参考:
https://aistudio.baidu.com/projectdetail/4483048
Real-Time Scene Text Detection with Differentiable Binarization
如何读论文-by 李沐
DB (Real-Time Scene Text Detection with Differentiable Binarization)
原理
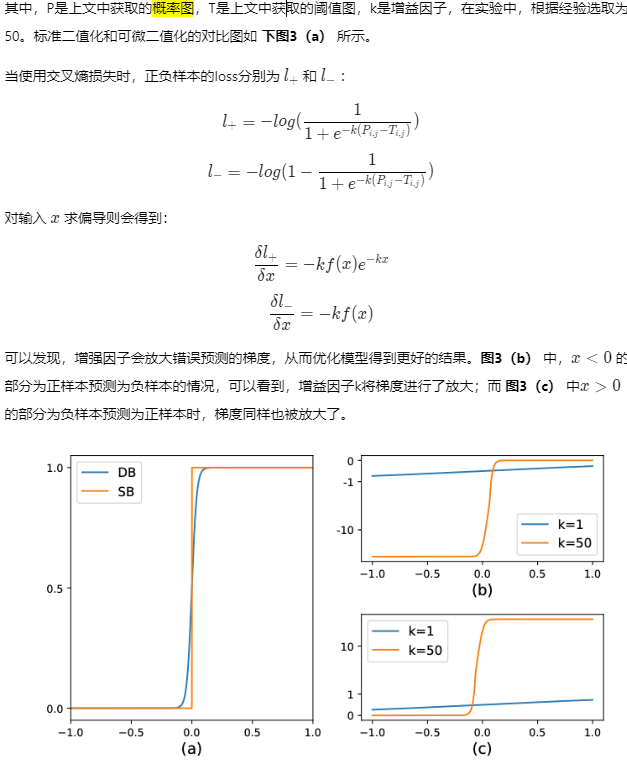
DB是一个基于分割的文本检测算法,其提出的可微分阈值,采用动态的阈值区分文本区域与背景
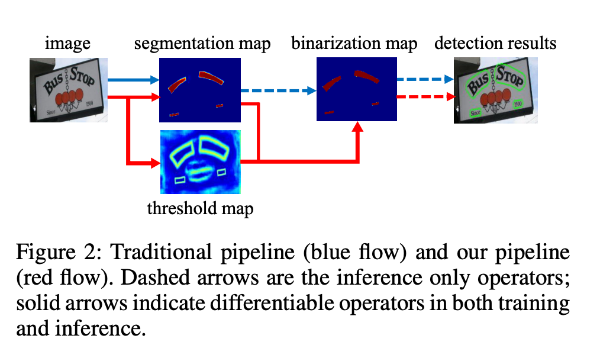
基于分割的普通文本检测算法,流程如上图蓝色箭头所示,得到分割结果后采用固定的阈值(标准二值化不可微,导致网络无法端到端训练)得到二值化的分割图,之后采用诸如像素聚类的启发式算法得到文本区域。
DB算法的流程如图中红色箭头所示,最大的不同在于DB有一个阈值图,通过网络去预测图片每个位置处的阈值,而不是采用一个固定的值,更好的分离文本背景与前景。
优势:
1.算法结构简单,无需繁琐的后处理
2.开源数据上拥有良好的精度和性能
DB算法提出了可微二值化,可微二值化将标准二值化中的阶跃函数进行了近似,使用如下公式进行代替:
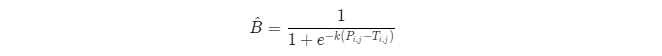
DB算法整体结构:
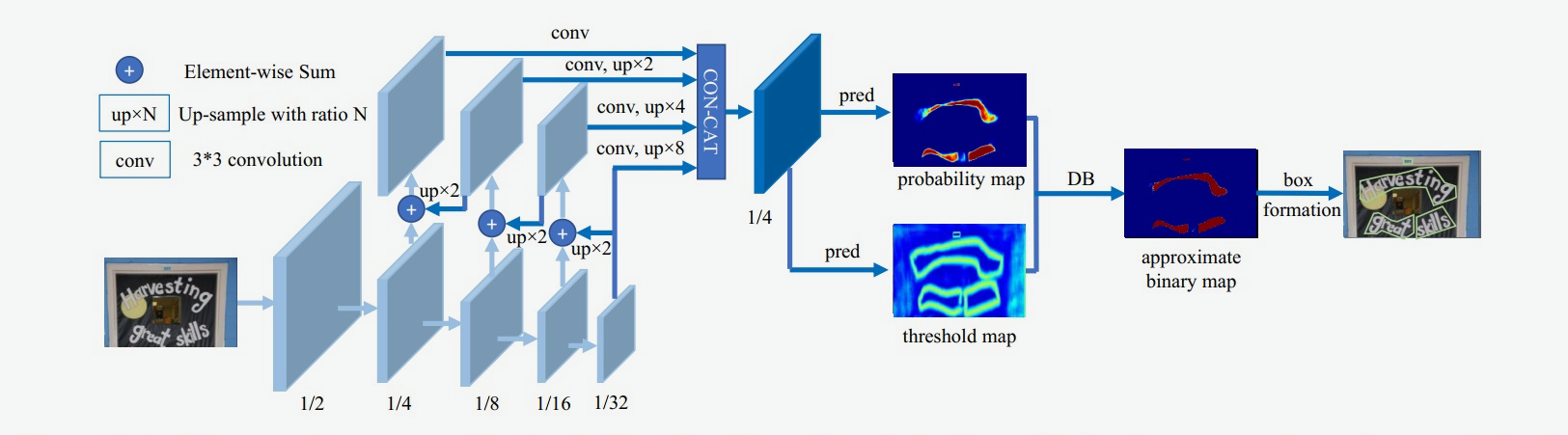
输入的图像经过网络Backbone和FPN提取特征,提取后的特征级联在一起,得到原图四分之一大小的特征,然后利用卷积层分别得到文本区域预测概率图和阈值图,进而通过DB的后处理得到文本包围曲线。
DB文本检测模型构建
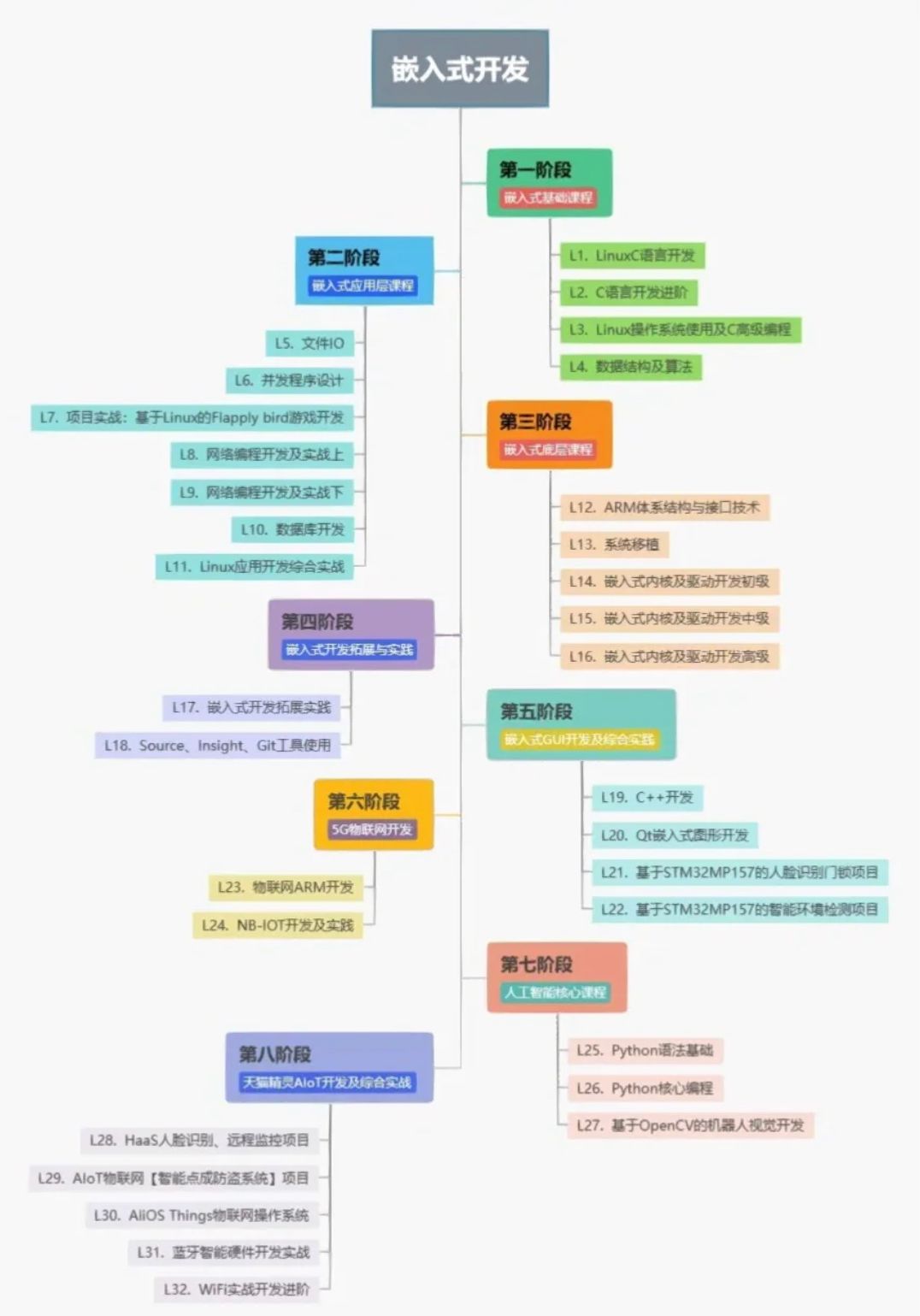
DB文本检测模型可以分为三个部分:
Backbone网络,负责提取图像的特征
FPN网络,特征金字塔结构增强特征
Head网络,计算文本区域概率图
backbone网络:论文中使用了ResNet50,本节实验中,为了加快训练速度,采用MobileNetV3 large结构作为backbone。
DB的Backbone用于提取图像的多尺度特征,如下代码所示,假设输入的形状为[640, 640],backbone网络的输出有四个特征,其形状分别是 [1, 16, 160, 160],[1, 24, 80, 80], [1, 56, 40, 40],[1, 480, 20, 20]。 这些特征将输入给特征金字塔FPN网络进一步的增强特征。
import paddle
from ppocr.modeling.backbones.det_mobilenet_v3 import MobileNetV3
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
# 1. 声明Backbone
model_backbone = MobileNetV3()
model_backbone.eval()
# 2. 执行预测
outs = model_backbone(fake_inputs)
# 3. 打印网络结构
# print(model_backbone)
# 4. 打印输出特征形状
for idx, out in enumerate(outs):
print("The index is ", idx, "and the shape of output is ", out.shape)
FPN网络
特征金字塔结构FPN是一种卷积网络来高效提取图片中各维度特征的常用方法。
