目录
一、⽀持向量机(SVM)算法
1 SVM算法导⼊
2 SVM算法定义
2.1 定义
2.2 超平⾯最⼤间隔介绍
2.3 硬间隔和软间隔
2.3.1 硬间隔分类
2.3.2 软间隔分类
3 ⼩结
二、 SVM算法api初步使⽤
三、 SVM算法原理
1 定义输⼊数据
2 线性可分⽀持向量机
3 SVM的计算过程与算法步骤
3.1 推导⽬标函数
3.2 ⽬标函数的求解
3.2.1 拉格朗⽇乘⼦法
3.2.2 对偶问题
3.2.3 整体流程确定
4 举例
5 ⼩结
四、 SVM的损失函数
1 SVM的主要三种损失函数
2 ⼩结
五、 SVM的核⽅法
1 什么是核函数
1.1 核函数概念
1.2 核函数举例
1.2.1 核⽅法举例1:
1.2.2 核⽅法举例2:
2 常⻅核函数
2.1 常⻅核函数介绍
2.2 核函数指导选用规则
3 ⼩结
六、SVM回归
七、 SVM算法api再介绍
1 SVM算法api综述
2 SVC
3 NuSVC
4 LinearSVC
5 ⼩结
八、 SVM总结
1 SVM基本综述
2 SVM优缺点
一、⽀持向量机(SVM)算法
- 了解什么是SVM算法
- 掌握SVM算法的原理
- 知道SVM算法的损失函数
- 知道SVM算法的核函数
- 了解SVM算法在回归问题中的使⽤
- 应⽤SVM算法实现⼿写数字识别器
1 SVM算法导⼊
引例:⽤⼀根棍子分开两种颜⾊的球,要求:尽量在放更多球之后,仍然适⽤。 首先很容易区分两种颜色的球
首先很容易区分两种颜色的球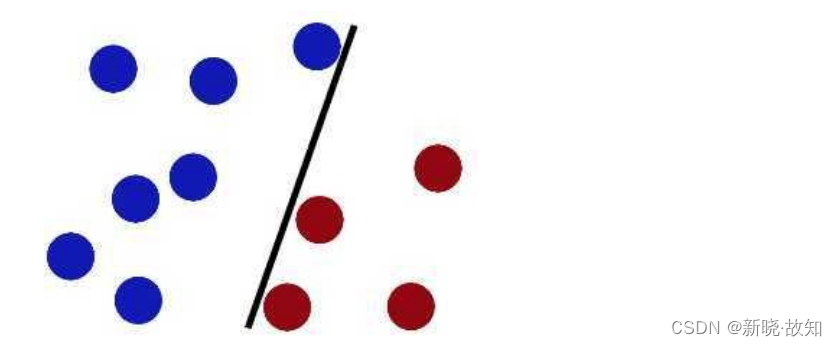 然后继续增多球的数量
然后继续增多球的数量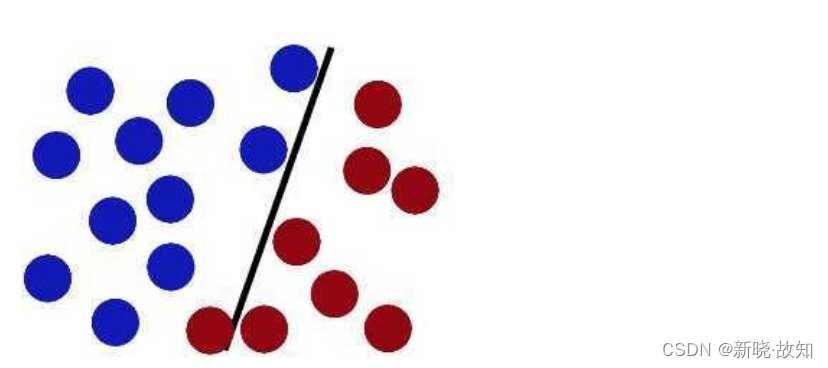 此时,已经有 ⼀个球无法使用一根棍子直接隔开,那么该如何做呢?SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能⼤的间隙。把区分使用的棍子变粗!
此时,已经有 ⼀个球无法使用一根棍子直接隔开,那么该如何做呢?SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能⼤的间隙。把区分使用的棍子变粗!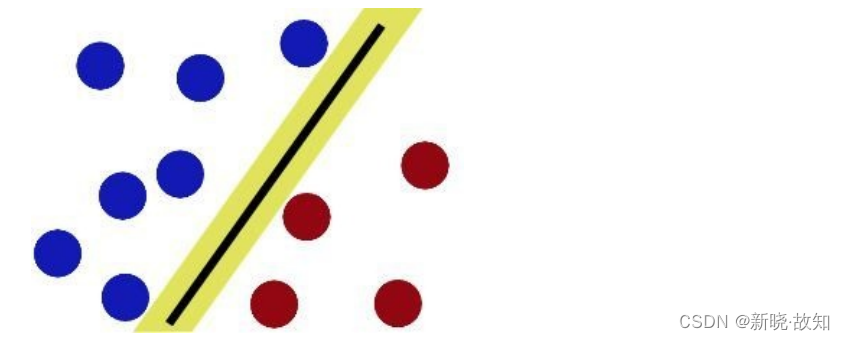 现在即使放了更多的球,棍仍然是⼀个好的分界线。但是遇到其他情况呢?
现在即使放了更多的球,棍仍然是⼀个好的分界线。但是遇到其他情况呢? 从低维上升到高维!
