每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

在“玩转LangChain - 1”一节,我发现自己达到了OpenAI使用限额,需要升级。通过本地运行大型语言模型(LLM),让LangChain可以访问它,这样可以节省一些费用。几周前,谷歌发布了Gemma。让我们试试看。
从Ollama 安装Ollama Mac版本,载入Gemma并通过Ollama在本地运行它。最初,我尝试安装Mistral,但发现它有点沉重。相比之下,Gemma 2b只有1G多一点。

运行
ollama run gemma:2b安装成功后,我们可以通过内部提问来验证Gemma的反应。

1.安装LangChain
执行
pip install langchain命令来安装LangChain。运行以下命令以验证安装是否成功:
python -c "import langchain; print('LangChain version:', langchain.version)"LangChain版本:0.1.11
2. 在测试代码中调用Gemma
from langchain_community.llms import Ollama
import logging
# Configure basic logging
logging.basicConfig(level=logging.INFO)
try:
llm = Ollama(model="gemma:2b")
# It's good practice to ensure prompts are well-defined. Adjust based on the model's capabilities.
prompt = ("Who are you? "
"Are you better than Mistral? "
"Can you share a detailed comparison?")
response = llm.invoke(prompt)
print(response)
except ImportError:
logging.error("Failed to import Ollama from langchain_community. Is the package installed?")
except Exception as e:
logging.error(f"An unexpected error occurred: {e}")运行结果

也可以调用Restful API
curl http://localhost:11434/api/chat -d '{
"model": "gemma:2b",
"messages": [
{ "role": "user", "content": "hi, who are you?" }
]
}'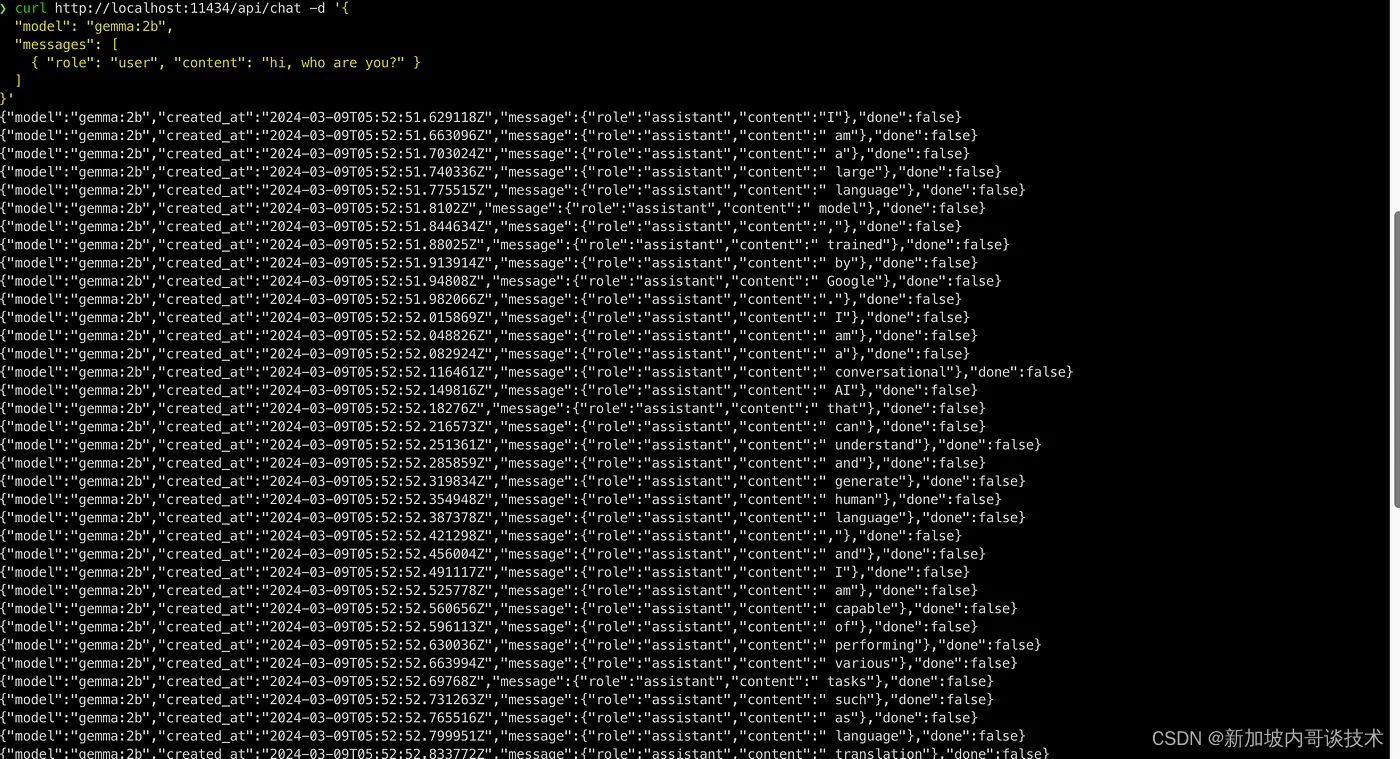
接收回复需要2-3秒钟,Gemma看起来相当不错。现在,我们准备将更复杂的LangChain作品移植到我们的本地大型语言模型(LLM),同时节省资金。玩得开心!