FPN网络的输入为Backbone部分的输出,输出特征图的高度和宽度为原图的四分之一。假设输入图像的形状为[1, 3, 640, 640],FPN输出特征的高度和宽度为[160, 160]
import paddle
from paddle import nn
import paddle.nn.functional as F
from paddle import ParamAttr
class DBFPN(nn.Layer):
def __init__(self, in_channels, out_channels, **kwargs):
super(DBFPN, self).__init__()
self.out_channels = out_channels
# DBFPN详细实现参考: https://github.com/PaddlePaddle/PaddleOCRblob/release%2F2.4/ppocr/modeling/necks/db_fpn.py
def forward(self, x):
c2, c3, c4, c5 = x
in5 = self.in5_conv(c5)
in4 = self.in4_conv(c4)
in3 = self.in3_conv(c3)
in2 = self.in2_conv(c2)
# 特征上采样
out4 = in4 + F.upsample(
in5, scale_factor=2, mode="nearest", align_mode=1) # 1/16
out3 = in3 + F.upsample(
out4, scale_factor=2, mode="nearest", align_mode=1) # 1/8
out2 = in2 + F.upsample(
out3, scale_factor=2, mode="nearest", align_mode=1) # 1/4
p5 = self.p5_conv(in5)
p4 = self.p4_conv(out4)
p3 = self.p3_conv(out3)
p2 = self.p2_conv(out2)
# 特征上采样
p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
fuse = paddle.concat([p5, p4, p3, p2], axis=1)
return fuse
Head网络
计算文本区域概率图,文本区域阈值图以及文本区域二值图。
DB Head网络会在FPN特征的基础上作上采样,将FPN特征由原图的四分之一大小映射到原图大小。
import math
import paddle
from paddle import nn
import paddle.nn.functional as F
from paddle import ParamAttr
class DBHead(nn.Layer):
"""
Differentiable Binarization (DB) for text detection:
see https://arxiv.org/abs/1911.08947
args:
params(dict): super parameters for build DB network
"""
def __init__(self, in_channels, k=50, **kwargs):
super(DBHead, self).__init__()
self.k = k
# DBHead详细实现参考 https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppocr/modeling/heads/det_db_head.py
def step_function(self, x, y):
