准备数据
先准备一些数据
#指定ik分词器
PUT /es_db
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
# 创建文档,指定id
PUT /es_db/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "java developer"
}
PUT /es_db/_doc/2
{
"name": "李四",
"sex": 1,
"age": 28,
"address": "广州荔湾大厦",
"remark": "java assistant"
}
PUT /es_db/_doc/3
{
"name": "王五",
"sex": 0,
"age": 26,
"address": "广州白云山公园",
"remark": "php developer"
}
PUT /es_db/_doc/4
{
"name": "赵六",
"sex": 0,
"age": 22,
"address": "长沙橘子洲",
"remark": "python assistant"
}
PUT /es_db/_doc/5
{
"name": "张龙",
"sex": 0,
"age": 19,
"address": "长沙麓谷企业广场",
"remark": "java architect assistant"
}
PUT /es_db/_doc/6
{
"name": "赵虎",
"sex": 1,
"age": 32,
"address": "长沙麓谷兴工国际产业园",
"remark": "java architect"
}
PUT /es_db/_doc/7
{
"name": "李虎",
"sex": 1,
"age": 27,
"address": "广州番禺节能科技园",
"remark": "java architect"
}
PUT /es_db/_doc/8
{
"name": "张星",
"sex": 1,
"age": 25,
"address": "武汉东湖高新区未来智汇城",
"remark": "golang developer"
}
PUT /es_db/_doc/9
{
"name": "李星云",
"sex": 1,
"age": 35,
"address": "杭州余杭区海创园",
"remark": "react developer"
}
PUT /es_db/_doc/10
{
"name": "范闲",
"sex": 1,
"age": 26,
"address": "杭州余杭区西溪湿地",
"remark": "vue developer"
}
PUT /es_db/_doc/11
{
"name": "陈萍萍",
"sex": 1,
"age": 18,
"address": "杭州西湖区太子湾景区",
"remark": "javascript developer"
}
PUT /es_db/_doc/12
{
"name": "王启年",
"sex": 1,
"age": 36,
"address": "杭州余杭区未来科技城",
"remark": "c++ developer"
}
match_all
使用match_all,匹配所有文档,默认只会返回10条数据。
原因:_search查询默认采用的是分页查询,每页记录数size的默认值为10。如果想显示更多数据,指定size

GET /es_db/_search
#等同于
GET /es_db/_search
{
"query": {
"match_all": {}
