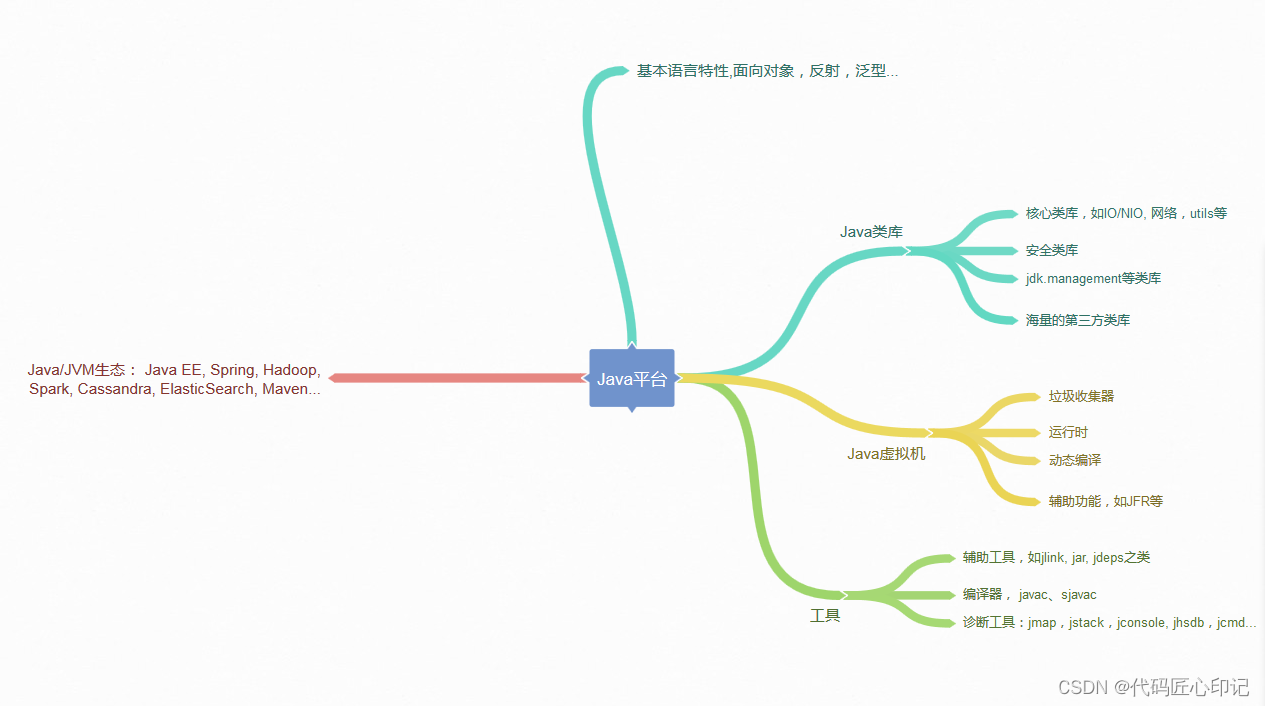
官方文档查阅: TritonInferenceServer文档
1. 写在前面
这篇文章开始进行大语言模型(Large Language Model, LLM)的学习笔记整理,这次想从Triton Inference Server框架开始,因为最近工作上用到了一些大模型部署方面的知识, 所以就快速补充了些,大模型这块, 属于是从用户使用触发,先把模型部署上来, 把整个业务流程走顺,让用户先能用起来,然后再深入到模型本身的细节中去哈哈。
Triton Inference Server是Nvida开源的机器学习推理引擎,提供了非常多实用的功能帮助我们快速落地AI模型到生产环境以提供业务使用(我们如果训练出来了一个大语言模型, 要怎么部署成一个服务, 开放给广大用户去进行使用)。当人手资源受限或开发时间不足的情况下,没有能力自研一套机器学习推理引擎,可以选择这套工具提高我们的模型部署效率。
这次学习是跟着B站上的这个课程学习的, 原理模块讲的很不错, 比直接看官方文档要亲民很多,不过这里面的实践代码没有开放出来,全程跟完一遍之后,如果不动手操作,记忆不太深刻。 所以我就想借着这个学习机会, 把里面的内容都亲自实操一下, 记录一些坑并顺便补充扩展内容,先理解基本原理,并掌握基本的部署流程,入门之后, 再去看官方文档的细节就会容易很多啦。
Triton Inference Server系列计划用3-4篇文章进行学习,本篇是该系列的第一章,也就是理论部分, 需要先对整个Triton Inference Server架构做一个初识, 从宏观上先了解下这是个啥? 是干什么的? 设计理念是啥? 为什么要用它?等
主要内容:
- Triton Inference Server整体架构(what)
- Triton Inference Server设计理念(how)
- Triton Inference Server优势总结(why)
Ok, let’s go!
2. Triton Inference Server整体架构
Triton Inference Server是Nvida开源的机器学习推理引擎,提供了非常多实用的功能帮助我们快速落地AI模型到生产环境以提供业务使用, 可以很方便的解决我们模型的服务部署问题。
工作流程大概是这样:我们训练出深度模型之后, 借助这个框架,可以很方便的部署一个模型服务, 类似于用flask或者fast框架搭建的那种后端服务, 用户把要推理的数据通过http或者grpc请求发给我们的服务, 我们接收到之后,给到模型推理,把推理结果返回给用户。 这样,我们就算把我们研制模型落地了。
整体架构如下:

