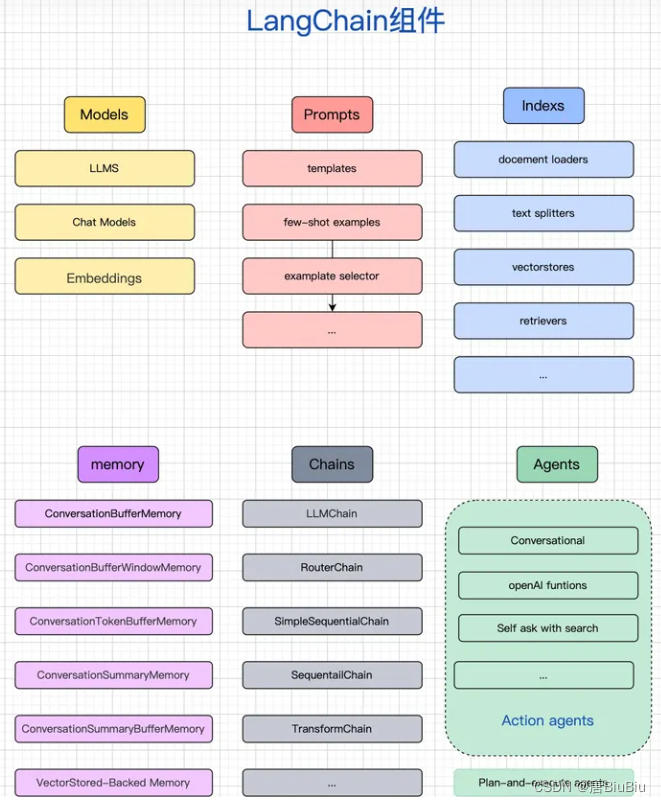
导入csv文件表头字符串出现zwnbsp字符(零宽度空白字符)处理
- 【1】现象描述
- 【2】问题分析
- 【3】原因分析
- 【4】问题解决
- (1)修改文件的编码格式
- (2)在代码中处理
【1】现象描述
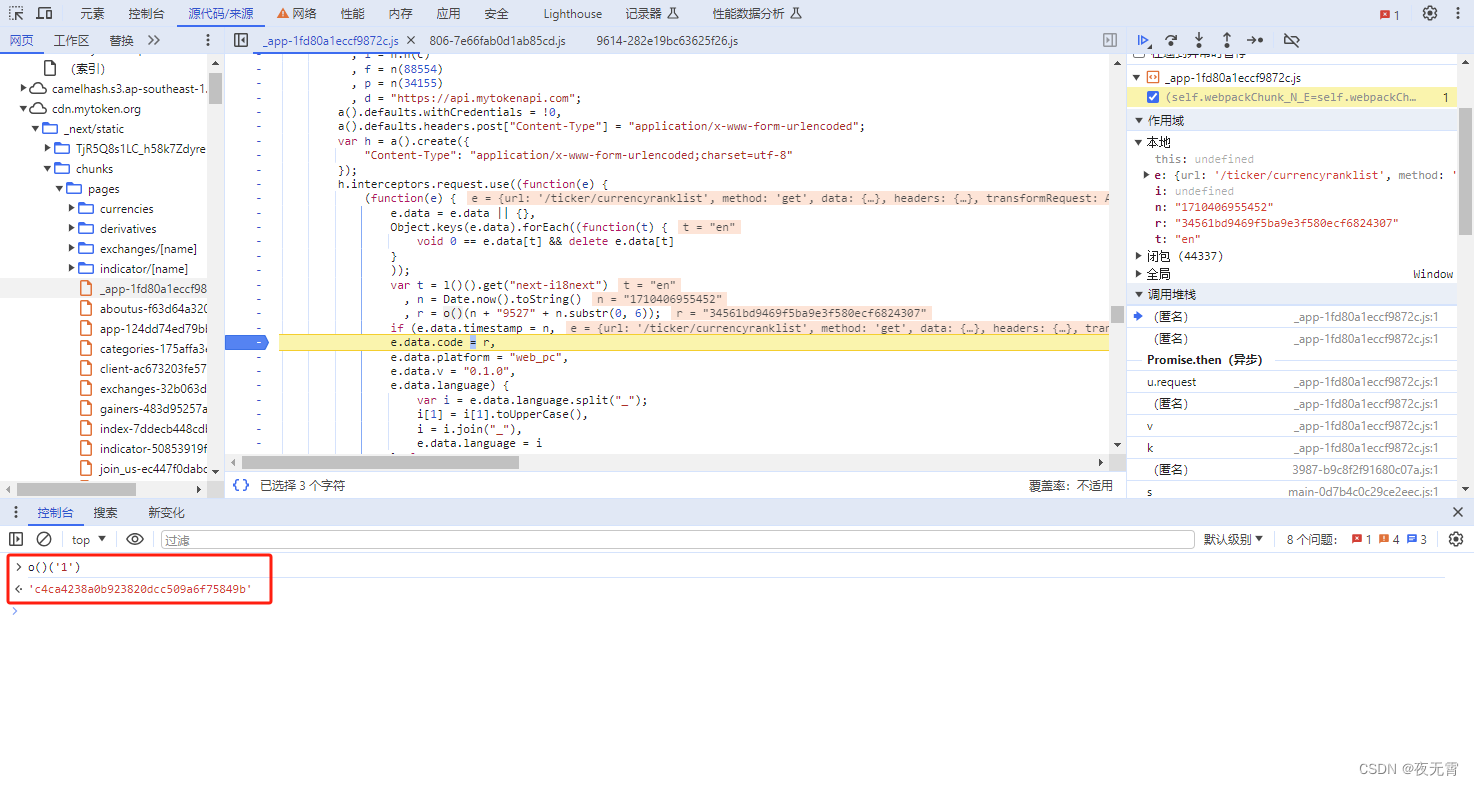
通过easyexcel导入csv文件,并且对表头进行校验。取出解析结果集的第一行,并且截取出了表头的英文名称,然后判断英文名称在字段列表中是否存在。第一个英文名称为“AC_BAL”,而字段列表明明有这个值,但是匹配结果却是空的。
【2】问题分析
