本篇文章记录我在智能车竞赛中,对 Infineon_TC264 这款芯片的底层库函数的学习分析。通过深入地对其库函数进行分析,C语言深入的知识得以再次在编程中呈现和运用。故觉得很有必要在此进行记录分享一下。


目录
编辑
一、代码段分析
NO.1 指向结构体的指针
NO.2 单片机的FIFO
NO.3 单片机的DMA
NO.4 结构体指针作为函数的入口参数
NO.5 结构体的嵌套使用
NO.6 初探双核单片机TC264
一、代码段分析
NO.1 指向结构体的指针
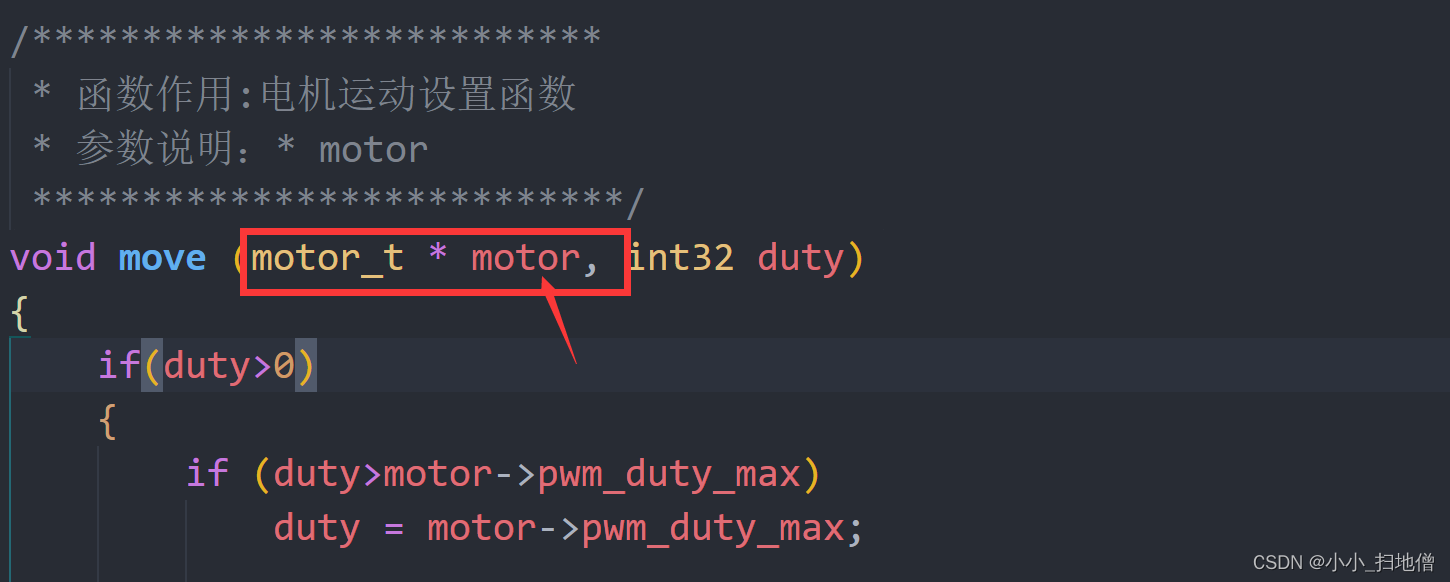
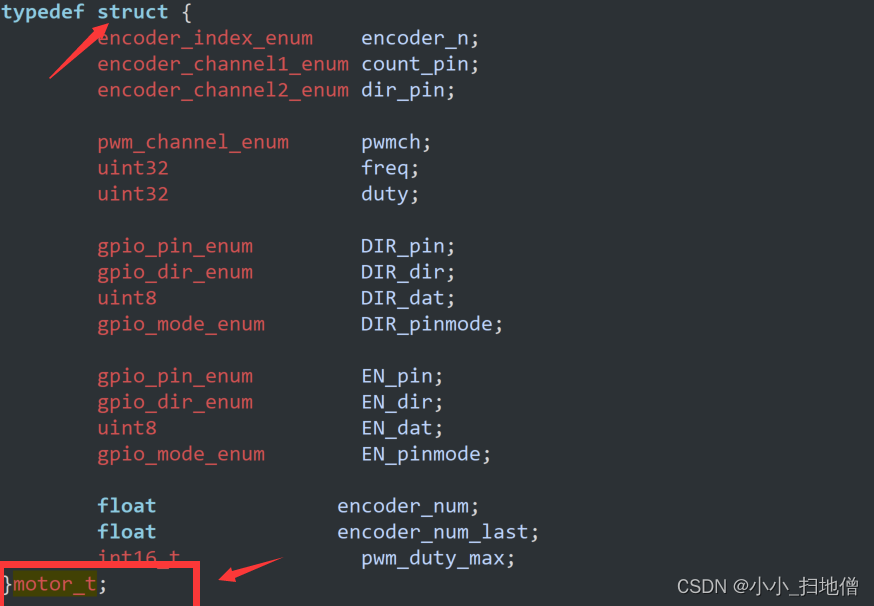
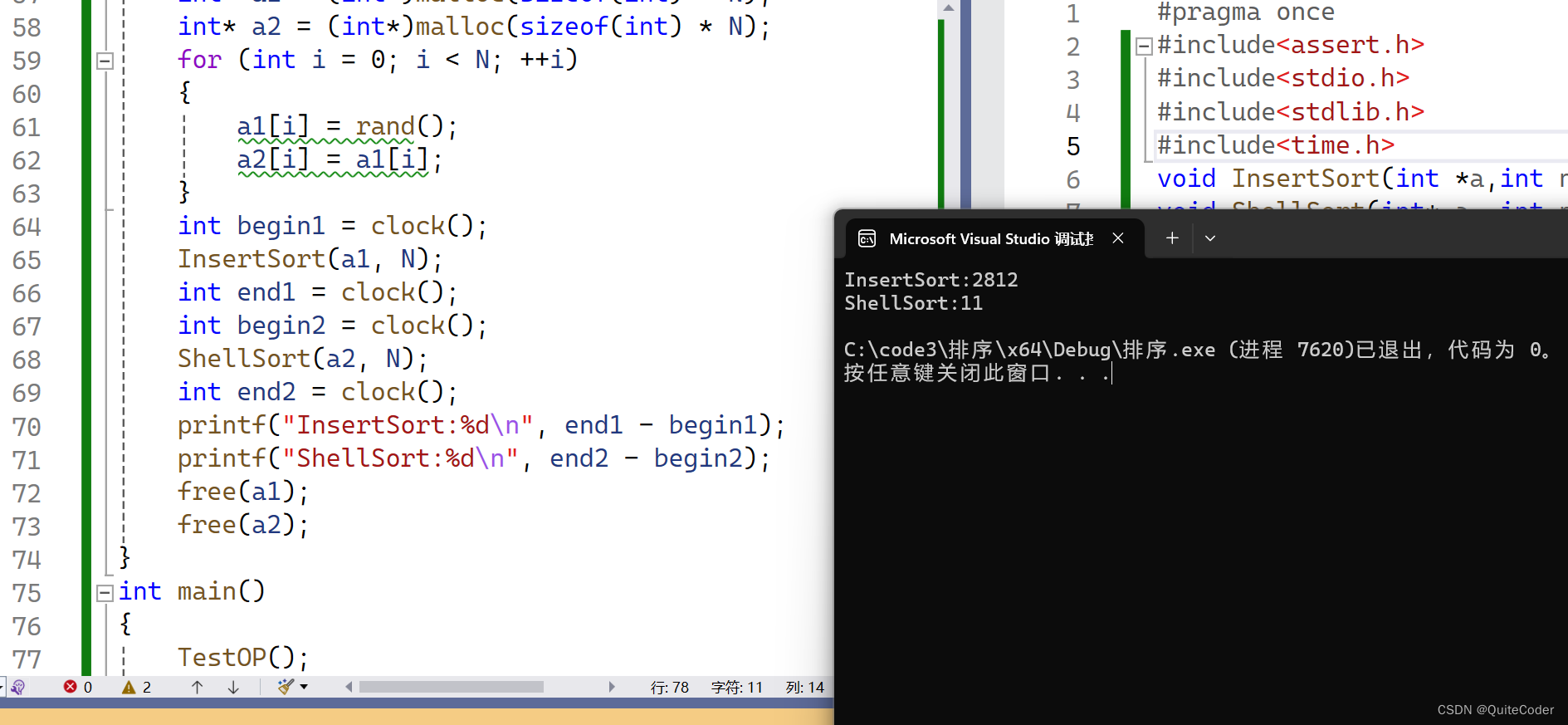
在这段代码中,
motor_t * motor是一个指向motor_t结构体的指针。这种写法表示motor是一个指针变量,指向类型为motor_t的结构体变量。通过使用指针,可以在函数内部直接修改结构体的内容,而无需传递整个结构体的副本,从而节省内存空间并提高效率。在函数中,通过传递
motor指针作为参数,可以在函数内部访问和操作该结构体变量的成员。通过指针操作,可以对结构体的成员进行读取或修改,包括调整电机的参数、控制电机的运动等操作。指针作为一种强大的工具,用于在函数之间传递和操作复杂的数据结构,如结构体。

NO.2 单片机的FIFO
在单片机中,FIFO表示先进先出(First In, First Out)的缓冲区或队列。FIFO通常用于临时存储数据,以便在处理器和外设之间传输数据时进行缓冲和调节速度。