}
}
_source
指定返回字段
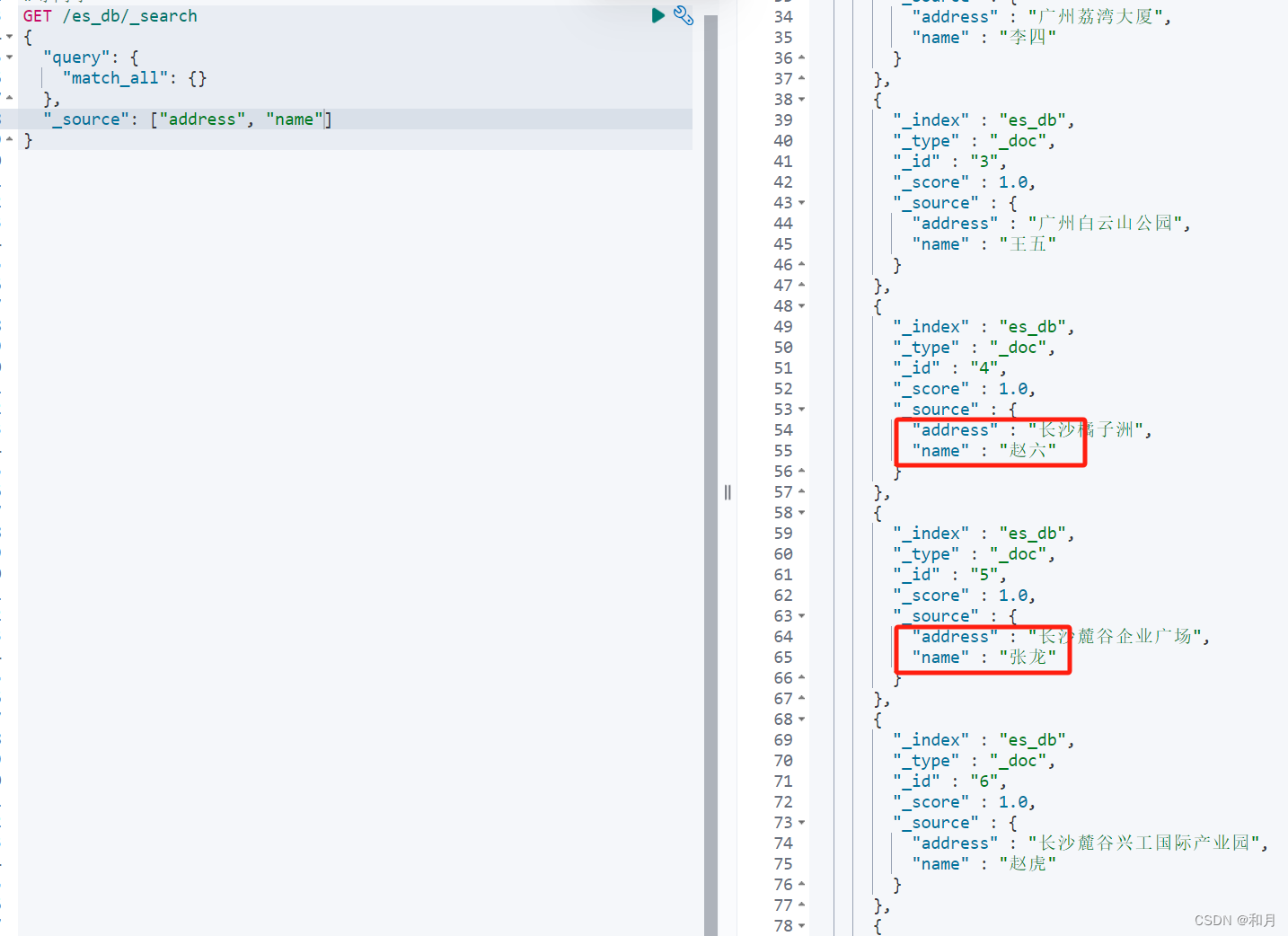
# 指定返回 某些字段
GET /es_db/_search
{
"query": {
"match_all": {}
},
"_source": ["address", "name"]
}只返回元数据
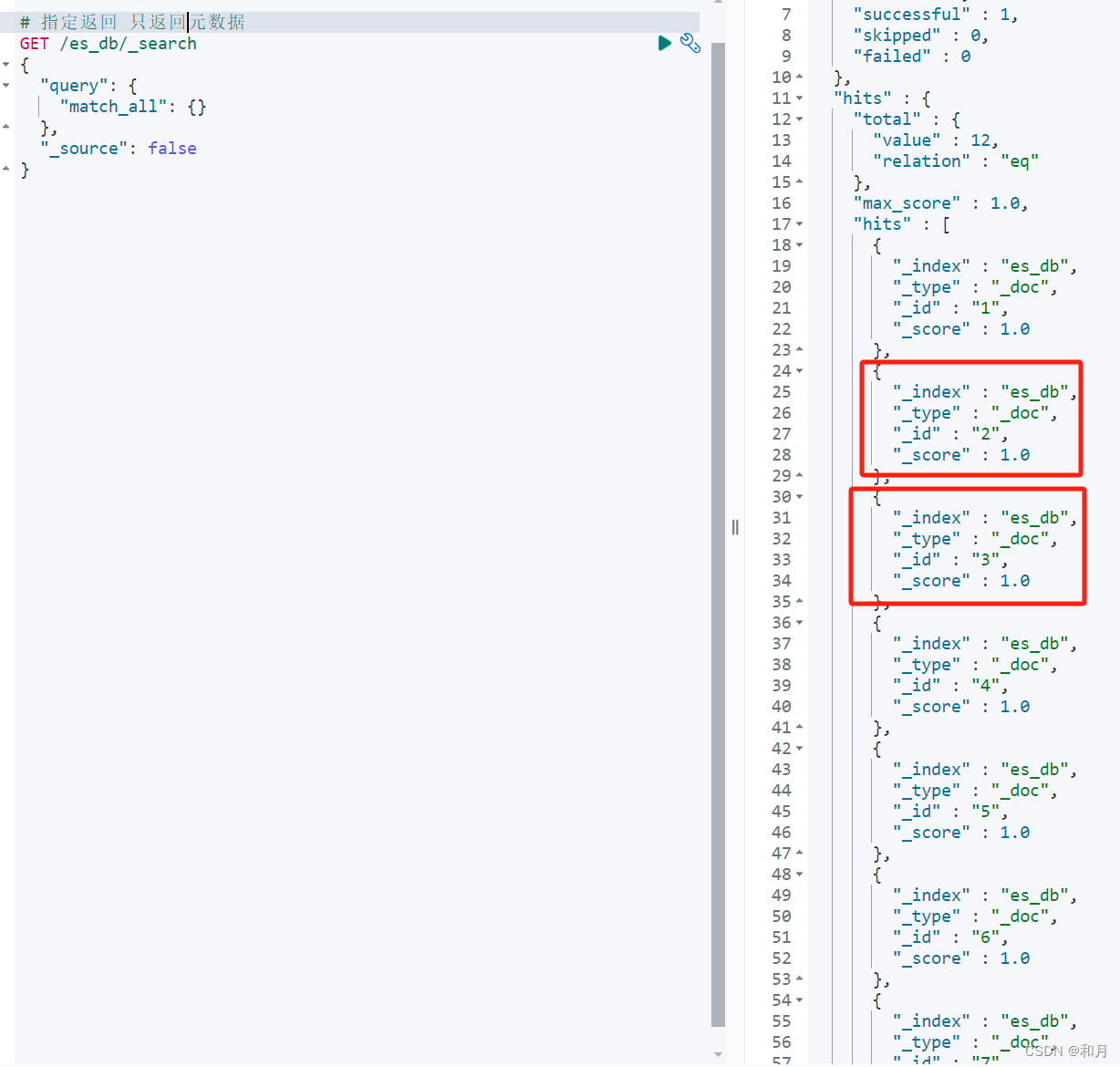
# 指定返回 只返回元数据
GET /es_db/_search
{
"query": {
"match_all": {}
},
"_source": false
}
返回指定条数 size
只返回两条
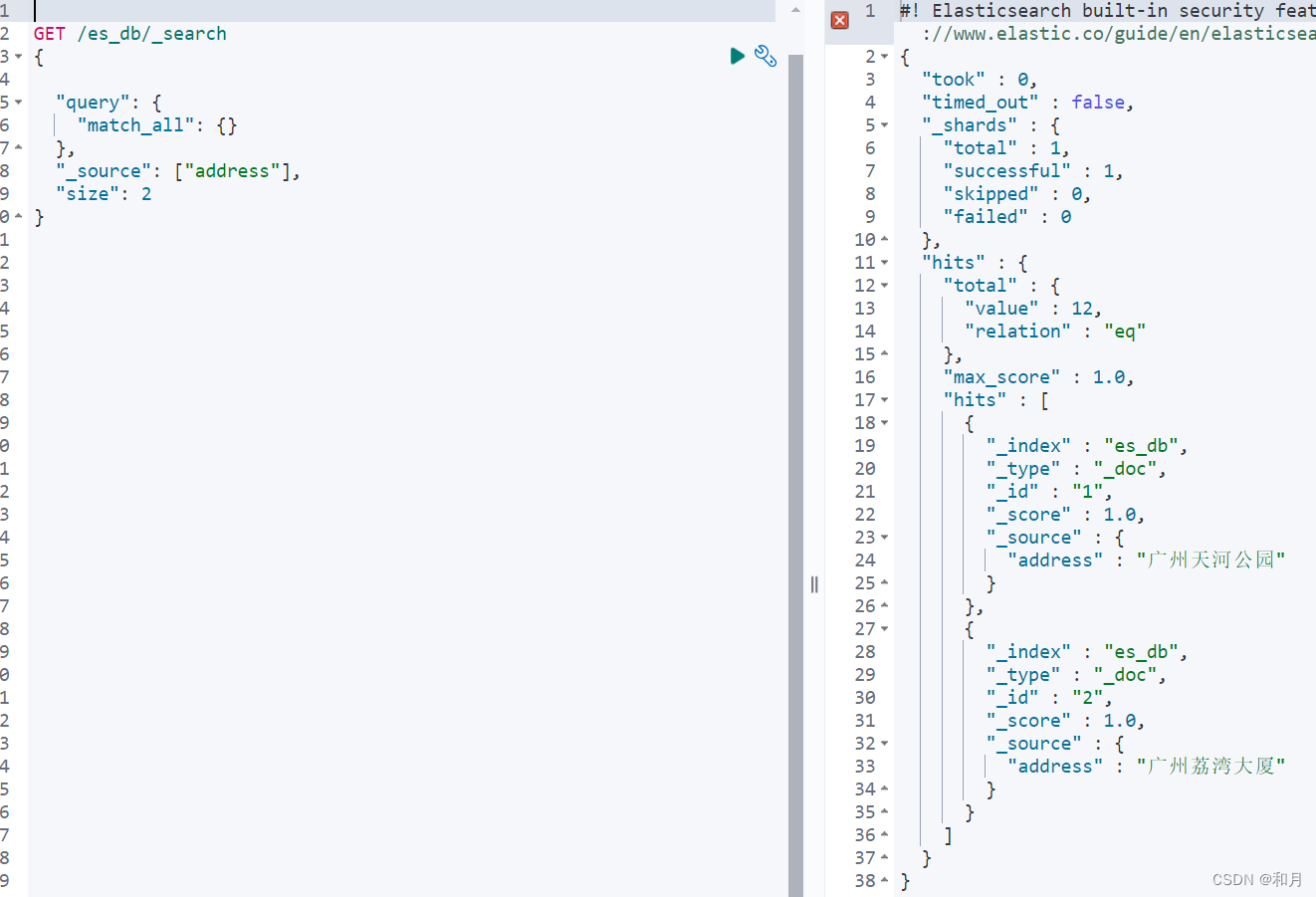
GET /es_db/_search
{
"query": {
"match_all": {}
},
"_source": ["address"],
"size": 2
}分页查询 from & size
查询第二页,三条数据

GET /es_db/_search
{
"query": {
"match_all": {}
},
"_source": ["address"],
"from": 2,
"size": 3
}指定排序字段 sort
以 age 倒序

但是注意,sort 排序会使 source 算分失效
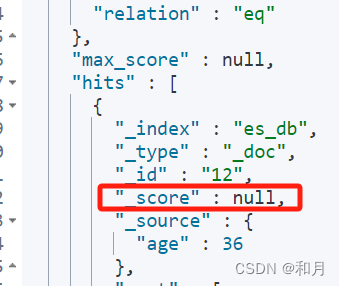
GET /es_db/_search
{
"query": {
"match_all": {}
},
"_source": ["age"],
"size": 5,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}Term query术语查询
