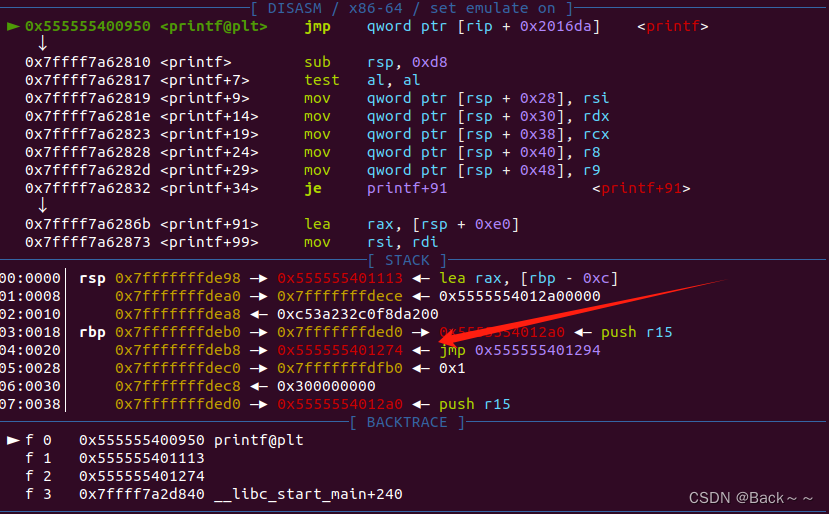
算法效率评估
时间效率:算法运行速度的快慢。
空间效率:算法占用内存空间的大小。
效率评估方法主要分为两种:实际测试、理论估算
实际测试问题:
1.难以排除测试环境的干扰因素。
硬件配置会影响算法的性能。需要在各种机器上进行测试,统计平均效率,而这是不现实的。
2.展开完整测试非常耗费资源。
随着输入数据量的变化,算法会表现出不同的效率。因此,为了得到有说服力的结论,需要测试各种规模的输入数据,而这需要耗费大量的计算资源。
由于实际测试具有较大的局限性,因此我们可以考虑仅通过一些计算来评估算法的效率。这种估算方法被称为渐近复杂度分析 (asymptotic complexity analysis),简称复杂度分析。
复杂度分析能够体现算法运行所需的时间和空间资源与输入数据大小之间的关系。它描述了随着输入数据大小的增加,算法执行所需时间和空间的增长趋势。
1.“时间和空间资源”分别对应时间复杂度(time complexity)和空间复杂度(space complexity)。
2.“随着输入数据大小的增加”意味着复杂度反映了算法运行效率与输入数据体量之间的关系。
3.“时间和空间的增长趋势”表示复杂度分析关注的 不是运行时间或占用空间的具体值,而是时间或空间增长的“快慢”。
复杂度分析克服了实际测试方法的弊端:
1.独立于测试环境,分析结果适用于所有运行平台;
2.可以体现不同数据量下的算法效率,尤其是在大数据量下的算法性能。
迭代与递归
迭代(iteration) 是一种重复执行某个任务的控制结构。在迭代中,程序会在满足一定的条件下重复执行某段代码,直到这个条件不再满足。
/**
* File: iteration.cpp
* Created Time: 2023-08-24
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* for 循环 */
int forLoop(int n) {
int res = 0;
// 循环求和 1, 2, ..., n-1, n
for (int i = 1; i <= n; ++i) {
res += i;
}
return res;
}
/* while 循环 */
int whileLoop(int n) {
int res = 0;
int i = 1; // 初始化条件变量
// 循环求和 1, 2, ..., n-1, n
while (i <= n) {
res += i;
i++; // 更新条件变量
}
return res;
}
/* while 循环(两次更新) */
int whileLoopII(int n) {
int res = 0;
int i = 1; // 初始化条件变量
// 循环求和 1, 4, 10, ...