在单片机中,FIFO通常是一个硬件模块,用于暂时存储数据。当数据被写入FIFO时,它被放置在FIFO的尾部;而当数据被读取时,它从FIFO的头部被取出,保持了数据的顺序性。
FIFO的常见用途包括:
通信接口:在串行通信中,FIFO可用于暂存接收到的数据或等待发送的数据,以便缓解处理器的负担。
DMA(Direct Memory Access):在DMA传输中,FIFO可以暂存要传输的数据,以便DMA控制器按照一定的速率将数据传输到目标设备或内存中。
数据采集:在数据采集系统中,FIFO可用于临时存储传感器数据,以便后续处理。
多任务处理:在实时系统中,FIFO可用于处理不同优先级任务之间的数据传输,确保数据按照先进先出的原则进行处理。
NO.3 单片机的DMA
DMA(Direct Memory Access)是单片机中的一种数据传输方式,它允许外设直接和内存之间进行数据传输,而无需通过中央处理器(CPU)的干预。
在传统的数据传输方式中,CPU负责从外设读取数据,并将数据写入内存,或者从内存读取数据并将数据发送到外设。这种方式会占用CPU的时间和资源,限制了系统的性能和效率。
而DMA可以解决这个问题。DMA控制器作为一个独立的硬件模块,可以直接访问内存,并与外设进行数据传输,而不需要CPU的介入。
使用DMA传输数据的基本过程如下:
配置DMA控制器:首先,需要配置DMA控制器,包括设置数据传输的方向(从外设到内存,或从内存到外设)、源地址和目的地址、传输数据的大小等参数。
