本文整理自阿里云开源大数据平台吕宴全关于新一代实时数据集成框架 Flink CDC 3.0 的核心技术架构解析,内容主要分为以下四部分:
Flink CDC 演进历程
Flink CDC 3.0 的架构设计
Flink CDC 3.0 的核心实现
未来规划
一、Flink CDC 演进历程
Flink CDC 是基于数据库日志 CDC(Change Data Capture)技术的实时数据集成框架,配合 Flink 优秀的管道能力和丰富的上下游生态,Flink CDC 可以高效实现海量数据的实时集成。
在 2020 年 7 月,Flink CDC 作为一个基于个人兴趣孵化的项目合并了第一个 commit,拉开了 Flink CDC 实时数据集成的篇章,让用户只创建一个简单的 Flink SQL 作业就能完成 CDC 数据的同步、加工和分析。这个阶段里存在通过加锁保证一致性,并且不支持水平拓展的问题,Flink CDC 参考 DBLog 论文的设计,实现了无锁并发读取的全增量同步,完成了从 1.0 到 2.0 的升级。
Flink CDC 2.0 受到了广大用户的好评,不过在广泛应用的过程中,也暴露出了一些有待提升的地方,需要提升的部分主要包括通过 SQL 定义表结构的方式,在上游表发生加减列时需要手动调整作业;在整库同步的场景下需要为每一张表创建一个作业,占用连接多,计算资源消耗大等。在社区用户与开发者的共同努力下,Flink CDC 于 2023 年 12 月完成了 3.0 版本的功能落地,提供了强大的端到端的全增量同步、表结构变更自动同步、整库同步、分库分表同步等高级特性,有效地解决了用户的痛点。
二、Flink CDC 3.0 的架构设计
Flink CDC 3.0 的核心特性包括:
-
端到端数据集成,用户只需要配置一个 YAML 文件就能快速构建数据入湖入仓作业
-
完整的数据同步,全量读取结束自动同步增量数据,并且上游表结构变更自动应用到下游
-
一个作业实例支持读取和写入多表,占用数据库连接少,增量读取阶段自动关闭空闲读取器,节省计算资源
Flink CDC 3.0 的整体架构自顶而下分为 4 层:
- Flink CDC API:面向终端用户的 API 层,用户使用 YAML 格式配置数据同步流水线,使用 Flink CDC CLI 提交任务
- Flink CDC Connect:对接外部系统的连接器层,通过对 Flink 与现有 Flink CDC source 进行封装实现对外部系统同步数据的读取和写入
- Flink CDC Composer:同步任务的构建层,将用户的同步任务翻译为 Flink DataStream 作业
- Flink CDC Runtime:运行时层,根据数据同步场景高度定制 Flink 算子,实现 schema 变更、路由、变换等高级功能

三、Flink CDC 3.0 的核心实现
1. 数据抽象
Event 是 Flink CDC 3.0 内部进行数据处理及传输的数据结构接口,其作用类似于 Flink SQL 中的 RowData 接口。Event 目前所有的实现如下图所示。
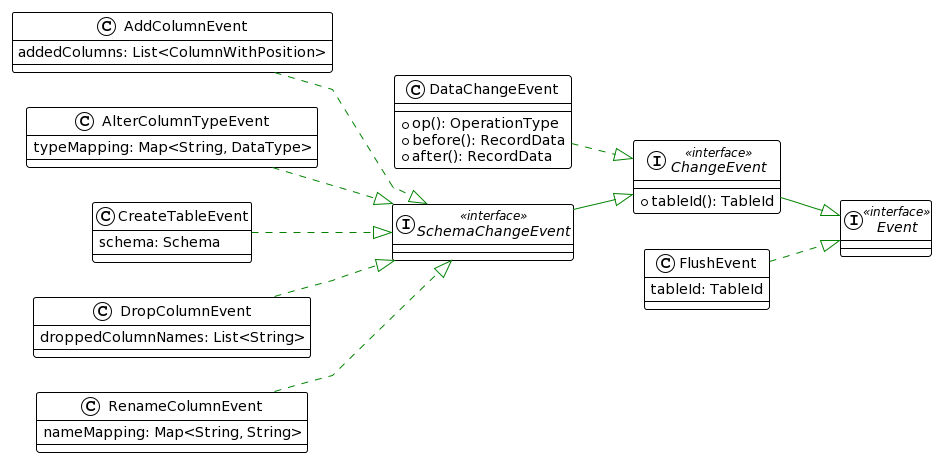
1.1 ChangeEvent
ChangeEvent 接口代表着在一张表上发生过的变更事件,实现类包括数据变更事件(即 DataChangeEvent 类)和表结构变更事件(即继承 SchemaChangeEvent 接口的类)两种:DataChangeEvent 里保存了完整的数据变更信息,即包含了变更前(before)和变更后(after)每条记录的字段值;SchemaChangeEvent 有增加列、删除列、修改列类型等实现。
Flink CDC 把表结构变更信息当成一种事件流转,这样能够避免在数据变更事件里保存类型信息,需要从 DataChangeEvent 读取数据的节点会基于 SchemaChangeEvent 维护表结构信息。Flink CDC 还实现了自己的序列化器,每条记录使用二进制的方式存储在 Flink 的 MemorySegment 中,通过这种底层结构的优化设计,有效提高在不同节点之间数据流转的效率。