while (i <= n) {
res += i;
// 更新条件变量
i++;
i *= 2;
}
return res;
}
/* 双层 for 循环 */
string nestedForLoop(int n) {
ostringstream res;
// 循环 i = 1, 2, ..., n-1, n
for (int i = 1; i <= n; ++i) {
// 循环 j = 1, 2, ..., n-1, n
for (int j = 1; j <= n; ++j) {
res << "(" << i << ", " << j << "), ";
}
}
return res.str();
}
/* Driver Code */
int main() {
int n = 5;
int res;
res = forLoop(n);
cout << "\nfor 循环的求和结果 res = " << res << endl;
res = whileLoop(n);
cout << "\nwhile 循环的求和结果 res = " << res << endl;
res = whileLoopII(n);
cout << "\nwhile 循环(两次更新)求和结果 res = " << res << endl;
string resStr = nestedForLoop(n);
cout << "\n双层 for 循环的遍历结果 " << resStr << endl;
return 0;
}

递归 (recursion) 是一种算法策略,通过函数调用自身来解决问题。它主要包含两个阶段:
1.递:程序不断深入地调用自身,通常传入更小或更简化的参数,直到达到“终止条件”。
2.归:触发“终止条件”后,程序从最深层的递归函数开始逐层返回,汇聚每一层的结果。
/**
* File: recursion.cpp
* Created Time: 2023-08-24
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 递归 */
int recur(int n) {
// 终止条件
if (n == 1)
return 1;
// 递:递归调用
int res = recur(n - 1);
// 归:返回结果
return n + res;
}
/* 使用迭代模拟递归 */
int forLoopRecur(int n) {
// 使用一个显式的栈来模拟系统调用栈
stack<int> stack;
int res = 0;
// 递:递归调用
for (int i = n; i > 0; i--) {
// 通过“入栈操作”模拟“递”
stack.push(i);
}
// 归:返回结果
while (!stack.empty()) {
// 通过“出栈操作”模拟“归”
res += stack.top();
stack.pop();
}
// res = 1+2+3+...+n
return res;
}
/* 尾递归 */
int tailRecur(int n, int res) {
// 终止条件
if (n == 0)
return res;
// 尾递归调用
return tailRecur(n - 1, res + n);
}
/* 斐波那契数列:递归 */
int fib(int n) {
// 终止条件 f(1) = 0, f(2) = 1
if (n == 1 || n == 2)
return n - 1;
// 递归调用 f(n) = f(n-1) + f(n-2)
int res = fib(n - 1) + fib(n - 2);
// 返回结果 f(n)
return res;
}
/* Driver Code */
int main() {
int n = 5;
int res;
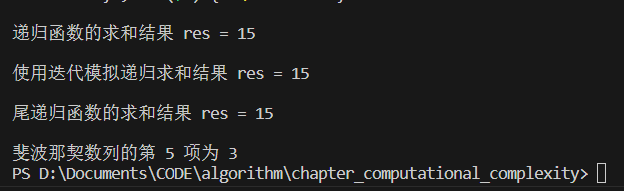
res = recur(n);
