文章目录
- 概述
- 解决方法
- 深度分页方式from + size
- 深度分页之scroll
- search_after
- 三种分页方式比较
概述
Elasticsearch 的深度分页问题是指在大数据集上进行大量分页查询时可能导致的性能下降和资源消耗增加的情况。这种情况通常发生在需要访问大量数据的情形下,比如用户进行长时间滚动查看或者需要遍历大量数据的操作。
深度分页问题通常会导致性能下降的原因有以下几点:
- 数据的大量跳过和读取:在深度分页查询中,Elasticsearch 需要跳过大量的文档记录才能到达目标页,这会导致大量的 IO 操作和资源消耗。
- 分布式搜索的成本:在分布式环境下,合并和排序大量数据的成本会很高。
- 数据热点:深度分页可能导致部分节点负载过高,增加了数据热点的风险。
解决方法
- 使用 Scroll API:Elasticsearch 提供了 Scroll API 来支持大数据集的深度分页查询。使用 Scroll API 可以创建一个快照,允许在保持搜索上下文的情况下连续检索大量数据,而不需要重新执行原始查询。这样可以避免深度分页带来的性能问题。
- 使用游标分页:类似于 Scroll API,游标分页也可以用于大数据集的分页查询。它允许客户端在多个请求之间保持打开的搜索上下文,从而避免了深度分页的性能问题。
- 基于数据模型的优化:考虑使用基于数据模型的优化方法,比如预聚合、数据摘要等方式,来提前计算和存储一些聚合结果,从而减少深度分页查询的计算成本。
- 使用游标/分页组合:结合游标和分页的方式,可以在大数据集上进行分页操作而不至于影响性能。
- 优化查询需求:考虑是否真正需要进行大数据集的深度分页操作,是否可以通过其他途径满足业务需求,从而避免深度分页问题。
- 基于数据模型的优化:可以考虑对数据模型进行优化,预先计算和存储一些聚合结果或摘要信息,从而减少深度分页查询的计算成本。
- 使用 Search After:Search After 是一种用于获取某个特定文档之后的文档的方式,可以结合排序字段的值来实现分页操作,避免了跳过大量文档记录的性能开销。
- 避免深度分页:在设计应用程序时,尽量避免需要深度分页的场景,可以通过其他方式满足业务需求,比如聚合查询、更精确的过滤条件等。
- 优化索引设计:合理设计索引结构、字段映射、分片设置等,可以提高搜索性能,从而减轻深度分页带来的性能压力。
- 限制每页返回的文档数量:在进行分页查询时,可以限制每页返回的文档数量,避免一次性返回大量数据,从而减少性能消耗。