从低维上升到高维!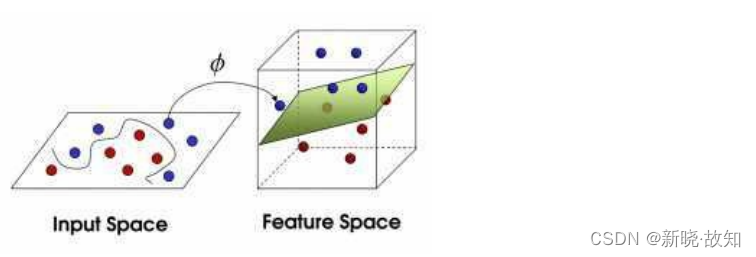
 把上⾯的物体起了别名:球 —— 「 data 」数据棍⼦ —— 「 classifier 」分类最⼤间隙 —— 「 optimization 」最优化低维到高维—— 「 kernelling 」核⽅法高维中区分的平面—— 「 hyperplane 」超平⾯SVM直观感受:
把上⾯的物体起了别名:球 —— 「 data 」数据棍⼦ —— 「 classifier 」分类最⼤间隙 —— 「 optimization 」最优化低维到高维—— 「 kernelling 」核⽅法高维中区分的平面—— 「 hyperplane 」超平⾯SVM直观感受: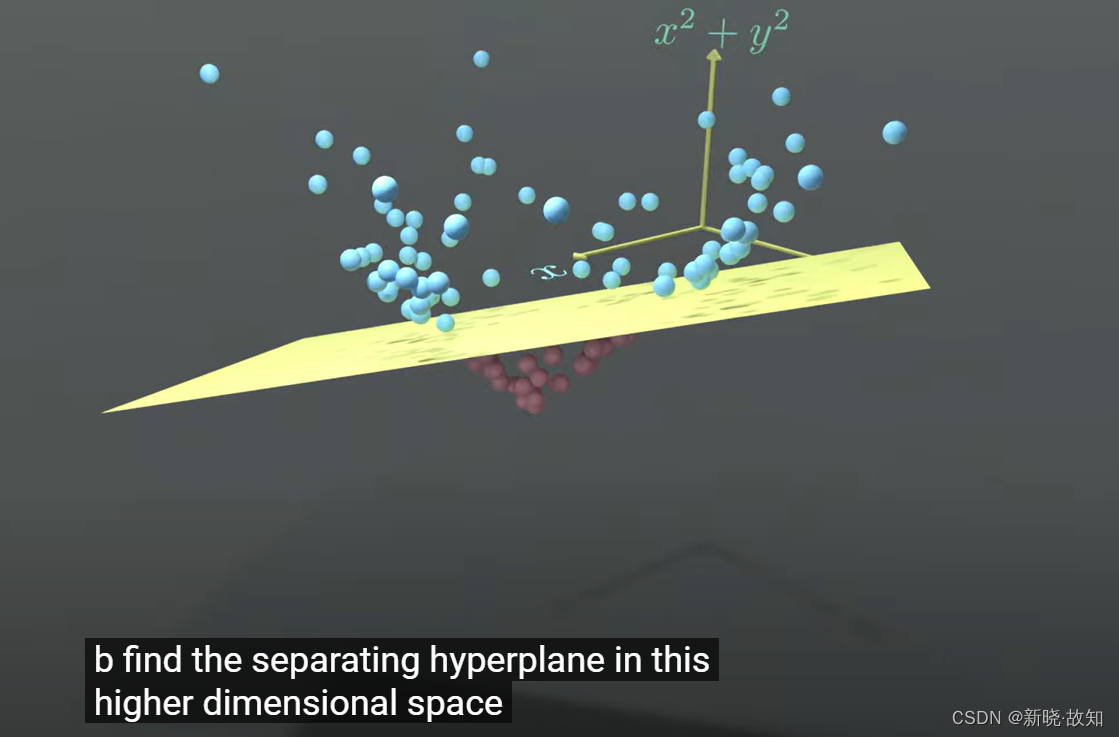
2 SVM算法定义
2.1 定义
SVM : SVM 全称是 supported vector machine (⽀持向量机),即寻找到⼀个超平⾯使样本分成两类,并且间隔最 ⼤。
SVM 能够执⾏线性或⾮线性分类、回归,甚⾄是异常值检测任务。它是机器学习领域最受欢迎的模型之⼀。 SVM 特别适⽤于中⼩型复杂数据集的分类。
2.2 超平⾯最⼤间隔介绍
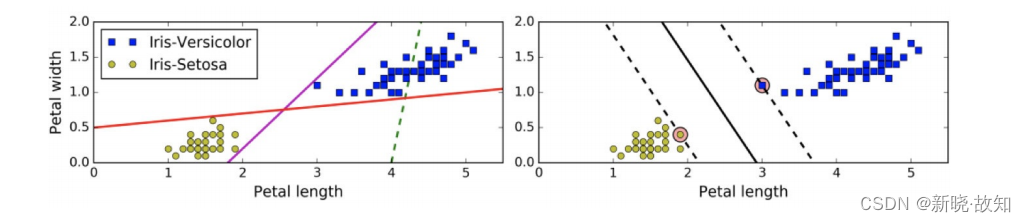
上左图显示了三种可能的线性分类器的决策边界:虚线所代表的模型表现⾮常糟糕,甚⾄都⽆法正确实现分类。其余两个模型在这个训练集上表现堪称完美,但是 它们的 决策边界与实例过于接近,导致在⾯对新实例时,表现可能不会太好 。右图中的实线代表 SVM 分类器的决策边界 ,不仅分离了两个类别,且 尽可能远离最近的训练实例 。
2.3 硬间隔和软间隔
2.3.1 硬间隔分类