启动DMA传输:一旦DMA控制器配置完成,可以启动DMA传输。DMA控制器开始从外设读取数据或向外设写入数据,直接与内存进行数据交换,而不需要CPU的介入。
完成DMA传输:当DMA传输完成后,DMA控制器会发出中断信号,通知CPU数据传输已经完成。
通过使用DMA,单片机可以在不占用CPU资源的情况下进行高速的数据传输。这对于需要高效处理大量数据的应用非常有用,如音频、视频处理,以及高速通信等。
需要注意的是,DMA的具体实现和功能会因单片机型号和厂商而异。因此,在使用DMA时,需参考所使用单片机的技术手册和相关资料,了解具体的配置和操作方法。

NO.4 结构体指针作为函数的入口参数
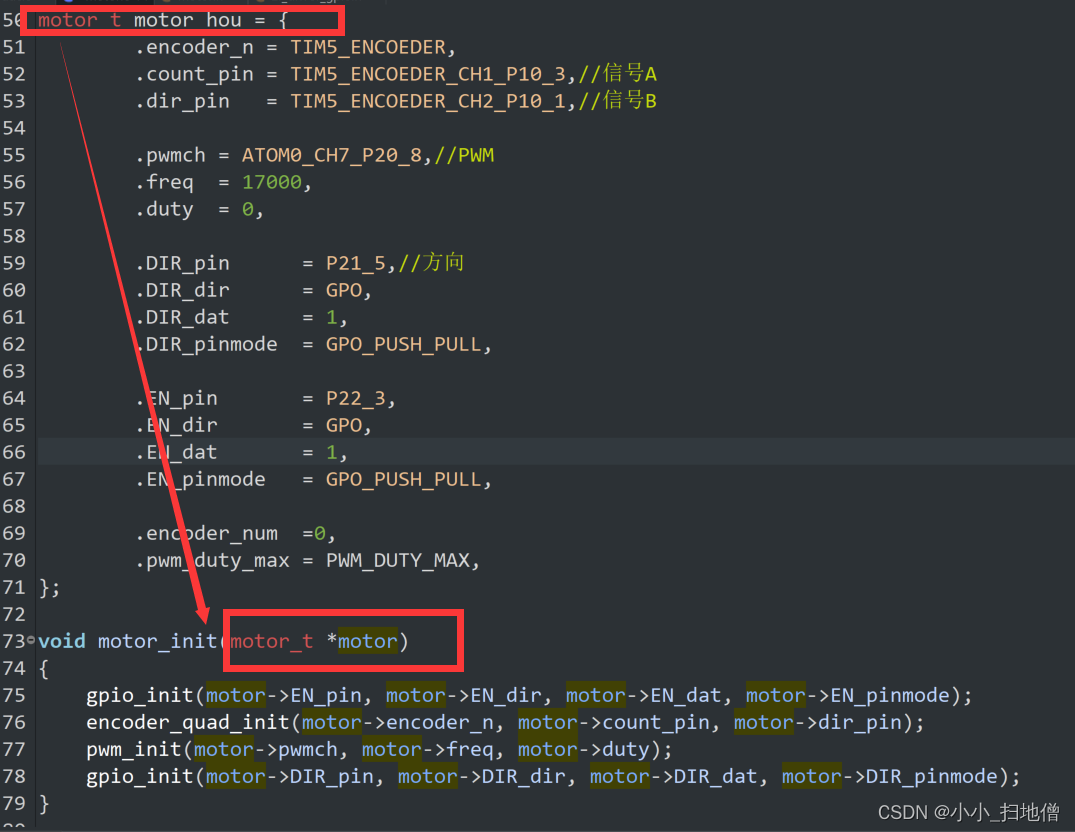
这段代码是用来初始化一个电机的函数。它接受一个指向 motor_t 结构体的指针作为参数,并使用该结构体中的信息来初始化电机的GPIO、编码器和PWM等部分。
首先,它调用 gpio_init 函数来初始化电机的使能引脚(EN_pin),然后调用 encoder_quad_init 函数来初始化电机的编码器,接着调用 pwm_init 函数来初始化电机的PWM信号,最后调用 gpio_init 函数来初始化电机的方向控制引脚(DIR_pin)。
在这段代码中,假设 motor_t 结构体包含了所有必要的信息来初始化电机所需的各个部分,而这些信息则通过 motor 指针传递进来。

NO.5 结构体的嵌套使用
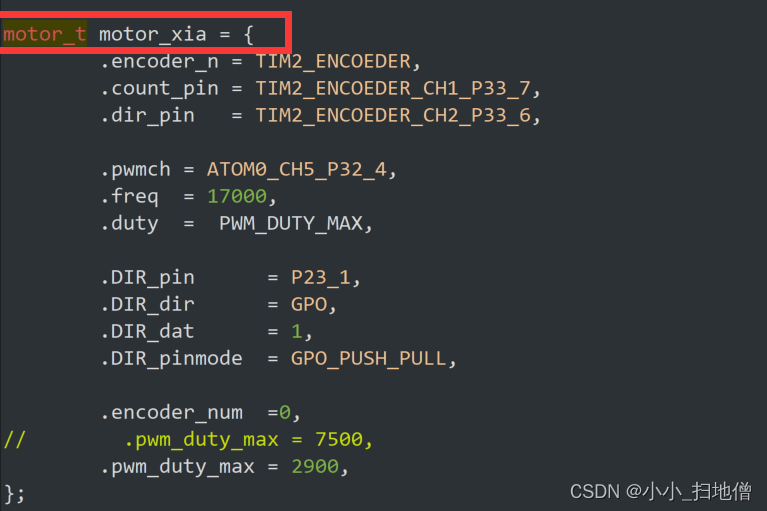
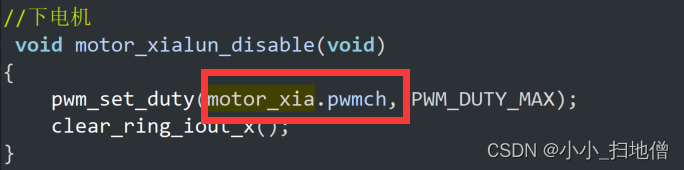