# 可微二值化实现,通过概率图和阈值图计算文本分割二值图
return paddle.reciprocal(1 + paddle.exp(-self.k * (x - y)))
def forward(self, x, targets=None):
shrink_maps = self.binarize(x)
if not self.training:
return {'maps': shrink_maps}
threshold_maps = self.thresh(x)
binary_maps = self.step_function(shrink_maps, threshold_maps)
y = paddle.concat([shrink_maps, threshold_maps, binary_maps], axis=1)
return {'maps': y}
# 1. 从PaddleOCR中imort DBHead
from ppocr.modeling.heads.det_db_head import DBHead
import paddle
# 2. 计算DBFPN网络输出结果
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
model_backbone = MobileNetV3()
in_channles = model_backbone.out_channels
model_fpn = DBFPN(in_channels=in_channles, out_channels=256)
outs = model_backbone(fake_inputs)
fpn_outs = model_fpn(outs)
# 3. 声明Head网络
model_db_head = DBHead(in_channels=256)
# 4. 打印DBhead网络
print(model_db_head)
# 5. 计算Head网络的输出
db_head_outs = model_db_head(fpn_outs)
print(f"The shape of fpn outs {fpn_outs.shape}")
print(f"The shape of DB head outs {db_head_outs['maps'].shape}")
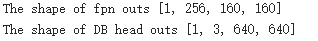
运行后发现报错:
类不完整,于是重新到github paddle ocr目录下下载相应文件
db_fpn.py
det_db_head.py
完整代码:
# from paddle import nn
#
# import paddle
# from paddle import nn
# import paddle.nn.functional as F
# from paddle import ParamAttr
#
# import math
# import paddle
# from paddle import nn
# import paddle.nn.functional as F
# from paddle import ParamAttr
#
# # import paddle
# # from ppocr.modeling.backbones.det_mobilenet_v3 import MobileNetV3
import math
import paddle
from paddle import nn
