目录
索引?
什么是索引?索引有什么优点?索引有什么缺点?
索引的分类
按照功能分类:
按照数据结构分类
相关数据结构(b-tree、b+tree)
b-tree
b+tree
b-tree和b+tree的区别
为什么Innodb要选择B+tree作为数据结构
索引常见问题
什么是聚簇索引?何时使用聚簇索引与非聚簇索引
联合索引是什么?为什么需要注意联合索引中的顺序?
b+tree中innodb不需要回表查询吗?myisam一定会回表查询吗?
什么情况使用了索引,查询还是慢
什么情况下适合建索引什么适合下不适合建索引?
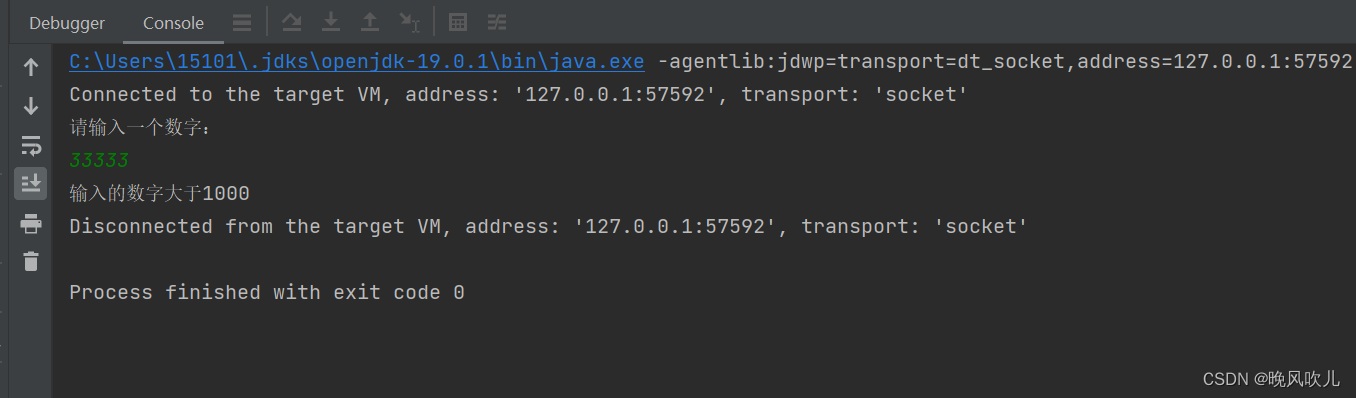
索引?
什么是索引?索引有什么优点?索引有什么缺点?
索引:索引是帮助mysql高效获取数据排好序的数据结构,一般来说索引本身也很大,不能全部存在内存中,因此索引往往保存在硬盘中
优点:提高了检索效率,降低了数据io成本,通过索引对数据进行排序,降低了数据排序的成本,降低了cpu的消耗
缺点:虽然索大大提高了查询速度,但是同时降低了更新表的速度,比如对表进行更新了之后,mysql不仅要更新数据,还要更新索引文件
索引的分类
按照功能分类:
- 普通索引:最基本的索引,没有任何限制
- 唯一索引:索引列的值必须唯一,但允许空,如果是组合索引,列值组合必须唯一
- 主键索引: 一种特殊的唯一索引,不允许空,在建表时主键列同时创建主键索引
- 联合索引: 将单列索引进行组合
- 外键索引:只有InnoDB支持,用来保证数据一致性,完整性和实现级联操作
- 全文索引:快速匹配全部文档的方式,innodb5.6版本后才支持。memory不支持
按照数据结构分类
- B Tree索引:Mysql使用最频繁的索引,是Innodb和myisam存储引擎默认的索引类型,底层是基于b+tree
- hash索引: Mysql中menmory存储引擎默认支持的索引类型
相关数据结构(b-tree、b+tree)
b-tree
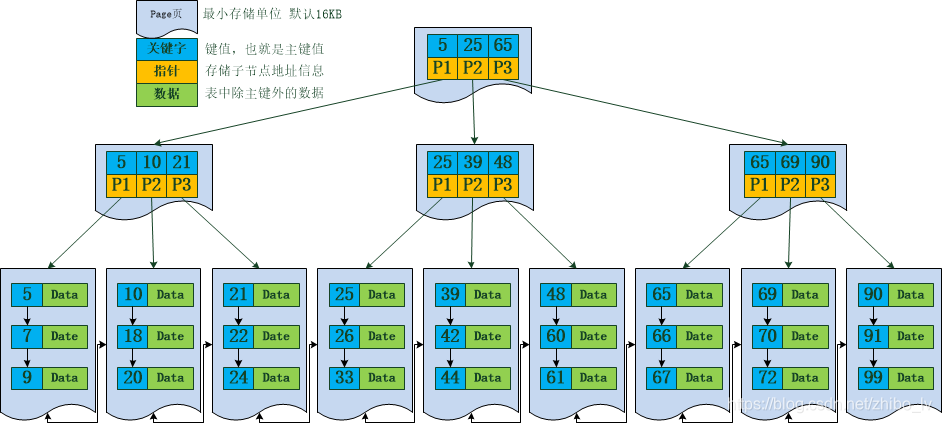
说明:上图中每一个黑色方块为一个磁盘块,P代表指向下一节点的指针,D代表携带的数据,蓝色方块中的数字代表键。
Btree是一种多路查找树,Btree中所有节点的子树个数的最大值为Btree的阶,如上图中每一个节点的子树最大值为3,所以是一颗3阶树,一个m阶的Btree如果不为空,就必须具备以下性质:
- 树中每个结点至多有m-1个关键字,即m棵子树。
- 树中可看到真实存在的最后一排为终端节点而非叶子节点,叶子节点实际不存在,是btree查询时候为空的情况,上图中3、5、9、10等这一排实际是终端节点。
- 除根节点以外,所有的非叶节点至少含有(m/2)-1个关键字,m/2棵子树
- 根节点关键字可以小于(m/2)-1个,可以没有子树,如果有子树,则至少有两棵子树