推理架构: client + server, 其实比较清晰, client不用多讲, 准备好数据给服务发请求就好, 主要说一下服务端,整个服务从大面上看,一般会部署到k8s集群上,因为既然开放出去, 肯定不是只有一台机器推理了,我们会有多台机器,每台机器上又会有多张卡一块进行推理。 而k8s是一个容器化的管理工具,我们每个小的服务启动,生命周期维护,弹性扩容等,需要有一个管理系统运维自动化的工具, 下面介绍一些关键的模块:
- 容器组(load balancer): 解负载均衡问题,客户端过来的请求,怎么有效均匀分配给后端的推理服务,达到高效利用资源, 平衡推理请求的压力效果
- 模型仓库管理(Model repository persistent volume): 管理我们训练出来的模型, 这里会支持很多类型的主流模型,比如pytorch, tf, onnx等等
- metrics service: 监督每个推理节点,负责每个推理节点的安全性检查(每个推理服务是否正常,延迟,吞吐,GPU利用率等)
- 推理核心(triton server): 负责推理部分(每个节点启动1或者多个triton inference server进行模型推理),Triton Inference Server的定位是整个推理架构服务器端的一部分, 工作在单个节点上进行推理服务
所以, 基于上面宏观架构, 先弄清楚几个概念:
- K8s集群:带有多台机器,多张GPU卡的容器化管理工具,负责保证整个推理服务的启动,生命周期等维护,机器的相关扩容等, 负责整个推理服务集群的调度
- triton server: 整个推理架构服务器端的一部分, 工作在单个节点上进行推理服务
- TensorRT引擎: 这个东西我特意查了下,详细内容看这篇文章, TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架,我们可以把Pytorch、TF或者其他框架训练好的模型,转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,可以有效提升模型在英伟达GPU上运行的速度。
这三者,从概念上来看,由大入小。下面抛开掉k8s集群,再看一下整体的架构图,稍微深入下细节:

