目录
前言
1. 在原有的自定义链表类 Linked 的基础上,添加新的 “节点添加”方法 addNode(Node node)
测试用例
测试结果
2. 在自定义链表类的基础上,使用双重循环“强力” 判断两个节点是否发生相交
测试用例
测试结果
3. 在自定义链表类的基础上,使用“双指针”判断两条链表是否相交
测试用例
测试结果
4. 在自定义链表类的基础上,将一条链表进行分割
测试用例
测试结果
5. 使用链表实现 LRU缓存
重写toString()方法
测试用例
测试结果
前言
书接上回,我们继续撕链表,不同上次的是,这次双向链表(使用“双向链表 + 哈希表”实现LRUCache缓存)也得被我们撕;
相关传送门:===》【算法】单向链表手撕代码《===
1. 在原有的自定义链表类 Linked 的基础上,添加新的 “节点添加”方法 addNode(Node node)
//不使用 new Node 创造节点
public void addNode(Node node){
//获取当前链表的尾节点
final Node l =last;
if(l !=null){
//链表不为空
l.next = node;
}else{
//链表为空
first =node;
}
last = node;
size++;
}不同于之前添加节点的方法 add(int val) 的是:这个方法不使用 new Node 创造节点;
原 add(int val) 方法:
//添加元素(尾插法)
public void add(int val){
//获取当前链表的尾节点
final Node l = last ;
//创建新节点
final Node newNode = new Node(val);
if(l !=null){
//链表不为空
l.next = newNode;
}else{
//链表为空
first = newNode;
}
last = newNode;
size++;
}-
测试用例
Linked.Node node1 =new Linked.Node(1);
Linked.Node node2 =new Linked.Node(2);
Linked.Node node3 =new Linked.Node(3);
Linked.Node node4 =new Linked.Node(4);
Linked.Node node5 =new Linked.Node(5);
Linked.Node nodeA =new Linked.Node(1);
Linked.Node nodeB =new Linked.Node(2);
Linked.Node nodeC =new Linked.Node(3);
Linked link1 = new Linked();
link1.addNode(node1);
link1.addNode(node2);
link1.addNode(node3);
link1.addNode(node4);
link1.addNode(node5);
Linked link2 =new Linked();
link2.addNode(nodeA);
link2.addNode(nodeB);
link2.addNode(nodeC);
link2.addNode(node3); //链表相交
System.out.println(link1);
System.out.println(link2);-
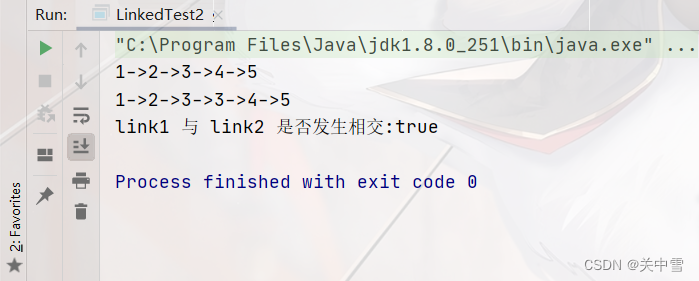
测试结果
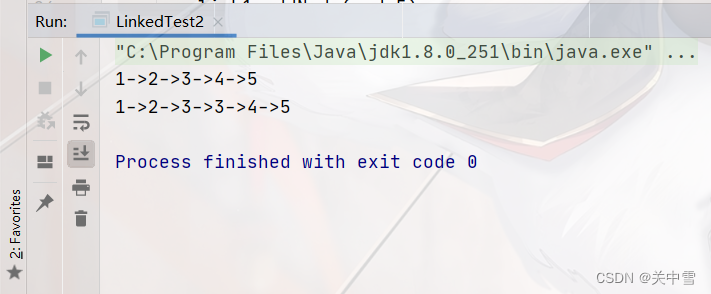
如图所示,link1链表与link2链表发生了链表相交
链表相交:顾名思义,两个链表在某个节点处有相同的节点,即它们共享同一个节点作为交点;
2. 在自定义链表类的基础上,使用双重循环“强力” 判断两个节点是否发生相交
思路:
- 设置两个变量,分别遍历两个链表,双重 for 循环,在循环遍历过程中,如果两个变量相等,那么两个链表相交;
//使用双重循环的方式判断两条链表是否相交
public static boolean isIntersect1(Linked link1,Linked link2){
for(Node p=link1.first; p !=null;p = p.next){
for(Node q =link2.first; q != null; q = q.next){
if( p == q ){
return true; //相交
}
}
}
return false; // 不相交
}解读:
- 外部循环从第一个链表的头节点开始,依次遍历每个节点;
- 内部循环检查第一个链表的当前节点是否与第二个链表的任何节点相同;
- 在内部循环中,通过比较节点的引用地址来判断两个节点是否相同;
- 如果找到相同的节点,说明两个链表在此处相交,返回 true;
- 如果外部循环结束后仍未找到相交的节点,那么说明两个链表不相交,返回 false;
效率较低,尤其是在处理大型链表时