在上⾯我们使⽤超平⾯进⾏分割数据的过程中,如果我们严格地让所有实例都不在最⼤间隔之间,并且位于正确的⼀边,这就是硬间隔分类。硬间隔分类有两个问题 ,⾸先,它只在 数据是线性可分离的时候才有效 ;其次, 它对异常值⾮常敏感 。当有⼀个额外异常值的鸢尾花数据:左图的数据根本找不出硬间隔,⽽右图最终显示的决策边界与我们之前所看到的⽆异常值时的决策边界也⼤不相同,可能⽆法很好地泛化。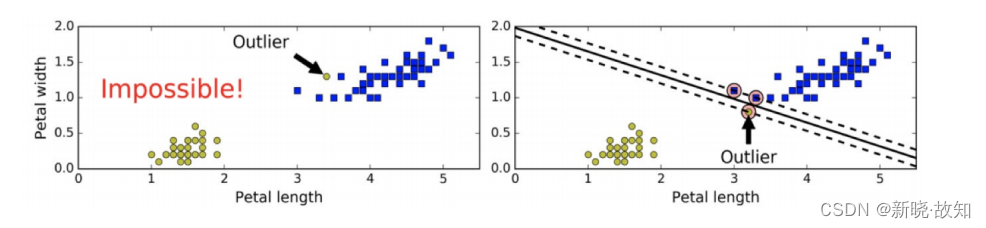
2.3.2 软间隔分类
要避免这些问题,最好使⽤更灵活的模型。 ⽬标是尽可能在保持最⼤间隔宽阔和限制间隔违例(即位于最⼤间隔之上, 甚⾄在错误的⼀边的实例)之间找到良好的平衡 ,这就是软间隔分类。要避免这些问题,最好使⽤更灵活的模型。⽬标是尽可能在保持间隔宽阔和限制间隔违例之间找到良好的平衡,这就是软间隔分类。 在 Scikit-Learn 的 SVM 类中,可以通过超参数 C 来控制这个平衡: C 值越⼩,则间隔越宽,但是间隔违例也会越多。上图显示了在⼀个⾮线性可分离数据集上,两个软间隔SVM 分类器各⾃的决策边界和间隔。左边使⽤了⾼ C 值,分类器的错误样本(间隔违例)较少,但是间隔也较⼩。右边使⽤了低 C 值,间隔⼤了很多,但是位于间隔上的实例也更多。看起来第⼆个分类器的泛化效果更好,因为⼤多数间隔违例实际上都位于决策边界正确的⼀边,所以即便是在该训练集上,它做出的错误预测也会更少。
在 Scikit-Learn 的 SVM 类中,可以通过超参数 C 来控制这个平衡: C 值越⼩,则间隔越宽,但是间隔违例也会越多。上图显示了在⼀个⾮线性可分离数据集上,两个软间隔SVM 分类器各⾃的决策边界和间隔。左边使⽤了⾼ C 值,分类器的错误样本(间隔违例)较少,但是间隔也较⼩。右边使⽤了低 C 值,间隔⼤了很多,但是位于间隔上的实例也更多。看起来第⼆个分类器的泛化效果更好,因为⼤多数间隔违例实际上都位于决策边界正确的⼀边,所以即便是在该训练集上,它做出的错误预测也会更少。
3 ⼩结
- SVM算法定义