import paddle.nn.functional as F
from paddle import ParamAttr
def make_divisible(v, divisor=8, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
class MobileNetV3(nn.Layer):
def __init__(self,
in_channels=3,
model_name='large',
scale=0.5,
disable_se=False,
**kwargs):
"""
the MobilenetV3 backbone network for detection module.
Args:
params(dict): the super parameters for build network
"""
super(MobileNetV3, self).__init__()
self.disable_se = disable_se
if model_name == "large":
cfg = [
# k, exp, c, se, nl, s,
[3, 16, 16, False, 'relu', 1],
[3, 64, 24, False, 'relu', 2],
[3, 72, 24, False, 'relu', 1],
[5, 72, 40, True, 'relu', 2],
[5, 120, 40, True, 'relu', 1],
[5, 120, 40, True, 'relu', 1],
[3, 240, 80, False, 'hardswish', 2],
[3, 200, 80, False, 'hardswish', 1],
[3, 184, 80, False, 'hardswish', 1],
[3, 184, 80, False, 'hardswish', 1],
[3, 480, 112, True, 'hardswish', 1],
[3, 672, 112, True, 'hardswish', 1],
[5, 672, 160, True, 'hardswish', 2],
[5, 960, 160, True, 'hardswish', 1],
[5, 960, 160, True, 'hardswish', 1],
]
cls_ch_squeeze = 960
elif model_name == "small":
cfg = [
# k, exp, c, se, nl, s,
[3, 16, 16, True, 'relu', 2],
[3, 72, 24, False, 'relu', 2],
[3, 88, 24, False, 'relu', 1],
[5, 96, 40, True, 'hardswish', 2],
[5, 240, 40, True, 'hardswish', 1],
[5, 240, 40, True, 'hardswish', 1],
[5, 120, 48, True, 'hardswish', 1],
[5, 144, 48, True, 'hardswish', 1],
[5, 288, 96, True, 'hardswish', 2],
[5, 576, 96, True, 'hardswish', 1],
[5, 576, 96, True, 'hardswish', 1],
]
cls_ch_squeeze = 576
else:
raise NotImplementedError("mode[" + model_name +
"_model] is not implemented!")