1.2 FlushEvent
FlushEvent 是包含数据刷写控制逻辑的特殊事件。当发生表结构变更事件后,之前的数据可能尚未处理完,链路上会并存两种不同表结构的数据。大部分数据库不允许直接在同一批次中混合处理两种表格式的数据,在处理新版本的数据之前,必须确保旧版本的数据已全部完成刷写操作。FlushEvent 作用是间隔这两种数据,在 Sink 端接受到 FlushEvent 后,就需要将之前缓存的数据全部刷写出去。
2. 算子编排
FlinkCDC 根据数据集成的场景,深度定制了 Flink DataStream 的算子链路,目前制定的数据处理链路如下图所示:

下面对这些模块的具体实现做进一步的介绍。
2.1 Source
Source 模块负责生产在链路中流转的变更事件。FlinkCDC 2.0 提供了强大的全增量同步、并发读取的能力,已经能够生成包含各类变更事件信息的 SourceRecord 对象,在此基础上,只需要再实现一个将 SourceRecord 解析成前面介绍的各种表变更事件的 DebeziumDeserializationSchema 自定义转换器,就能完成 FlinkCDC 3.0 数据源的接入。
在第一次启动时,Source 模块需要先拉取表结构信息,并生成 CreateTableEvent 发送到下游中,这是为了让下游节点能够解析 DataChangeEvent。
在 FlinkCDC 里,添加了丰富的 DDL 解析器来辅助数据库变更事件生成。具体来说,通过在 Alter 语句的解析树中每个规则(诸如语句、表达式和字面量等)的进入(Enter)和退出(Exit)阶段添加自定义逻辑,能够生成我们需要的各种 SchemaChangeEvent。以删除列的生成逻辑为例,在 CustomAlterTableParserListener 类的 enterAlterByDropColumn 方法中获取到被删除的列的列名,可以据此生成一个 DropColumnEvent 事件。
public void enterAlterByDropColumn(MySqlParser.AlterByDropColumnContext ctx) {
String removedColName = parser.parseName(ctx.uid());
changes.add(new DropColumnEvent(currentTable, Collections.singletonList(removedColName)));
super.enterAlterByDropColumn(ctx);
}
2.2 Transform
在当前版本暂未实现。
2.3 Schema
在发生表结构变更事件以后,Schema 模块负责阻塞上游数据的继续发放,直到旧版本格式数据刷写完毕。这个逻辑需要通过 FlushEvent 来传递,由于下游可能存在多个 Sink,需要通过运行在 JobManager 上的一个 OperatorCoordinator 来进行管控,这个 OperatorCoordinator 称为 SchemaRegistry。
具体来说,处理表结构变更的流程如下图所示:
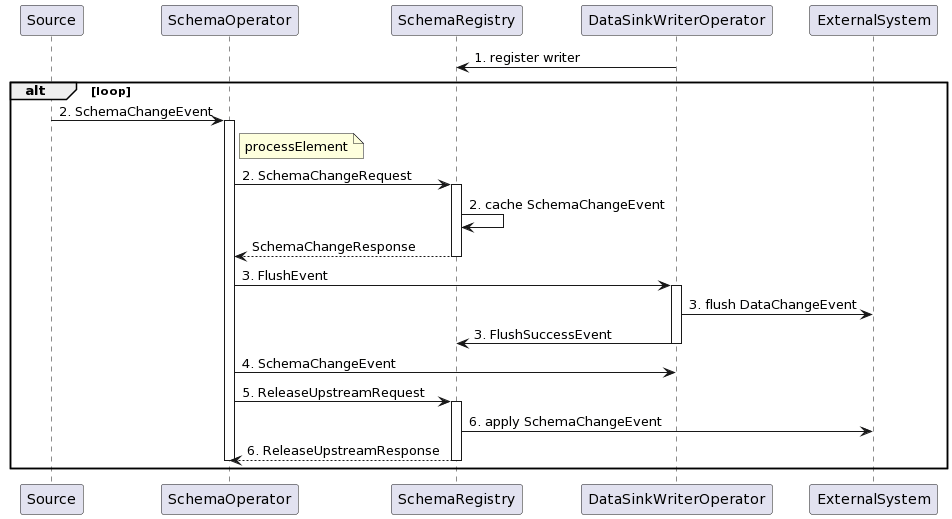
- 在程序启动时,所有的 Sink Operator 都向 SchemaRegistry 注册,SchemaRegistry 记录 Writer 的数量。
- 在收到来自 Source 的 SchemaChangeEvent 时,SchemaOperator 发送一个包含本次表结构变更事件的 SchemaChangeRequest 给 SchemaRegistry,让 SchemaRegistry 缓存这个 SchemaChangeEvent。
- SchemaOperator 下发一个 FlushEvent 给所有的 Sink Operator,Sink Operator 接收到 FlushEvent 后刷写数据到外部系统,并且发送 FlushSuccessEvent 向 SchemaRegistry 进行汇报。SchemaRegistry 据此统计响应的 Writer 数量。
