无重复字符的最长子串
- 1. 题目解析
- 2. 讲解算法原理
- 3. 编写代码
1. 题目解析
题目地址:无重复字符的最长子串

2. 讲解算法原理
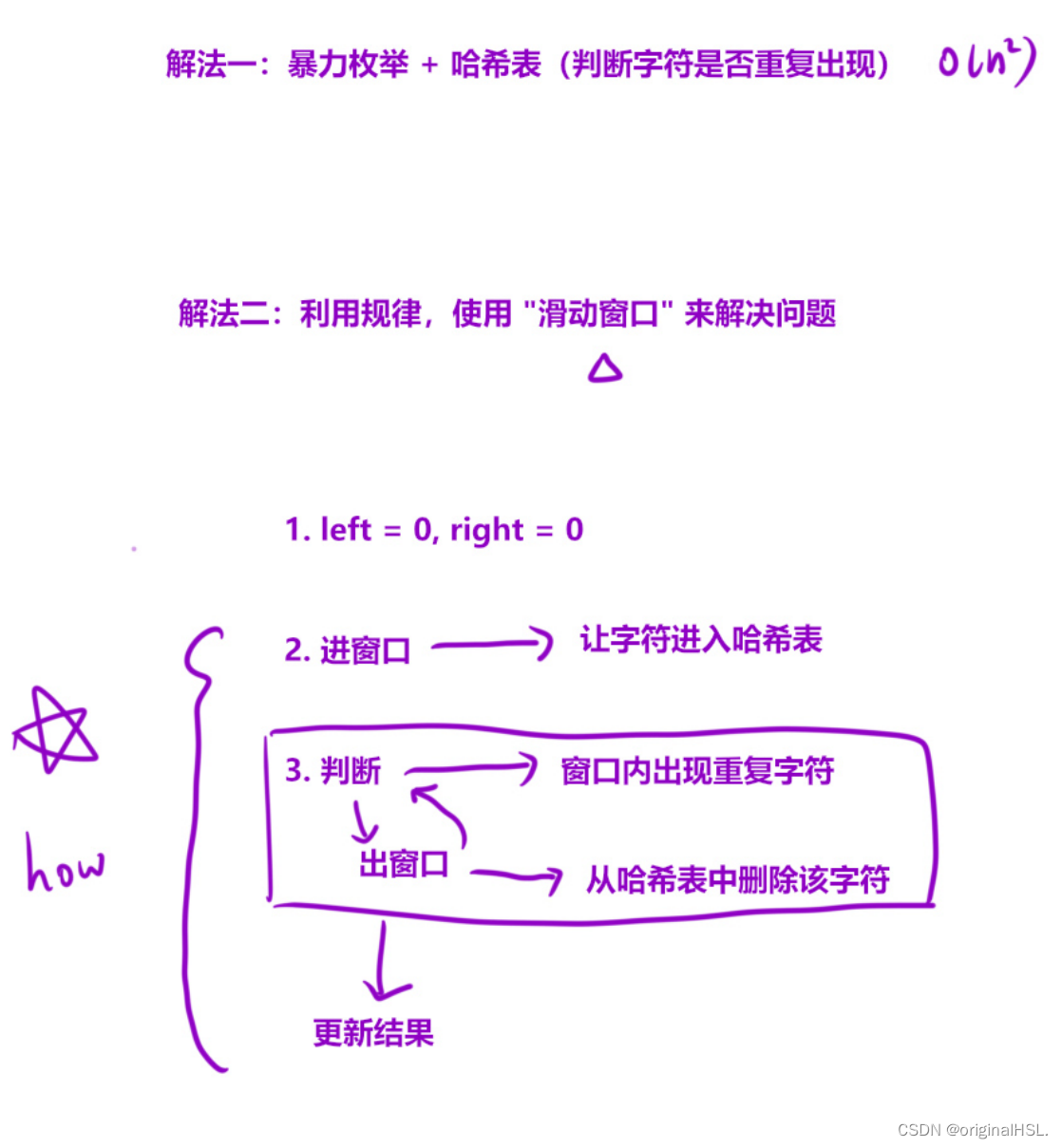
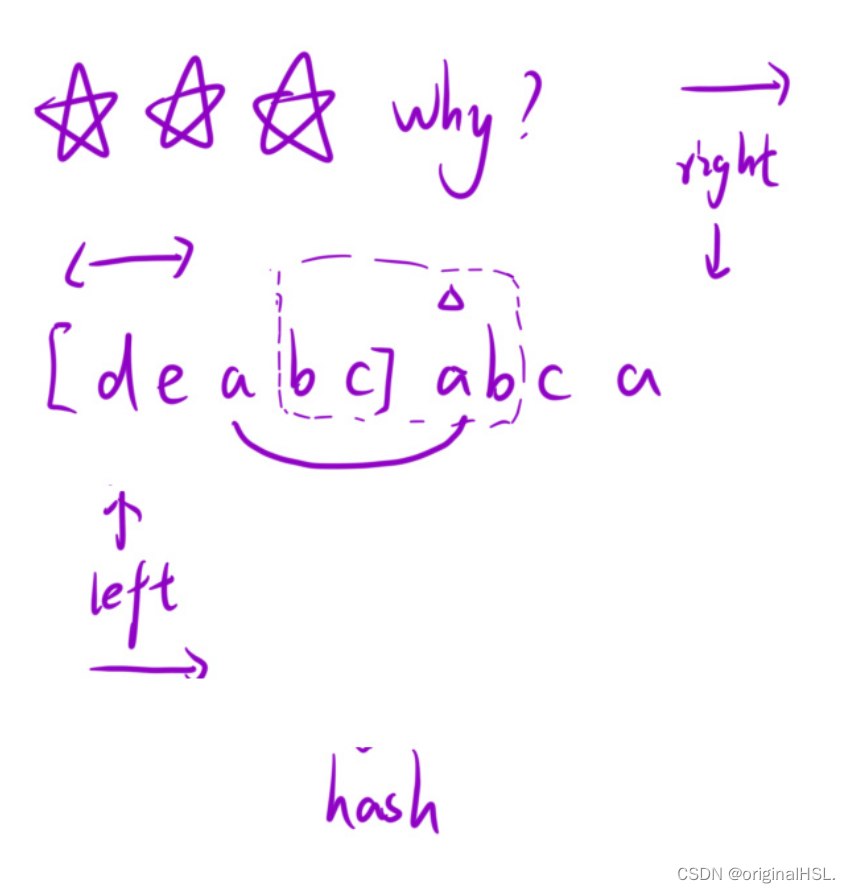
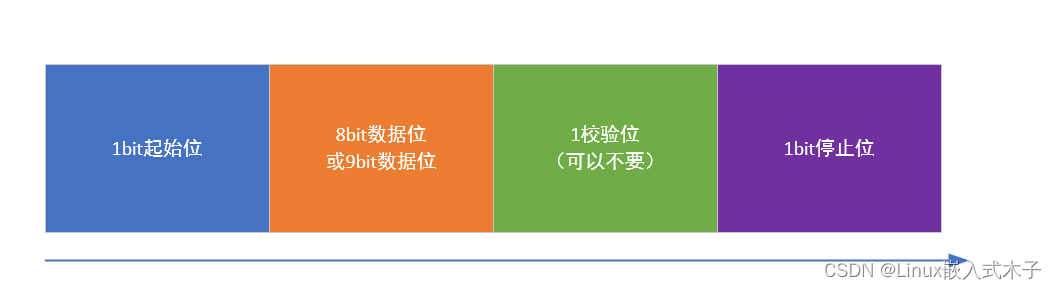
首先定义了变量 left、right 和 len,分别表示当前无重复子串的左边界、右边界和最大长度。
获取输入字符串 s 的长度 n。
定义一个大小为 128 的数组 hash,用于记录字符出现的次数。数组的下标表示字符的 ASCII 值,初始值都为 0。
进入循环,循环条件是 right 小于 n。
在循环中,首先将当前字符 s[right] 在 hash 数组中的计数加1。
接着,进入一个内层循环,该循环的条件是当前字符 s[right] 在 hash 数组中的计数大于1,即表示出现了重复字符。
在内层循环中,将左边界字符 s[left] 在 hash 数组中的计数减1,并将左边界 left 向右移动一位。
内层循环结束后,表示当前窗口内已经没有重复字符了。通过 right-left+1 计算当前无重复子串的长度,并更新 len 的值。
将右边界 right 向右移动一位,继续下一轮循环。
循环结束后,如果输入字符串长度为 1,则返回 1,否则返回最长无重复子串的长度 len。
3. 编写代码
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int left=0,right=0,len=0;
int n=s.size();
int hash[128]={0};
while(right<n)
{
hash[s[right]]++;
while(hash[s[right]]>1)
{
hash[s[left]]--;//出窗口
left++;
}
len=max(len,right-left+1);//更新结果
right++;
}
if(n==1)
return 1;
return len;
}
};