supported_scale = [0.35, 0.5, 0.75, 1.0, 1.25]
assert scale in supported_scale, \
"supported scale are {} but input scale is {}".format(supported_scale, scale)
inplanes = 16
# conv1
self.conv = ConvBNLayer(
in_channels=in_channels,
out_channels=make_divisible(inplanes * scale),
kernel_size=3,
stride=2,
padding=1,
groups=1,
if_act=True,
act='hardswish')
self.stages = []
self.out_channels = []
block_list = []
i = 0
inplanes = make_divisible(inplanes * scale)
for (k, exp, c, se, nl, s) in cfg:
se = se and not self.disable_se
start_idx = 2 if model_name == 'large' else 0
if s == 2 and i > start_idx:
self.out_channels.append(inplanes)
self.stages.append(nn.Sequential(*block_list))
block_list = []
block_list.append(
ResidualUnit(
in_channels=inplanes,
mid_channels=make_divisible(scale * exp),
out_channels=make_divisible(scale * c),
kernel_size=k,
stride=s,
use_se=se,
act=nl))
inplanes = make_divisible(scale * c)
i += 1
block_list.append(
ConvBNLayer(
in_channels=inplanes,
out_channels=make_divisible(scale * cls_ch_squeeze),
kernel_size=1,
stride=1,
padding=0,
groups=1,
if_act=True,
act='hardswish'))
self.stages.append(nn.Sequential(*block_list))
self.out_channels.append(make_divisible(scale * cls_ch_squeeze))
for i, stage in enumerate(self.stages):
self.add_sublayer(sublayer=stage, name="stage{}".format(i))
def forward(self, x):
x = self.conv(x)
out_list = []
for stage in self.stages:
x = stage(x)
out_list.append(x)
return out_list
class ConvBNLayer(nn.Layer):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride,
padding,
groups=1,
if_act=True,
act=None):
super(ConvBNLayer, self).__init__()
self.if_act = if_act
self.act = act
self.conv = nn.Conv2D(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias_attr=False)
self.bn = nn.BatchNorm(num_channels=out_channels, act=None)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
if self.if_act:
if self.act == "relu":
x = F.relu(x)
elif self.act == "hardswish":
x = F.hardswish(x)
else:
print("The activation function({}) is selected incorrectly.".
format(self.act))
exit()
return x
class ResidualUnit(nn.Layer):
def __init__(self,
in_channels,
mid_channels,
out_channels,
kernel_size,
stride,
use_se,
act=None):
super(ResidualUnit, self).__init__()
self.if_shortcut = stride == 1 and in_channels == out_channels
self.if_se = use_se
self.expand_conv = ConvBNLayer(
in_channels=in_channels,
out_channels=mid_channels,
kernel_size=1,
stride=1,
padding=0,
if_act=True,
act=act)
self.bottleneck_conv = ConvBNLayer(
in_channels=mid_channels,
out_channels=mid_channels,
kernel_size=kernel_size,
stride=stride,
padding=int((kernel_size - 1) // 2),
groups=mid_channels,
if_act=True,
act=act)
if self.if_se:
self.mid_se = SEModule(mid_channels)
self.linear_conv = ConvBNLayer(
in_channels=mid_channels,
out_channels=out_channels,
kernel_size=1,
stride=1,
padding=0,
if_act=False,
act=None)
def forward(self, inputs):
x = self.expand_conv(inputs)
x = self.bottleneck_conv(x)
if self.if_se:
x = self.mid_se(x)
x = self.linear_conv(x)
if self.if_shortcut:
x = paddle.add(inputs, x)
return x
class SEModule(nn.Layer):
def __init__(self, in_channels, reduction=4):
super(SEModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2D(1)
self.conv1 = nn.Conv2D(
in_channels=in_channels,
out_channels=in_channels // reduction,
kernel_size=1,
stride=1,
padding=0)
self.conv2 = nn.Conv2D(
in_channels=in_channels // reduction,
out_channels=in_channels,
kernel_size=1,
stride=1,
padding=0)