cout << "\n递归函数的求和结果 res = " << res << endl;
res = forLoopRecur(n);
cout << "\n使用迭代模拟递归求和结果 res = " << res << endl;
res = tailRecur(n, 0);
cout << "\n尾递归函数的求和结果 res = " << res << endl;
res = fib(n);
cout << "\n斐波那契数列的第 " << n << " 项为 " << res << endl;
return 0;
}
递归:1+2+…+n
/* 递归 */
int recur(int n) {
// 终止条件
if (n == 1)
return 1;
// 递:递归调用
int res = recur(n - 1);
// 归:返回结果
return n + res;
}

调用栈
递归函数每次调用自身时,系统都会为新开启的函数分配内存,以存储局部变量、调用地址和其他信息等。
这将导致两方面的结果:
1.函数的上下文数据都存储在称为“栈帧空间”的内存区域中,直至函数返回后才会被释放。因此,递归通常比迭代更加耗费内存空间。
2.递归调用函数会产生额外的开销。因此递归通常比循环的时间效率更低。
栈顺序:先入后出
尾递归
如果函数在返回前的最后一步才进行递归调用,则该函数可以被编译器或解释器优化,使其在空间效率上与迭代相当。这种情况被称为尾递归 (tail recursion)。
许多编译器或解释器并不支持尾递归优化,如 Python,即使函数是尾递归形式,仍然可能会遇到栈溢出问题。
普通递归:当函数返回到上一层级的函数后,需要继续执行代码,因此系统需要保存上一层调用的上下文。
尾递归:递归调用是函数返回前的最后一个操作,这意味着函数返回到上一层级后,无须继续执行其他操作,因此系统无须保存上一层函数的上下文。
/* 尾递归 */
int tailRecur(int n, int res) {
// 终止条件
if (n == 0)
return res;
// 尾递归调用
return tailRecur(n - 1, res + n);
}
普通递归:求和操作是在“归”的过程中执行的,每层返回后都要再执行一次求和操作。
尾递归:求和操作是在“递”的过程中执行的,“归”的过程只需层层返回。

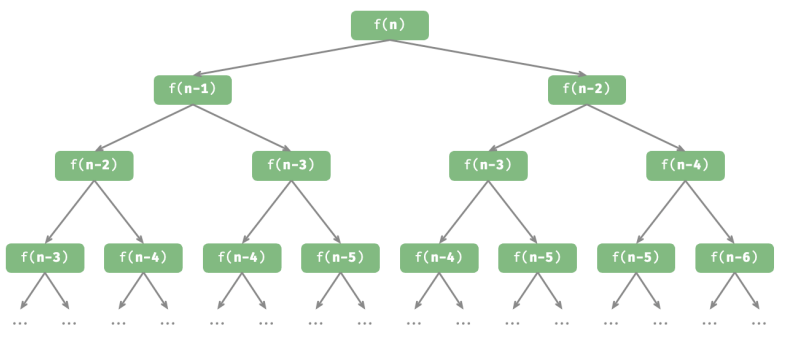
递归树
给定一个斐波那契数列 0, 1, 1, 2, 3, 5, 8, 13, … ,求该数列的第 𝑛 个数字:
/* 斐波那契数列:递归 */
int fib(int n) {
// 终止条件 f(1) = 0, f(2) = 1
if (n == 1 || n == 2)
return n - 1;
// 递归调用 f(n) = f(n-1) + f(n-2)
int res = fib(n - 1) + fib(n - 2);
// 返回结果 f(n)
return res;
}
在函数内递归调用了两个函数,这意味着从一个调用产生了两个调用分支。如图 所示,这样不断递归调用下去,最终将产生一棵层数为 𝑛 的递归树(recursion tree)。
从本质上看,递归体现了“将问题分解为更小子问题”的思维范式,这种分治策略至关重要。
从算法角度看,搜索、排序、回溯、分治、动态规划等许多重要算法策略直接或间接地应用了这种思维方式。
从数据结构角度看,递归天然适合处理链表、树和图的相关问题,因为它们非常适合用分治思想进行分析。
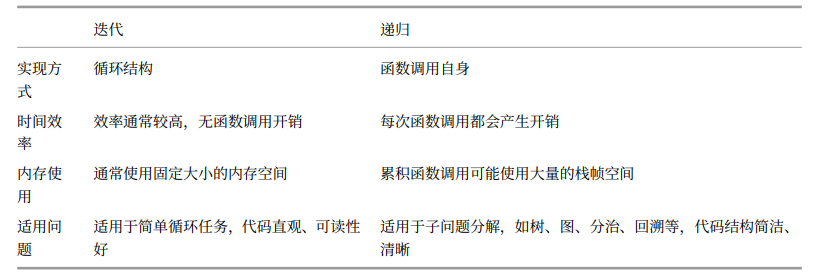
两者对比
事实上,“调用栈”和“栈帧空间”这类递归术语已经暗示了递归与栈之间的密切关系。
1.递:当函数被调用时,系统会在“调用栈”上为该函数分配新的栈帧,用于存储函数的局部变量、参数、返回地址等数据。
2.归:当函数完成执行并返回时,对应的栈帧会被从“调用栈”上移除,恢复之前函数的执行环境。
因此,可以使用一个显式的栈来模拟调用栈的行为,从而将递归转化为迭代形式:
/* 使用迭代模拟递归 */
