文章目录
- 需求
- 所需第三方库
- requests模块
- lxml模块
- 了解 lxml模块和xpath语法
- xpath语法-基础节点选择语法
- 实战教程
- 完整代码
需求
目标网站: https://movie.douban.com/top250
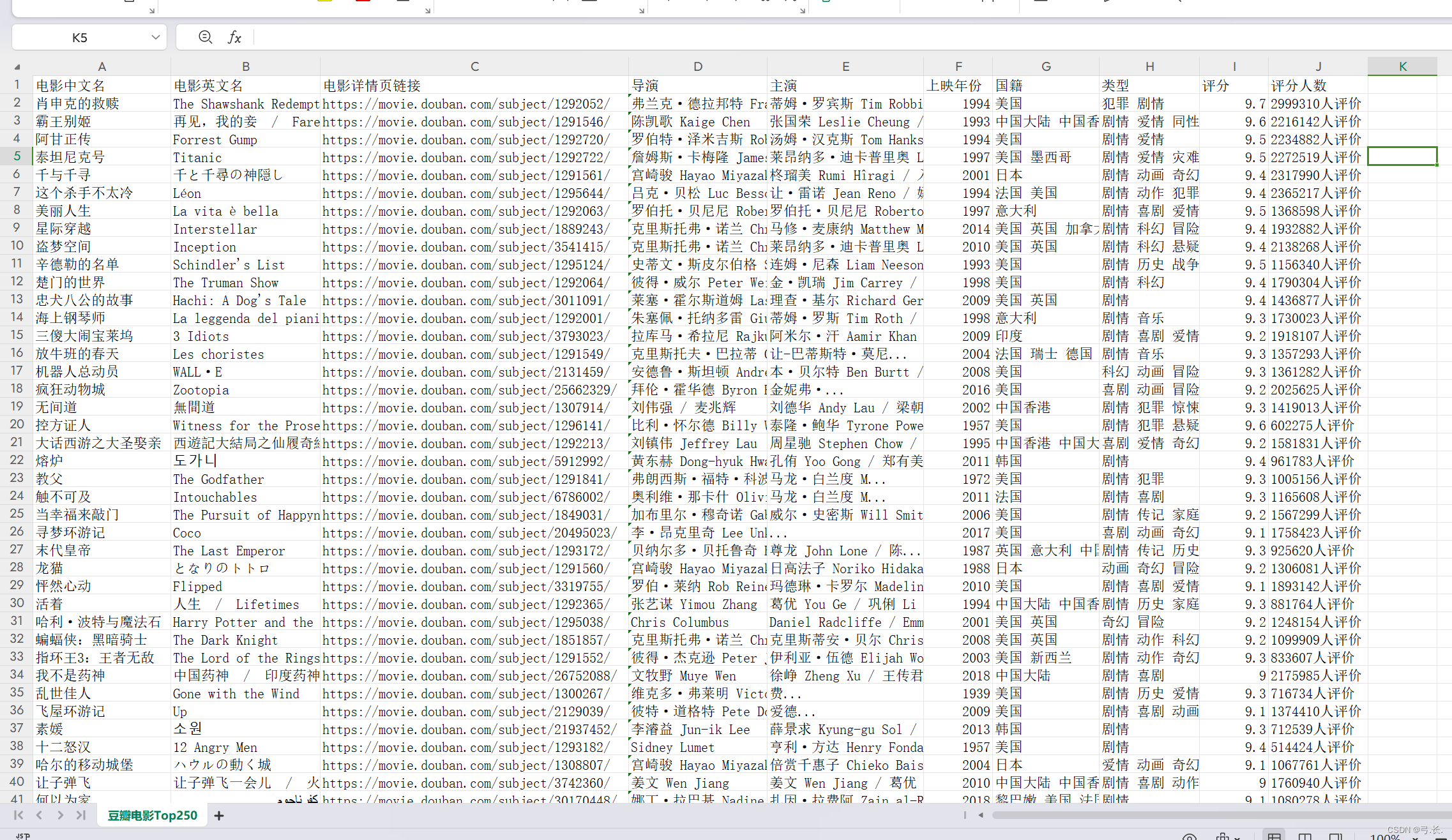
需求: 爬取电影中文名、英文名、电影详情页链接、导演、主演、上映年份、国籍、类型、评分、评分人数, 并保存到csv文件当中
目标url:https://movie.douban.com/top250
所需第三方库
requestslxml
安装
requests安装命令:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
lxml安装命令:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
简介
requests模块
requests 是 Python 编程语言中一个常用的第三方库,它可以帮助我们向 HTTP 服务器发送各种类型的请求,并处理响应。
- 向 Web 服务器发送 GET、POST 等请求方法;
- 在请求中添加自定义标头(headers)、URL 参数、请求体等;
- 自动处理 cookies;
- 返回响应内容,并对其进行解码;
- 处理重定向和跳转等操作;
- 检查响应状态码以及请求所消耗的时间等信息。
lxml模块
了解 lxml模块和xpath语法
lxml 是 Python 编程语言中一个常用的第三方库,它提供了一个高效而简单的方式来解析和处理 XML 和 HTML 文档。
- 从文件或字符串中读取 XML 或 HTML 文档;
- 使用 XPath 或 CSS 选择器来查找和提取文档中的数据;
- 解析 XML 或 HTML 文档,并将其转换为 Python 对象或字符串;
- 对文档进行修改、重构或序列化;
- 处理命名空间和 CDATA 等特殊情况。
对html或xml形式的文本提取特定的内容,就需要我们掌握lxml模块的使用和xpath语法。
- lxml模块可以利用XPath规则语法,来快速的定位HTML\XML 文档中特定元素以及获取节点信息(文本内容、属性值)
- XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML 文档中对元素和属性进行遍历。
