大语言模型RAG-langchain models (二)
往期文章:大语言模型RAG-技术概览 (一)
文章目录
- 大语言模型RAG-langchain models (二)
- **往期文章:[大语言模型RAG-技术概览 (一)](https://blog.csdn.net/tangbiubiu/article/details/136651625)**
- 核心模块总览
- Models
- LLMs
- chat
- Embedding
核心模块总览
langchain的核心模块(Modules)如下图所示。
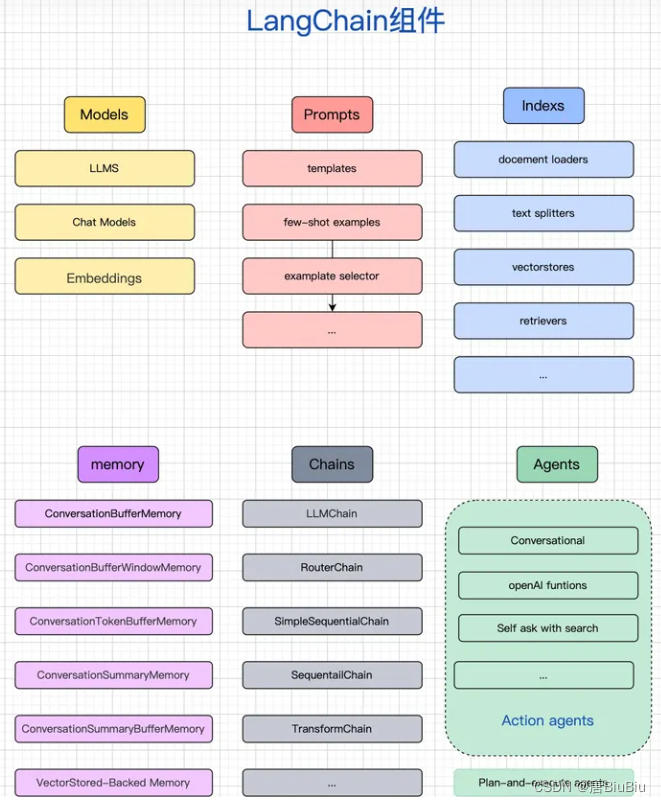
图片来自网络
-
models是语言模型的接口,是所有应用的核心。 -
prompts是构建提示词工程的接口,一般prompts的输出是models的输入,所以根据语言模型的不同,提示词工程也有不同的构造方法。 -
indexs是构造文档的方法,以便语言模型能与文档交互。这里的文档一般是指非结构化的文档,如文本文档,PDF等等。 -
memory使语言模型在聊天中记住先前的交互,使每条对话具有上下文联系。 -
chains为调用多种工具相互串联提供了标准接口。 -
agents有些应用需要根据用户输入来构造chain,它可以大大的提高chain的灵活性。
今天主要介绍models
Models
在介绍之前,先说设置API KEY的方法。
一劳永逸的方法是写在环境变量里:
export OPENAI_API_KEY="..."
在脚本中添加,源码中给出的Example:
import os
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_BASE"] = "https://<your-endpoint.openai.azure.com/"
os.environ["OPENAI_API_KEY"] = "your AzureOpenAI key"
os.environ["OPENAI_API_VERSION"] = "2023-05-15"
os.environ["OPENAI_PROXY"] = "http://your-corporate-proxy:8080"
在调用供应商提供的模型时,也可以在参数中设置API KEY,如:
from langchain_community.chat_models import ChatZhipuAI
zhipuai_chat = ChatZhipuAI(
temperature=0.5,
api_key="xxx", # 在这里传入KEY
model="chatglm_turbo",
)
models 一般是大模型供应商提供的大语言模型,langchain为不同的模型作了接口。主要分为三类:
LLMs
输入和输出都是字符串。封装在langchain.llms中。可以使用下面的属性获取LLMs列表.
