一. 窗口函数的定义和一些规范:
- 对数据进行分区,数据的样式是不改变的,但是会多添加一列。
- 窗口函数只能写在"结果集"中。
二. 排名函数
1. rank() over()
例题:对每个人的消费金额进行排名:
- rank() 排名函数
- over()窗口函数:over(partition by 字段 order by 字段 asc|desc)
- partition( 分区 ) by "分区的依据"
- over() 的结果是一个独立的数据表,只有一列排序的号码,最后添加一列与原表合并
rank() over()的缺点 :
- 他是排名函数,但是当有多个相同的数值排名相同时,会导致排名断层,举例如下,当存在 1 ,2,3,3,5。 这种排名时,因为存在两个3,所以不会有第四名的存在。
rank() 排名函数
over()窗口函数:over(partition by 字段 order by 字段 asc|desc)
partition( 分区 ) by "分区的依据"select
uid,
sum(amount)as amt,
rank() over(order by sum(amount) desc) #(这里意思是按照sum(amount)从大到小排序,
#数字最大的排名为1)
from orderinfo
where `ispaid`= "已支付"
GROUP BY uid
order by amt desc # 这里的desc是对sum(amount)进行降序排列
limit 202. row_number() over() 行编号
- 行编号,无论值大小,只负责编号。即使分数一样例如:99, 99。 但是他们的排名时第一名和第二名。单纯的记录行号
3. dense_rank() over() 排名函数
- 他和rank()over() 不同 , dense_rank() 碰到相同的数值会进行并列,不会出现排名的断层。
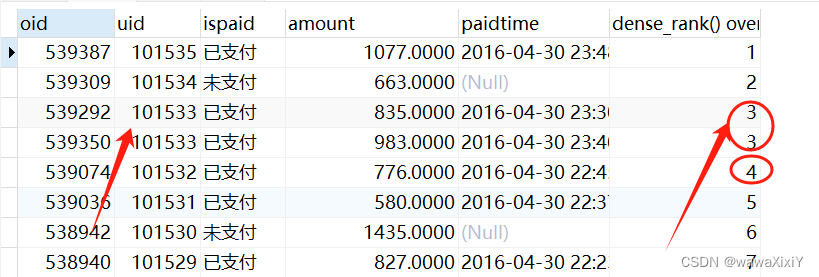
- rank() : 排名函数,会把数值相同的 并列排名,跳过并列排名的名次 , 导致排名断层
- row_number() : 计算当前的 行号函数,不会把数值相同的 并列排名, 导致排名不准确
- dense_rank() : 排名函数,会把数值相同的 并列排名,不会导致排名断层
窗口函数当中分区只是生成一个计算列而已,不会对原数据的形状进行改变,最终和源数据合并
over(partition by order by)
- partition by 分区依据 (group by 分组依据)
- order by 排序
- rows三. 移动、上下选位窗口函数
1. lag(column(获取那一列,可以是计算列) , 行数) : 向上获取数据, 向上访问几行
解释:
- 环比增长额是下个月 - 上个月的消费额度
- lag(sum(amount),1) 意思是选取上一行的数据
select
DATE_FORMAT(paidtime,"%Y-%m-01") as 年月,
sum(amount) as amt,
lag(sum(amount),1) over() 上期增长,
lag(sum(amount),1) over() - sum(amount) 环比增长额
from `orderinfo`
where ispaid ="已支付"
group by 年月
2. lead(column(获取那一列,可以是计算列) , 行数): 向下获取数据

四. 分区函数
1. partition by
-
partition by 对原始数据 做分组,但是不会改变数据的行数
不能直接使用当前结果集中的 计算列名,但是可以自主 从新计算字段
例题: 计算每个订单占当月订单的份额
select
#这是设置格式为 年-月-01
DATE_FORMAT(paidtime,"%Y-%m-01") as 年月,
#每一笔订单的金额
`amount` 订单金额,
#按照年-月-01分区,就是3月 4月 5月,计算sum(amount),也就是每个月的总额
sum(amount) over(partition by DATE_FORMAT(paidtime,"%Y-%m-01")) as 月总额,
# 这个除法就是计算每笔订单 占单月订单的份额
`amount` / sum(amount) over(partition by DATE_FORMAT(paidtime,"%Y-%m-01")) as 总额百分比
from orderinfo
where ispaid = "已支付"
order by DATE_FORMAT(paidtime,"%Y-%m-01") asc例题: 计算每个月订单额占总额的份额
select *,
# 对每个不同月总额求和 就是 年总额
sum(月总额) over(partition by year(年月)) as 年总额,
# 月总额 / 年总额
月总额/sum(月总额) over(partition by year(年月)) 月份占总额比
from
(
# 子查询结果是每个月的总额
select
# 把时间规范成 年 -月 ,结果是 三个不同的月份
DATE_FORMAT(paidtime,"%Y-%m-01") as 年月,
# 统计出每个月的总额
sum(amount) as 月总额
from orderinfo
where ispaid = "已支付"
GROUP BY 年月
) as tmp
不使用窗户函数做法:
select
DATE_FORMAT(paidtime,"%Y-%m-01") as 年月,
sum(amount) as 月总额,
# 通过year函数,选择2016的进行求和,这样就和结果就是年度总额
(select sum(amount) from orderinfo where ispaid = "已支付" and year(paidtime)),
