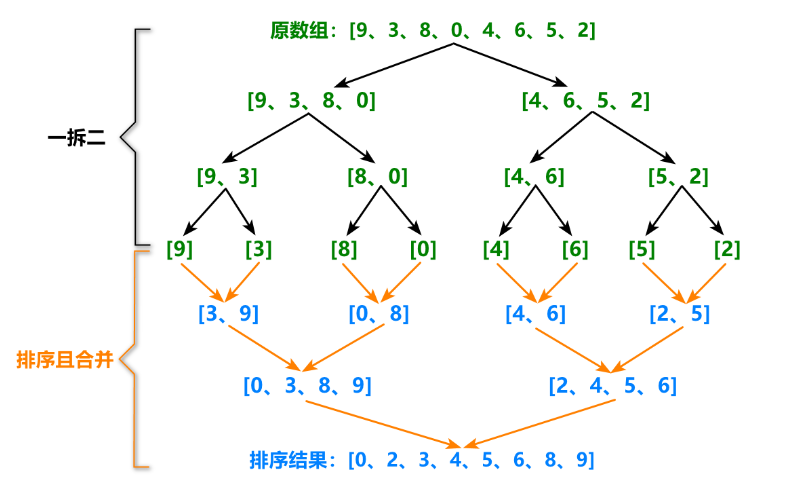
void __MergeSort(int* arr, int begin, int end, int* tmp) {
if (begin >= end)
return;
// 递归,先将数组无限分割,直到每个子数列的长度小于等于2
int mid = (begin + end) / 2;
_MergeSort(arr, begin, mid, tmp);
_MergeSort(arr, mid + 1, end, tmp);
int leftBegin = begin;
int leftEnd = mid;
int rightBegin = mid + 1;
int rightEnd = end;
int pos = begin;
while (leftBegin <= leftEnd && rightBegin <= rightEnd) {
// 从前往后同步遍历两个子数列,将相对较小的值先写入tmp中
if (arr[leftBegin] < arr[rightBegin])
tmp[pos++] = arr[leftBegin++];
else
tmp[pos++] = arr[rightBegin++];
}
// 将还没遍历完的子数列的值一次性写入tmp中
while (leftBegin <= leftEnd) {
tmp[pos++] = arr[leftBegin++];
}
while (rightBegin <= rightEnd) {
tmp[pos++] = arr[rightBegin++];
}
// 内存数据copy,将临时存储有序子数列的tmp数组的值写入arr对应位置
memcpy(arr + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
void MergeSort(int* arr, int n) {
int* tmp = (int*)malloc(sizeof(int) * n);
__MergeSort(arr, 0, n - 1, tmp);
free(tmp);
tmp = NULL;
}快速排序的思想是找到一个关键Key值,每一次遍历都将比Key值小的数据放在Key左边,比Key值大的数据放在Key值右边,然后通过递归对Key值左右两边的子数组用同样的方法进行排序,最终实现了数组的排序。但是当子数组范围已经很小的时候,此时再通过递归调用的效率损耗是很大的,而且此时的数组有序度已经相当高了,所以归并排序可以配合着插入排序使用,即将子数组分割到一定的范围后,就不再分治,而是直接调用插入排序算法。
快速排序算法有多种实现方式,如Hoare法、挖坑法、前后指针法和非递归法。虽然快排有多种实现方式,但是他们的算法原理是一样的。

// Hoare法
// 选左边为key值,则右边先走,最后左右相遇时比key值小
// 选右边为key值,则左边先走,最后左右相遇时比key值大
int __Hoare(std::vector<int>& arr, int begin, int end) {
int ikey = begin;
while (begin < end) {
while (arr[end] >= arr[ikey] && end > begin) {
--end;
}
while (arr[begin] <= arr[ikey] && begin < end) {
++begin;
}
std::swap(arr[begin], arr[end]);
}
swap(arr[ikey], arr[end]);
return end;
}
void QuickSort(std::vector<int>& arr, int begin, int end) {
if (begin >= end)
return;
int ikey = __Hoare(arr, begin, end);
QuickSort(arr, begin, ikey - 1);
QuickSort(arr, ikey + 1, end);
}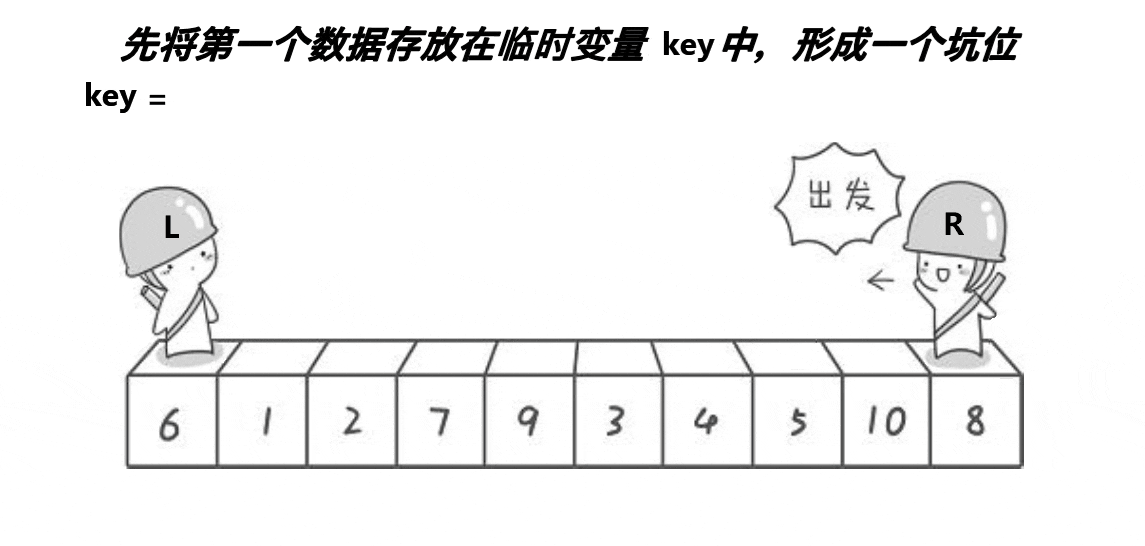
// 挖坑法
int __DigHole(std::vector<int>& arr, int begin, int end) {
int key = arr[begin];
while (begin < end) {
while (arr[end] >= key && end > begin) {
--end;
}
arr[begin] = arr[end];
while (arr[begin] <= key && begin < end) {
++begin;
}
arr[end] = arr[begin];
}