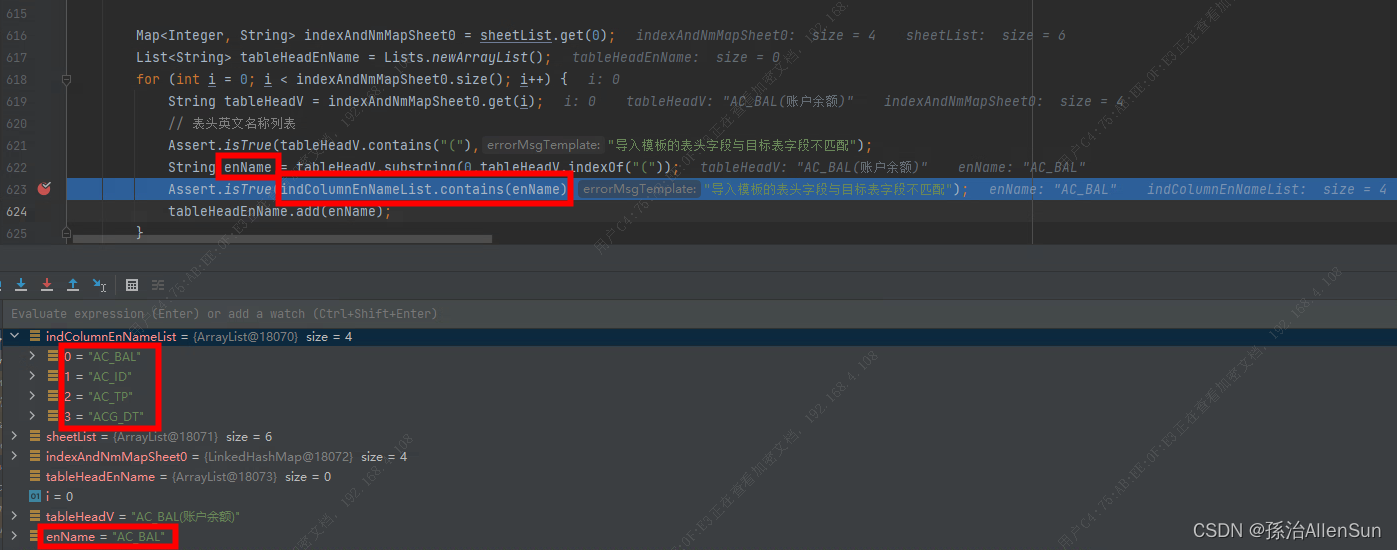
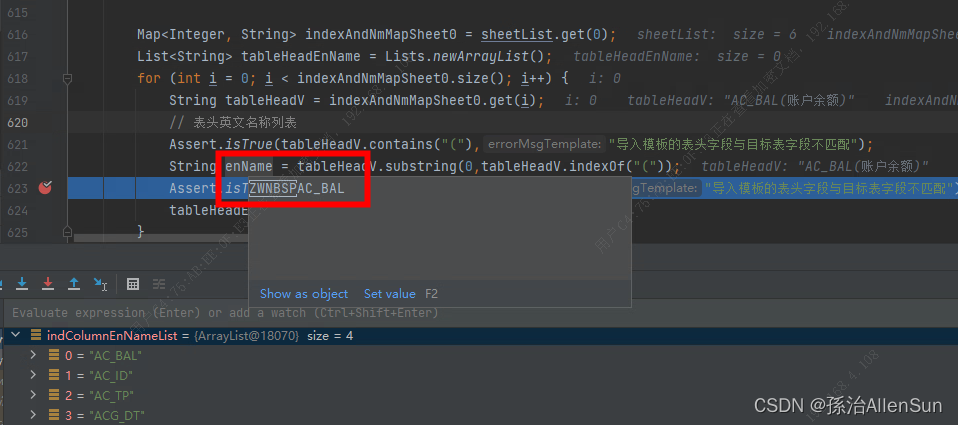
既然匹配不上,就不能仅靠肉眼去观察了,要把判断交给代码,在debug页面对字符串进行判断,判断结果true,那说明不是字段列表的问题,而是enName字段的问题了

查看enName,发现字符串前端多了一部分内容【ZWNBSP】,所以在字段列表里匹配不到这个值
【3】原因分析
该CSV文件的编码格式是 带有UTF-8-BOM,它与我们常用的UTF-8编码格式不同;区别就是在有没有BOM。即文件的开头有没有 UFEFF。这样就会造成生成数组的第一个元素,无法进行判断匹配。
ZWNBSP是"zero-width no-break space (ZWNBSP)"的字符。会以 “\UFEFF”作为字符串的开头;因此就可以解释清楚为什么数组的第一个元素为什么匹配不上。只需要去掉 ZWNBSP即可正确的匹配
【4】问题解决
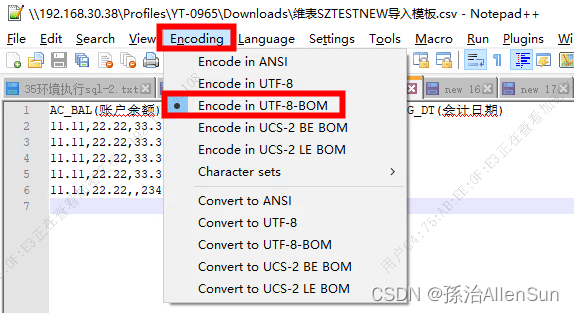
(1)修改文件的编码格式
使用notepad++打开文件,把编码格式改成UTF-8
(2)在代码中处理
public static final String UTF8_BOM="\uFEFF";
String rowMessage =header[j];
if(rowMessage.startsWith(UTF8_BOM)) {
rowMessage=rowMessage.substring(1);
}