sum(amount) /(select sum(amount) from orderinfo where ispaid = "已支付" and year(paidtime))
from orderinfo
where ispaid = "已支付"
GROUP BY DATE_FORMAT(paidtime,"%Y-%m-01")五. 分桶函数
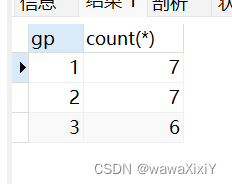
- 分桶函数一般是对 数字 进行划分的
- 实际上,分桶函数会根据现有的数值和桶数按照比例划分,例如100个数据,10个桶,他会均衡的进行划分,如果加上 partition by 会在当前分区中进行划分
ntile(桶的数量) over (partition by)
# 在外部进行group by
select gp,count(*)
from
(
select *,
ntile(3) over() as gp
from
(
select *
from userinfo
order by uid
limit 20
) as tmp
)as tmp1
group by gp
这样就是按照uid的顺序 因为limit 20了, 他就会按照20个 等分为3等份
partition by 的方式划分
# 这种就是按照性别 男生中划分3个,女生中也划分三个
select *,
ntile(3) over(partition by sex) as gp
from
(
select *
from userinfo
order by uid
limit 20
) as tmp
手动划分
CREATE FUNCTION agegp(age INT) RETURNS VARCHAR(32) DETERMINISTIC
BEGIN
IF age < 18 THEN
RETURN '未成年人';
ELSEIF age < 36 THEN
RETURN '青年';
ELSEIF age < 51 THEN
RETURN '壮年';
ELSEIF age < 61 THEN
RETURN '年轻老人';
ELSEIF age < 76 THEN
RETURN '老人';
ELSE
RETURN '大龄老人';
END IF;
END
# 将 表中的age 传入 上面函数中,上面的函数就是划分
select * , agegp(age) as gp from
(select *,year(now()) - year(birthday) as age from `userinfo`
where birthday is not null and sex is not null
) as tmp六. first_value() 和 last_value()
first_value(字段) ,不分区 得到的是整理数据中的第一个(受到排序的影响)
first_value(字段) over(partition by sex),分区,会获取每个分区中的第一个(受到排序的影响)
select *,
FIRST_VALUE(uid) over(partition by sex ) as try
FROM
(
select * from
userinfo
where sex is not null
limit 20
) as tmp

七. 百分位累计分布
- cume_dist() over(order by 字段 desc)
- 返回的是位置比例 : 从小到大,并且去重
- 计算公式 1 / 去重数量 * 位置索引(从1开始的)
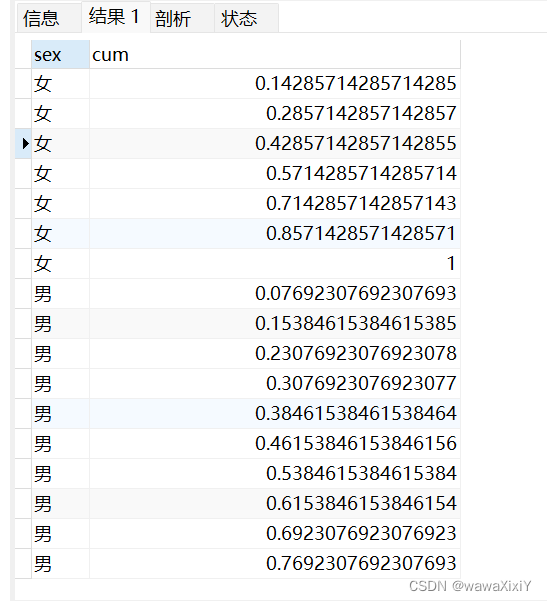
select sex,cume_dist() over(partition by sex order by birthday) as cum from
(
select * from userinfo LIMIT 20
)as tmp
他这个就是按照sex分类的,这个函数就是:例如第一个女生的cum是0.14,他是女生的认识有 7个,第一个女生就是1/7,第二个就是2/8
八. 百分位排名
- percent_rank() 百分位排名
- 生成一个课排序列
select uid,
amt,
sex,
cume_dist() over(order by amt) as cum,
PERCENT_RANK() over(order by amt) as per
from
(select uid, round(sum(amount))as amt
from orderinfo
where ispaid = "已支付"
GROUP BY uid
) tmp
join userinfo
using(uid)
order by amt desc
九. rows 和 range
rows()
UNBOUNDED PRECEDING: 指定窗口从第一行开始,到当前行结束。
1 PRECEDING: 指定窗口从当前行 向前数 n 行开始,到当前行结束。
CURRENT ROW: 指定窗口仅包含当前行。
1 FOLLOWING: 指定窗口从当前行向后数 n行开始,到当前行结束。
UNBOUNDED FOLLOWING: 指定窗口从当前行开始,一直到最后一行结束。
over(parition by 字段 order by 字段 desc|asc rows between 关键字 and 关键字) over(parition by 字段 order by 字段 desc|asc rows between 关键字 and 关键字)
# 这里是向前找一行,在往后找一行,和中间自己这一行
select uid,sum(uid) over(rows between 1 preceding and 1 following) as abc
from
(select
*
from userinfo limit 10)as tmp
range()
用rows()