寻找到⼀个超平⾯使样本分成两类,并且间隔最⼤。
- 硬间隔和软间隔
硬间隔只有在数据是线性可分离的时候才有效对异常值⾮常敏感软间隔尽可能在保持最⼤间隔宽阔和限制间隔违例之间找到良好的平衡
二、 SVM算法api初步使⽤
>>> from sklearn import svm >>> X = [[0, 0], [1, 1]] >>> y = [0, 1] >>> clf = svm.SVC() >>> clf.fit(X, y) SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)在拟合后 , 这个模型可以⽤来预测新的值 :>>> clf.predict([[2., 2.]]) array([1])
三、 SVM算法原理
- 知道SVM中线性可分⽀持向量机
- 知道SVM中⽬标函数的推导过程
- 了解拉格朗⽇乘⼦法、对偶问题
- 知道SVM中⽬标函数的求解过程
1 定义输⼊数据

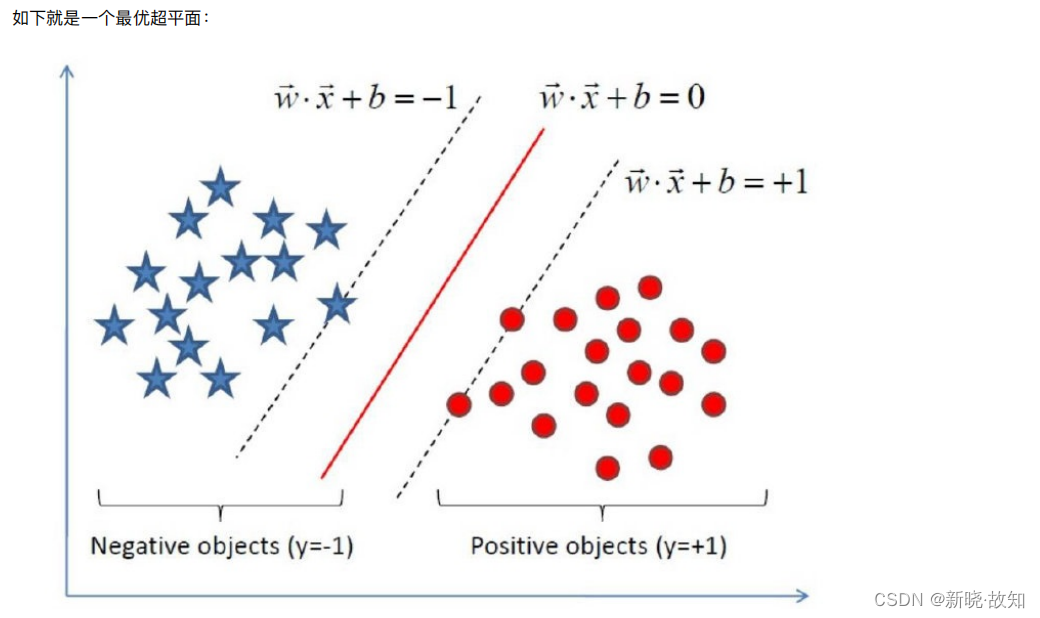
2 线性可分⽀持向量机
⼜⽐如说这样:


3 SVM的计算过程与算法步骤
3.1 推导⽬标函数



3.2 ⽬标函数的求解
到这⼀步,终于把⽬标函数给建⽴起来了。那么下⼀步⾃然是去求⽬标函数的最优值 .因为⽬标函数带有⼀个约束条件,所以 我们可以⽤拉格朗⽇乘⼦法求解 。3.2.1 拉格朗⽇乘⼦法
拉格朗⽇乘⼦法 (Lagrange multipliers) 是 ⼀种寻找多元函数在⼀组约束下的极值的⽅法 .通过引⼊拉格朗⽇乘⼦,可将有 d 个变量与 k 个约束条件的最优化问题转化为具有 d + k 个变量的⽆约束优化问题求解。这里希望通过⼀个直观简单的例⼦尽⼒解释拉格朗⽇乘⼦法和 KKT 条件的原理。
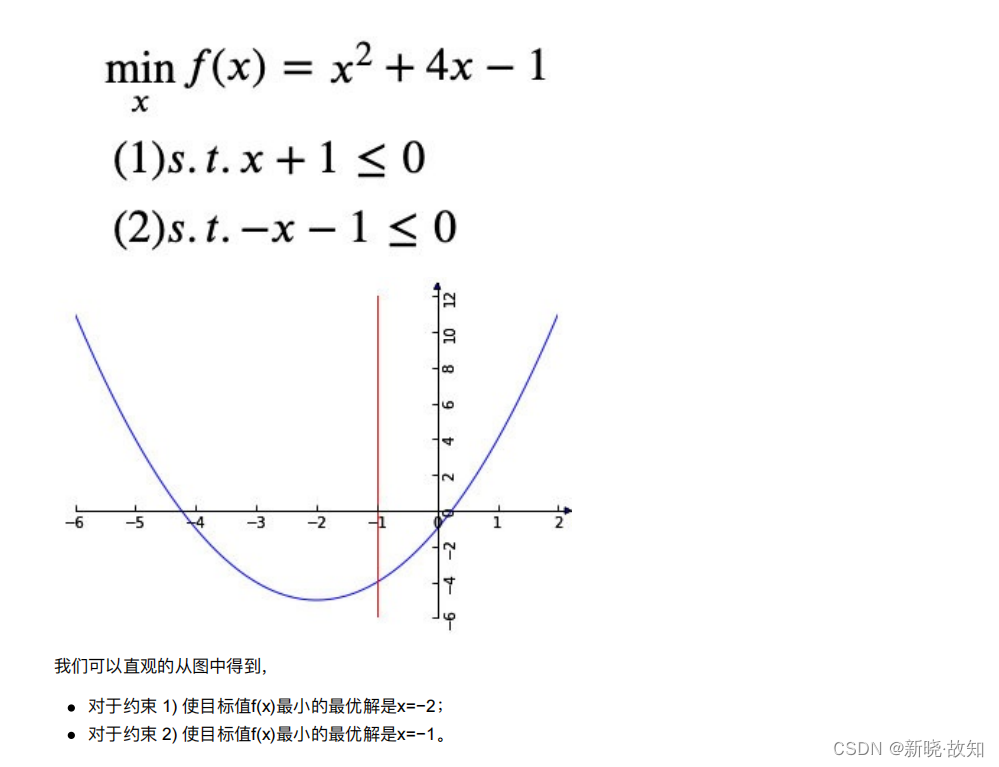 下⾯我们⽤拉格朗⽇乘⼦来求解这个最优解。