>>> from langchain import llms
>>> llms.__all__
['AI21', 'AlephAlpha', 'AmazonAPIGateway', 'Anthropic', 'Anyscale',
'Arcee', 'Aviary', 'AzureMLOnlineEndpoint', 'AzureOpenAI', 'Banana',
'Baseten', 'Beam', 'Bedrock', 'CTransformers', 'CTranslate2', 'CerebriumAI',
'ChatGLM', 'Clarifai', 'Cohere', 'Databricks', 'DeepInfra', 'DeepSparse',
'EdenAI', 'FakeListLLM', 'Fireworks', 'ForefrontAI', 'GigaChat', 'GPT4All',
'GooglePalm', 'GooseAI', 'GradientLLM', 'HuggingFaceEndpoint', 'HuggingFaceHub',
'HuggingFacePipeline', 'HuggingFaceTextGenInference', 'HumanInputLLM',
'KoboldApiLLM', 'LlamaCpp', 'TextGen', 'ManifestWrapper', 'Minimax',
'MlflowAIGateway', 'Modal', 'MosaicML', 'Nebula', 'NIBittensorLLM', 'NLPCloud',
'Ollama', 'OpenAI', 'OpenAIChat', 'OpenLLM', 'OpenLM', 'PaiEasEndpoint',
'Petals', 'PipelineAI', 'Predibase', 'PredictionGuard', 'PromptLayerOpenAI',
'PromptLayerOpenAIChat', 'OpaquePrompts', 'RWKV', 'Replicate', 'SagemakerEndpoint',
'SelfHostedHuggingFaceLLM', 'SelfHostedPipeline', 'StochasticAI', 'TitanTakeoff',
'TitanTakeoffPro', 'Tongyi', 'VertexAI', 'VertexAIModelGarden', 'VLLM',
'VLLMOpenAI', 'WatsonxLLM', 'Writer', 'OctoAIEndpoint', 'Xinference',
'JavelinAIGateway', 'QianfanLLMEndpoint', 'YandexGPT', 'VolcEngineMaasLLM']
假设你要使用OpenAI,仅需三行即可调用(前提是你有api key):
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-ada-001", n=2, best_of=2)
llm("Tell me a joke")
' Why did the chicken cross the road? To get to the other side.'
也可以使用列表调用:
llm_result = llm.generate(["Tell me a joke", "Tell me a poem"])
llm_result.generations
[Generation(text=' Why did the chicken cross the road? To get to the other side!'),
Generation(text=' Why did the chicken cross the road? To get to the other side.')]
调用之后可以查询llm模型提供的信息(不同的llm可能会提供不同的信息):
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
因为大多数api是按照tekon收费的,所以查看一段文本的token数很有意义:
llm.get_num_tokens("what a joke")
3
chat
第二类model是聊天模型,虽然它是llm的包装,但它的接口基于消息而不是文本。
还是用.__all__方法可以获取聊天模型列表:
>>> langchain_community.chat_models.__all__
[
"LlamaEdgeChatService",
"ChatOpenAI",
#...
#省略若干行
#...
"ChatYuan2",
"ChatZhipuAI",
]
使用中文聊天模型的实例:
>>> from langchain_community.chat_models import ChatZhipuAI
>>> from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
>>> zhipu_api_key = 'your apikey'
# 定义聊天模型。不同聊天模型的参数可能不同,请参照源码,后面会贴出一部分源码。
# 在模型定义中有流式输出的参数,可参照源码。
>>> chat = ChatZhipuAI(
... temperature=0.5,
... api_key=zhipu_api_key,
... model="chatglm_turbo",
... )
# 定义聊天信息。以下的格式可以作为所有chat model的输入,langchain已经把接口统一了。
>>> messages = [
... AIMessage(content="你好。"),
... SystemMessage(content="你是一个知识渊博,耐心的导师。"),
... HumanMessage(content='牛顿定律是什么?'),
... ]
>>> response = chat(messages)
>>> response.content # 这里的response是AIMessage对象
"牛顿定律是...." #输出省略
'''
messages也可以批量处理,将多个信息组成二维列表即可,模型的输出会是对应的列表形式
'''
batch_messages = [
[
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
],
[
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love artificial intelligence.")
],
]
result = chat.generate(batch_messages)
# 这里的result是LLMResult对象,除了记录了输入和输出以外,还有诸如token使用量等统计
result.llm_outpuy # 查看token统计
在打造专有大模型时,我们常常要使用提示词模板,langchain还贴心的准备了相应的接口,请看官网给出的示例:
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# get a chat completion from the formatted messages
chat(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
# 输出
AIMessage(content="J'adore la programmation.", additional_kwargs={})
# 或者更直接的构建MessagePromptTemplate
prompt=PromptTemplate(
template="You are a helpful assistant that translates {input_language} to {output_language}.",
input_variables=["input_language", "output_language"],
)
system_message_prompt = SystemMessagePromptTemplate(prompt=prompt)
不同的聊天模型怎么使用建议直接看源码,源码的注释可以说是非常友好了。下面贴一段ChatZhipuAI的源码浅浅感受一下:
class ChatZhipuAI(BaseChatModel):
"""
`ZHIPU AI` large language chat models API.