- W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
- 提取xml、html中的数据需要lxml模块和xpath语法配合使用
xpath语法-基础节点选择语法
- XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。
- 这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
- 使用chrome插件选择标签时候,选中时,选中的标签会添加属性class=“xh-highlight”
xpath定位节点以及提取属性或文本内容的语法
| 表达式 | 描述 |
|---|---|
| nodename | 选中该元素。 |
| / | 从根节点选取、或者是元素和元素间的过渡。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| text() | 选取文本。 |
xpath语法-节点修饰语法
可以根据标签的属性值、下标等来获取特定的节点
节点修饰语法
| 路径表达式 | 结果 |
|---|---|
| //title[@lang=“eng”] | 选择lang属性值为eng的所有title元素 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()>1] | 选择bookstore下面的book元素,从第二个开始选择 |
| //book/title[text()=‘Harry Potter’] | 选择所有book下的title元素,仅仅选择文本为Harry Potter的title元素 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
关于xpath的下标
- 在xpath中,第一个元素的位置是1
- 最后一个元素的位置是last()
- 倒数第二个是last()-1
xpath语法-其他常用节点选择语法
- // 的用途
- //a 当前html页面上的所有的a
- bookstore//book bookstore下的所有的book元素
- @ 的使用
- //a/@href 所有的a的href
- //title[@lang=“eng”] 选择lang=eng的title标签
- text() 的使用