def forward(self, inputs):
outputs = self.avg_pool(inputs)
outputs = self.conv1(outputs)
outputs = F.relu(outputs)
outputs = self.conv2(outputs)
outputs = F.hardsigmoid(outputs, slope=0.2, offset=0.5)
return inputs * outputs
class DBFPN(nn.Layer):
def __init__(self, in_channels, out_channels, **kwargs):
super(DBFPN, self).__init__()
self.out_channels = out_channels
weight_attr = paddle.nn.initializer.KaimingUniform()
self.in2_conv = nn.Conv2D(
in_channels=in_channels[0],
out_channels=self.out_channels,
kernel_size=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.in3_conv = nn.Conv2D(
in_channels=in_channels[1],
out_channels=self.out_channels,
kernel_size=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.in4_conv = nn.Conv2D(
in_channels=in_channels[2],
out_channels=self.out_channels,
kernel_size=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.in5_conv = nn.Conv2D(
in_channels=in_channels[3],
out_channels=self.out_channels,
kernel_size=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.p5_conv = nn.Conv2D(
in_channels=self.out_channels,
out_channels=self.out_channels // 4,
kernel_size=3,
padding=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.p4_conv = nn.Conv2D(
in_channels=self.out_channels,
out_channels=self.out_channels // 4,
kernel_size=3,
padding=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.p3_conv = nn.Conv2D(
in_channels=self.out_channels,
out_channels=self.out_channels // 4,
kernel_size=3,
padding=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.p2_conv = nn.Conv2D(
in_channels=self.out_channels,
out_channels=self.out_channels // 4,
kernel_size=3,
padding=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
def forward(self, x):
c2, c3, c4, c5 = x
in5 = self.in5_conv(c5)
in4 = self.in4_conv(c4)
in3 = self.in3_conv(c3)
in2 = self.in2_conv(c2)
out4 = in4 + F.upsample(
in5, scale_factor=2, mode="nearest", align_mode=1) # 1/16
out3 = in3 + F.upsample(
out4, scale_factor=2, mode="nearest", align_mode=1) # 1/8
out2 = in2 + F.upsample(
out3, scale_factor=2, mode="nearest", align_mode=1) # 1/4
p5 = self.p5_conv(in5)
p4 = self.p4_conv(out4)
p3 = self.p3_conv(out3)
p2 = self.p2_conv(out2)
p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
fuse = paddle.concat([p5, p4, p3, p2], axis=1)
return fuse
# class DBFPN(nn.Layer):
# def __init__(self, in_channels, out_channels, **kwargs):
# super(DBFPN, self).__init__()
# self.out_channels = out_channels
#
# # DBFPN详细实现参考: https://github.com/PaddlePaddle/PaddleOCRblob/release%2F2.4/ppocr/modeling/necks/db_fpn.py
#
# def forward(self, x):
# c2, c3, c4, c5 = x
#
# in5 = self.in5_conv(c5)
# in4 = self.in4_conv(c4)
# in3 = self.in3_conv(c3)
# in2 = self.in2_conv(c2)
#
# # 特征上采样
# out4 = in4 + F.upsample(
# in5, scale_factor=2, mode="nearest", align_mode=1) # 1/16
# out3 = in3 + F.upsample(
# out4, scale_factor=2, mode="nearest", align_mode=1) # 1/8
# out2 = in2 + F.upsample(
# out3, scale_factor=2, mode="nearest", align_mode=1) # 1/4
#
# p5 = self.p5_conv(in5)
# p4 = self.p4_conv(out4)
# p3 = self.p3_conv(out3)
# p2 = self.p2_conv(out2)
#
# # 特征上采样
# p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
# p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
# p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
#
# fuse = paddle.concat([p5, p4, p3, p2], axis=1)
# return fuse
def get_bias_attr(k):
stdv = 1.0 / math.sqrt(k * 1.0)
initializer = paddle.nn.initializer.Uniform(-stdv, stdv)
bias_attr = ParamAttr(initializer=initializer)