int forLoopRecur(int n) {
// 使用一个显式的栈来模拟系统调用栈
stack<int> stack;
int res = 0;
// 递:递归调用
for (int i = n; i > 0; i--) {
// 通过“入栈操作”模拟“递”
stack.push(i);
}
// 归:返回结果
while (!stack.empty()) {
// 通过“出栈操作”模拟“归”
res += stack.top();
stack.pop();
}
// res = 1+2+3+...+n
return res;
}
尽管迭代和递归在很多情况下可以互相转化,但不一定值得这样做,有以下两点原因:
1.转化后的代码可能更加难以理解,可读性更差;
2.对于某些复杂问题,模拟系统调用栈的行为可能非常困难;
总之,选择迭代还是递归取决于特定问题的性质。
时间复杂度
运行时间可以直观且准确地反映算法的效率。
1.确定运行平台,包括硬件配置、编程语言、系统环境等,这些因素都会影响代码的运行效率;
2.评估各种计算操作所需的运行时间;
3.统计代码中所有的计算操作,并将所有操作的执行时间求和,从而得到运行时间。
实际上,统计算法的运行时间既不合理也不现实。首先,我们不希望将预估时间和运行平台绑定,因为算法需要在各种不同的平台上运行。其次,我们很难获知每种操作的运行时间,这给预估过程带来了极大的难度。
统计时间增长趋势
时间复杂度分析统计的不是算法运行时间,而是算法运行时间随着数据量变大时的增长趋势。
/* 常数阶 */
//虽然运行时间很长,但它与输入数据大小 n 无关
int constant(int n) {
int count = 0;
int size = 100000;
for (int i = 0; i < size; i++)
count++;
return count;
}
/* 线性阶 */
int linear(int n) {
int count = 0;
for (int i = 0; i < n; i++)
count++;
return count;
}
相较于直接统计算法的运行时间,时间复杂度分析的特点:
1.时间复杂度能够有效评估算法效率;
2.时间复杂度的推算方法更简便;
3. 时间复杂度也存在一定的局限性。
函数渐近上界
将线性阶的时间复杂度记为
O
(
n
)
O(n)
O(n) ,这个数学符号称为大 O 记号 big‑ Onotation,表示函数 𝑇(n)的渐近上界 (asymptotic upper bound).


计算渐近上界就是寻找一个函数
f
(
n
)
f(n)
f(n) ,使得当
n
n
n 趋向于无穷大时,
T
(
n
)
T(n)
T(n) 和
f
(
n
)
f(n)
f(n) 处于相同的增长级别,仅相差一个常数项 c 的倍数。
推算方法
第一步:统计操作数量:
a.操作数量 𝑇(𝑛) 中的各种系数、常数项都可以忽略;
b.循环嵌套时使用乘法。总操作数量等于外层循环和内层循环操作数量之积。
第二步:判断渐近上界:
在 𝑛 趋于无穷大时,最高阶的项将发挥主导作用,其他项的影响都可以忽略。
常见类型


常数阶 𝑂(1): 常数阶的操作数量与输入数据大小 𝑛 无关,即不随着 𝑛 的变化而变化。
线性阶 𝑂(𝑛): 线性阶的操作数量相对于输入数据大小 𝑛 以线性级别增长。
遍历数组和遍历链表等操作的时间复杂度均为 𝑂(𝑛) ,其中 𝑛 为数组或链表的长度.
平方阶 𝑂(𝑛2): 平方阶的操作数量相对于输入数据大小 𝑛 以平方级别增长。平方阶通常出现在嵌套循环中。
指数阶 𝑂(2𝑛): 指数阶增长非常迅速,在穷举法(暴力搜索、回溯等)中比较常见。对于数据规模较大的问题,指数阶是不可接受的,通常需要使用动态规划或贪心算法等来解决。
对数阶 𝑂(log 𝑛): 与指数阶相反,对数阶反映了“每轮缩减到一半”的情况。设输入数据大小为 𝑛 ,由于每轮缩减到一半,因此循环次数是 log 2 n \log_2 n log2n ,即 2 n 2^n 2n 的反函数。简记为 𝑂(log 𝑛).