- //a/text() 获取所有的a下的文本
- //a[texts()=‘下一页’] 获取文本为下一页的a标签
- a//text() a下的所有的文本
- xpath查找特定的节点
- //a[1] 选择第一个s
- //a[last()] 最后一个
- //a[position()<4] 前三个
- 包含
- //a[contains(text(),“下一页”)]选择文本包含下一页三个字的a标签**
- //a[contains(@class,‘n’)] class包含n的a标签
实战教程
打开网站
https://movie.douban.com/top250
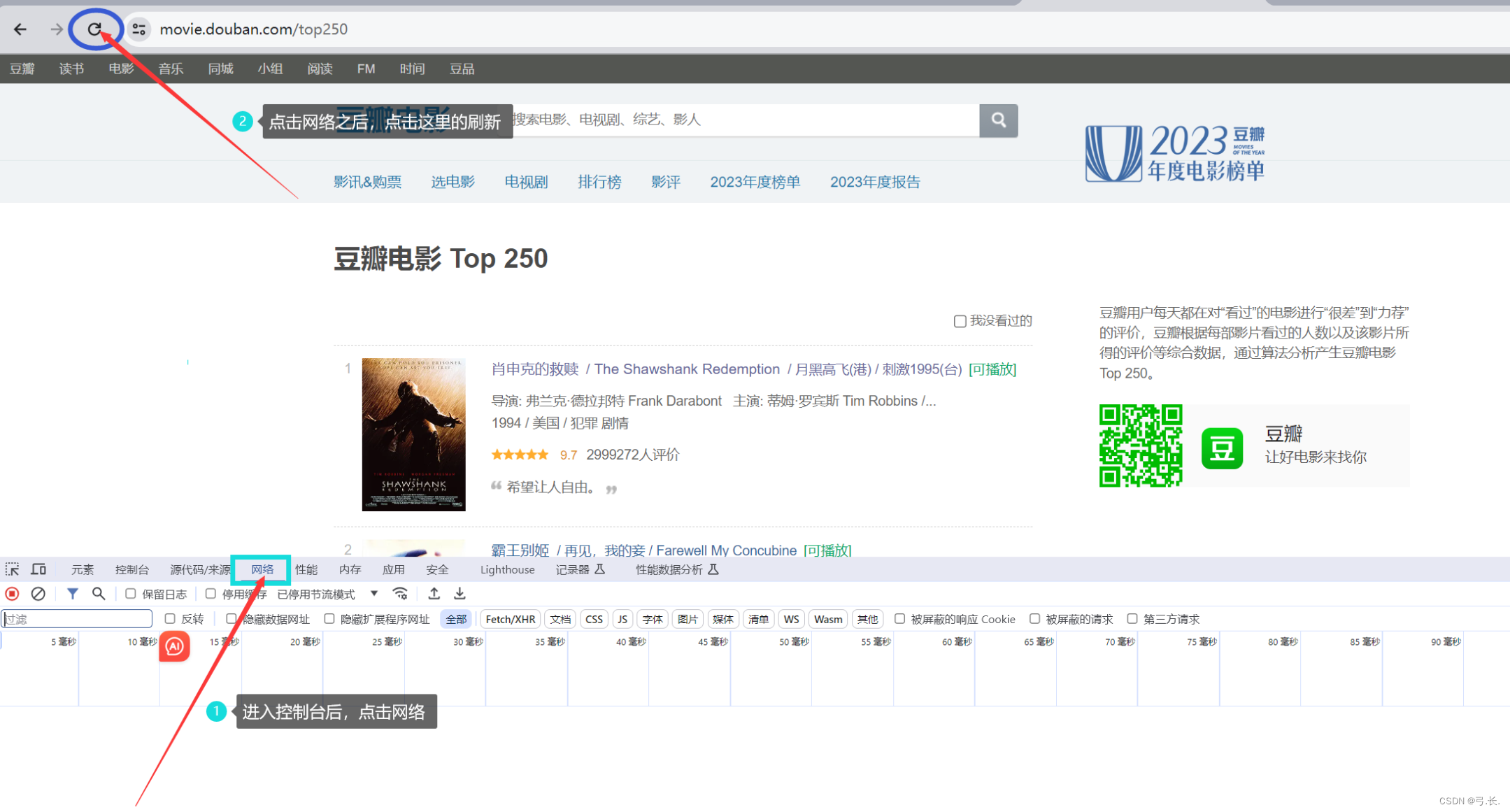
进入网站之后鼠标右击检查,或者F12来到控制台,点击网络,然后刷新。
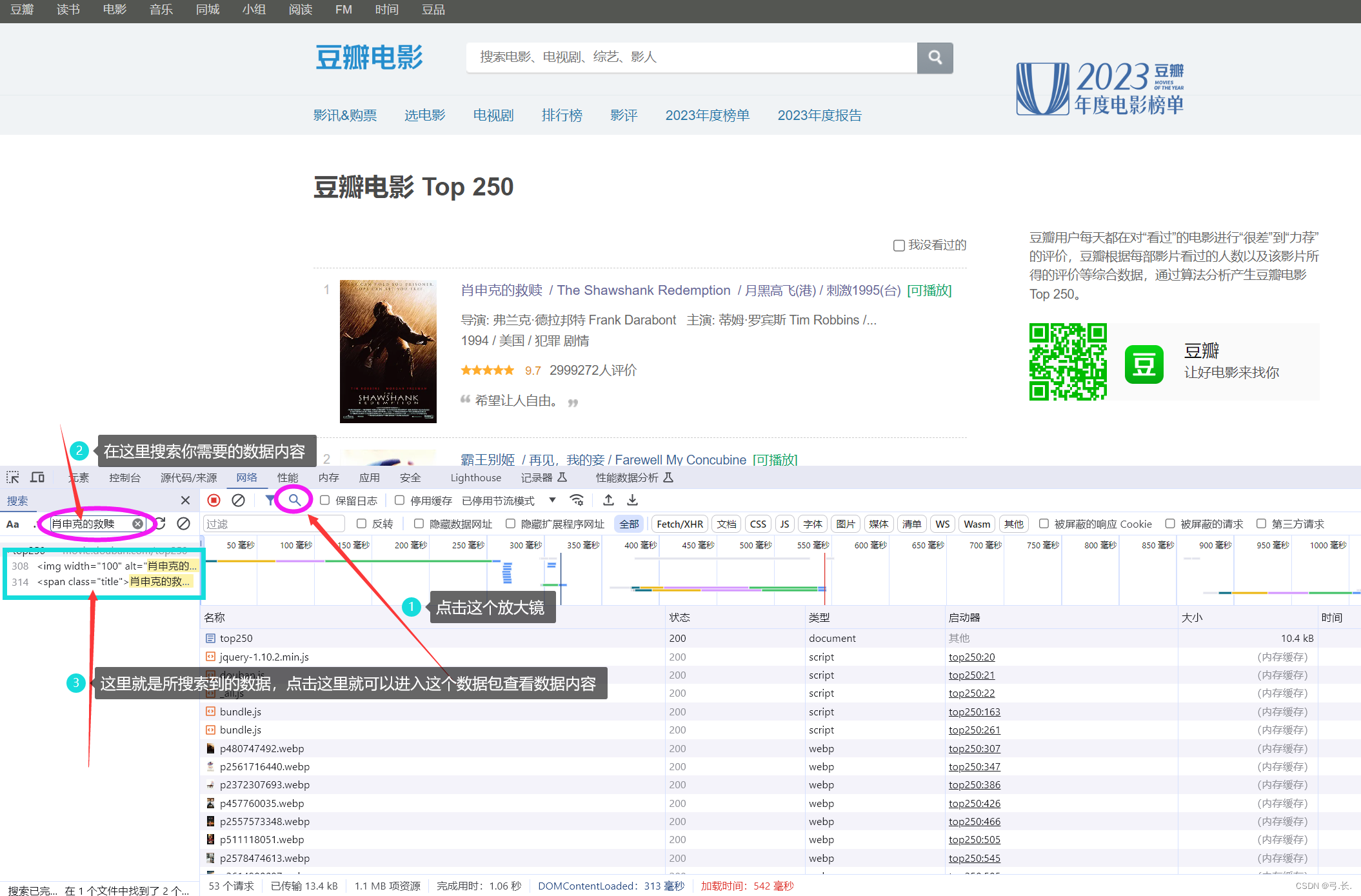
刷新之后,点击那个放大镜搜索你需要的的数据内容,这样可以直接找到你所需要的数据包
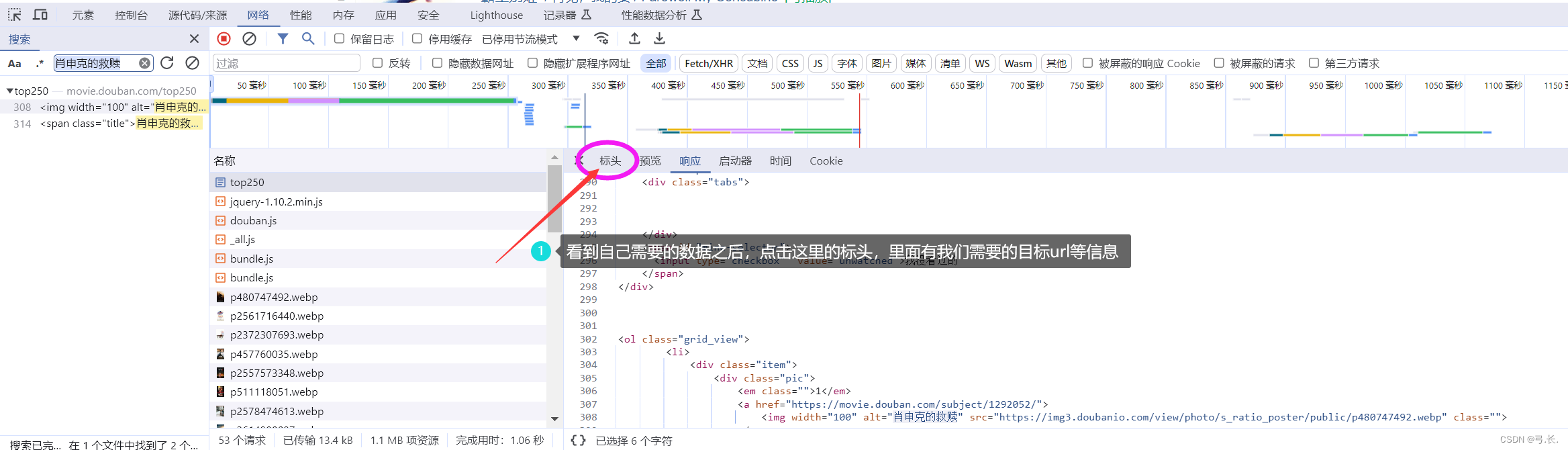
点击进入数据包之后,首先要查看我们需要的数据是否都在这个数据包里面,如果我们需要的数据在这个数据包里面不全,则这个数据包可能不是我们需要的,要另外进行查找;如果我们需要的数据在这个数据包里面都有,那么这个数据包是我们所需要的数据包,接下来我们就点击标头,里面有我们需要的url等信息。
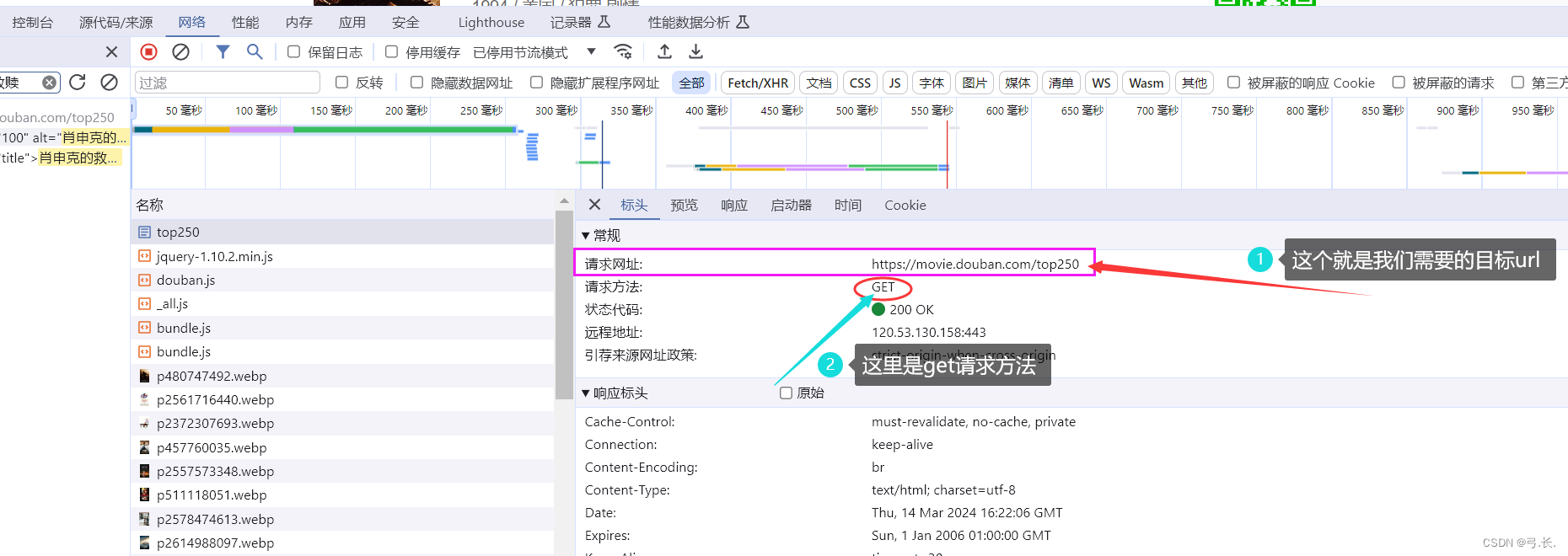
# 导入模块
import requests
# 目标url
url = 'https://movie.douban.com/top250'
# 发送请求, 获取响应
res = requests.get(url) # 标头里面的请求方法是GET, 所以这里我们使用get请求方法
print(res.text)
我们打印之后发现并没有输出任何内容,这是因为对于爬虫来说,有时候网站可能会采取一些反爬虫措施,以防止爬虫程序过度访问网站或者获取网站数据。那么为了避免反爬,我们需要设置合适的请求头信息来模拟真实浏览器行为,设置合适的 User-Agent 和其他请求头信息,使请求看起来更像是来自正常的浏览器访问。
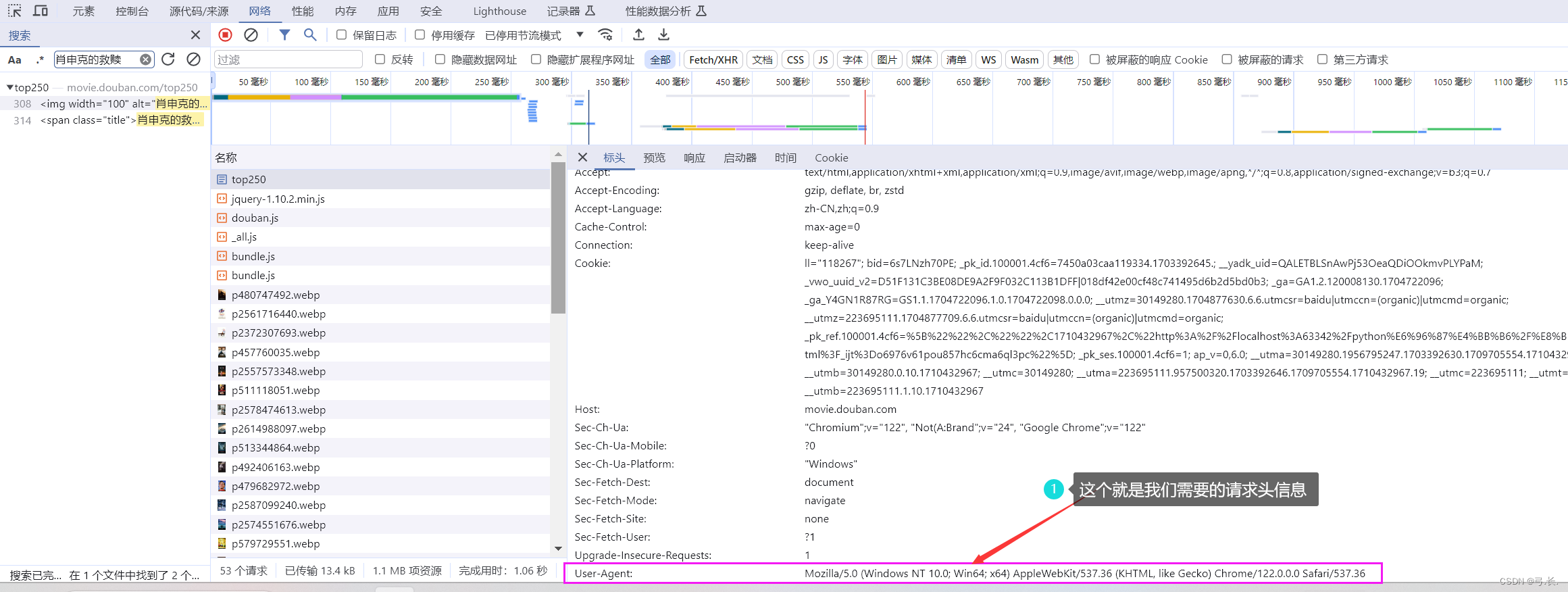
那么 User-Agent 要在哪里找呢?
别急,其实这个也在我们的标头里面,我们用鼠标向下滑动就可以找到 User-Agent 。