-
测试用例
在 1 的测试用例中,添加:
System.out.println("link1 与 link2 是否发生相交:"+Linked.isIntersect1(link1,link2));-
测试结果
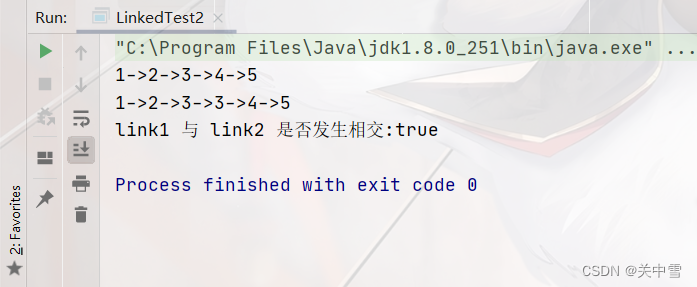
3. 在自定义链表类的基础上,使用“双指针”判断两条链表是否相交
思路:
- 判断两个链表是否相交,该两个链表中长度必定有长有短,或者相等。如果这两个链表长度不相等,我们可以得到两个链表的长度的插值diff。同样也是设置两个变量 p,q,分别遍历长链表和短链表,与方法使用双重循环不同的是,p遍历长链表的时候不是从第一个节点开始遍历,而是先让p往后移动diff个节点,然后p和q同时循环往后一个节点,如果p == q,那么两个链表就相交。
//使用“双指针”判断两条链表是否相交
public static boolean isIntersect2(Linked link1 ,Linked link2){
/**
* 不支持这个算法,需要添加代码,对链表元素进行遍历,计算链表长度
* public int size(){
* return size;
* }
*/
// p指向长链表
//
Node p = link1.size() > link2.size() ? link1.first : link2.first;
Node q = link1.size() < link2.size() ? link1.first : link2.first;
//两条链表的长度差
int diff = Math.abs(link1.size() - link2.size());
//长链表移动diff个结点
while (diff-- >0){
p = p.next;
}
//遍历链表中的剩余结点
while (p != q){
p = p.next;
q = q.next;
}
if( p != null){
return true; //相交
}
return false; //不相交
}更改原自定义链表类的链表长度计算方法 size()
//返回链表长度
public int size(){
int size =0;
for(Node x =first;x !=null; x =x.next){
size++;
}
return size;
}解读:
- 使用链表的 size() 方法获取链表的长度;
- 通过比较两个链表的长度,选择其中较长的链表,将较长的链表赋值给 p,较短的链表赋值给 q ;
- 然后计算两个链表的差值,并将p移动该差值的节点数目,使得 p 和 q 所在位置到链表末尾的距离相同;
- 使用两个指针同时遍历两个链表,直到 p 和 q 相等,或者遍历到链表结尾;
- 如果 p 和 q 相等,说明两个链表在某个位置相交,返回 true 表示相交;
时间复杂度为O(m+n),其中m和n分别为两个链表的长度。相较于双重循环的方法,这种方法通常具有更好的性能。
-
测试用例
Linked.Node node1 =new Linked.Node(1);
Linked.Node node2 =new Linked.Node(2);
Linked.Node node3 =new Linked.Node(3);
Linked.Node node4 =new Linked.Node(4);
Linked.Node node5 =new Linked.Node(5);
Linked.Node nodeA =new Linked.Node(1);
Linked.Node nodeB =new Linked.Node(2);
Linked.Node nodeC =new Linked.Node(3);
Linked link1 = new Linked();
link1.addNode(node1);
link1.addNode(node2);
link1.addNode(node3);
link1.addNode(node4);
link1.addNode(node5);
Linked link2 =new Linked();
link2.addNode(nodeA);
link2.addNode(nodeB);
link2.addNode(nodeC);
link2.addNode(node3); //链表相交
System.out.println(link1);
System.out.println(link2);
System.out.println("link1 与 link2 是否发生相交:"+Linked.isIntersect2(link1,link2));-
测试结果
4. 在自定义链表类的基础上,将一条链表进行分割
思路:
- 遍历原链表,判断每个节点,并存入两条不同的新链表中,分别用于保存小于给定值x和大于给定值x的节点,最后合并两条链表。
//链表的分割
public static Node partition(Node head,int x){