- SchemaOperator 下发 SchemaChangeEvent 给所有的 Sink Operator,让 Sink Operator 更新对应表的序列化器。
- SchemaOperator 发送一个 ReleaseUpstreamRequest 给 SchemaRegistry,并且开始阻塞自身,不再处理任何变更事件,直到收到 SchemaRegistry 的回应。
- SchemaRegistry 接收到 FlushSuccessEvent 以后,会和第 1 步中注册的 Sink Operator 进行比较,如果所有的 Sink Operator 都已刷写完毕,则开始将第 2 步中受到的 SchemaChangeEvent 应用到外部系统中,并且对第 4 步接收到的 ReleaseUpstreamRequest 进行回应。这样,SchemaOperator 就可以开始继续传递新的数据变更时和表结构变更事件了。
2.4 Route
Route 模块提供了表名映射的能力。通过为每一个源表中的数据设置其写入的目标表,通过一对一以及多对一的映射配置,我们能够实现整库同步和简单的分库分表同步功能。
Route 模块基于 Flink 的 RichMapFunction 实现,允许通过 source-table 指定一个正则表达式规则,将一系列符合正则表达式规则的表名,替换到另外一个由 sink-table 指定的表名。RouteFunction 的核心代码如下:
public Event map(Event event) throws Exception {
ChangeEvent changeEvent = (ChangeEvent) event;
TableId tableId = changeEvent.tableId();
for (Tuple2<Selectors, TableId> route : routes) {
Selectors selectors = route.f0;
TableId replaceBy = route.f1;
if (selectors.isMatch(tableId)) {
return recreateChangeEvent(changeEvent, replaceBy);
}
}
return event;
}
2.5 Partition
在数据同步场景,数据的生产和消费的速率常常是不匹配的,用户希望能够通过增加 Sink 的并发度来提高数据处理的速率。Partition 模块负责分发事件到不同的 Sink 中。
在 Partition 阶段,数据变更事件按照表名和主键作为哈希键,保证同一张表中相同主键的数据不会因数据分发出现乱序的情况。哈希键的计算方式如下所示:
public Integer apply(DataChangeEvent event) {
List<Object> objectsToHash = new ArrayList<>();
// Table ID
TableId tableId = event.tableId();
Optional.ofNullable(tableId.getNamespace()).ifPresent(objectsToHash::add);
Optional.ofNullable(tableId.getSchemaName()).ifPresent(objectsToHash::add);
objectsToHash.add(tableId.getTableName());
// Primary key
RecordData data =
event.op().equals(OperationType.DELETE) ? event.before() : event.after();
for (RecordData.FieldGetter primaryKeyGetter : primaryKeyGetters) {
objectsToHash.add(primaryKeyGetter.getFieldOrNull(data));
}
// Calculate hash