# 导入模块
import requests
# 目标url
url = 'https://movie.douban.com/top250'
# 添加请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# 发送请求, 获取响应 这里的headers=是一个关键字
res = requests.get(url, headers=headers) # 标头里面的请求方法是GET, 所以这里我们使用get请求方法
print(res.text)
注意:这里的请求头信息要以字典的格式写入

可以看到,我们在添加了请求头信息后,再次运行就有了输出内容,我们可以用CTRL + F查找一些数据,看这个打印出来的数据是否是我们需要的,还有看数据打印是否有缺失,如果有,则证明还是有反爬,还需要添加其他一些反爬参数,不同的网站所需要的反爬参数不一样。但也不能一次性把所有的参数全部添加,有些可能是参数陷阱,添加了反而会报错。
接下来就是进行数据提取,也就需要我们导入lxml模块。
lxml模块的使用
-
导入lxml 的 etree 库
from lxml import etree -
利用etree.HTML,将html字符串(bytes类型或str类型)转化为Element对象,Element对象具有xpath的方法,返回结果的列表
html = etree.HTML(text) ret_list = html.xpath("xpath语法规则字符串") -
xpath方法返回列表的三种情况
- 返回空列表:根据xpath语法规则字符串,没有定位到任何元素
- 返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值
- 返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath
# 导入模块
import requests
from lxml import etree
# 目标url
url = 'https://movie.douban.com/top250'
# 添加请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# 发送请求, 获取响应 这里的headers=是一个关键字
res = requests.get(url, headers=headers) # 标头里面的请求方法是GET, 所以这里我们使用get请求方法