return bias_attr
class Head(nn.Layer):
def __init__(self, in_channels, name_list):
super(Head, self).__init__()
self.conv1 = nn.Conv2D(
in_channels=in_channels,
out_channels=in_channels // 4,
kernel_size=3,
padding=1,
weight_attr=ParamAttr(),
bias_attr=False)
self.conv_bn1 = nn.BatchNorm(
num_channels=in_channels // 4,
param_attr=ParamAttr(
initializer=paddle.nn.initializer.Constant(value=1.0)),
bias_attr=ParamAttr(
initializer=paddle.nn.initializer.Constant(value=1e-4)),
act='relu')
self.conv2 = nn.Conv2DTranspose(
in_channels=in_channels // 4,
out_channels=in_channels // 4,
kernel_size=2,
stride=2,
weight_attr=ParamAttr(
initializer=paddle.nn.initializer.KaimingUniform()),
bias_attr=get_bias_attr(in_channels // 4))
self.conv_bn2 = nn.BatchNorm(
num_channels=in_channels // 4,
param_attr=ParamAttr(
initializer=paddle.nn.initializer.Constant(value=1.0)),
bias_attr=ParamAttr(
initializer=paddle.nn.initializer.Constant(value=1e-4)),
act="relu")
self.conv3 = nn.Conv2DTranspose(
in_channels=in_channels // 4,
out_channels=1,
kernel_size=2,
stride=2,
weight_attr=ParamAttr(
initializer=paddle.nn.initializer.KaimingUniform()),
bias_attr=get_bias_attr(in_channels // 4), )
def forward(self, x):
x = self.conv1(x)
x = self.conv_bn1(x)
x = self.conv2(x)
x = self.conv_bn2(x)
x = self.conv3(x)
x = F.sigmoid(x)
return x
class DBHead(nn.Layer):
"""
Differentiable Binarization (DB) for text detection:
see https://arxiv.org/abs/1911.08947
args:
params(dict): super parameters for build DB network
"""
def __init__(self, in_channels, k=50, **kwargs):
super(DBHead, self).__init__()
self.k = k
binarize_name_list = [
'conv2d_56', 'batch_norm_47', 'conv2d_transpose_0', 'batch_norm_48',
'conv2d_transpose_1', 'binarize'
]
thresh_name_list = [
'conv2d_57', 'batch_norm_49', 'conv2d_transpose_2', 'batch_norm_50',
'conv2d_transpose_3', 'thresh'
]
self.binarize = Head(in_channels, binarize_name_list)
self.thresh = Head(in_channels, thresh_name_list)
def step_function(self, x, y):
return paddle.reciprocal(1 + paddle.exp(-self.k * (x - y)))
def forward(self, x, targets=None):
shrink_maps = self.binarize(x)
if not self.training:
return {'maps': shrink_maps}
threshold_maps = self.thresh(x)
binary_maps = self.step_function(shrink_maps, threshold_maps)
y = paddle.concat([shrink_maps, threshold_maps, binary_maps], axis=1)
return {'maps': y}
# class DBHead(nn.Layer):
# """
# Differentiable Binarization (DB) for text detection:
# see https://arxiv.org/abs/1911.08947
# args:
# params(dict): super parameters for build DB network
# """
#
# def __init__(self, in_channels, k=50, **kwargs):
# super(DBHead, self).__init__()
# self.k = k
#
# # DBHead详细实现参考 https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppocr/modeling/heads/det_db_head.py
#
# def step_function(self, x, y):
# # 可微二值化实现,通过概率图和阈值图计算文本分割二值图
# return paddle.reciprocal(1 + paddle.exp(-self.k * (x - y)))
#
# def forward(self, x, targets=None):
# shrink_maps = self.binarize(x)
# if not self.training:
# return {'maps': shrink_maps}
#
# threshold_maps = self.thresh(x)
# binary_maps = self.step_function(shrink_maps, threshold_maps)
# y = paddle.concat([shrink_maps, threshold_maps, binary_maps], axis=1)
# return {'maps': y}
if __name__=='__main__':
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
# 声明Backbone
model_backbone = MobileNetV3()