return (Objects.hash(objectsToHash.toArray()) * 31) & 0x7FFFFFFF;
}
同时由于 Sink 模块需要维护表结构信息,对于表结构变更事件,需要广播到每一个并发里。对于控制数据刷写的 FlushEvent,也需要广播到每一个下游的每一个通道里。

其代码实现如下:
public void processElement(StreamRecord<Event> element) throws Exception {
Event event = element.getValue();
if (event instanceof SchemaChangeEvent) {
// Update hash function
TableId tableId = ((SchemaChangeEvent) event).tableId();
cachedHashFunctions.put(tableId, recreateHashFunction(tableId));
// Broadcast SchemaChangeEvent
broadcastEvent(event);
} else if (event instanceof FlushEvent) {
// Broadcast FlushEvent
broadcastEvent(event);
} else if (event instanceof DataChangeEvent) {
// Partition DataChangeEvent by table ID and primary keys
partitionBy(((DataChangeEvent) event));
}
}
2.6 Sink
在 Sink 模块,需要将数据写出到外部系统中,并且将表结构变更应用到外部系统中。FlinkCDC 的 DataSink API 提供了 EventSinkProvider 和 MetaDataApplier 接口去完成这两件事情。
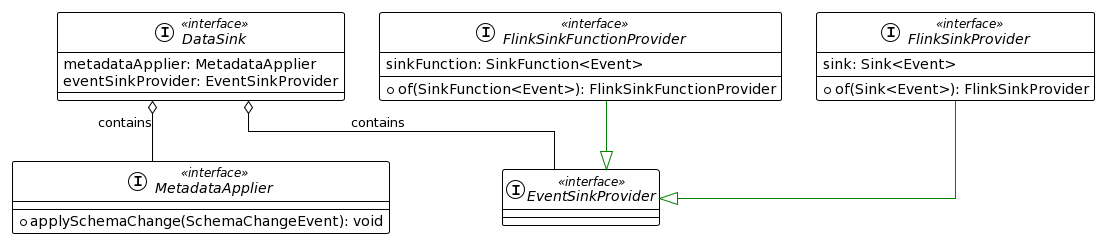
EventSinkProvider 用于将表数据变更应用到外部系统中。EventSinkProvider 要求提供一个基于 Flink SinkFunction 或者是 Flink Sink API 的实现,并且具备写出到多个表的能力。以 Flink Sink API 为例,SinkWriter 需要从 DataChangeEvent 中取出变更数据,并写出到对应的表中。当处理到 SchemaChangeEvent 时, SinkWriter 更新内存中保存的表结构信息。当处理到 FlushEvent 时, Sink Operator 会调用 SinkWriter 的 flush 方法将数据刷写出去。
MetaDataApplier 用于将表结构变更应用到外部系统中。在 SchemaRegistry 接受到所有的 Sink 算子处理完 FlushEvent 的通知后,由 SchemaRegistry 负责调用 MetaDataApplier 的 applySchemaChange方法去应用表结构变更事件。考虑到任务重启的情况,MetaDataApplier 需要支持对一个表结构变更事件幂等处理。
四、未来规划
Flink CDC 社区致力于持续深化数据同步与处理的全面性和灵活性。在 Flink CDC 3.0 里,针对数据集成场景定制了高效的数据格式和算子编排,实现了对表结构变更同步和整库同步的支持。基于未来的演进规划,社会将会着重关注完善 Transform 模块的功能,以满足用户对数据同步过程中的深度定制需求。计划在下一个大版本中,支持表结构动态调整,包括裁剪不必要的列、添加计算列等功能,以及提供数据过滤能力,让用户能够在同步过程中一站式完成复杂的数据转换任务。
此外,在连接器生态建设方面,社区正着手接入 Kafka、PostgreSQL 等业界主流的数据源,以及 Paimon、Iceberg 等先进的湖仓存储系统。进一步拓宽 Flink CDC 的上下游数据集成范围,推动上下游组件的深度融合。