b+tree
说明:一个m阶的B+tree如果不为空,就必须满足以下特性:
- 树种每个节点至多含有m个关键字,m棵子树(节点的关键字和子树相同)
- 除根节点外,所有非叶节点至少含有m/2个关键字,m/2棵子树
- 根节点的关键字个数可以小于m/2,可以没有子树,如果有子树,至少有两棵
- 所有叶结点中包含了全部关键字和关键字指向记录的指针,叶节点内的关键字也是有序排列的,叶节点之间也是有序排列的,指针相连,实际是个双向链表
- 所有的非叶节点仅仅携带关键字和指向下一节点的指针
- B+tree分为聚集索引和非聚集索引,如果是聚集索引的话,叶子节点存放的是一整行记录的数据。如果是非聚集索引的话,仅仅存放着主键,还要通过主键回表查询那一行记录的数据
b-tree和b+tree的区别
以m阶树表示
- B+tree由分块查找进化而来,B树由二叉排序树进化而来
- 在B+tree中每个非根节点的关键字数的取值范围是m/2<= n<=m,子树个数为n;在Btree中每个非根节点的关键字树的取值范围是(m/2)-1<=n<m-1,子树个数为n+1
- 在B+tree中,只有叶节点包含信息,非叶节点只起到索引所用;Btree中全部节点的关键字都包含信息
- 在B+tree中,叶节点包含了全部关键字,非叶节点中出现的关键字一定会出现在叶节点中;在Btree中,任何节点中的关键字都不会重复
- B+tree支持顺序查找和多路查找,Btree只支持多路查找
- B+tree中,查找成功或失败都会到达最后一层(叶子节点);而Btree中查找成功时,随时停止搜索。
- B+tree的叶子节点有一条链相连;Btree中终端节点各自独立
- 增删文件(节点)时,效率更高。因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
为什么Innodb要选择B+tree作为数据结构
- B+tree每次都要访问叶子节点,遍历层次来看更加的稳定
- b+tree的叶子节点使用指针连接在一起,方便了顺序遍历,既能满足范围查找又能满足多路查找
- B+Tree 只需要去遍历叶子节点就可以实现整棵树的遍历
- B+Tree 的非叶子节点并没有保存关键字的具体数据信息,内部节点相对B-Tree更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了
索引常见问题
什么是聚簇索引?何时使用聚簇索引与非聚簇索引
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因
密集索引和稀疏索引对应聚簇索引和非聚簇索引
联合索引是什么?为什么需要注意联合索引中的顺序?
联合索引:MySQL可以使用多个字段同时建立一个索引,叫做联合索引。在联合索引中,如果想要命中索引,需要按照建立索引时的字段顺序挨个使用,否则无法命中索引。
为什么要注意排序?
MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
当进行查询时,此时索引仅仅按照name严格有序,因此必须首先使用name字段进行等值查询,之后对于匹配到的列而言,其按照age字段严格有序,此时可以使用age字段用做索引查找,以此类推。因此在建立联合索引的时候应该注意索引列的顺序,一般情况下,将查询需求频繁或者字段选择性高的列放在前面。此外可以根据特例的查询或者表结构进行单独的调整。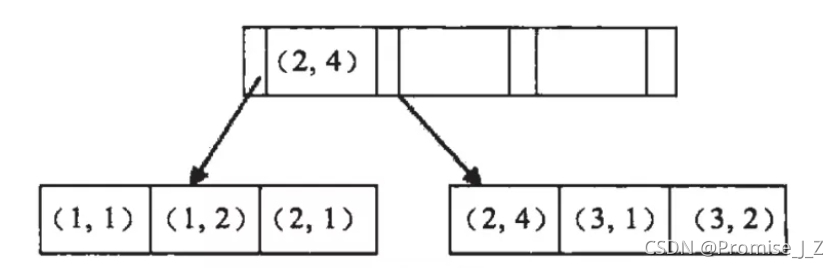
如上图所示他们是按照a来进行排序,在a相等的情况下,才按b来排序。
因此,我们可以看到a是有序的1,1,2,2,3,3。而b是一种全局无序,局部相对有序状态!什么意思呢?
从全局来看,b的值为1,2,1,4,1,2,是无序的,因此直接执行b = 2这种查询条件没有办法利用索引。
从局部来看,当a的值确定的时候,b是有序的。例如a = 1时,b值为1,2是有序的状态。当a=2时候,b的值为1,4也是有序状态。因此,你执行a = 1 and b = 2是a,b字段能用到索引的。而你执行a > 1 and b = 2时,a字段能用到索引,b字段用不到索引。因为a的值此时是一个范围,不是固定的,在这个范围内b值不是有序的,因此b字段用不上索引。
综上所示,最左匹配原则,在遇到范围查询的时候,就会停止匹配。
b+tree中innodb不需要回表查询吗?myisam一定会回表查询吗?
都不一定,先说innodb,在innodb中主键索引是采用聚簇索引的形式有以下三种情况
- 如果通过主键查找,那么命中的时候,主键索引中就会包含那一行记录,就不用回表查询
- 实现覆盖索引,当通过联合索引查询是,查询的数据刚好是联合索引的列,就不用回表查询,例如select name,age from student where name=‘zhangsan’ and age=18,联合索引(name,age) ,这种情况就不用回表,因为查找的内容就是索引本身
- 如果通过普通查找所有列例如select * from student where name=‘zhangsan’,索引为name,这时候是需要回表查询的
再说myisam,myisam中都是非聚簇索引,所以仅仅当实现索引覆盖的时候不用回表,其他情况都需要回表查询
什么情况使用了索引,查询还是慢
- 索引全表扫描
- 索引过滤性不好
- 频繁回表的开销
什么情况下适合建索引什么适合下不适合建索引?
适合建立索引的情况
- 主键自动创建索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 排序和分组的字段
不适合建立索引的情况
- 频繁增删改的字段不适合创建索引
- where条件里的字段不适合创建索引
- 数据重复且分布均匀的数据。
- 表的记录过少(建立索引无意义)
b+tree中3层树高能存储多少条数据?
假设每个索引使用的是bigint,占8个字节,然后指针占6个字节,也是说第一层中一个索引就占了14个字节,而mysql中有页的概念,一页大小为16kb。第一次能存放的索引就是16kb/14b=1170个,而第一个节点中有1170个索引,也就意味着能有1170棵子树,也就是说第一第二成存放的索引为1170*1170=1368900个,在第三层中,如果是用的innodb的话,假设表中每一行数据1kb,也就是一页能存放16个索引。那么总数就是1170*1170*16=21,902,400个。约为两千万条数据。
innodb通过索引查询数据中比较耗时的是哪一步?
最耗时的一步是将数据从磁盘读取到内存中的这一步,而数据读取到内存中会进行比较与筛选。那么问题来了,为什么不一次性将所有的数据都读取到内存进行比较筛选呢?如果我们数据库中的数据量非常非常大的时候,一次行将所有的数据读取到内存,就会出现两个极端问题
- 内存占用严重,甚至会出现内存溢出的问题
- 过大量的数据同时进行比较,效率也不一定会高



![[博士论文]基于图数据的可信赖机器学习](https://img-blog.csdnimg.cn/img_convert/3cd8ad50e2bdce6e62b869486d6009dd.png)