# model_backbone.eval()
# # 2. 执行预测
# outs = model_backbone(fake_inputs)
# # 3. 打印网络结构
# # print(model_backbone)
#
# # 4. 打印输出特征形状
# for idx, out in enumerate(outs):
# print("The index is ", idx, "and the shape of output is ", out.shape)
# The index is 0 and the shape of output is [1, 16, 160, 160]
# The index is 1 and the shape of output is [1, 24, 80, 80]
# The index is 2 and the shape of output is [1, 56, 40, 40]
# The index is 3 and the shape of output is [1, 480, 20, 20]
in_channles = model_backbone.out_channels
# 声明FPN网络
model_fpn = DBFPN(in_channels=in_channles, out_channels=256)
# 打印FPN网络
print(model_fpn)
# DBFPN(
# (in2_conv): Conv2D(16, 256, kernel_size=[1, 1], data_format=NCHW)
# (in3_conv): Conv2D(24, 256, kernel_size=[1, 1], data_format=NCHW)
# (in4_conv): Conv2D(56, 256, kernel_size=[1, 1], data_format=NCHW)
# (in5_conv): Conv2D(480, 256, kernel_size=[1, 1], data_format=NCHW)
# (p5_conv): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
# (p4_conv): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
# (p3_conv): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
# (p2_conv): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
# )
# 5. 计算得到FPN结果输出
outs = model_backbone(fake_inputs)
fpn_outs = model_fpn(outs)
# The shape of fpn outs [1, 256, 160, 160]
# 3. 声明Head网络
model_db_head = DBHead(in_channels=256)
# 4. 打印DBhead网络
print(model_db_head)
# DBHead(
# (binarize): Head(
# (conv1): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
# (conv_bn1): BatchNorm()
# (conv2): Conv2DTranspose(64, 64, kernel_size=[2, 2], stride=[2, 2], data_format=NCHW)
# (conv_bn2): BatchNorm()
# (conv3): Conv2DTranspose(64, 1, kernel_size=[2, 2], stride=[2, 2], data_format=NCHW)
# )
# (thresh): Head(
# (conv1): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
# (conv_bn1): BatchNorm()
# (conv2): Conv2DTranspose(64, 64, kernel_size=[2, 2], stride=[2, 2], data_format=NCHW)
# (conv_bn2): BatchNorm()
# (conv3): Conv2DTranspose(64, 1, kernel_size=[2, 2], stride=[2, 2], data_format=NCHW)
# )
# )
# 5. 计算Head网络的输出
db_head_outs = model_db_head(fpn_outs)
print(f"The shape of fpn outs {fpn_outs.shape}")
# The shape of fpn outs [1, 256, 160, 160]
print(f"The shape of DB head outs {db_head_outs['maps'].shape}")
# The shape of DB head outs [1, 3, 640, 640]
结果:
DBFPN(
(in2_conv): Conv2D(16, 256, kernel_size=[1, 1], data_format=NCHW)
(in3_conv): Conv2D(24, 256, kernel_size=[1, 1], data_format=NCHW)
(in4_conv): Conv2D(56, 256, kernel_size=[1, 1], data_format=NCHW)
(in5_conv): Conv2D(480, 256, kernel_size=[1, 1], data_format=NCHW)
(p5_conv): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
(p4_conv): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
(p3_conv): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
(p2_conv): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
)
DBHead(
(binarize): Head(
(conv1): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
(conv_bn1): BatchNorm()
(conv2): Conv2DTranspose(64, 64, kernel_size=[2, 2], stride=[2, 2], data_format=NCHW)
(conv_bn2): BatchNorm()
(conv3): Conv2DTranspose(64, 1, kernel_size=[2, 2], stride=[2, 2], data_format=NCHW)
)
(thresh): Head(
(conv1): Conv2D(256, 64, kernel_size=[3, 3], padding=1, data_format=NCHW)
(conv_bn1): BatchNorm()
(conv2): Conv2DTranspose(64, 64, kernel_size=[2, 2], stride=[2, 2], data_format=NCHW)
(conv_bn2): BatchNorm()
(conv3): Conv2DTranspose(64, 1, kernel_size=[2, 2], stride=[2, 2], data_format=NCHW)
)
)
The shape of fpn outs [1, 256, 160, 160]
The shape of DB head outs [1, 3, 640, 640]
DB算法优点:(有监督,backbone选ResNet50效果更好)
- 精度更高、快
- 弯曲文本
- 多方向文本
- 多语言