这段代码是对 motor_t 结构体变量 motor_xia 进行初始化赋值。

NO.6 初探双核单片机TC264
双核单片机相对于单核单片机来说,具有以下区别:
性能更强:双核单片机拥有两个处理核心,可以同时运行多个任务,提高处理性能和效率。
更高的可靠性:双核单片机可以实现双核热备份,一旦一个核心出现问题,另一个核心可以继续工作,提高系统的稳定性和可靠性。
更灵活的应用:双核单片机可以将不同的任务分配给不同的核心处理,实现并行处理,适用于复杂的应用场景。
总的来说,双核单片机相比于单核单片机在性能、可靠性和应用方面都有明显的优势,适合需要更高处理性能和稳定性要求的应用场景。
双核单片机的设计通常会考虑到避免核心之间的冲突。在设计上,双核单片机通常会采用独立的缓存系统、总线结构等来确保两个核心能够独立运行而不会相互干扰。
此外,软件开发人员在编写应用程序时也需要注意避免核心之间的冲突。他们可以通过合理分配任务、使用同步机制等方式来确保双核系统的稳定运行,避免核心之间的竞争和冲突。
在双核系统中,同一个变量在不同核心中运行时,最终的值可能会取决于具体的情况和系统设计。由于每个核心都有自己的寄存器和缓存,可能会导致变量的值在两个核心之间发生不同步。
如果在双核系统中需要多个核心之间共享变量,并且需要保证变量的一致性,通常需要使用同步机制来确保数据的一致性,比如使用锁、信号量、互斥量等。这样可以避免出现数据竞争和不一致的情况,保证变量的最终值是符合预期的。
因此,要确保在双核系统中对同一个变量进行操作时能够得到正确的结果,开发人员需要特别注意同步机制的使用,以避免数据竞争和不确定性的情况发生。
如何进行同步机制呢?