//准备两条链表,用于分别保存小于x的节点和大于x的节点
Node linked1 = new Node(0);
Node linked2 = new Node(0);
Node cur1 =linked1;
Node cur2 =linked2;
//从头节点开始遍历,分别判断每个节点与x之间的大小关系
while (head !=null){
if(head.val <=x){
//小于x,存入链表1
cur1.next = head;
cur1 = cur1.next;
}else{
//大于x,存入链表2
cur2.next = head;
cur2 = cur2.next;
}
head = head.next;
}
//合并链表
cur1.next = linked2.next;
cur2.next = null;
return linked1.next;
}解读:
- 定义了一个静态方法
partition,该方法接收两个参数:一个是头节点head,另一个是值x;- 创建了两个新的链表
linked1和linked2,并分别用cur1和cur2来指向这两个链表的当前节点;- 从头节点开始遍历原始链表
head,对每个节点的值与给定值x进行比较;- 如果节点的值小于等于
x,则将该节点添加到linked1链表中,并更新cur1指针;- 如果节点的值大于
x,则将该节点添加到linked2链表中,并更新cur2指针;- 遍历完整个原始链表后,将
linked1链表的尾部与linked2链表的头部连接起来,同时将linked2链表的尾部指向 null,以避免形成循环;- 最后返回
linked1链表的头部作为结果,即经过分区后的新链表;
-
测试用例
// 创建链表节点
Linked.Node node1 = new Linked.Node(3);
Linked.Node node2 = new Linked.Node(5);
Linked.Node node3 = new Linked.Node(8);
Linked.Node node4 = new Linked.Node(5);
Linked.Node node5 = new Linked.Node(10);
Linked.Node node6 = new Linked.Node(2);
Linked.Node node7 = new Linked.Node(1);
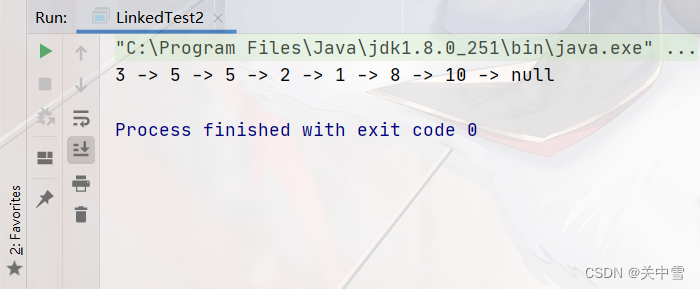
// 构建链表:3 -> 5 -> 8 -> 5 -> 10 -> 2 -> 1
node1.next = node2;
node2.next = node3;
node3.next = node4;
node4.next = node5;
node5.next = node6;
node6.next = node7;
// 执行分割方法
Linked.Node result = Linked.partition(node1, 5);
// 输出分割后的链表
while (result != null) {
System.out.print(result.val + " -> ");
result = result.next;
}
System.out.println("null");-
测试结果
5. 使用链表实现 LRU缓存
要求:
实现 LRUCache 类:满足 LRU ( Least Recently User 最近最少使用)缓存实现类;
- LRUCache(int capacity) 以正整数作为容量 capacity 初始化LRU缓存;
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1;
- void put(int key,int value) 如果关键字 key 已经存在,则变更其数据值 value;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该逐出最久未使用的关键字;
- 函数 get() 和 put() 必须以 O(1) 的平均时间复杂度运行;
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
public class LRUCache{
public LRUCache(int capacity){
}
public int get(int key){
}
public void put(int key,int value){
}
}思路:
通过双向链表 + 哈希表实现:
- 双向链表按照被使用的顺序存储键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的,用于实现 Least Recently User 最近最少使用的缓存约束;
- 哈希表通过缓存数据的键映射在双向链表中的位置;
- get () 根据 key 获取 value ,并同时将节点移动至链表的头部;
