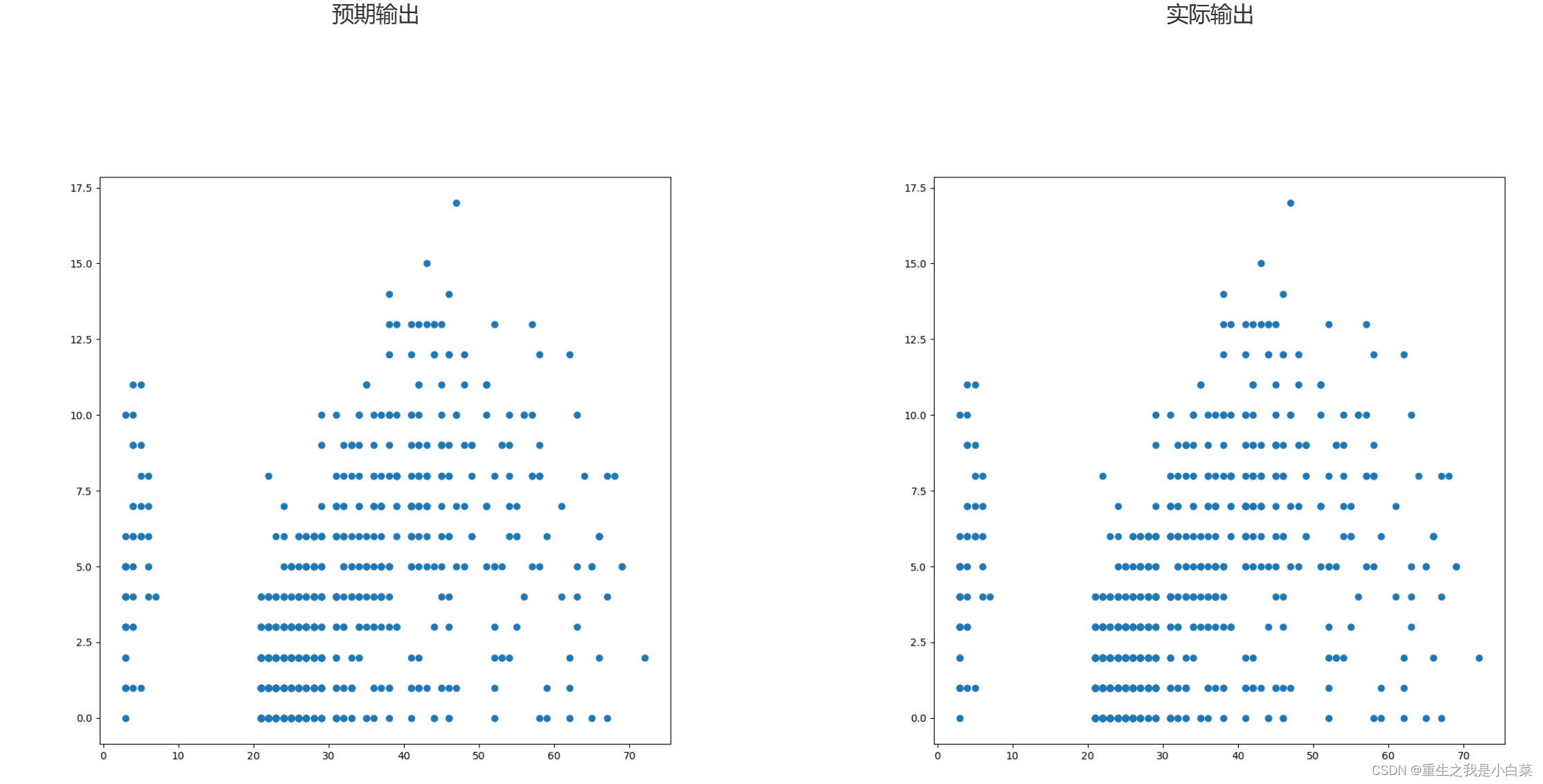
前置任务
module 'PIL.Image' has no attribute 'ANTIALIAS'
Image.ANTIALIAS 替换为 Image.LANCZOS,参考https://blog.csdn.net/fovever_/article/details/134690657
OSError: 'science' is not a valid package style, path of style file, URL of
这是对应可视化里面生成期刊风格的图表,但是本地缺少相应的font
参考https://blog.csdn.net/qysh123/article/details/136075472,但是感觉很复杂,而且也不一定能成功,干脆先把plt.style.context([‘science’, ‘ieee’, ‘no-latex’])那一部分注释掉,暂时还是用默认字体
module 'numpy' has no attribute 'bool'
这个报错影响测试环节,参考https://blog.csdn.net/weixin_49779629/article/details/136137827,把bool改成bool_
Argument interpolation should be of type InterpolationMode instead of int. P
这是warning,暂时不影响,可以参考https://blog.csdn.net/weixin_39518984/article/details/119897453,需要调Pillow版本
还有个问题是提供的运行脚本仅针对单一类别(那训练了个啥?),所以我加上个类别列表遍历。但是这样的话,每轮到一个新类别,dataset.py里load_mvtec3d函数中的mvtec3d_classes列表会持续添加’mvtec-'字符,暂时没排查出是哪来的,不过这个只影响assert,所以干脆注释掉
train.py
虽然这个代码是test phase,但不是pure test,还需要训练50epoch(都加上.eval()了结果还是可以算梯度优化,那这个.eval()到底有什么用)
看数据集调用,图像都直接读取存入内存,现在这异常检测空间换时间这么极端吗
输入16,3,256,256的img,16,1,256,256的gt(其实还有类别标签,但训练阶段没有用到,那就是说训练损失是像素级的)
CDOModel(
(model): ModuleDict(
(ME): HRNet_(
调用预训练模型(调用下载)的专家模型不计算梯度
(model): HighResolutionNet(
(conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
16,64,128,128
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
16,64,64,64
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(layer1): Sequential(
(0): Bottleneck(输入+输出的残差
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1~3): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
16,256,64,64
(transition1): ModuleList(
(0): Sequential(
(0): Conv2d(256, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): Sequential(
(0): Sequential(
(0): Conv2d(256, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
分别单独输入给这两层
然后分别得到16,32,64,64和16,64,32,32 x_list
然后再分别把这俩结果分别输入stage2的两个branch
)
(stage2): Sequential(
(0): HighResolutionModule(
(branches): ModuleList(
(0): Sequential(
(0~3): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential(
(0~3): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
然后分别得到16,32,64,64和16,64,32,32 x
)
)
~~下面的fuse_layers[i]的层数和前面的x的数量(branch的数量对应)~~
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
(fuse_layers): ModuleList(将不同分支交叉融合
(0): ModuleList(
(0): None
(1): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
也就是说x[0]16,32,64,64直接作为一个y
计算fuse_layers[0][1](x[1])得到16,32,32,32后对它双线性插值得到16,32,64,64
再和y相加后relu,存入y_list这个列表
#(relu): ReLU(inplace=True)