线性对数阶 𝑂(𝑛 log ): 线性对数阶常出现于嵌套循环中,两层循环的时间复杂度分别为 𝑂(log 𝑛) 和 𝑂(𝑛)。
主流排序算法的时间复杂度通常为 𝑂(𝑛 log 𝑛) ,例如快速排序、归并排序、堆排序等。
阶乘阶 𝑂(𝑛!): 阶乘阶对应数学上的“全排列”问题。给定 𝑛 个互不重复的元素,求其所有可能的排列方案。
因为当 𝑛 ≥ 4 时恒有 𝑛! > 2𝑛 ,所以阶乘阶比指数阶增长得更快,在 𝑛 较大时也是不可接受的。
最差、最佳、平均时间复杂度
算法的时间效率往往不是固定的,而是与输入数据的分布有关。
实际中很少使用最佳时间复杂度,因为通常只有在很小概率下才能达到,可能会带来一定的误导性。而最差时间复杂度更为实用,因为它给出了一个效率安全值;
最差时间复杂度和最佳时间复杂度只出现于“特殊的数据分布”,这些情况的出现概率可能很小,并不能真实地反映算法运行效率。相比之下,平均时间复杂度可以体现算法在随机输入数据下的运行效率,用 Θ 记号来表示。
空间复杂度
空间复杂度(space complexity)用于衡量算法占用内存空间随着数据量变大时的增长趋势。
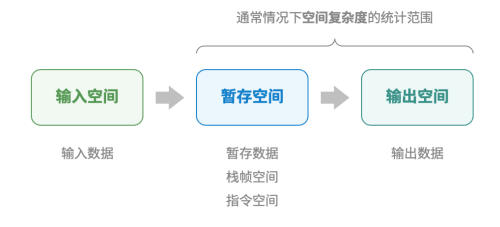
算法相关空间
输入空间:用于存储算法的输入数据。
暂存空间:用于存储算法在运行过程中的变量、对象、函数上下文等数据。
输出空间:用于存储算法的输出数据。
一般情况下,空间复杂度的统计范围是“暂存空间”加上“输出空间”。
暂存空间可以进一步划分为三个部分:
1.暂存数据:用于保存算法运行过程中的各种常量、变量、对象等。
2.栈帧空间:用于保存调用函数的上下文数据。系统在每次调用函数时都会在栈顶部创建一个栈帧,函数返回后,栈帧空间会被释放。
3.指令空间:用于保存编译后的程序指令,在实际统计中通常忽略不计。
推算方法
空间复杂度的推算方法与时间复杂度大致相同,只需将统计对象从“操作数量”转为“使用空间大小”。
通常只关注最差空间复杂度。 因为内存空间是一项硬性要求,必须确保在所有输入数据下都有足够的内存空间预留。
最差空间复杂度中的“最差”有两层含义:
1.以最差输入数据为准;
2.以算法运行中的峰值内存为准。
在递归函数中,需要注意统计栈帧空间。
常见类型

常数阶 𝑂(1): 常数阶常见于数量与输入数据大小 𝑛 无关的常量、变量、对象。
需要注意的是,在循环中初始化变量或调用函数而占用的内存,在进入下一循环后就会被释放,因此不会累积占用空间,空间复杂度仍为 𝑂(1) ;
线性阶 𝑂(𝑛): 线性阶常见于元素数量与 𝑛 成正比的数组、链表、栈、队列等。
平方阶 𝑂(𝑛2): 平方阶常见于矩阵和图,元素数量与 𝑛 成平方关系。
指数阶 𝑂(2𝑛): 指数阶常见于二叉树。
层数为 𝑛 的“满二叉树”的节点数量为 2^𝑛 − 1 ,占用 𝑂(2𝑛) 空间
对数阶 𝑂(log 𝑛): 对数阶常见于分治算法。例如归并排序,输入长度为 𝑛 的数组,每轮递归将数组从中点处划分为两半,形成高度为 log 𝑛 的递归树,使用 𝑂(log 𝑛) 栈帧空间。
权衡时间与空间
降低时间复杂度通常需要以提升空间复杂度为代价,反之亦然。我们将牺牲内存空间来提升算法运行速度的思路称为“以空间换时间”;反之,则称为“以时间换空间”。
学习地址
学习地址:https://github.com/krahets/hello-algo
重新复习数据结构,所有的内容都来自这里。

![[Java、Android面试]_01_多线程: 重要参数、状态、优雅停止线程等](https://img-blog.csdnimg.cn/direct/0fdb6b6755854f9faea737c8cb81b87c.png)