- put () 添加新缓存键值对,并同时添加至链表的头部。如果超出容量,则删除链表尾部节点;
- 通过上述操作,可保证查找函数 get() 和 put() 的时间复杂度为 O(1);
基础代码:
在 LRUCache 类中创建 Node 内部类
//①节点类:双向链表的节点
class Node{
public int key;
public int value;
Node prev; //节点前趋
Node next; //节点后继
public Node(){}
public Node(int key,int value){
this.key = key;
this.value = value;
}
}解读:
- key:表示节点的键,缓存中存储的数据的标识;
- value:表示节点的值,缓存中存储的数据;
- prev:表示节点的前趋节点,该节点在链表中的前一个节点;
- next:表示节点的后继节点,该节点在链表中的后一个节点;
- 默认构造函数
public Node():创建一个空节点;- 构造函数
public Node(int key, int value):创建一个具有指定键值的节点;
定义缓存容量和“伪”头节点和“伪”尾节点
//②定义缓存容量
private int capacity;
//②定义“伪”头节点和"伪"尾节点
private Node first,last;解读:
capacity:表示缓存的容量,缓存可以存储的键值对的最大数量。在LRU缓存中,当缓存达到容量上限时,需要进行淘汰操作以腾出空间存储新的数据;
first和last:分别表示双向链表中的虚拟头节点和虚拟尾节点。在LRU缓存中,使用虚拟头节点和虚拟尾节点的目的是简化链表操作,使得在链表头部和尾部插入、删除节点更加方便高效。这两个节点并不存储实际的数据,只是作为辅助节点来连接实际的数据节点;
定义 LRUCache 的有参构造方法
public LRUCache(int capacity) {
this.capacity = capacity;
//③创建
first = new Node();
last = new Node();
//③形成链表
first.next = last;
last.prev = first;
}解读:
将输入的缓存容量赋给成员变量
capacity,保存缓存的最大容量;创建虚拟头节点
first和虚拟尾节点last,并将它们连接起来形成一个双向链表。这两个节点不存储实际的数据,只作为辅助节点来连接实际的数据节点。在这里,通过将first的next指向last,以及last的prev指向first,形成了一个空的双向链表结构;
创建操作节点 Node 的三个方法:addFirst、removeNode、removeLast、moveToFirst;
//④添加新节点至链表头部
private void addFirst(Node newNode){
newNode.prev = first;
newNode.next = first.next;
first.next.prev = newNode;
first.next = newNode;
}
//④删除链表中的指定节点
private void removeNode(Node node){
node.prev.next = node.next;
node.next.prev = node.prev;
}
//④删除链表的尾节点
private Node removeLast(){
Node res =last.prev;
removeNode(res);
return res;
}
//④移动指定节点至链表头部
private void moveToFirst(Node node){
removeNode(node);
addFirst(node);
}
解读:
addFirst(Node newNode)方法用于将新节点添加至链表头部。该方法首先将新节点的prev指向虚拟头节点first,将新节点的next指向原头节点的下一个节点,然后将原头节点的prev指向新节点,最后将虚拟头节点first的next指向新节点,完成新节点的插入;
removeNode(Node node)方法用于删除链表中的指定节点。该方法通过修改指定节点的前趋节点和后继节点的指针来实现节点的删除操作;
removeLast()方法用于删除链表的尾节点,并返回被删除的节点。该方法首先找到尾节点last的前一个节点,然后调用removeNode(node)方法删除该节点,并返回被删除的尾节点;
moveToFirst(Node node)方法用于将指定节点移动至链表头部。该方法先调用removeNode(node)方法将节点从原位置删除,然后调用addFirst(node)方法将节点添加至链表头部,实现节点的移动操作;
初始化哈希表和定义哈希表的 put() 方法
//⑤创建哈希表,用来提高查询链表的性能
private Map<Integer,Node> cache = new HashMap<>(); //⑤添加新缓存 key-value 键值对