这样图就能比较清晰的看清楚triton server的整个工作流程了,首先,是用户给服务发送http请求或者grpc请求, 然后服务接收到请求,会放到一个队列里面, 当然,load balancer会针对队列里面的请求做一些推理优化,比如把几个小的batch合并成一个大batch给到模型等, 做完优化之后,就可以去模型仓库里面调指定的模型去推理。这些模型有各种格式的。 模型推理完结果,会把输出返回给客户端。 整个过程用,健康检查系统会监控模型的工作状态, 吞吐和GPU利用率等。
通过这张图,整理下Triton支持的基础功能:
- 支持多框架类型的模型(TensorRT, ONNX engine, TF, Pytorch,自定义),原因是triton与backends是解耦的, 可以实现多类框架的backends,通过在配置文件中指定模型要用的backends之后, triton就根据指定去调对应的backends推理(backends那篇文章中会详细整理到)。
- Triton可GPU/CPU推理,做到了推理的异构计算
- 可以多实例推理(GPU并行, 提升效率)
- HTTP、GRPC的请求支持
- 集成k8s系统和系统安全性检查,监控,很多基本的服务框架的功能都有,模型管理比如热加载、模型版本切换、动态batch,类似于之前的tensorflow server
- 做到了模型统一管理,加载更新
- 开源,可以自定义修改,很多问题可以直接issue,官方回复及时
- NGG支持(NGC可以理解是NV的一个官方软件仓库,里面有好多编译好的软件、docker镜像等,我们可以下载之后一键运行triton server)
3.Triton Inference Server设计理念
上面的内容大概能理解trition inference server是个啥, 是在怎么工作的了,下面从启发性的角度思考下,假设我们要做一个这样的推理服务,应该怎么去设计呢?
3.1 推理服务的生命周期
第一个角度,就是整个推理服务的生命周期, 我们的模型肯定会有很多类型, 我们针对每种类型的模型,怎么去支持? 需要有不同的backends的方式,即通过backends的方式, 支持多种框架类型的模型,做到Backends的解耦和,比如pytorch的模型, backends要用pytorch, tf的模型,backends要用tf,通用功能设计:
- backends的管理(load等)
- 模型的管理(load, 更新状态)
- 多instance的推理管理, 要能做到多线程推理的并发
- 推理服务请求的分发与调度
- 推理服务的生命周期管理(推理请求管理和推理响应的管理等)
- 支持多请求协议(HTTP和GRPC请求等)
3.2 模型优化的角度
模型本身不仅有框架实现方式的区别, 自身场景也有一些区别,所以要从场景上,支持3大类模型:
- 单一的, 没有相互依赖,无状态的模型,比如CV的相关模型
这类模型可以优化下推理服务请求的调度方式, 比如支持动态batch或者是default scheduler(均匀分配打batch) ,打batch的好处是, 可以把请求队列里面的用户请求, 多个请求打成一个batch去给到模型推理, 提高GPU的利用率

- 单一的, 有状态的模型(NLP, 当前状态需依赖前面的状态)
调度的时候,每个推理请求要映射到同一个instance上去,因为前后有依赖关系, 这里面也有两种方式:- direct: 映射到同一个instance上去, 在同一个instance的内部不打batch
- Oldest: 映射到同一个instance上去, 在同一个instance的内部打batch

- 模型pipeline
不是一个模型了,而是多个模型的组合,后一个模型要依赖前一个模型的输出结果,比如cv任务的推理里面,我可能有一个预处理的模型,针对输入的图像做一些预处理操作, 然后再给到一个分类或者分割的模型, 最后可能还有个后处理的模型做后处理返回结果。

在调度上,每个模型有自己的调度方式。单模型多线程或者是多模型多线程等,类似于下面这个图

3.3 Backend的角度
Backends的角度要考虑两点:
- Backend对推理服务本身进行解耦, 因为整个推理服务是用C++编译的, 解耦开之后,后面万一增加backends了,不用再编译整个triton服务了,只需要单独编译backends, 提供给triton需要的.so文件就可以了,这样会非常方便,类似于可插拔。
- 用户可以自定义backend对数据推理作个性化
- 需要实现triton的API, 告诉triton的推理过程
- 这个需要看官方文档
4. Triton Inference Server优势总结
综上, 对整个triton inference server的优势总结, 上面的2部分整理了一些了:
- 开源,bsd协议。
- 社区方式管理,重构风险低;
- 核心团队来自NV,对NVGPU的适配好;
- 来自不同公司贡献的backend;
- 可以促进新特性,提需求;
- 支持多框架;
- 使用的公司多,对NVIDIA系列GPU比较友好,也是大厂购买NVIDIA云服务器推荐使用的框架;
- 通过customer backend解耦定制模型;
- 基于多实例支持,GRPC和CUDA基于内存的优化,实现更好的性能;
- 驾驶舱(监控)支持
反正牛就是完事了, 不过通过学习完之后使用的结果来看, 部署大模型确实是比较方便。
5. 小总
本文是LLM系列的第一篇文章, 从推理框架服务开始, 这篇文章比较简单,主要是Trition Inference Server的理论知识为主, 主要总结了下, trition inference server是啥? 包含哪些模块?大致上怎么工作的? 为什么要用它等等。
下一篇文章,我们就来stey by step的部署模型, 把整个流程串一遍啦 😉