(1): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): None
)
这一层fuse_layers[1][0](x[0])作为y 16,64,32,32
此时i=j=1相当于相同分支,所以y直接与x[1]求和
#(relu): ReLU(inplace=True)
relu放进y_list
)
)
)
(transition2): ModuleList(
(0): None
(1): None
(2): Sequential(
(0): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
其实结果来说就是先把y_list放进清空的x_list
然后再算一下transition2[2](y_list[-1])
得到16,128,16,16放进x_list
然后分别通过下面的三个branch
)
)
(stage3): Sequential(
(0~3): HighResolutionModule(
(branches): ModuleList(
(0): Sequential(
(0~3): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential(
(0~3): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): Sequential(
(0~3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
此时得到维度不变的x
(fuse_layers): ModuleList(
(0): ModuleList(
(0): None
(1): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): Sequential(
(0): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
x[0]直接作为y
随后先后分别像上面一样依次经过fuse_layers[0][1~2](x[1~2])、插值、累加给y,最后relu给清空的y_list
(1): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): None
(2): Sequential(
(0): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
fuse_layers[1][0](x[0])作为y
x[1]直接加给y
fuse_layers[1][2](x[2])插值后再加给y
relu入组
(2): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): Sequential(
(0): Conv2d(32, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential(
(0): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): None
)
fuse_layers[2][0](x[0])作为y
fuse_layers[2][1](x[1])直接再加给y
x[2]再加给y
relu入组
)
注意这里是有三次的高像素模块
)
)
(transition3): ModuleList(
(0): None
(1): None
(2): None
(3): Sequential(
(0): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
其实结果来说就是先把y_list放进清空的x_list
然后再算一下transition3[3](y_list[-1])
得到16,256,8,8放进x_list
然后分别通过下面的四个branch
)
)
(stage4): Sequential(
(0~2): HighResolutionModule(
(branches): ModuleList(
(0): Sequential(
(0~3): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential(
(0~3): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): Sequential(
(0~3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): Sequential(
(0~3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(fuse_layers): ModuleList(
(0): ModuleList(
(0): None
(1): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): Sequential(
(0): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): Sequential(
(0): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
x[0]作为y
fuse_layers[0][1](x[1])插值再加给y
fuse_layers[0][2](x[2])插值再加给y
fuse_layers[0][3](x[3])插值再加给y
relu入组
