昨天说到要做一个自定义的训练模型,但是很快这个想法就被扑灭了,因为这个手工标记的成本太大,而且我的上级并不是想要我做这个场景,而是希望我通过这个场景展示出可以接下最终需求的能力。换句话来说:可以,但是没必要。
所以我来github上找找有没有现成的模型可以使用,这不,让我发现了一个更适合新手宝宝使用的模型--HanLP,废话少说,咱们直接上干货:
HanLP下载
我们以文档的代码为例讲解一下结果:
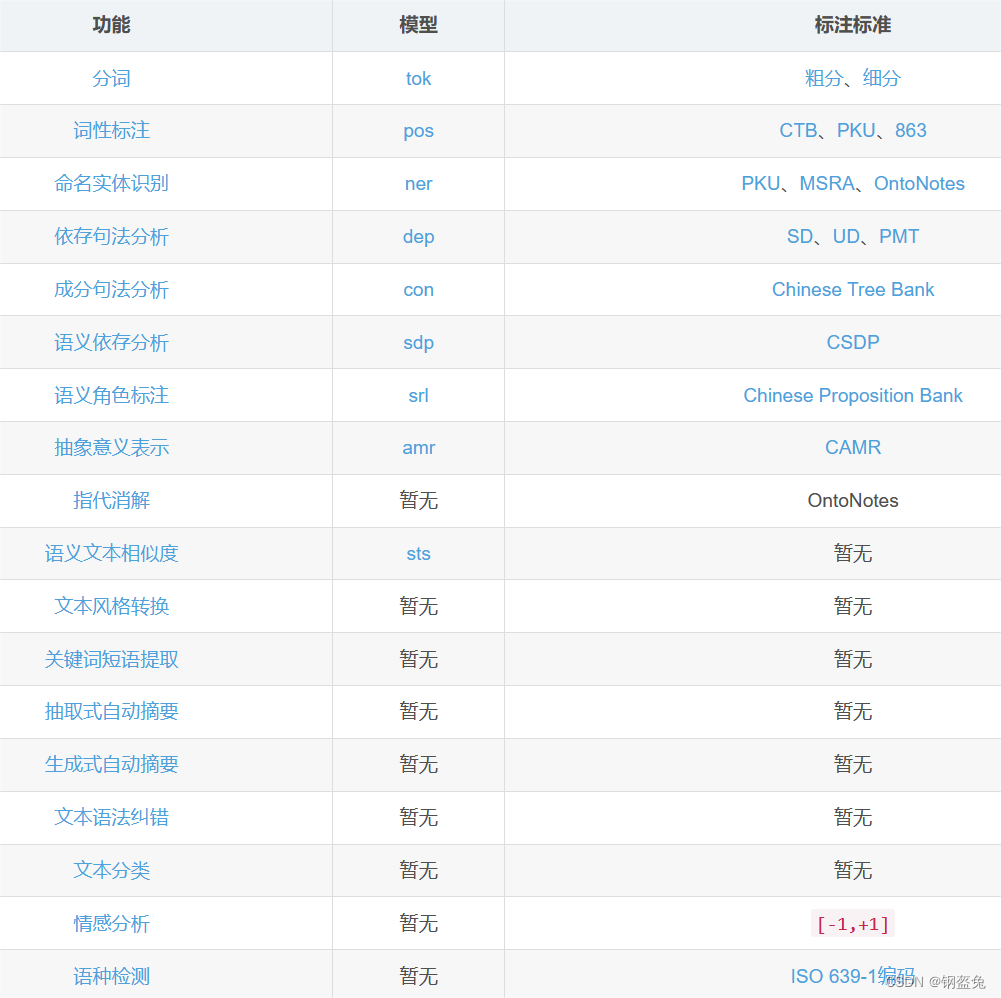
HanLP最终输出的是一个标准的字典类型,一开始看到结果的小伙伴可能会有点懵,key值结合上面这个表就好懂了哈,比如:tok/fine: tok是分词,coarse为粗分,fine为细分
而且文档中还有许多底下代码没有使用的功能,因为我们用的是restful版本,所以其实几乎所有功能我们都可以使用,只需要点击对应功能的教程就可以了:
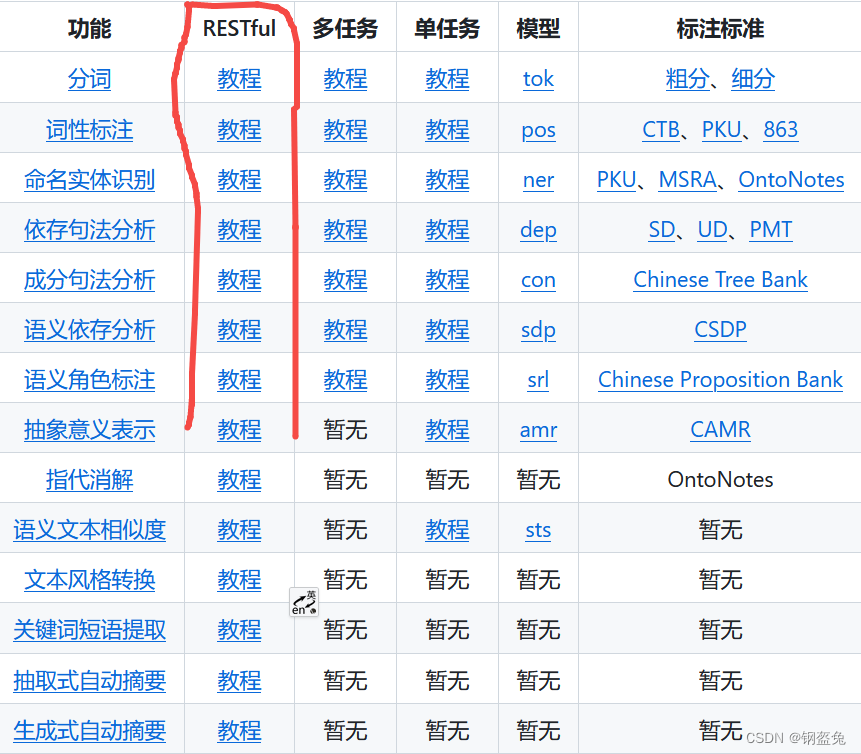
下面附上实战代码:
from hanlp_restful import HanLPClient
import sys
import os
HanLP = HanLPClient('https://www.hanlp.com/api', auth="你自己申请的密钥", language='zh') # auth不填则匿名,zh中文,mul多语种
data="你要解析的文本"
##获取最基本的信息
# info = HanLP.parse(data)
# print("细分效果{}".format(info["tok/fine"]))
# print("粗分效果{}".format(info["tok/coarse"]))
#抽象意义表示
# abstact = HanLP.abstract_meaning_representation(data)
# print("抽象意义表示{}".format(abstact))
# #生成式摘要(这个效果不太好)
# active_summary = HanLP.abstractive_summarization(data)
# print("生成式摘要:{}".format(active_summary))
# #抽取式摘要
# extarct_summary = HanLP.extractive_summarization(data, topk=3)
# print("抽取式摘要:{}".format(extarct_summary))
# #提取关键词
# key = HanLP.keyphrase_extraction(data)
# print("关键词:{}".format(key))
# #文本分类
# class_text = HanLP.text_classification(data, model='news_zh', topk=True, prob=True)
# print("文本分类:{}".format(class_text))下一小节我们将介绍如何计算文本相似度