下⾯我们⽤拉格朗⽇乘⼦来求解这个最优解。

3.2.2 对偶问题
我们要将其转换为
对偶问题
,变成极⼤极⼩值问题:
从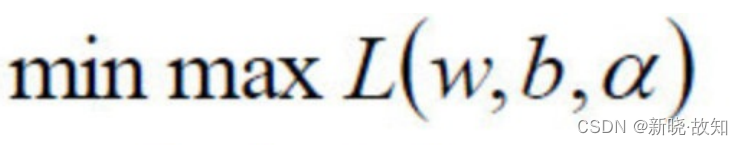 变为:
变为: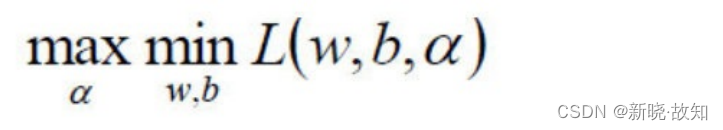

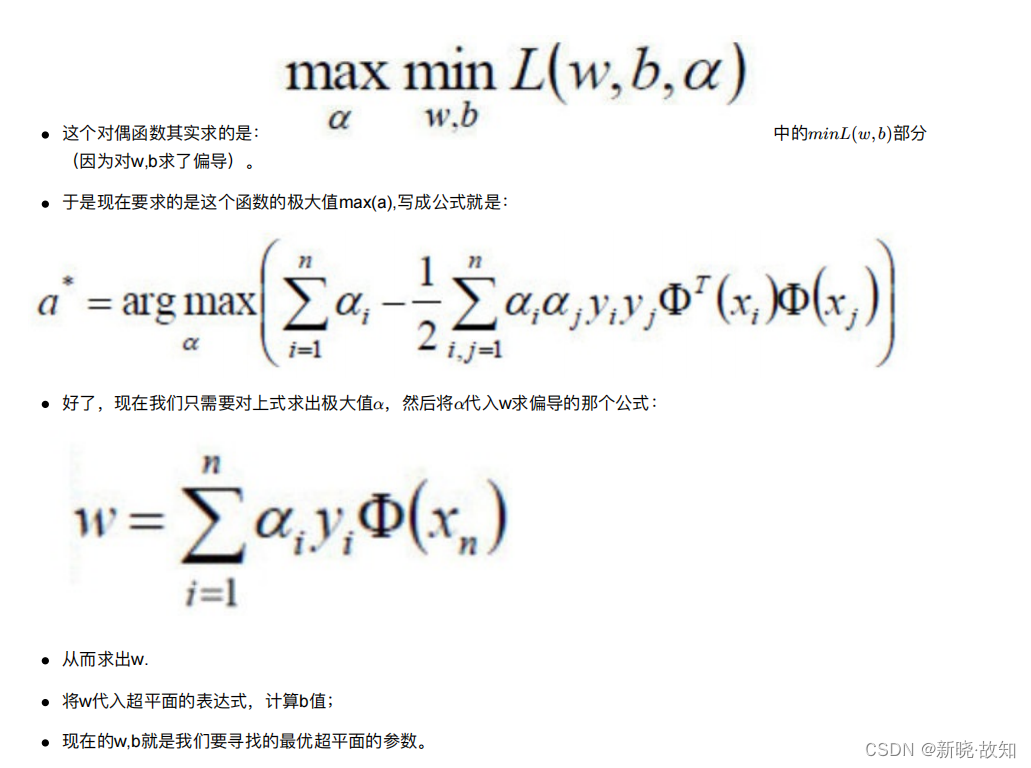
3.2.3 整体流程确定
我们⽤数学表达式来说明上⾯的过程:

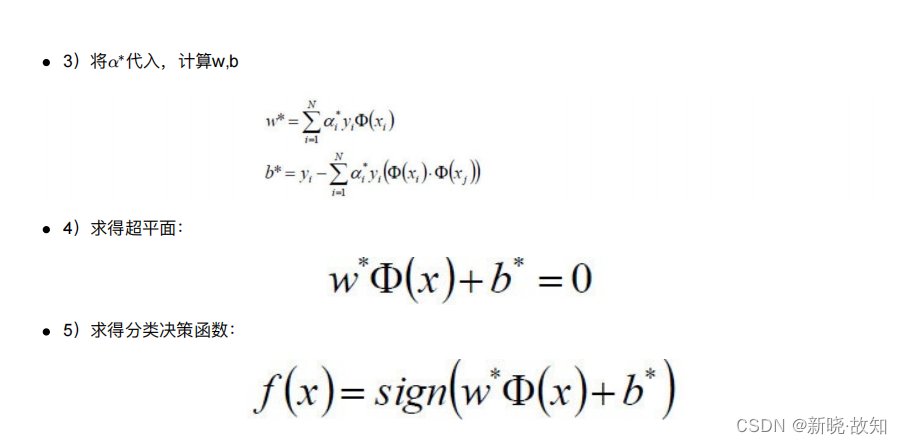
4 举例

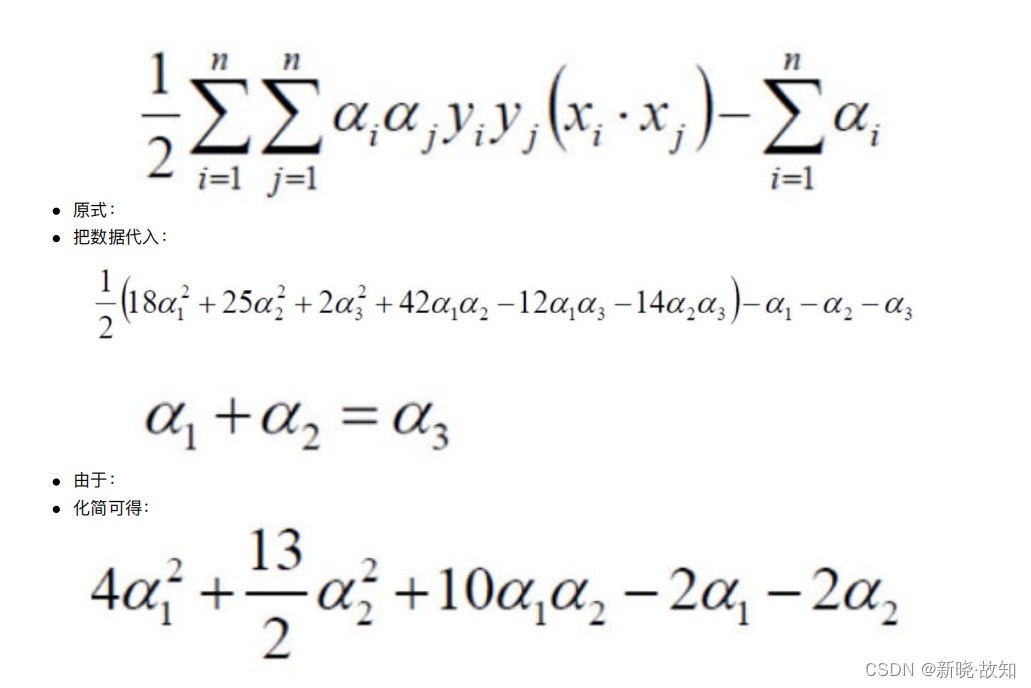


5 ⼩结

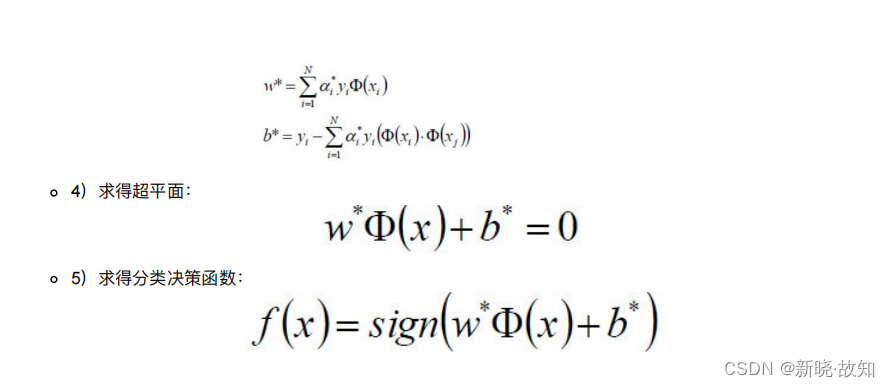
四、 SVM的损失函数
- 了解SVM的损失函数
- 知道SVM中的Hinge损失函数
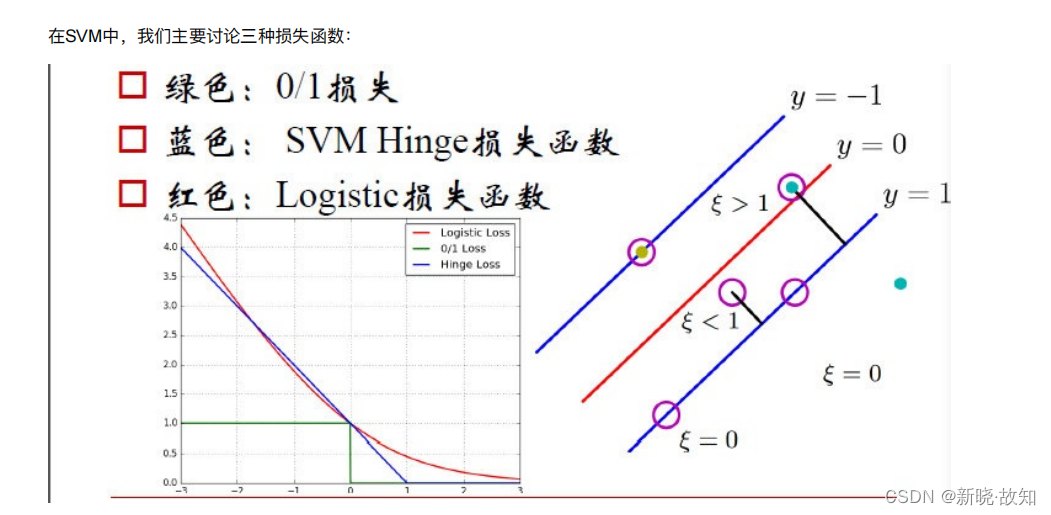
1 SVM的主要三种损失函数

2 ⼩结
SVM的损失函数
- 0/1损失函数
- Hinge损失函数
- Logistic损失函数
五、 SVM的核⽅法
- 知道SVM的核⽅法
- 了解常⻅的核函数
【
SVM +
核函数】 具有极⼤威⼒。
核函数并不是
SVM
特有的,核函数可以和其他算法也进⾏结合,只是核函数与
SVM
结合的优势⾮常⼤。
1 什么是核函数
1.1 核函数概念
核函数,是将原始输⼊空间映射到新的特征空间,从⽽,使得原本线性不可分的样本可能在核空间可分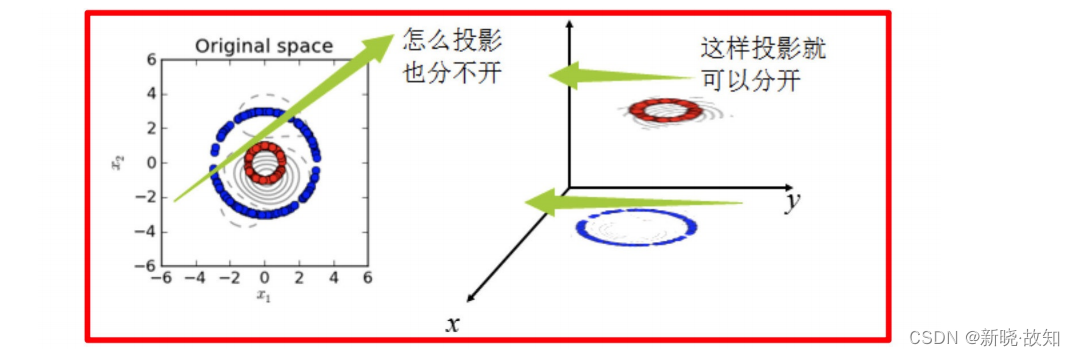
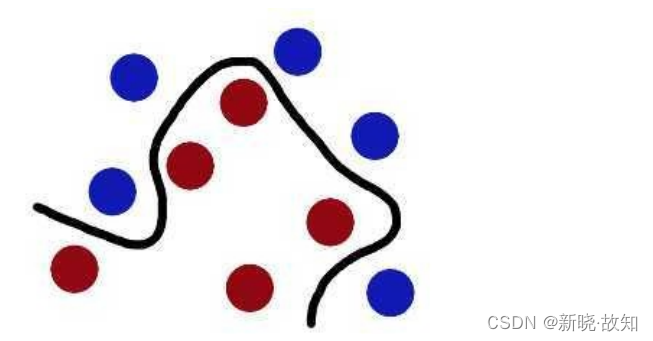
下图所示的两类数据,分别分布为两个圆圈的形状,这样的数据本身就是线性不可分的,此时该如何把这两类数据分开呢?