在双核系统中,可以采用以下几种常见的同步机制来确保对共享变量的操作是有序且正确的:
锁(Lock):使用锁机制可以确保在一个核心执行某段代码时,其他核心无法同时执行该段代码。常见的锁包括互斥锁(Mutex)和自旋锁(Spinlock),可以根据具体需求选择适合的锁类型。
信号量(Semaphore):信号量是一种计数器,用于控制多个核心对共享资源的访问。核心在访问共享资源之前需要先获取信号量,如果信号量计数为0,则核心会被阻塞,直到其他核心释放信号量。
互斥量(Mutex):互斥量是一种特殊的锁,用于保护共享资源的访问。只有获取到互斥量的核心才能访问共享资源,其他核心需要等待互斥量释放后才能进行访问。
条件变量(Condition Variable):条件变量用于实现核心之间的等待和唤醒机制。一个核心可以等待某个条件满足后再继续执行,而其他核心可以在满足条件时通知等待的核心继续执行。
这些同步机制可以根据具体的应用场景和需求选择使用。在代码编写中,需要谨慎地使用同步机制,确保正确地获取和释放锁、信号量等,以避免死锁和竞态条件等问题的发生。此外,一些双核单片机芯片也提供了特定的硬件支持来简化同步操作的实现,可以根据具体芯片的文档进行使用和配置。
如何在双核系统中使用互斥锁(Mutex)来对共享资源进行加锁和解锁操作?
#include <stdio.h>
#include <pthread.h>
// 定义共享资源
int shared_resource = 0;
// 定义互斥锁
pthread_mutex_t mutex;
// 线程函数1,对共享资源递增
void *thread_func1(void *arg) {
for (int i = 0; i < 1000000; i++) {
// 加锁
pthread_mutex_lock(&mutex);
shared_resource++;
// 解锁
pthread_mutex_unlock(&mutex);
}
return NULL;
}
// 线程函数2,对共享资源递减
void *thread_func2(void *arg) {
for (int i = 0; i < 1000000; i++) {
// 加锁
pthread_mutex_lock(&mutex);
shared_resource--;
// 解锁
pthread_mutex_unlock(&mutex);
}
return NULL;
}
int main() {
pthread_t thread1, thread2;
// 初始化互斥锁
pthread_mutex_init(&mutex, NULL);
// 创建线程1
pthread_create(&thread1, NULL, thread_func1, NULL);
// 创建线程2
pthread_create(&thread2, NULL, thread_func2, NULL);
// 等待线程结束
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
// 销毁互斥锁
pthread_mutex_destroy(&mutex);
// 打印共享资源的最终值
printf("Final value of shared_resource: %d\n", shared_resource);
return 0;
}
在上面的代码中,通过创建两个线程并分别对共享资源进行递增和递减操作,使用互斥锁来保护共享资源的访问。在每个线程对共享资源进行操作之前,先调用
pthread_mutex_lock()加锁,操作完成后再调用pthread_mutex_unlock()解锁。这样可以确保同一时刻只有一个线程可以访问共享资源,避免数据竞争和不一致性的问题。




![[Kali] 安装Nessus及使用](https://img-blog.csdnimg.cn/direct/17c6362b4b5f4880b19417cbe0b8f6cc.png)