总的来说,针对 Elasticsearch 的深度分页问题,需要综合考虑数据访问方式、业务需求以及 Elasticsearch 提供的查询和分页机制,选择合适的方式来解决深度分页问题,并且在实际应用中需要进行充分的性能测试和优化。
在Elasticsearch中进行深度分页操作是一种常见的需求,但是如果使用传统的分页方式会比较耗时,可能会导致性能问题。为了解决这个问题,Elasticsearch提供了一些深度分页方案,主要包括以下几种:
深度分页方式from + size+深度分页之scroll+search_after参数
深度分页方式from + size
es 默认采用的分页方式是 from+ size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如我们执行如下查询
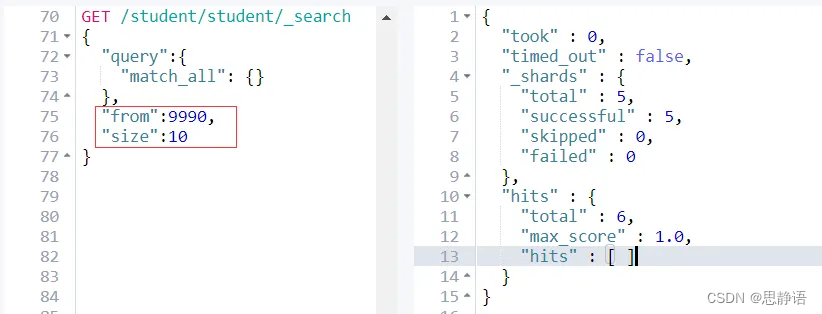
GET /student/student/_search
{
"query":{
"match_all": {}
},
"from":5000,
"size":10
}
意味着 es 需要在各个分片上匹配排序并得到5010条数据,协调节点拿到这些数据再进行排序等处理,然后结果集中取最后10条数据返回。
我们会发现这样的深度分页将会使得效率非常低,因为我只需要查询10条数据,而es则需要执行from+size条数据然后处理后返回。
其次:es为了性能,限制了我们分页的深度,es目前支持的最大的 max_result_window = 10000;也就是说我们不能分页到10000条数据以上。
例如:
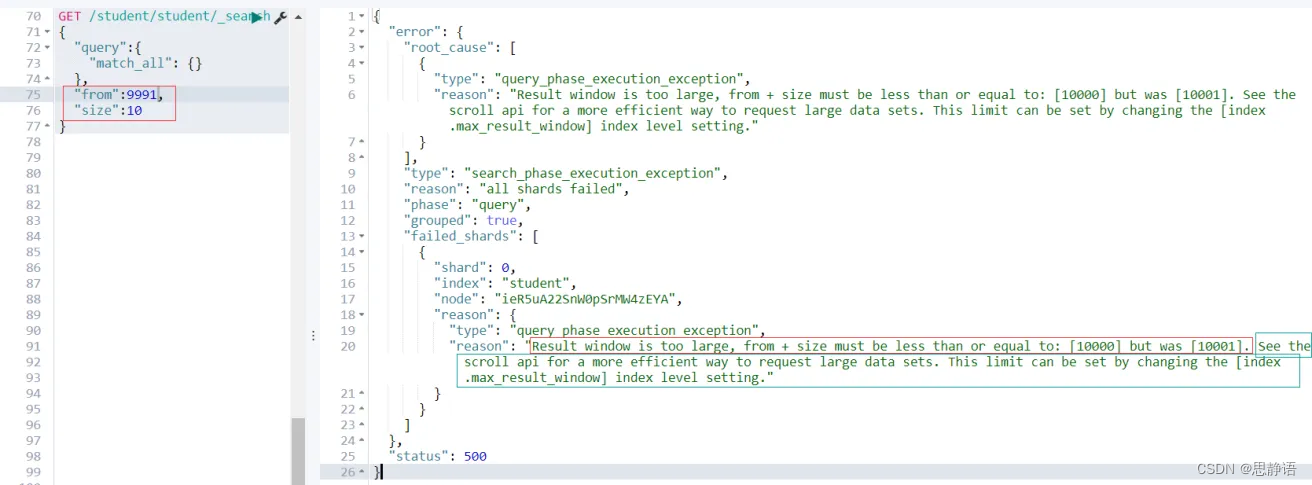
from + size <= 10000所以这个分页深度依然能够执行。
继续看上图,当size + from > 10000;es查询失败,并且提示
Result window is too large, from + size must be less than or equal to: [10000] but was [1001]
接下来看还有一个很重要的提示
See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting
有关请求大数据集的更有效方法,请参阅滚动api。这个限制可以通过改变[索引]来设置。哦呵,原来es给我们提供了另外的一个API scroll。难道这个 scroll 能解决深度分页问题?