# 网页源码
html = res.text
# 实例化etree对象
tree = etree.HTML(html)
利用XPATH语法进行数据提取
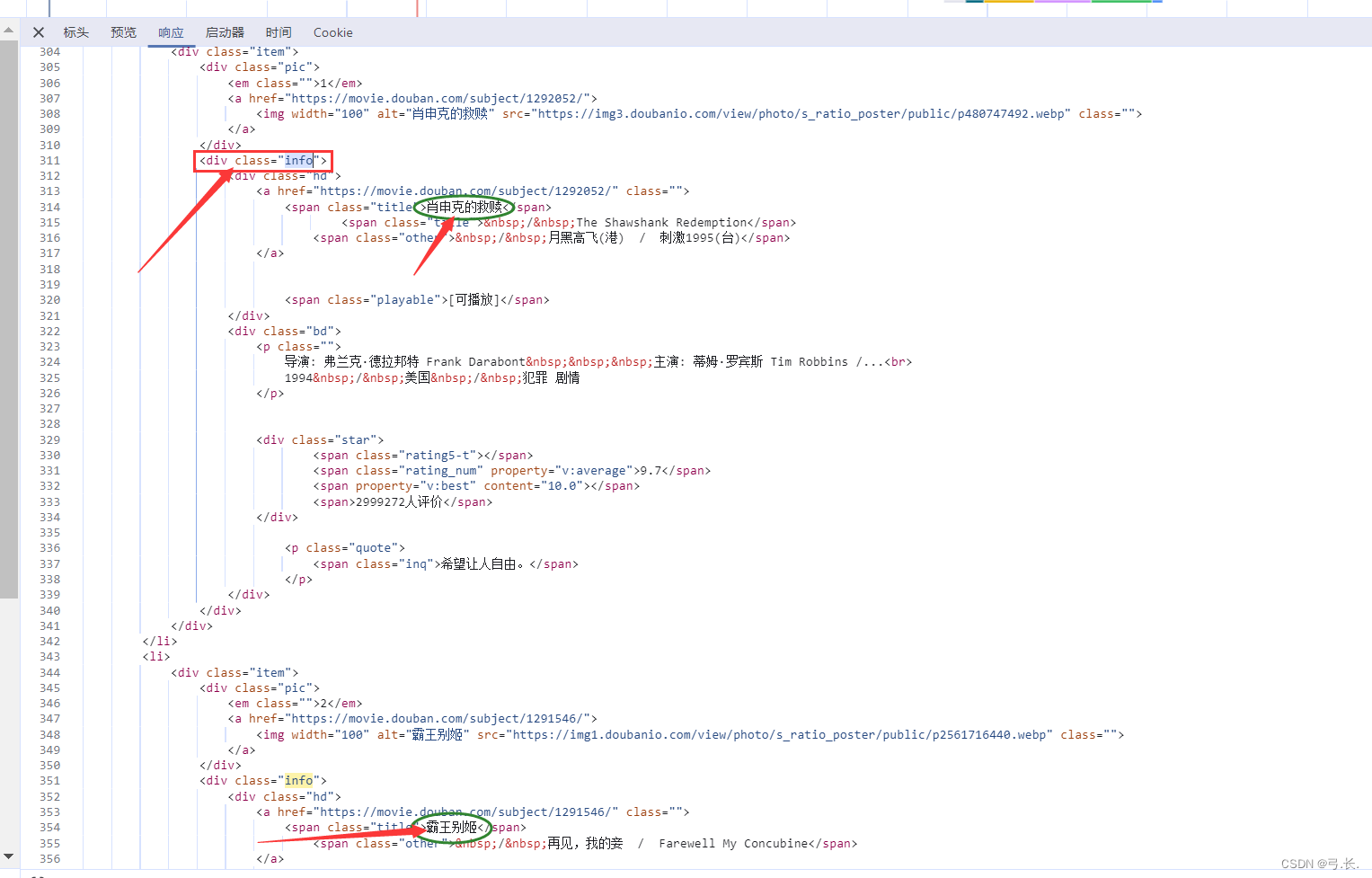
点击响应,我们可以看到,我们所需要的电影名等信息都在这个<div class="info">这个标签里面,那么我们就可以直接利用xpath语法找到这个标签。
# 利用xpath找到<div class="info">这个标签
divs = tree.xpath('//div[@class="info"]')
print(divs)

可以看到,打印出来的是列表数据类型,既然是列表,我们就可以利用循环遍历列表里面的元素,而且我们需要的电影数据也在这些标签元素里面。
这里以一部电影为例,其他电影数据分布与第一部电影类似,搞定了第一部,其他的就可以通过循环来实现。
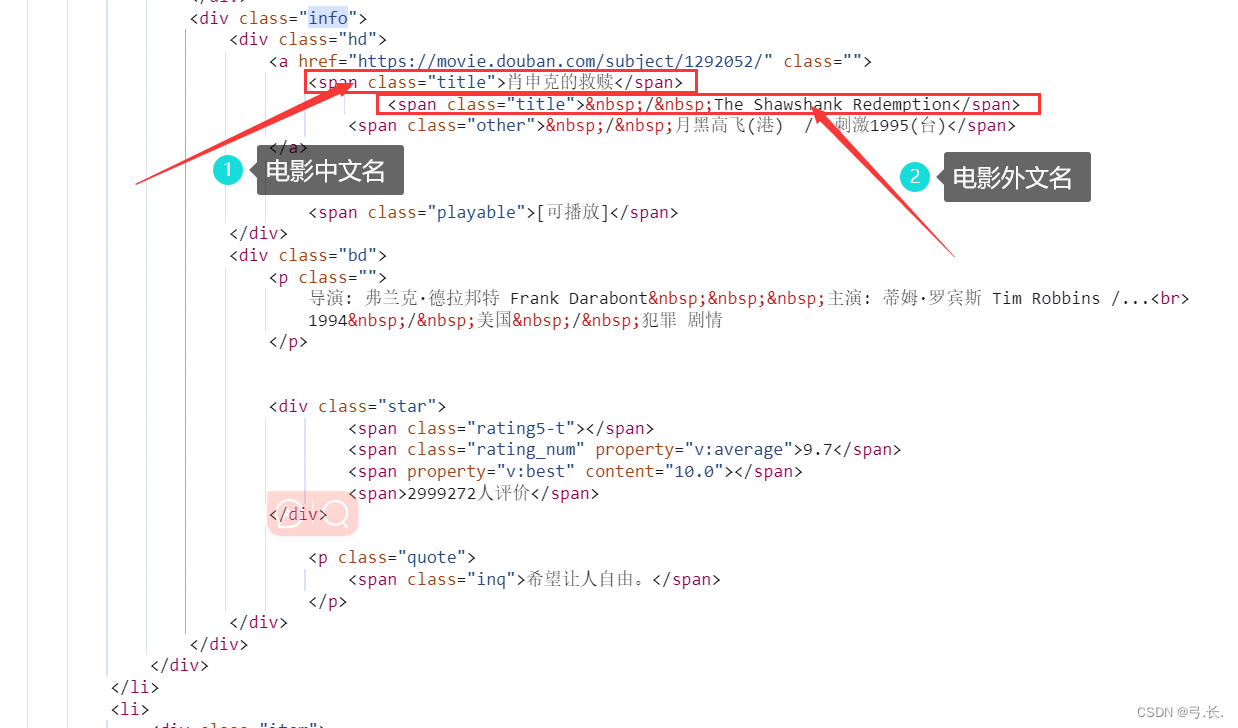
前面我们已经找到了<div class="info">这个标签,返回的数据类型是一个列表,循环遍历这个列表里的元素,那么我们接下来找标签元素就可以直接以<div class="info">为父节点来查找他的子孙级标签。
这里就以电影中文名为例,<div class="info">的下一级标签是<div class="hd">在下一级就是一个a标签,然后就是电影中文名所在的<span class="title">标签。
# 利用xpath找到<div class="info">这个标签
divs = tree.xpath('//div[@class="info"]')
# print(divs)
for div in divs:
title = div.xpath('./div[@class="hd"]/a/span/text()')
print(title)
break
xpath里面的 ./ 代表当前节点,也就是<div class="info">标签;最后的text()是获取标签里的文本内容。这里用break终止循环,我们只要查看一下打印的数据正不正确就行了。

返回的数据类型还是列表,可以看到:电影中文名就是列表的第一个元素,外文名就是第二个元素,直接利用索引取值就行了。