term 精准查询,比如 姓名,年龄,bool类型
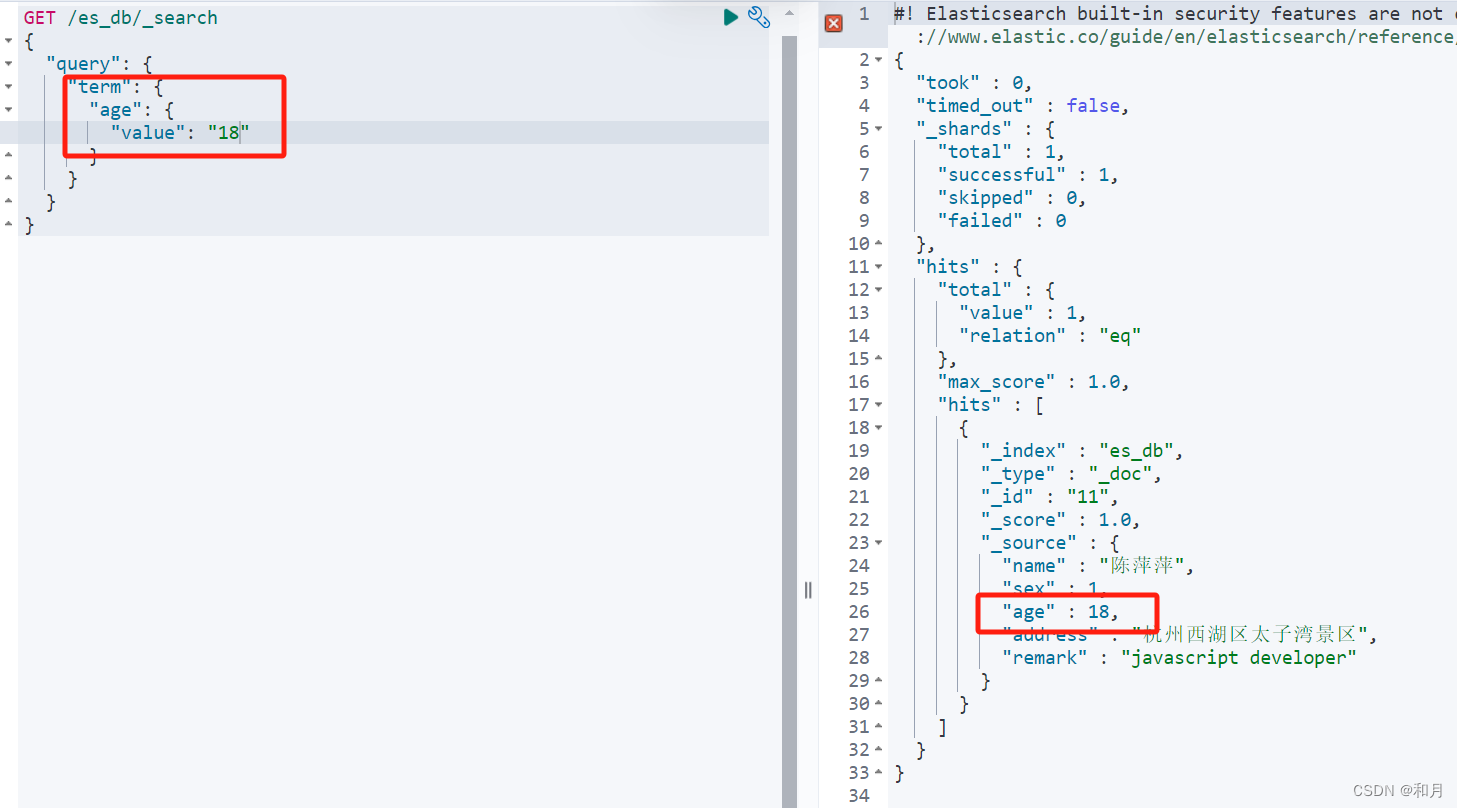
这里需要注意,由于使用 term 表示不对查询内容进行分词,全值匹配
所以如果文章词库中没有对应的全值分词记录,会查不到文章记录

如果使用 term 对分词字段进行全值查询,可以 keyword关键字
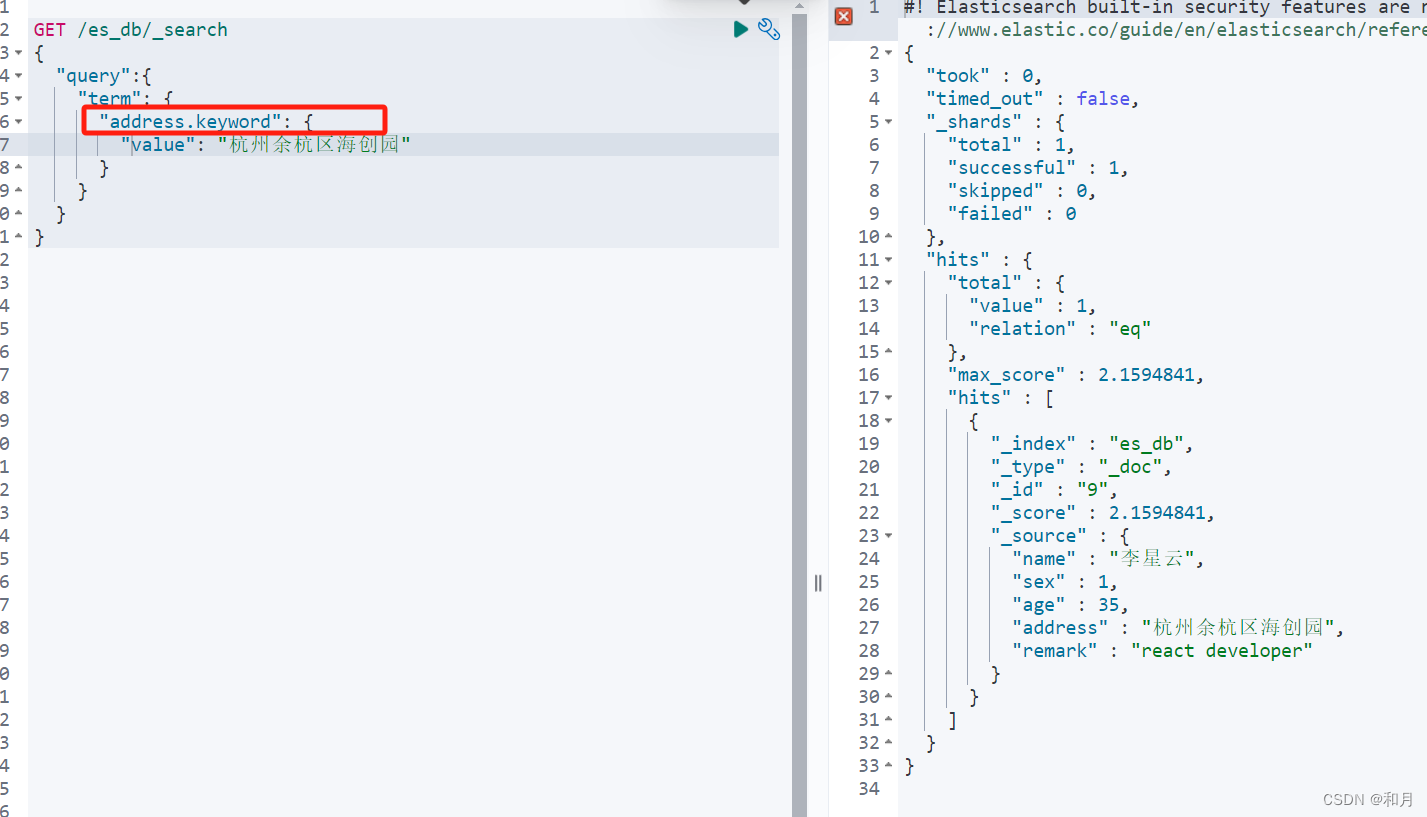
GET /es_db/_search
{
"query":{
"term": {
"address.keyword": {
"value": "杭州余杭区海创园"
}
}
}
}使用 constant source 避免算分 提高性能

# 这里会计算 source 算分
GET /es_db/_search
{
"query":{
"term": {
"address.keyword": {
"value": "杭州余杭区海创园"
}
}
}
}
# 这里表示 转为一个 Filtering 避免算分 而且 Filter 可以有效利用缓存
#提高性能
GET /es_db/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"address.keyword": "杭州余杭区海创园"
}
}
}
}
}
term 处理多值字段时,表示包含,而不是等于

POST /employee/_bulk
{"index":{"_id":1}}
{"name":"小明","interest":["跑步","篮球"]}
{"index":{"_id":2}}
{"name":"小红","interest":["跳舞","画画"]}