arr[end] = key;
return end;
}
void QuickSort(std::vector<int>& arr, int begin, int end) {
if (begin >= end)
return;
int ikey = __DigHole(arr, begin, end);
QuickSort(arr, begin, ikey - 1);
QuickSort(arr, ikey + 1, end);
}
// 前后指针法
// 三数取中是快速排序算法的优化方案,目的是为了避免最坏情况的发送
// 除了三数取中,还可以在将子数组分到足够的小的范围的时候采用插入排序进行优化
// 时间复杂度:O(N * log N)
int __MidIndex(vector<int>& arr, int r, int m, int l) {
if ((arr[r] - arr[m]) * (arr[m] - arr[l]) >= 0)
return m;
else if ((arr[m] - arr[r]) * (arr[r] - arr[l]) >= 0)
return r;
else
return l;
}
int __Ptrptr(std::vector<int>& arr, int begin, int end) {
int key = arr[begin];
int prev = begin;
int cur = begin + 1;
while (cur <= end) {
if (arr[cur] < key && ++prev != cur) {
std::swap(arr[prev], arr[cur]);
}
++cur;
}
std::swap(arr[begin], arr[prev]);
return prev;
}
void QuickSort(std::vector<int>& arr, int begin, int end) {
if (begin >= end)
return;
int ikey = (arr, 0, (begin + end) / 2, end);
std::swap(arr[begin], arr[ikey]);
ikey = __Ptrptr(arr, begin, end);
QuickSort(arr, begin, ikey - 1);
QuickSort(arr, ikey + 1, end);
}// 非递归快排
// 在某些极端的情况下,大量的递归会导致堆栈移除,所以需要使用非递归快排算法
// 非递归快排的本质是通过栈或队列来实现对分治的下标控制
// 无论是Hoare法、挖坑法、前后指针法都可以改写为非递归形式
void QuickSort(std::vector<int>& arr, int begin, int end) {
if (begin >= end)
return;
int ikey = (arr, 0, (begin + end) / 2, end);
std::swap(arr[begin], arr[ikey]);
std::stack<std::pair<int, int>> stk;
stk.push(std::make_pair(begin, end));
while (!stk.empty()) {
int b = stk.top().first;
int e = stk.top().second;
stk.pop();
//ikey = __Hoare(arr, b, e);
//ikey = __DigHole(arr, b, e);
ikey = __Ptrptr(arr, b, e);
if (ikey - 1 > b)
stk.push(std::make_pair(b, ikey - 1));
if (ikey + 1 < e)
stk.push(std::make_pair(ikey + 1, e));
}
}五、哈希思想排序
哈希思想的排序是指计数排序和基数排序,哈希思想的排序算法时间复杂度都非常低,但是他们都有一定的局限性,使用计数排序需要数组中的最大值和最小值差值不能太大,否则空间损耗很大,使用基数排序需要明确知道最大值的位数。
// 计数排序
// 时间复杂度取决于最值之差
void CountSort(std::vector<int>& arr) {
int max = *std::max_element(arr.begin(), arr.end());
int min = *std::min_element(arr.begin(), arr.end());
int range = max - min + 1;
std::vector<int> count(range);
for (int i = 0; i < arr.size(); ++i) {