另外我们可以看到外文名有一些\xa0/\xa0这样的符号,\xa0 是一个 Unicode 字符,表示非断行空格。我们利用索引取值之后可以用字符串中的strip函数将它给去除。
for div in divs:
# title = div.xpath('./div[@class="hd"]/a/span/text()')
# print(title)
title_cn = div.xpath('./div[@class="hd"]/a/span/text()')[0]
title_en = div.xpath('./div[@class="hd"]/a/span/text()')[1].strip('\xa0/\xa0')
print(title_cn, title_en)
break
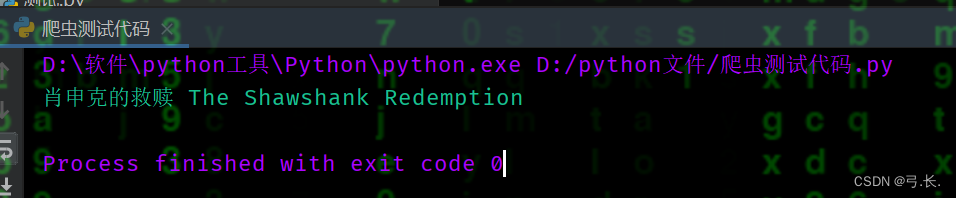
这样就获得了中文名和外文名。
电影详情页链接也可以用上面类似的方法获取。
for div in divs:
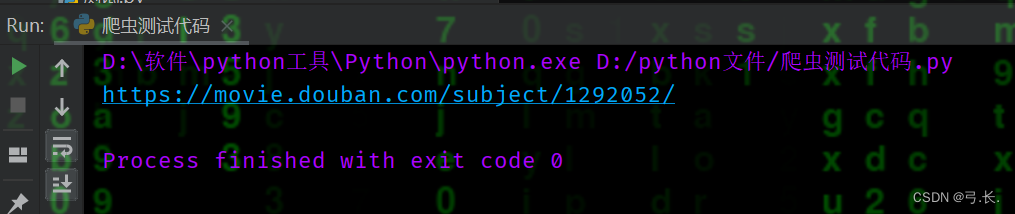
# 电影详情页链接
links = div.xpath('./div[@class="hd"]/a/@href')[0]
print(links)
break
但这里有一点需要注意,我们这里不是要获取a标签里的文本内容,而是要获取a标签里的href属性值。xpath中可以用@获取标签里面的属性值。
获取导演、主演、上映年份、国籍和电影类型
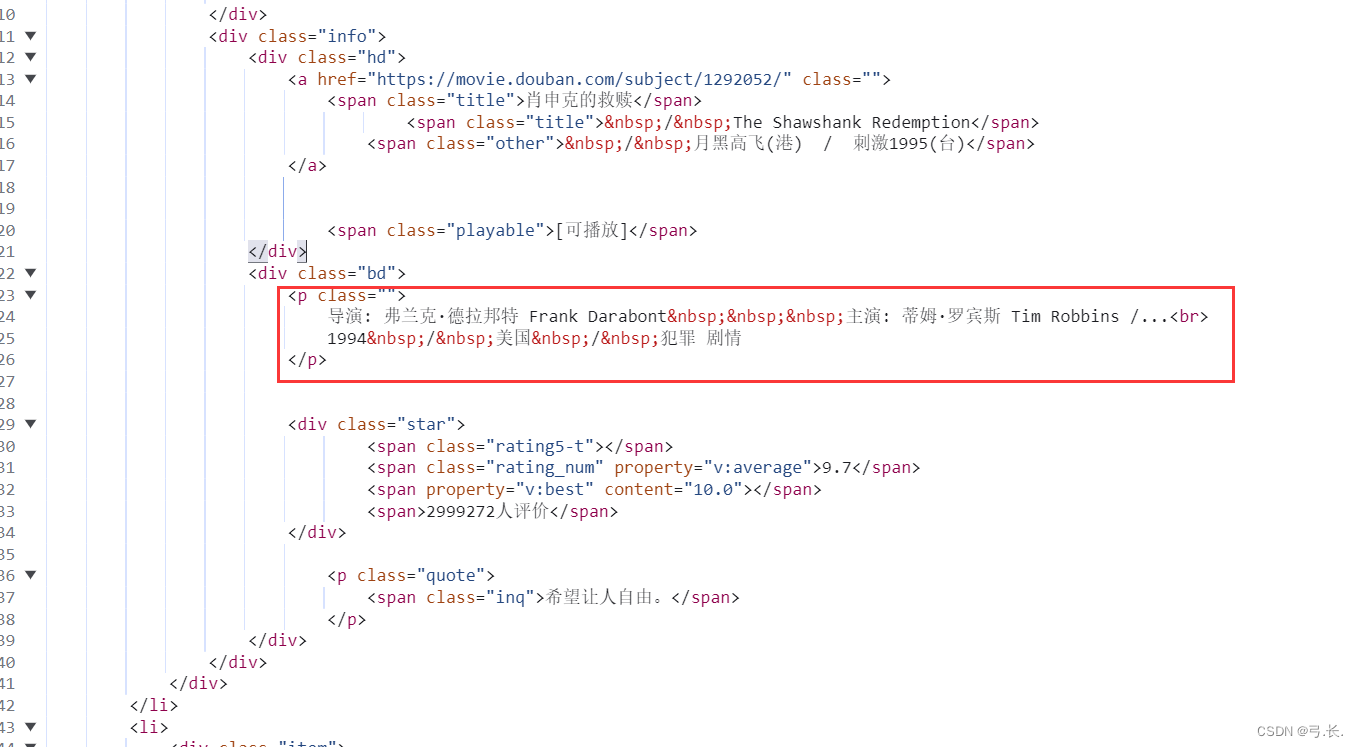
可以看到导演、主演、上映年份、国籍和电影类型其实都在一个p标签里面,那么我们只要获取到这个p标签,然后利用索引取值就行了。
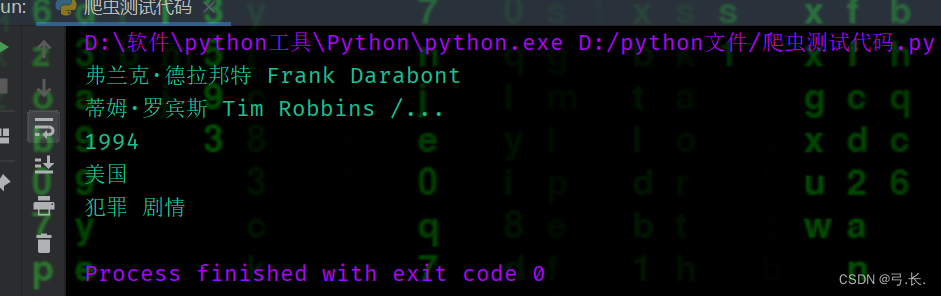
for div in divs:
# 导演
director = div.xpath('./div[@class="bd"]/p/text()')[0].strip().split('导演: ')[1].split('主演: ')[0]
print(director)
# 主演
try:
act = div.xpath('./div[@class="bd"]/p/text()')[0].strip().split('导演: ')[1].split('主演: ')[1]
# print(act)
except IndexError as e:
print('无主演信息...')