{"index":{"_id":3}}
{"name":"小丽","interest":["跳舞","唱歌","跑步"]}
POST /employee/_search
{
"query": {
"term": {
"interest.keyword": {
"value": "跑步"
}
}
}
}
Terms Query多术语查询
Terms query用于在指定字段上匹配多个词项(terms)。它会精确匹配指定字段中包含的任何一个词项。

POST /es_db/_search
{
"query": {
"terms": {
"remark.keyword": ["java assistant", "java architect"]
}
}
}exists query
在Elasticsearch中可以使用exists进行查询,以判断文档中是否存在对应的字段。

POST /es_db/_search
{
"query": {
"exists": {
"field": "remark11"
}
}
}ids query
ids 关键字 : 值为数组类型,用来根据一组id获取多个对应的文档

GET /es_db/_search
{
"query": {
"ids": {
"values": [1,2]
}
}
}range query范围查询
- range:范围关键字
- gte 大于等于
- lte 小于等于
- gt 大于
- lt 小于
- now 当前时间
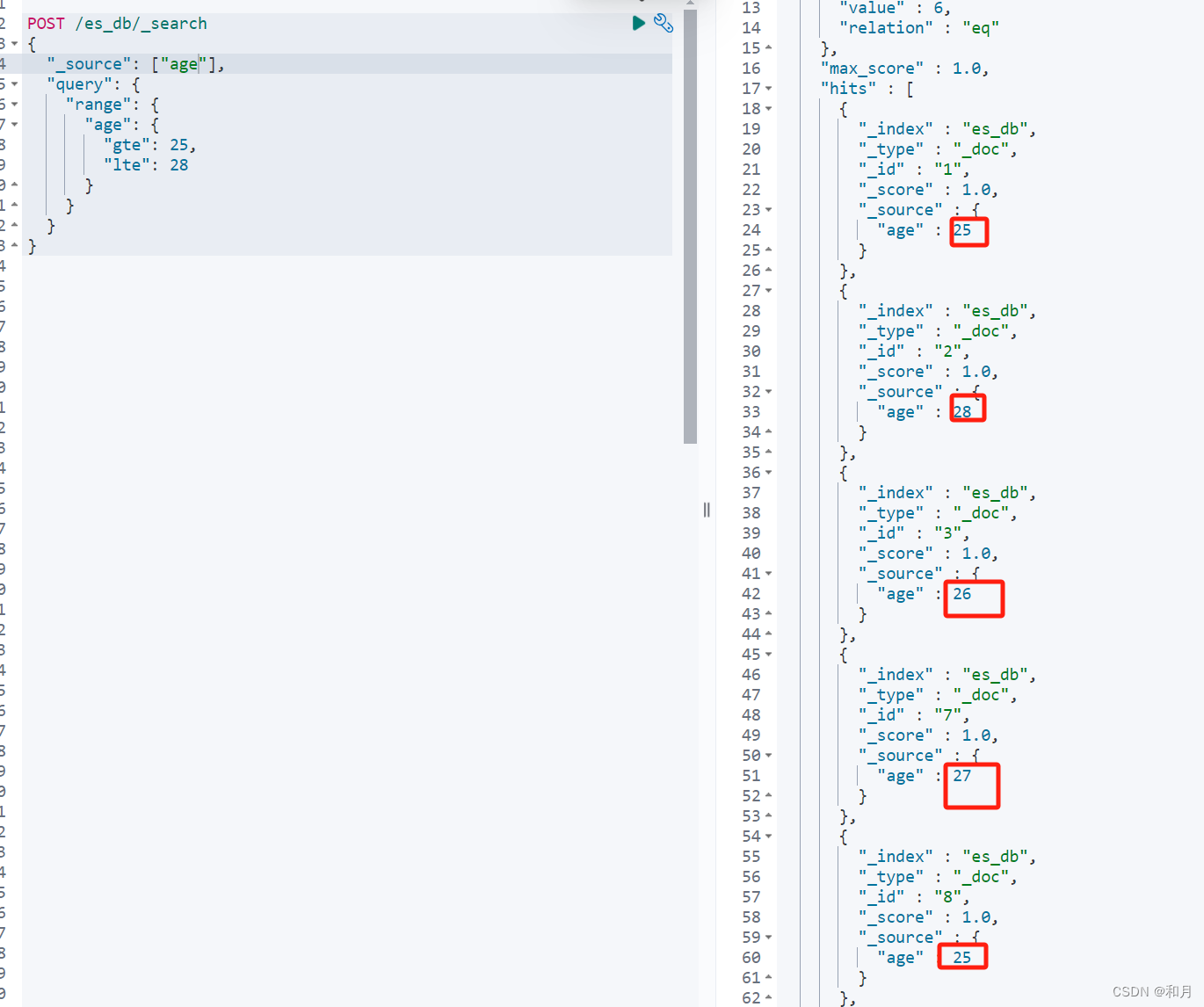
查询时间
now - 3y 表示 当前时间 减去 3年
也是 now - 3d 就是当前时间减去3天,以此类推

#日期范围比较
DELETE /product