1.2 核函数举例
1.2.1 核⽅法举例1:
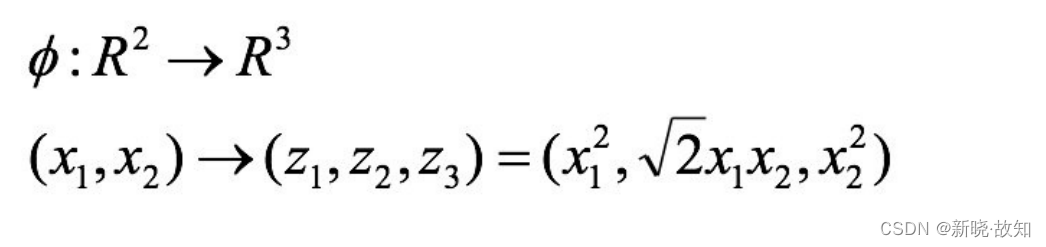
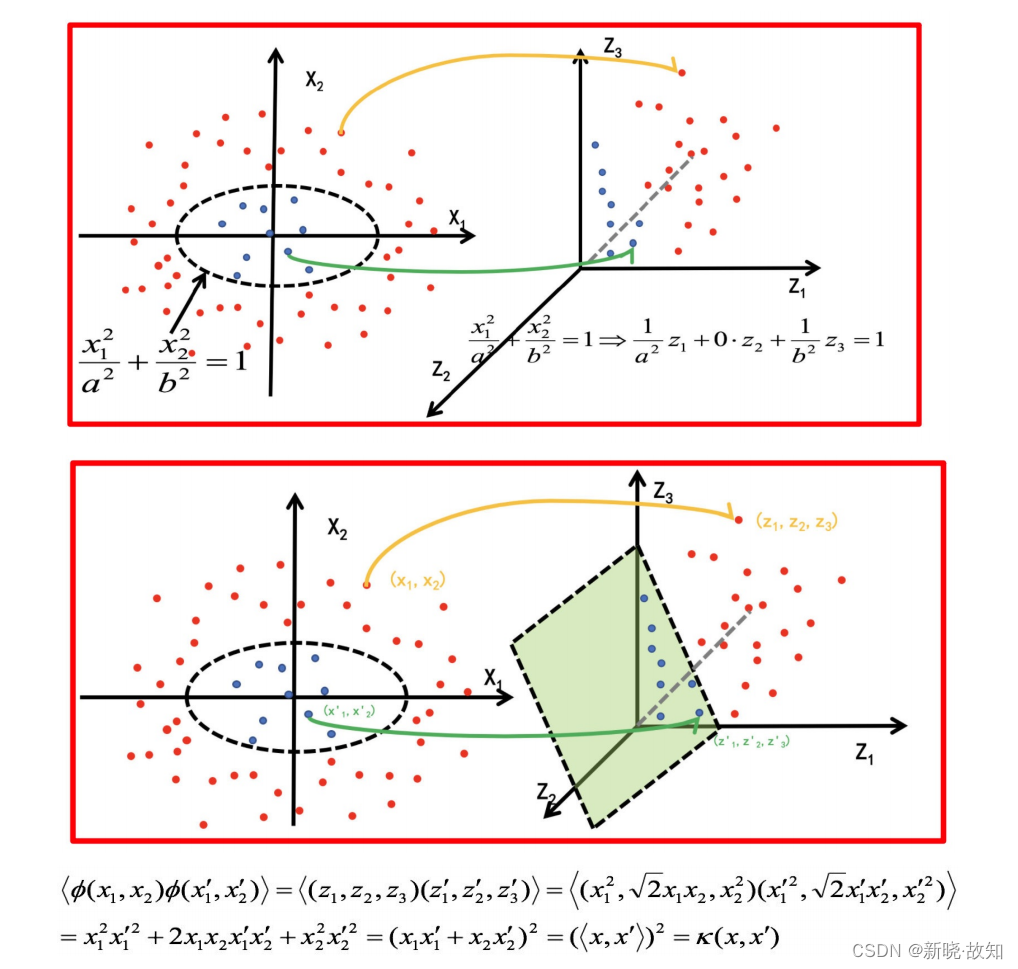

1.2.2 核⽅法举例2:
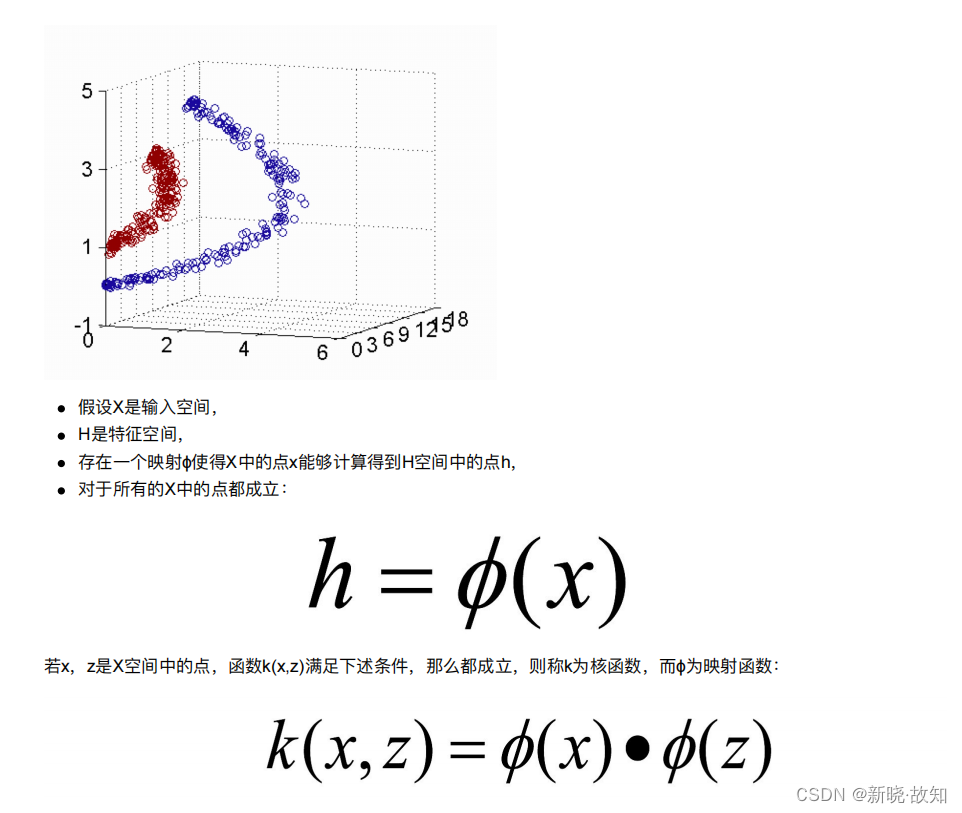
- 下⾯这张图位于第⼀、⼆象限内。我们关注红⾊的⻔,以及“北京四合院”这⼏个字和下⾯的紫⾊的字⺟。
- 我们把红⾊的⻔上的点看成是“+”数据,字⺟上的点看成是“-”数据,它们的横、纵坐标是两个特征。
- 显然,在这个⼆维空间内,“+”“-”两类数据不是线性可分的。

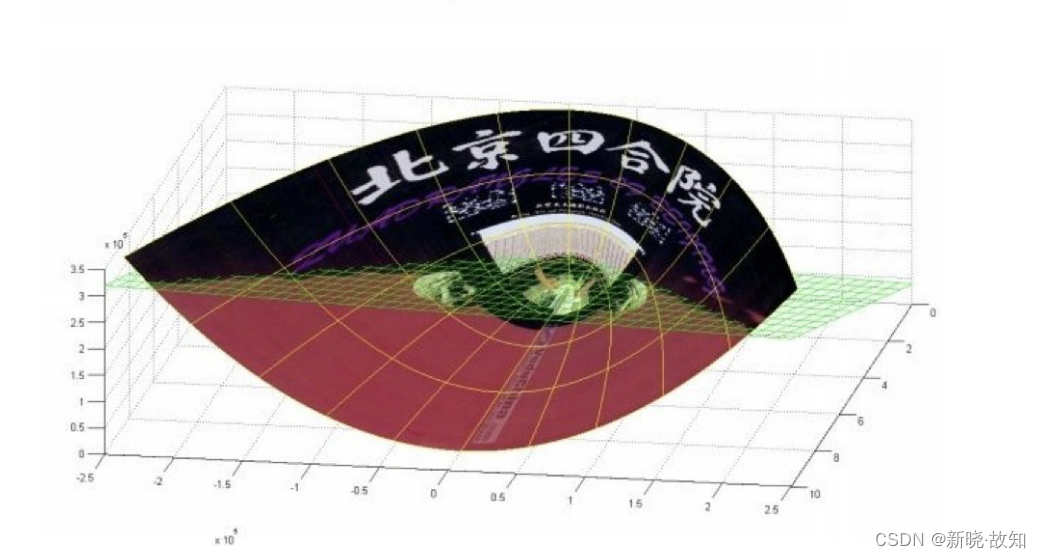 (前后轴为x轴,左右轴为y轴,上下轴为z轴)
(前后轴为x轴,左右轴为y轴,上下轴为z轴)
- 绿⾊的平⾯可以完美地分割红⾊和紫⾊,两类数据在三维空间中变成线性可分的了。
- 三维中的这个判决边界,再映射回⼆维空间中:是⼀条双曲线,它不是线性的。
- 核函数的作⽤就是⼀个从低维空间到⾼维空间的映射,⽽这个映射可以把低维空间中线性不可分的两类点变成线性可分的。

2 常⻅核函数
2.1 常⻅核函数介绍
- 线性核和多项式核:
这两种核的作⽤也是⾸先在属性空间中找到⼀些点,把这些点当做base ,核函数的作⽤就是找与该点距离和⻆度满⾜某种关系的样本点。当样本点与该点的夹⻆近乎垂直时,两个样本的欧式⻓度必须⾮常⻓才能保证满⾜线性核函数⼤于0 ;⽽当样本点与base 点的⽅向相同时,⻓度就不必很⻓;⽽当⽅向相反时,核函数值就是负的,被判为反类。即,它在空间上划分出⼀个梭形,按照梭形来进⾏正反类划分。
- RBF核:
⾼斯核函数就是在属性空间中找到⼀些点,这些点可以是也可以不是样本点,把这些点当做base ,以这些base为圆⼼向外扩展,扩展半径即为带宽,即可划分数据。换句话说,在属性空间中找到⼀些超圆,⽤这些超圆来判定正反类。
- Sigmoid核:
同样地是定义⼀些base,核函数就是将线性核函数经过⼀个tanh 函数进⾏处理,把值域限制在了 -1 到 1 上。总之,都是在定义距离,⼤于该距离,判为正,⼩于该距离,判为负。⾄于选择哪⼀种核函数,要根据具体的样本分布情况来确定。
2.2 核函数指导选用规则
1 ) 如果 Feature 的数量很⼤,甚⾄和样本数量差不多时,往往线性可分,这时选⽤ LR 或者线性核 Linear ;2 ) 如果 Feature 的数量很⼩,样本数量正常,不算多也不算少,这时选⽤ RBF 核;3 ) 如果 Feature 的数量很⼩,⽽样本的数量很⼤,这时⼿动添加⼀些 Feature ,使得线性可分,然后选⽤ LR 或者线性核Linear ;4 ) 多项式核⼀般很少使⽤,效率不⾼,结果也不优于 RBF ;5 ) Linear 核参数少,速度快; RBF 核参数多,分类结果⾮常依赖于参数,需要交叉验证或⽹格搜索最佳参数,⽐较耗时;6 )应⽤最⼴的应该就是 RBF 核,⽆论是⼩样本还是⼤样本,⾼维还是低维等情况, RBF 核函数均适⽤。