count[arr[i] - min]++;
}
int j = 0;
for (int i = 0; i < range; ++i) {
while (count[i] != 0) {
arr[j++] = i + min;
count[i] -= 1;
}
}
}// 基数排序
// 计数排序可以是做一种特殊的桶排序
// 时间复杂度为O(K * N)
// 设数据最大位数
#define K 3
// 取模的类别数(桶数、基数)
#define RADIX 10
// 桶
queue<int> _q[RADIX];
// 获取val值对应桶的位置,即哈希映射
int GetPos(int a, int k)
{
int pos = a % RADIX;
while (k--)
{
a /= RADIX;
pos = a % RADIX;
}
return pos;
}
// 分发数据,将数组数据按模分发到哈希桶上
void Distribute(int* arr, int left, int right, int k)
{
for (int i = left; i < right; ++i)
{
int pos = GetPos(arr[i], k);
_q[pos].push(arr[i]);
}
}
// 收集数据,根据队列的特性从哈希桶上收集数据,存入数组
void Collect(int* arr)
{
int pos = 0;
for (int i = 0; i < RADIX; ++i)
{
while (!_q[i].empty())
{
arr[pos++] = _q[i].front();
_q[i].pop();
}
}
}
void RadixSort(int* arr, int n)
{
int k = 0;
while (k < K)
{
Distribute(arr, 0, n, k++);
Collect(arr);
}
}六、分割思想排序
分割思想排序是指桶排序和外排序。
桶排序和外排序通常应用于理大量数据的排序,因为数据量太大而内存存不下,所以需要先将数据分割再进行排序。桶排序利用分布式思想,先将数据分割在多个桶中,每个桶中的数据量差不多,然后对每个桶中的数据进行排序最后再将数据合并,外排序是通过将数据存储在磁盘上来缓解内存不足的问题,通过内存与磁盘间进行多次数据的交换实现对全部数据的排序。
通常情况下,桶排序是稳定的,它在每个桶中的排序算法会保证元素间的相对顺序,最后的合并过程也会保持稳定性,但是却并不绝对,因为无论是桶排序还是外排序,其稳定性都取决于其内部子数列的排序算法的选择。
// 桶排序
void BucketSort(std::vector<float>& arr) {
int n = arr.size();
std::vector<std::vector<float>> buckets(n);
// 将元素分布到桶中
// 将元素分布到桶中的算法由程序员自己决定,根据数据集决定
// 将数值越小的数,放在越靠前的桶中
for (int i = 0; i < n; i++) {
float bucket_index = arr[i] / 10;
if (bucket_index < 0)
bucket_index = 0;
else if (bucket_index >= n)
bucket_index = n - 1;
buckets[bucket_index].push_back(arr[i]);
}
// 对每个非空的桶进行排序
for (int i = 0; i < n; i++) {
if (!buckets[i].empty()) {
std::sort(buckets[i].begin(), buckets[i].end());
}
}
// 将排序后的元素放回原数组
int index = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < buckets[i].size(); j++) {
arr[index++] = buckets[i][j];
}
}
}// 外排序
#include <iostream>
#include <fstream>
#include <vector>
#include <algorithm>
#include <string>
const int MAX_MEMORY_SIZE = 100; // 假设内存最多可以容纳100个元素
void externalSort(const std::string& inputFileName, const std::string& outputFileName) {
// 读取数据并分块排序
// ...(省略读取和排序步骤)
// 文件归并
// ...(省略文件归并步骤)
}