POST /product/_bulk
{"index":{"_id":1}}
{"price":100,"date":"2021-01-01","productId":"XHDK-1293"}
{"index":{"_id":2}}
{"price":200,"date":"2022-01-01","productId":"KDKE-5421"}
GET /product/_search
{
"query": {
"range": {
"date": {
"gte": "now-3y"
}
}
}
}prefix query前缀查询
它会对分词后的term进行前缀搜索。
- 它不会分析要搜索字符串,传入的前缀就是想要查找的前缀
- 默认状态下,前缀查询不做相关度分数计算,它只是将所有匹配的文档返回,然后赋予所有相关分数值为1。它的行为更像是一个过滤器而不是查询。两者实际的区别就是过滤器是可以被缓存的,而前缀查询不行。
prefix的原理:需要遍历所有倒排索引,并比较每个term是否以所指定的前缀开头。

GET /es_db/_search
{
"_source": ["address"],
"query": {
"prefix": {
"address": {
"value": "杭州"
}
}
}
}wildcard query通配符查询
通配符查询:工作原理和prefix相同,只不过它不是只比较开头,它能支持更为复杂的匹配模式。
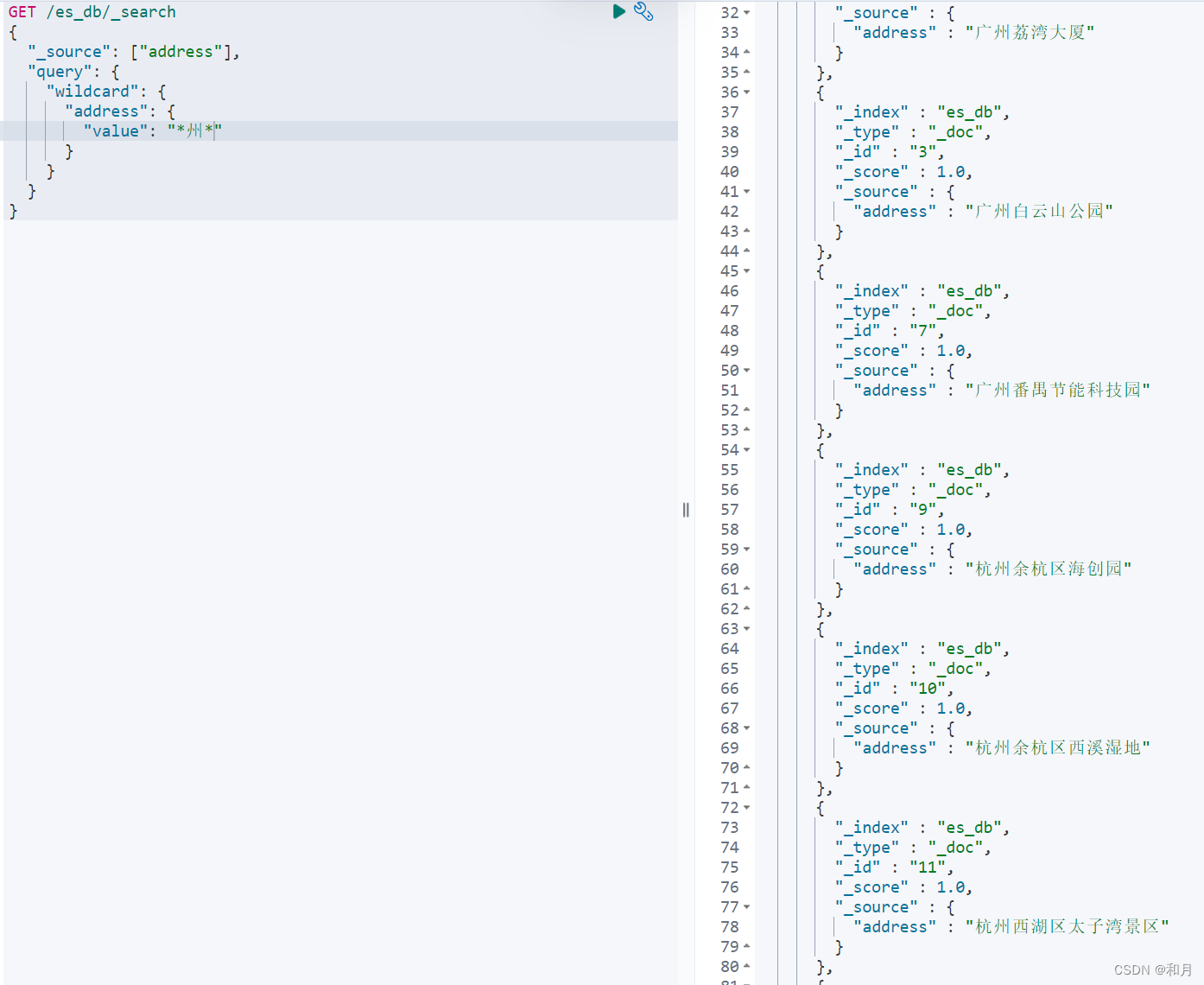
GET /es_db/_search
{
"_source": ["address"],
"query": {
"wildcard": {
"address": {
"value": "*州*"
}
}
}
}fuzzy query模糊查询