3 ⼩结
- SVM的核⽅法
将原始输⼊空间映射到新的特征空间,从⽽,使得原本线性不可分的样本可能在核空间可分。
- 常⻅核函数
线性核多项式核RBF核Sigmoid核
六、SVM回归
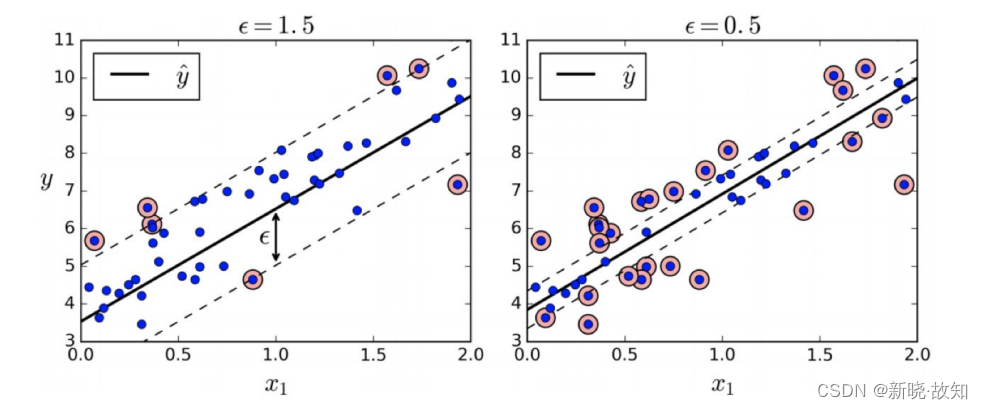
SVM 回归 是让尽可能多的实例位于预测线上,同时限制间隔违例(也就是不在预测线距上的实例)。
线距的宽度由超参数
ε
控制。
七、 SVM算法api再介绍
1 SVM算法api综述
- SVM⽅法既可以⽤于分类(⼆/多分类),也可⽤于回归和异常值检测。
- SVM具有良好的鲁棒性,对未知数据拥有很强的泛化能⼒,特别是在数据量较少的情况下,相较其他传统机器学习算法具有更优的性能。
使⽤SVM作为模型时,通常采⽤如下流程:1. 对样本数据进⾏归⼀化2. 应⽤核函数对样本进⾏映射 (最常采⽤和核函数是 RBF 和 Linear ,在样本线性可分时, Linear 效果要⽐ RBF 好)3. ⽤ cross-validation 和 grid-search 对超参数进⾏优选4. ⽤最优参数训练得到模型5. 测试
sklearn中⽀持向量分类主要有三种⽅法:SVC 、 NuSVC 、 LinearSVC ,扩展为三个⽀持向量回归⽅法: SVR 、 NuSVR、 LinearSVR 。
- SVC和NuSVC⽅法基本⼀致,唯⼀区别就是损失函数的度量⽅式不同
NuSVC中的nu 参数和 SVC 中的 C 参数;
- LinearSVC是实现线性核函数的⽀持向量分类,没有kernel参数。
2 SVC
class sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3,coef0=0.0,random_state=None)
- C: 惩罚系数,⽤来控制损失函数的惩罚系数,类似于线性回归中的正则化系数。
C越⼤,相当于惩罚松弛变量,希望松弛变量接近 0 ,即 对误分类的惩罚增⼤ ,趋向于对训练集全分对的情况,这样会出现训练集测试时准确率很⾼,但泛化能⼒弱,容易导致过拟合。C值⼩,对误分类的惩罚减⼩ ,容错能⼒增强,泛化能⼒较强,但也可能⽋拟合。
- kernel: 算法中采⽤的核函数类型,核函数是⽤来将⾮线性问题转化为线性问题的⼀种⽅法。
参数选择有RBF, Linear, Poly, Sigmoid或者⾃定义⼀个核函数。默认的是"RBF",即径向基核,也就是⾼斯核函数;⽽Linear指的是线性核函数,Poly指的是多项式核,Sigmoid指的是双曲正切函数tanh核;。