public void put(int key, int value) {
Node node =cache.get(key);
if(node == null){
//key 如果不存在
//创建新节点
Node newNode =new Node(key,value);
cache.put(key,newNode); //添加至哈希表
addFirst(newNode); //添加链表头部
if(++size > capacity){
//⑦超出缓存容量时,删除尾部节点(哈希表、链表)
Node last = removeLast();
cache.remove(last.key);
}
}else{
//key 如果存在
node.value = value;
moveToFirst(node); //移动至链表头部
}
}解读:
1. 通过调用
cache.get(key)方法从哈希表中获取指定键key对应的节点node。2. 如果
node为null,表示键key不存在于缓存中,需要执行以下操作:
- 创建新的节点
newNode,使用输入的key和value初始化该节点。- 将新节点
newNode添加至哈希表cache中,使用key作为键,newNode作为值。- 调用
addFirst(newNode)方法将新节点newNode添加至链表的头部;- 如果缓存的大小
size超过了最大容量capacity,则需要执行以下操作:
- 调用
removeLast()方法删除链表的尾节点,并返回被删除的节点last;- 从哈希表
cache中删除键为last.key的键值对;3. 如果
node不为null,表示键key已存在于缓存中,需要执行以下操作:
- 更新节点
node的值为输入的value;- 调用
moveToFirst(node)方法将节点node移动至链表的头部;
定义链表长度和 哈希表的 put() 方法
//⑥定义链表长度(缓存个数)
private int size; //⑥ 根据key,获取value
public int get(int key) {
Node node =cache.get(key);
if(node == null){
return -1; //不存在
}
moveToFirst(node); //存在则将这个元素移动至链表的头部
return node.value; //返回这个节点的值
}解读:
通过调用
cache.get(key)方法从哈希表中获取指定键key对应的节点node。如果
node为null,表示缓存中不存在键key,则返回-1表示不存在该键;如果
node不为null,表示缓存中存在键key,则需要执行以下操作:
- 调用
moveToFirst(node)方法将节点node移动至链表的头部,以更新节点的访问顺序;- 返回节点
node的值node.value;
在 put()方法中定义超出容量时的判断逻辑
if(++size > capacity){
//⑦超出缓存容量时,删除尾部节点(哈希表、链表)
Node last = removeLast();
cache.remove(last.key);
}解读:
调用
removeLast()方法删除链表的尾节点,并将被删除的节点赋值给变量last;通过
cache.remove(last.key)从哈希表cache中删除键为last.key的键值对,即删除了对应的缓存项;
重写toString()方法
@Override
public String toString() {
//使用线程不安全,但性能较好的StringBuilder
StringBuilder ret = new StringBuilder();
String ret1 ="";
for(Node x =first;x != null;x =x.next){
// ret.append(x.key+":"+x.value+"\t");
ret1 += x.key + ":"+x.value+"\t\t";
}
return ret1.toString();
}测试用例
public static void main(String[] args) {
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1);
System.out.println(lRUCache);
lRUCache.put(2, 2);
System.out.println(lRUCache);
lRUCache.put(3, 3);
System.out.println(lRUCache);
lRUCache.put(2, 20);
System.out.println(lRUCache);
lRUCache.put(4, 4);
System.out.println(lRUCache);
System.out.println(lRUCache.get(2)); // 返回 20
System.out.println(lRUCache);
}测试结果