print(act)
# 上映年份
Release_year = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split('/')[0]
print(Release_year)
# 国籍
nationality = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split('/')[1].strip()
print(nationality)
# 类型
genre = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split('/')[2].strip()
print(genre)
break
这里要注意一下,有些电影可能会没有主演信息,如果按照常规方法那样的的话,当没有获取到数据就会报错,为了避免这种情况的发生,可以用异常处理一下,这样就算没有获取到信息也不会报错,程序还是可以继续进行,其他地方像上映年份前后都有 这样的符号,这其实是是 HTML 中的实体字符,表示一个非断行空格。中间还有/的符号,像这样的我们可以先利用split函数将/去掉,然后利用strip函数去除空格。
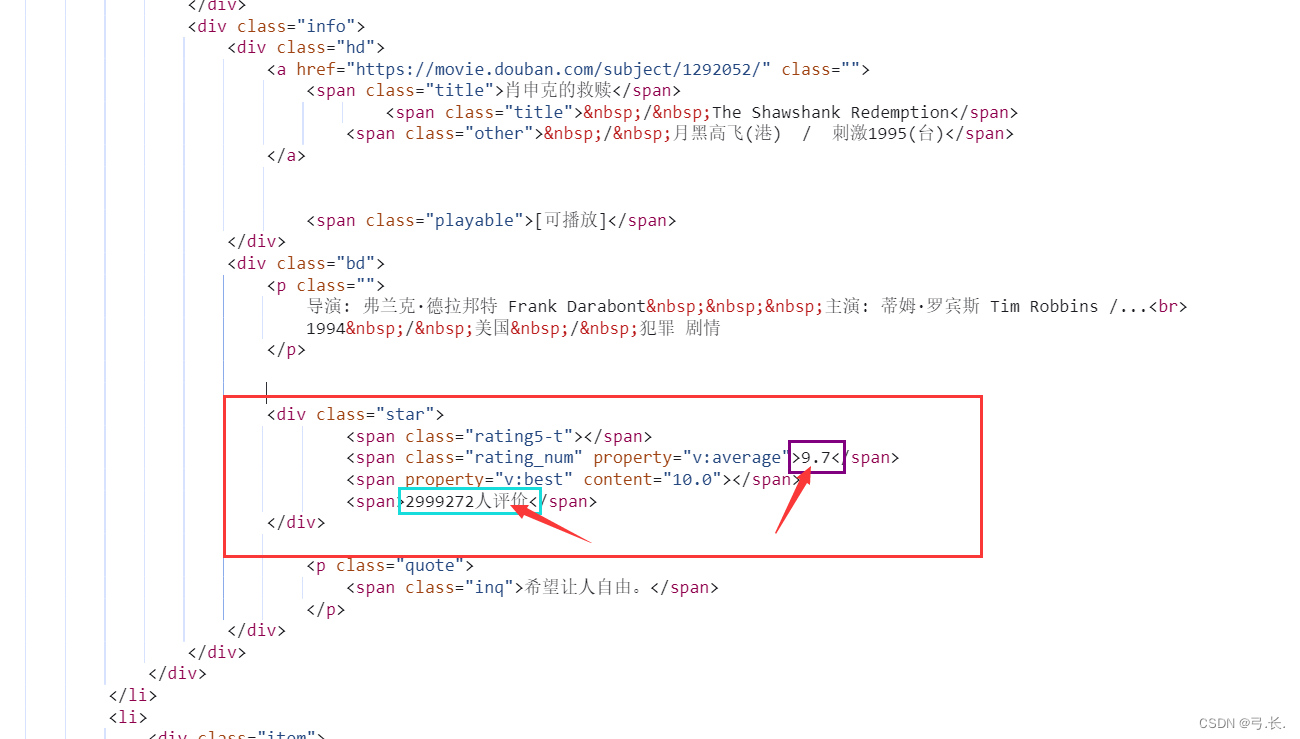
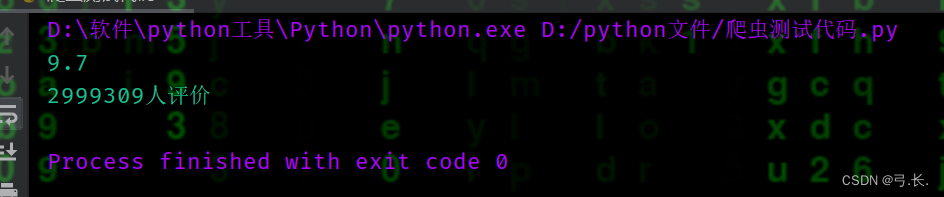
for div in divs:
# 评分
score = div.xpath('./div[@class="bd"]/div/span[2]/text()')[0]
print(score)
# 评分人数
num_score = div.xpath('./div[@class="bd"]/div/span[4]/text()')[0]
print(num_score)
break
最后的评分和评分人数所在同一级的不同span标签里面,而且它们还具有同一个父级标签<div class="star">,这里我们只要注意在取span标签时,它的索引是从1开始的,而不是从0开始。
到这里我们都是爬取一页的电影数据,并没有进行翻页处理,那怎么进行翻页处理呢?
