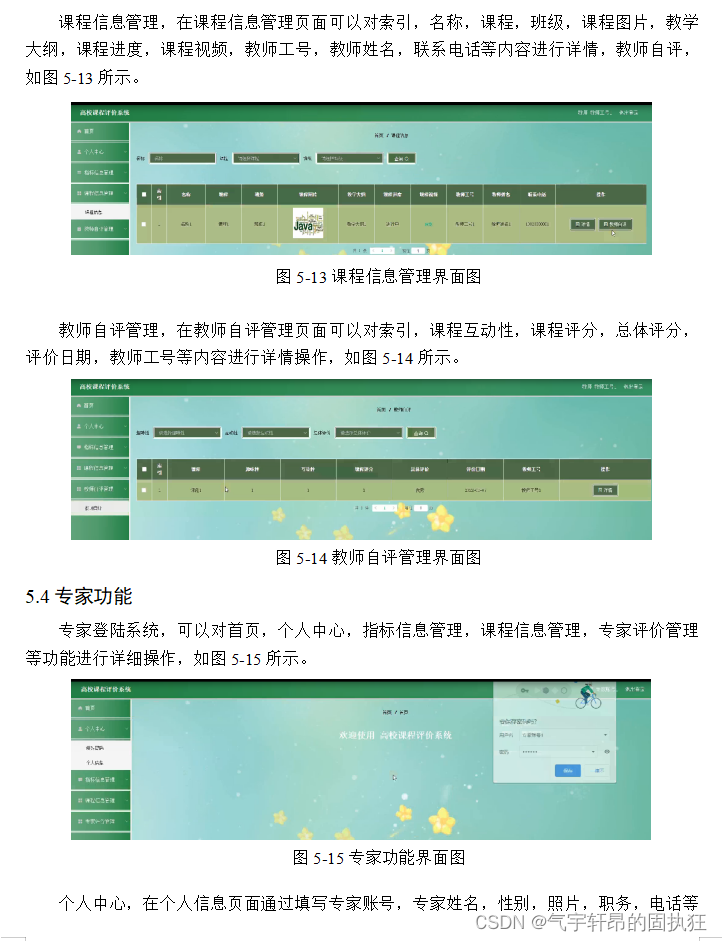
机器学习模型—支持向量机 (SVM)
支持向量机 (SVM) 是一种强大的机器学习算法,用于线性或非线性分类、回归,甚至异常值检测任务。SVM 可用于各种任务,例如文本分类、图像分类、垃圾邮件检测、笔迹识别、基因表达分析、人脸检测和异常检测。SVM 在各种应用中具有适应性和高效性,因为它们可以管理高维数据和非线性关系。
当我们试图找到目标特征中可用的不同类之间的最大分离超平面时,SVM 算法非常有效。
支持向量机
支持向量机 (SVM) 是一种用于分类和回归的监督机器学习算法。
尽管我们也说回归问题,但它最适合分类。SVM算法的主要目标是在N维空间中找到能够将特征空间中不同类的数据点分开的最优超平面。超平面尝试使不同类的最近点之间的间隔尽可能最大。超平面的维度取决于特征的数量。如果输入特征的数量是两个,那么超平面只是一条线。如果输入特征的数量为三个,则超平面变为二维平面。当特征数量超过三个时就变得难以想象。
让我们考虑两个自变量 x 1、 x 2和一个因变量(蓝色圆圈或红色圆圈)。
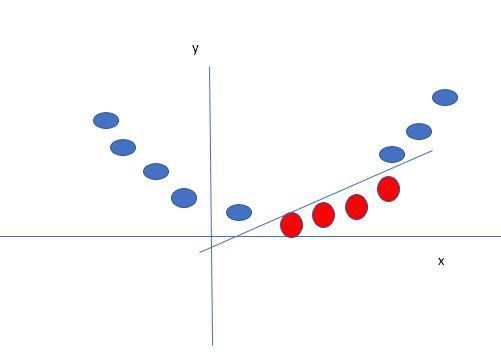
从上图可以清楚地看出,有多条线(这里的超平面是一条线,因为我们只考虑两个输入特征 x 1 , x 2),它们分隔我们的数据点或在红色和蓝色圆圈之间进行分类。那么我们如何选择分离数据点的最佳线或一般最佳超平面呢?
支持向量机如何工作
作为最佳超平面的一种合理选择是代表两类之间最大分离或边缘的超平面。