在实际的搜索中,我们有时候会打错字,从而导致搜索不到。在Elasticsearch中,我们可以使用fuzziness属性来进行模糊查询,从而达到搜索有错别字的情形。
fuzzy 查询会用到两个很重要的参数,fuzziness,prefix_length
- fuzziness:表示输入的关键字通过几次操作可以转变成为ES库里面的对应field的字段
通俗理解:容错率,最多容错 2
-
- 操作是指:新增一个字符,删除一个字符,修改一个字符,每次操作可以记做编辑距离为1;
- 如中文集团到中威集团编辑距离就是1,只需要修改一个字符;如果fuzziness值在这里设置成2,会把编辑距离为2的东东集团也查出来。
- 该参数默认值为0,即不开启模糊查询; fuzzy 模糊查询 最大模糊错误必须在0-2之间
- prefix_length:表示限制输入关键字和ES对应查询field的内容开头的第n个字符必须完全匹配,不允许错别字匹配;
-
- 如这里等于1,则表示开头的字必须匹配,不匹配则不返回;
- 默认值也是0;
- 加大prefix_length的值可以提高效率和准确率。
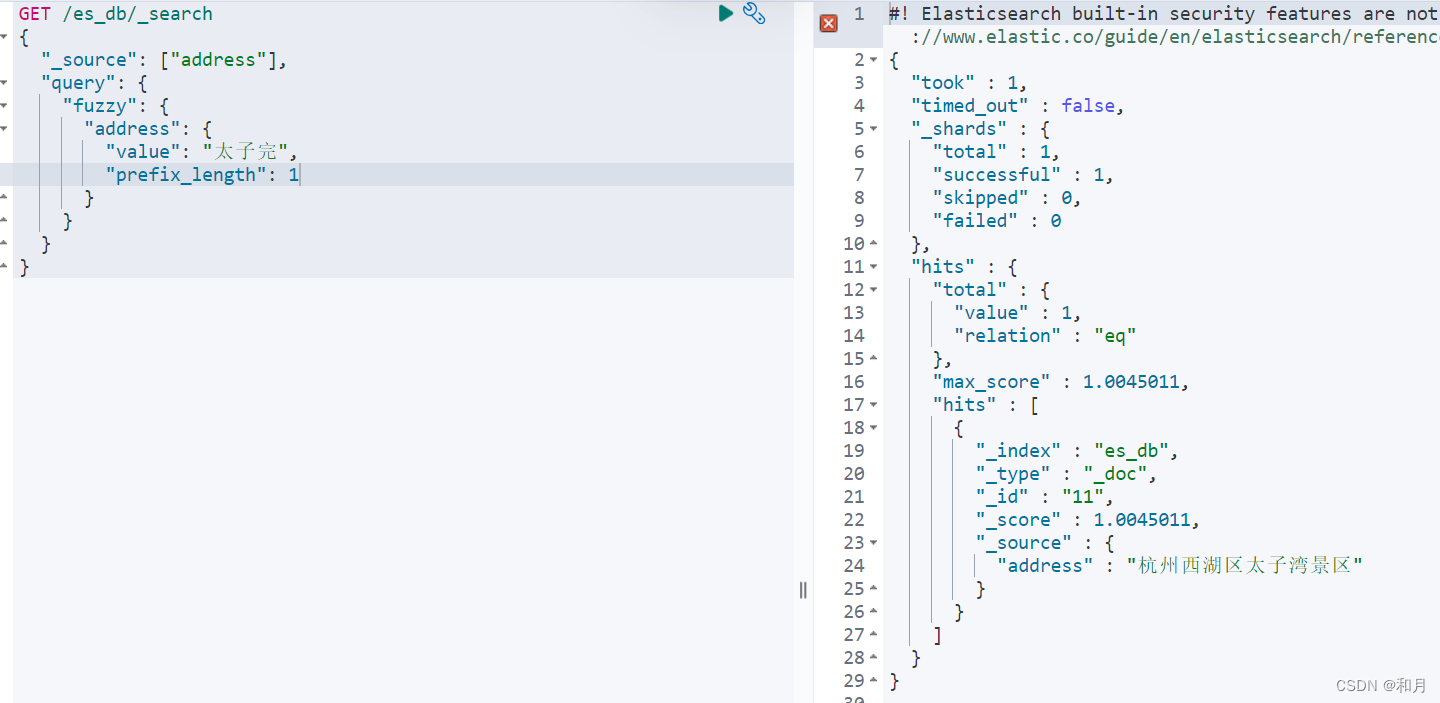
GET /es_db/_search
{
"_source": ["address"],
"query": {
"fuzzy": {
"address": {
"value": "太子完",
"prefix_length": 1
}
}
}
}match query匹配查询
match 表示会对查询字段进行分词,然后在和文章的分词进行比对

match支持以下参数:
- query : 指定匹配的值
- operator : 匹配条件类型
-
- and : 条件分词后都要匹配