(1): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): None
(2): Sequential(
(0): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
fuse_layers[1][0](x[0])作为y
x[1]直接再加给y
fuse_layers[1][2](x[2])插值再加给y
fuse_layers[1][3](x[3])插值再加给y
relu入组
(2): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): Sequential(
(0): Conv2d(32, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential(
(0): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): None
(3): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
fuse_layers[2][0](x[0])作为y
fuse_layers[2][1](x[1])直接再加给y
x[2]再加给y
fuse_layers[2][3](x[3])插值再加给y
relu入组
(3): ModuleList(
(0): Sequential(
(0): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(2): Sequential(
(0): Conv2d(32, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Sequential(
(0): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): Sequential(
(0): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): None
)
)
fuse_layers[3][0](x[0])作为y
fuse_layers[3][1](x[1])直接再加给y
fuse_layers[3][2](x[2])再加给y
x[3]再加给y
relu入组
)
注意这个高像素模块计算3次
)
最后只保留前三个作为x_list
其实只用到了前面的部分,最后这一部分没有调用
(last_layer): Sequential(
(0): Conv2d(480, 480, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(480, 19, kernel_size=(1, 1), stride=(1, 1))
)
)
)
(MA) 同上
)
)
从而分别有了专家和学徒的fe_list和fa_list
接下来计算损失
cal_loss
先通过双线性插值把二者中每一个特征图都调整到第一层的特征图长宽(H_0, W_0)即16,32,64,64和16,64,64,64和16,256,64,64
对应遍历每一层的fe和fa,先将mask也最近邻插值到16,1,64,64
fe和fa重塑为65536,32,mask是65532,
根据mask是否为0,分别取出fa和fe的正常区域和异常区域特征。fe_n和fa_n代表正常样本的特征(63576,32),而fe_s和fa_s代表异常(1960,32)
cal_discrepancy
以fe_n和fa_n为例,分别归一化后计算欧氏距离平方d_p,并有其均值 mu_p
自适应计算权重:
对于正常样本,权重计算为((d_p) / mu_p) ** gamma。
对于异常样本,权重计算为((mu_p) / d_p) ** gamma。(等一下,训练的时候为啥会有异常?!)
再聚合,也就是计算加权的特征差异性损失,d_p=torch.sum(d_p*w)
sum_w=torch.sum(w)
从而 对于正常和异常的特征计算得到loss_n、weight_n、loss_s、weight_s
loss += ((loss_n - loss_s) / (weight_n + weight_s) * B)其中B是batchsize
然后测试阶段
取数据有data 16,3,256,256;mask 16,1,256,256;label 16个01标签组成的tensor;name 16个类似bagel_combined_000组成的tuple
先将data逆标准化(乘方差,加均值,乘255,uint8)得到256,256,3组成的列表test_imgs
label转成列表 gt_list
mask转成256,256组成的列表 gt_mask_list
但网络中输入的还是一开始的data
从而有outputs
然后计算评估指标
cal_am
同样先对专家和学徒的fe_list和fa_list通过双线性插值把二者中每一个特征图都调整到第一层的特征图长宽(H_0, W_0)即16,32,64,64和16,64,64,64和16,256,64,64
对应遍历每一层的fe和fa,直接整体视为异常样本计算d_p(视作异常样本其实也就影响OOM自适应计算权重,但是反正这里不自适应计算权重了,所以其实没啥影响)至于这里没有二维化,而是直接输入四维张量,是因为二维化可以方便根据掩码区分正常和异常的像素点,以便分别计算它们的损失,这里不需要区分,所以输入四维张量没有影响
cal_discrepancy
这一次不自适应计算权重
不聚合d_p(这样的话其实权重都根本没有用到)
从而有16,64,64的d_p-》a_map 16,1,64,64,再双线性插值到16,1,256,256