To use, you should have the ``zhipuai`` python package installed.
Example:
.. code-block:: python
from langchain_community.chat_models import ChatZhipuAI
zhipuai_chat = ChatZhipuAI(
temperature=0.5,
api_key="your-api-key",
model="chatglm_turbo",
)
"""
zhipuai: Any
zhipuai_api_key: Optional[str] = Field(default=None, alias="api_key")
"""Automatically inferred from env var `ZHIPUAI_API_KEY` if not provided."""
model: str = Field("chatglm_turbo")
"""
Model name to use.
-chatglm_turbo:
According to the input of natural language instructions to complete a
variety of language tasks, it is recommended to use SSE or asynchronous
call request interface.
-characterglm:
It supports human-based role-playing, ultra-long multi-round memory,
and thousands of character dialogues. It is widely used in anthropomorphic
dialogues or game scenes such as emotional accompaniments, game intelligent
NPCS, Internet celebrities/stars/movie and TV series IP clones, digital
people/virtual anchors, and text adventure games.
"""
temperature: float = Field(0.95)
"""
What sampling temperature to use. The value ranges from 0.0 to 1.0 and cannot
be equal to 0.
The larger the value, the more random and creative the output; The smaller
the value, the more stable or certain the output will be.
You are advised to adjust top_p or temperature parameters based on application
scenarios, but do not adjust the two parameters at the same time.
"""
top_p: float = Field(0.7)
"""
Another method of sampling temperature is called nuclear sampling. The value
ranges from 0.0 to 1.0 and cannot be equal to 0 or 1.
The model considers the results with top_p probability quality tokens.
For example, 0.1 means that the model decoder only considers tokens from the
top 10% probability of the candidate set.
You are advised to adjust top_p or temperature parameters based on application
scenarios, but do not adjust the two parameters at the same time.
"""
request_id: Optional[str] = Field(None)
"""
Parameter transmission by the client must ensure uniqueness; A unique
identifier used to distinguish each request, which is generated by default
by the platform when the client does not transmit it.
"""
streaming: bool = Field(False)
"""Whether to stream the results or not."""
incremental: bool = Field(True)
"""
When invoked by the SSE interface, it is used to control whether the content
is returned incremented or full each time.
If this parameter is not provided, the value is returned incremented by default.
"""
return_type: str = Field("json_string")
"""
This parameter is used to control the type of content returned each time.
- json_string Returns a standard JSON string.
- text Returns the original text content.
"""
ref: Optional[ref] = Field(None)
"""
This parameter is used to control the reference of external information
during the request.
Currently, this parameter is used to control whether to reference external
information.
If this field is empty or absent, the search and parameter passing format
is enabled by default.
{"enable": "true", "search_query": "history "}
"""
# 省略一万行...
Embedding
最后一类是文本嵌入模型(text-embedding-model)
从原理上来看,嵌入模型与以上的两种模型有本质不同。嵌入模型的思路是将字符串组成的空间映射到嵌入空间,这个嵌入空间是一个连续向量空间,且嵌入空间与原本的字符空间是同构的。这样做的目的有两点:
- 嵌入空间可以降维和升维,可以更好的提取语义特征。
- 连续向量空间的数学工具更多,可以更好的应用分类、预测、搜索等算法。比如前文的知识库搜索中用到的向量相似度就是利用连续向量空间中的距离来进行搜索的方法。
本文的重点不在原理上,原理的细节可自行搜索。知道Embedding模型在知识库中的作用即可:一方面知识库中的文档是以embedding的形式储存在向量库;另一方面是llm模型在检索知识库时是在embedding空间进行的,具体来说是用户的query和向量库进行向量相似度的计算,最终得出结果。
依然可以用__all__属性查看供应商提供的所有embedding。
>>> import langchain
>>> langchain.embeddings.__all__
使用方法官方示例:
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])