- degree:
当指定kernel 为 'poly' 时,表示选择的多项式的最⾼次数,默认为三次多项式;若指定kernel 不是 'poly' ,则忽略,即该参数只对 'poly' 有⽤。多项式核函数是将低维的输⼊空间映射到⾼维的特征空间。
- coef0: 核函数常数值(y=kx+b中的b值),
只有‘poly’ 和 ‘sigmoid’ 核函数有,默认值是 0 。
3 NuSVC
class sklearn.svm.NuSVC(nu=0.5)nu : 训练误差部分的上限和⽀持向量部分的下限,取值在( 0 , 1 )之间,默认是 0.5
4 LinearSVC
class sklearn.svm.LinearSVC(penalty='l2', loss='squared_hinge', dual=True, C=1.0)
- penalty:正则化参数,
L1和L2 两种参数可选,仅 LinearSVC 有。
- loss:损失函数,
有hinge和 squared_hinge 两种可选,前者⼜称 L1 损失,后者称为 L2 损失,默认是 squared_hinge ,其中hinge是 SVM 的标准损失, squared_hinge 是 hinge 的平⽅
- dual:是否转化为对偶问题求解,默认是True。
- C:惩罚系数,
⽤来控制损失函数的惩罚系数,类似于线性回归中的正则化系数。
5 ⼩结
- SVM的核⽅法
将原始输⼊空间映射到新的特征空间,从⽽,使得原本线性不可分的样本可能在核空间可分。
- SVM算法api
sklearn.svm.SVCsklearn.svm.NuSVCsklearn.svm.LinearSVC
八、 SVM总结
1 SVM基本综述
- SVM是⼀种⼆类分类模型。
- 它的基本模型是在特征空间中寻找间隔最⼤化的分离超平⾯的线性分类器。
1)当训练样本线性可分时,通过硬间隔最⼤化,学习⼀个线性分类器,即线性可分⽀持向量机;2)当训练数据近似线性可分时,引⼊松弛变量,通过软间隔最⼤化,学习⼀个线性分类器,即线性⽀持向量机;3)当训练数据线性不可分时,通过使⽤核技巧及软间隔最⼤化,学习⾮线性⽀持向量机。
2 SVM优缺点
- SVM的优点:
在⾼维空间中⾮常⾼效;即使在数据维度⽐样本数量⼤的情况下仍然有效;在决策函数(称为⽀持向量)中使⽤训练集的⼦集, 因此它也是⾼效利⽤内存的;通⽤性:不同的核函数与特定的决策函数⼀⼀对应;
- SVM的缺点:
如果特征数量⽐样本数量⼤得多,在选择核函数时要避免过拟合;对缺失数据敏感;对于核函数的⾼维映射解释⼒不强
后记:
●本博客基于B站开源学习资源,是作者学习的笔记记录,仅用于学习交流,不做任何商业用途!