深度分页之scroll
在es中如果我们分页要请求大数据集或者一次请求要获取较大的数据集,scroll都是一个非常好的解决方案。
使用scroll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来scroll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的。每次发送scroll请求,我们还需要指定一个scroll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了。
一个滚屏搜索允许我们做一个初始阶段搜索并且持续批量从Elasticsearch里拉取结果直到没有结果剩下。这有点像传统数据库里的cursors(游标)。
滚屏搜索会及时制作快照。这个快照不会包含任何在初始阶段搜索请求后对index做的修改。它通过将旧的数据文件保存在手边,所以可以保护index的样子看起来像搜索开始时的样子。这样将使得我们无法得到用户最近的更新行为。
scroll的使用很简单
执行如下curl,每次请求两条。可以定制 scroll = 5m意味着该窗口过期时间为5分钟。
GET /student/student/_search?scroll=5m
{
"query": {
"match_all": {}
},
"size": 2
}
{
"_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAC0YFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtGRZpZVI1dUEyMlNuVzBwU3JNVzR6RVlBAAAAAAAALRsWaWVSNXVBMjJTblcwcFNyTVc0ekVZQQAAAAAAAC0aFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtHBZpZVI1dUEyMlNuVzBwU3JNVzR6RVlB",
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 6,
"max_score" : 1.0,
"hits" : [
{
"_index" : "student",
"_type" : "student",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "fucheng",
"age" : 23,
"class" : "2-3"
}
},
{
"_index" : "student",
"_type" : "student",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "xiaoming",
"age" : 25,
"class" : "2-1"
}
}
]
}
}
在返回结果中,有一个很重要的
_scroll_id
在后面的请求中我们都要带着这个 scroll_id 去请求。
现在student这个索引中共有6条数据,id分别为 1, 2, 3, 4, 5, 6。当我们使用 scroll 查询第4次的时候,返回结果应该为kong。这时我们就知道已经结果集已经匹配完了。
继续执行3次结果如下三图所示。
GET /_search/scroll
{
"scroll":"5m",
"scroll_id":"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAC0YFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtGRZpZVI1dUEyMlNuVzBwU3JNVzR6RVlBAAAAAAAALRsWaWVSNXVBMjJTblcwcFNyTVc0ekVZQQAAAAAAAC0aFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtHBZpZVI1dUEyMlNuVzBwU3JNVzR6RVlB"
}
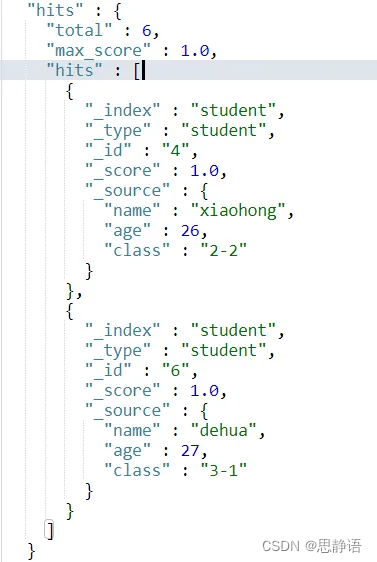

由结果集我们可以发现最终确实分别得到了正确的结果集,并且正确的终止了scroll。
search_after
from + size的分页方式虽然是最灵活的分页方式,但是当分页深度达到一定程度将会产生深度分页的问题。scroll能够解决深度分页的问题,但是其无法实现实时查询,即当scroll_id生成后无法查询到之后数据的变更,因为其底层原理是生成数据的快照。这时 search_after应运而生。其是在es-5.X之后才提供的。
search_after 是一种假分页方式,根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,但是只要能表示其唯一性就可以。
为了演示,我们需要给上文中的student索引增加一个uid字段表示其唯一性。
执行如下查询:
GET /student/student/_search
{
"query":{
"match_all": {}
},
"size":2,
"sort":[
{
"uid": "desc"
}
]
}
结果集:
View Code
下一次分页,需要将上述分页结果集的最后一条数据的值带上。
GET /student/student/_search
{
"query":{
"match_all": {}
},
"size":2,
"search_after":[1005],
"sort":[
{
"uid": "desc"
}
]
}
这样我们就使用search_after方式实现了分页查询。
三种分页方式比较
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反应数据的实时性(快照版本) | 维护成本高,需要维护一个 scroll_id海量数据的导出(比如笔者刚遇到的将es中20w的数据导入到excel)需要查询海量结果集的数据 |
| search_after | 高 | 性能最好不存在深度分页问题能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 | 海量数据的分页 |