从而遍历每一层的fe和fa的过程中累加这个a_map,再压缩得到16,256,256

随后遍历,分别经过高斯滤波后有am_np_list 16个256,256ndarray组成的列表,这也就是score

当把所有测试数据遍历完,再把所有的score做成110,256,256的ndarray,和gt_mask_list、gt_list一起送入metric_cal
issue里提到AU-PRO的计算过程确实很耗时,所以不到最后不计算
metric_cal
对于AUC很简单直接调包完事
至于pro
cal_pro_metric
输入:labeled_imgs是110个256,256的ndarray组成的列表,score_imgs是110,256,256的ndarray
- 二值化标签图:首先,将labeled_imgs(标签图)中的像素值二值化。小于或等于0.45的值被设置为0(非异常),大于0.45的值被设置为1(异常)。然后,将标签图转换为布尔类型,以便后续处理。
- 初始化变量:定义存储不同阈值下的平均IOU(交并比)、IOU的标准差、平均PRO、PRO的标准差、阈值和假正率(FPR)的列表。
- 阈值迭代:通过在score_imgs的最大和最小值之间生成一系列阈值,分别根据阈值逐步将score_imgs(分数图)二值化(大于阈值为1,否则为0),创建二进制得分图binary_score_maps。对于每个阈值:
- a. 计算PRO:对于每个标签图,使用measure.label找到连通区域,并对每个区域计算其与二值化得分图的重叠部分。这是通过计算交集除以实际区域的面积来完成的。
通过measure.regionprops计算得到的props,它代表了标签图labeled_imgs[i]中的所有连通区域的属性
- 获取边界框:prop.bbox提供了连通区域的边界框(x_min, y_min, x_max, y_max)。这个边界框定义了包含当前连通区域的最小矩形。
(根据真实异常区域裁剪出一个roi框区域)- 裁剪预测标签:使用边界框从二进制得分图binary_score_maps[i]中裁剪出对应的预测区域cropped_pred_label。
(把预测异常掩码放到roi上)- 裁剪实际标签:虽然原始代码中有注释指向masks,但实际使用的是prop.filled_image,它表示的是填充的区域图像,即当前连通区域内部的像素标记为True,外部的像素标记为False。
(真实异常掩码在roi上)- 计算交集:通过np.logical_and(cropped_pred_label, cropped_mask)计算预测区域和实际区域之间的交集。这里的交集是指两者同时为True的像素点。
- 计算PRO值:PRO值是交集的像素数除以连通区域的面积(prop.area),这表示预测正确的区域占实际异常区域的比例。
- b. 计算IOU:对于每幅图像,计算标签图和二值化得分图的交并比(IOU)。这是通过计算交集除以并集来完成的。
(可以认为pro更关注于每个独立异常区域的检测效果,而iou是整幅图像级别的平均表现,但是最终这个代码里并没有用到iou,怪不得作者觉得耗时间?)- c. 存储结果:将每个步骤计算的IOU和PRO的平均值和标准差存储起来。
- 计算FPR:对于每个阈值,计算假正率,即错误标记为异常的非异常像素占所有非异常像素的比例。
masks_neg=~labeled_imgs,代表所有非异常(背景)的像素。fpr是在当前阈值下,将背景像素错误分类为异常的比例,即假正率。这是通过计算二值化得分图(binary_score_maps)与masks_neg的逻辑与操作的结果中True值的数量,除以masks_neg中True值的总数量得到的。
- 计算PRO-AUC:在特定的FPR阈值(如0.3)下,计算PRO曲线下的面积(PRO-AUC)。这是通过插值方法在限定的FPR下对PRO值进行积分得到的
(说的是auc函数内部操作)。idx = fprs <= fpr_thresh筛选出所有小于或等于fpr_thresh(0.3)的FPR值的索引
fprs_selected = fprs[idx]选取了低于FPR阈值的FPR值,而pros_mean_selected = pros_mean[idx]选取了对应的PRO平均值。(fprs、pros_mean对应阈值数量)
将fprs_selected的范围从[0, fpr_thresh]归一化到[0, 1],这是因为标准的AUC计算假设FPR的范围是[0, 1]。
使用auc(fprs_selected, pros_mean_selected)计算选定FPR范围内的PRO曲线下的面积(PRO-AUC)。auc函数通常是根据FPR排序的点来计算曲线下面积的,所以输入的FPR和PRO值需要按FPR升序排列。
对比了一下和shape-guided的区别
- 计算面积:sg显式地使用梯形法则来计算PRO曲线下的面积,而cdo是调用auc函数
- 阈值的选择:SG方法通过在预测分数的分布中np.linspace均匀选择阈值,而cdo方法在最大和最小预测分数之间均匀取步长来确定阈值。
- 数据结构:SG方法将预测和真实标签作为二维numpy浮点数组处理,而cdo方法处理的是布尔类型的二维numpy数组。
- 组件处理:SG方法中一直都是用的整张图的gt掩码来计算重叠,而cdo方法虽然一开始有binary_score_maps,但后面截了roi,是再生成一个cropped_mask得到的区域掩码。
- 假阳性率(FPR):SG方法计算每个阈值下的假阳性率(FPR),并将其与PRO值一起用于评估,而cdo方法中主要关注于预设特定阈值0.3的FPR。并且sg里是根据像素比例计算fpr,而cdo是逻辑与直接计算