我们可以点击其他页数,查看一下其url的变化
第一页的url: https://movie.douban.com/top250?start=0&filter=
第二页的url: https://movie.douban.com/top250?start=25&filter=
第三页的url: https://movie.douban.com/top250?start=50&filter=
...
我们可以发现它的start的参数随着翻页是发生变化的,变化规律类似与一个表达式:(页数 - 1) * 25。
for page in range(1, 11):
# 目标url
url = f'https://movie.douban.com/top250?start={(page - 1) * 25}&filter='
# 发送请求, 获取响应
res = requests.get(url, headers=headers)
# 打印响应信息
print(res.text)
现在我们所有的数据都爬完了,现在就要进行数据保存了,这里我们是要保存到csv文件中,就要借助于csv这个内置模块。
将数据写入到csv文件中需要以特定的格式写入,一种是列表嵌套元组,一种是列表嵌套字典。这里我们使用列表嵌套字典的方式写入。别问,问就是习惯了
应为字典里面要有所有电影的数据信息,为了方便,我们直接在循环内部定义一个字典,每一部电影的数据都放在一个字典中。而所有的字典都在一个列表当中,所以我们直接将列表定义在循环外面就行了。
with open('豆瓣电影Top250.csv', 'w', encoding='utf-8-sig', newline='') as f:
# 1. 创建对象
writer = csv.DictWriter(f, fieldnames=('电影中文名', '电影英文名', '电影详情页链接', '导演', '主演', '上映年份', '国籍', '类型', '评分', '评分人数'))
# 2. 写入表头
writer.writeheader()
# 3. 写入数据
writer.writerows(moive_list)
我们将数据组织为字典的列表,并使用 csv.DictWriter() 将数据写入到 CSV 文件中。需要注意的是,在使用 csv.DictWriter() 时,我们首先调用了 writeheader() 方法写入表头信息,然后通过循环逐行写入数据。
完整代码
# 导入模块
import requests
from lxml import etree
import csv
# 请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
moive_list = []
for page in range(1, 11):
# 目标url
url = f'https://movie.douban.com/top250?start={(page - 1) * 25}&filter='
# 发送请求, 获取响应
res = requests.get(url, headers=headers)
# 打印响应信息
# print(res.text)
# 网页源码
html = res.text
# 实例化etree对象
tree = etree.HTML(html)
divs = tree.xpath('//div[@class="info"]')
# print(divs)
for div in divs:
dic = {}
title = div.xpath('./div[@class="hd"]/a/span[@class="title"]/text()')
# 电影中文标题
title_cn = ''.join(title).split('\xa0/\xa0')[0]
dic['电影中文名'] = title_cn
# 电影英文标题
title_en = div.xpath('./div[@class="hd"]/a/span[2]/text()')[0].strip('\xa0/\xa0')
dic['电影英文名'] = title_en
# 电影详情页链接
links = div.xpath('./div[@class="hd"]/a/@href')[0]
dic['电影详情页链接'] = links
# print(links)
# 导演
director = div.xpath('./div[@class="bd"]/p/text()')[0].strip().split('导演: ')[1].split('主演: ')[0]
dic['导演'] = director
# print(director)
# 主演
try:
act = div.xpath('./div[@class="bd"]/p/text()')[0].strip().split('导演: ')[1].split('主演: ')[1]
# print(act)
except IndexError as e:
print(end='')
dic['主演'] = act
# 上映年份
Release_year = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split(' /')[0]
dic['上映年份'] = Release_year
# print(Release_year)
# 国籍
nationality = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split(' /')[1].strip()
dic['国籍'] = nationality
# print(title_cn, nationality)
# 类型
genre = div.xpath('./div[@class="bd"]/p/text()')[1].strip().split(' /')[2].strip()
dic['类型'] = genre
# print(genre)
# 评分
score = div.xpath('./div[@class="bd"]/div/span[2]/text()')[0]
dic['评分'] = score
# print(score)
# 评分人数
num_score = div.xpath('./div[@class="bd"]/div/span[4]/text()')[0]
dic['评分人数'] = num_score
# print(dic)
moive_list.append(dic)
# print(len(moive_list)) # 检查数据是否全部爬取成功
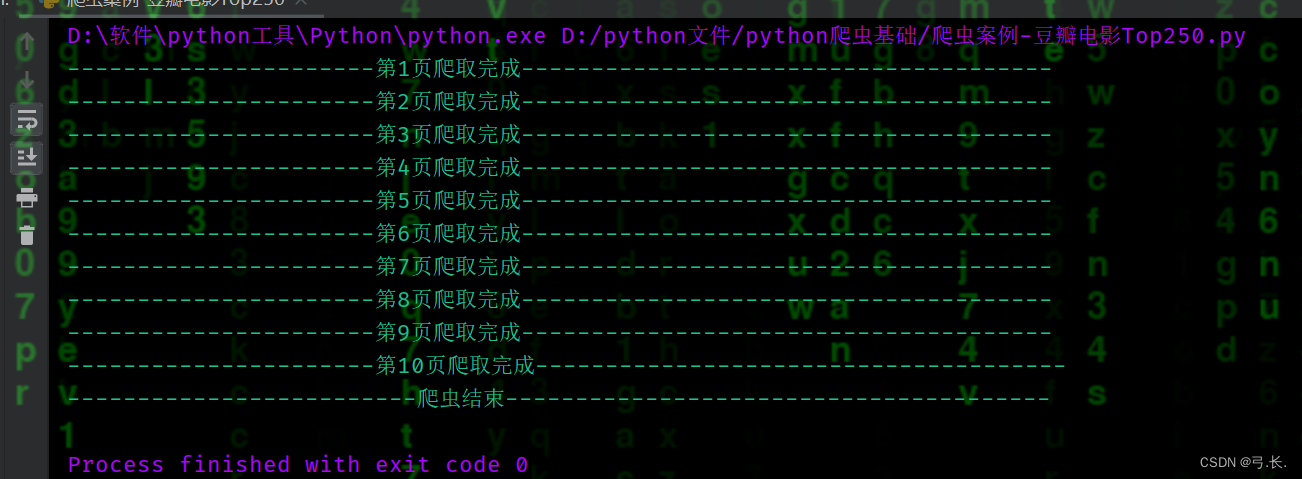
print(f'----------------------第{page}页爬取完成--------------------------------------')
print('-----------------------爬虫结束--------------------------')
# 数据保存
with open('豆瓣电影Top250.csv', 'w', encoding='utf-8-sig', newline='') as f:
# 1. 创建对象
writer = csv.DictWriter(f, fieldnames=('电影中文名', '电影英文名', '电影详情页链接', '导演', '主演', '上映年份', '国籍', '类型', '评分', '评分人数'))
# 2. 写入表头
writer.writeheader()
# 3. 写入数据
writer.writerows(moive_list)