- or : 条件分词后有一个匹配即可(默认)
- minmum_should_match : 最低匹配度,即条件在倒排索引中最低的匹配度
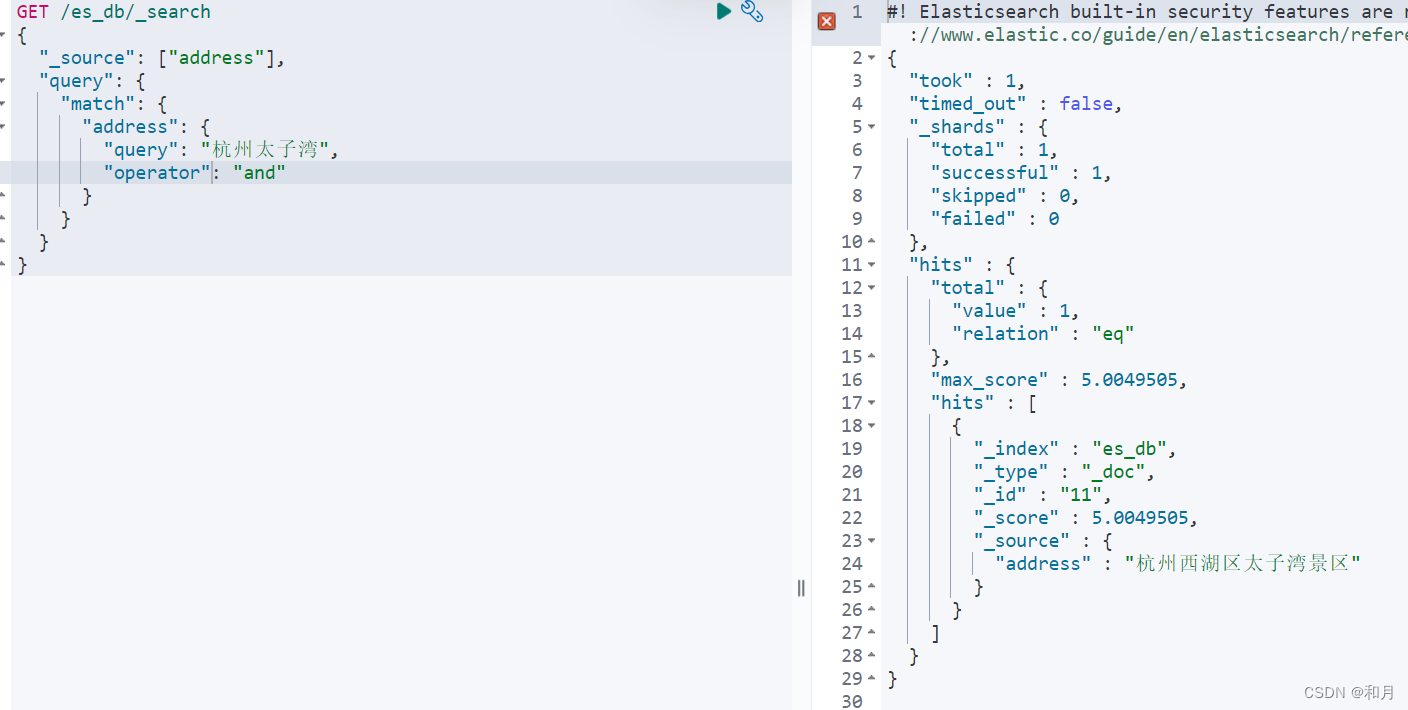
# 表示至少分词后 需要全部匹配
GET /es_db/_search
{
"_source": ["address"],
"query": {
"match": {
"address": {
"query": "杭州太子湾",
"operator": "and"
}
}
}
}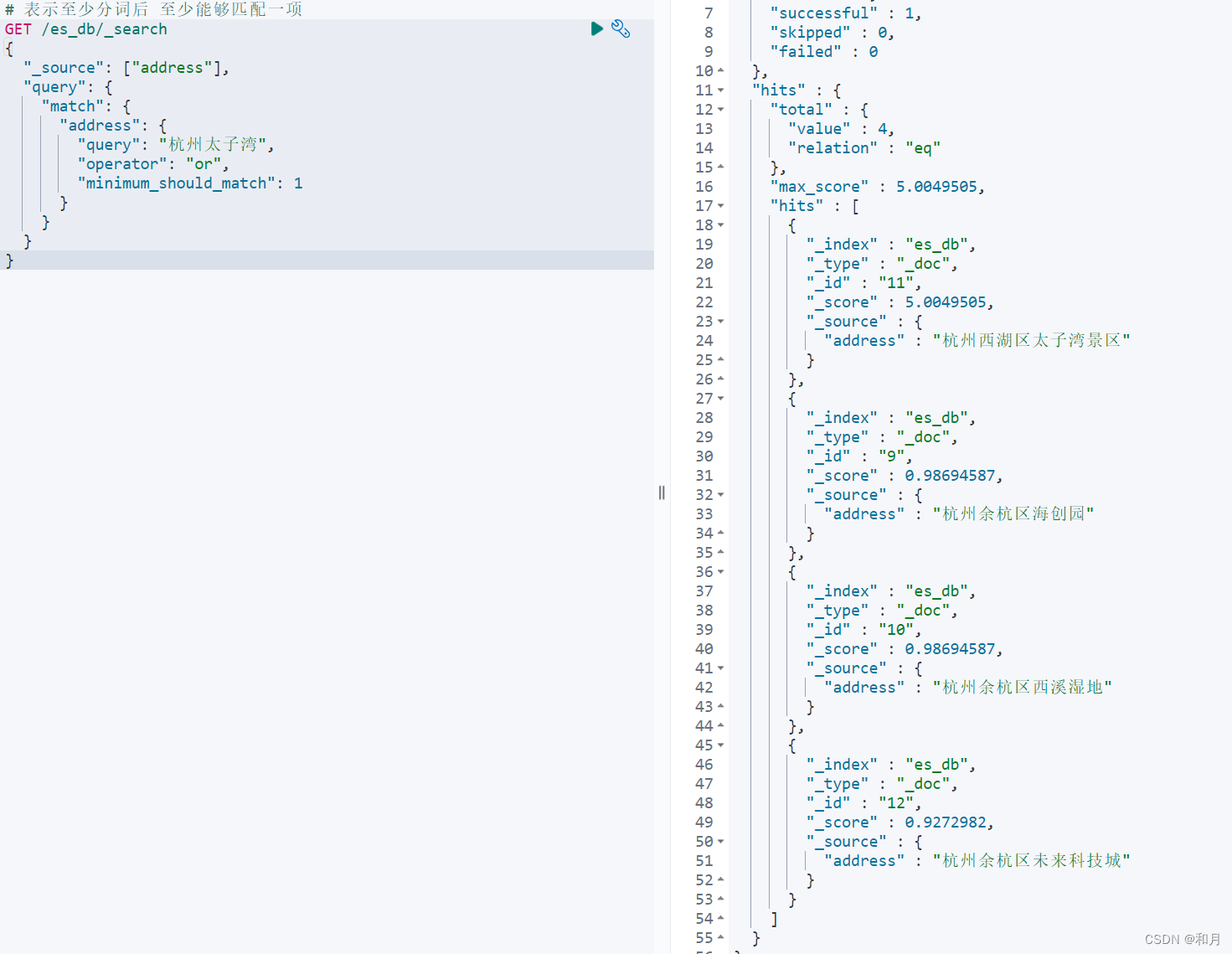
# 表示至少分词后 至少能够匹配一项
GET /es_db/_search
{
"_source": ["address"],
"query": {
"match": {
"address": {
"query": "杭州太子湾",
"operator": "or",
"minimum_should_match": 1
}
}
}
}multi_match query 多字段查询
可以根据字段类型,决定是否使用分词查询,得分最高的在前面

#多字段查询
GET /es_db/_search
{
"_source": ["address", "name"],
"query": {
"multi_match": {
"query": "杭州星云",
"fields": [
"address",
"name"
]
}
}
}注意:字段类型分词,将查询条件分词之后进行查询,如果该字段不分词就会将查询条件作为整体进行查询。
match_phrase query短语查询
短语搜索(match phrase)会对搜索文本进行文本分析,然后到索引中寻找搜索的每个分词并要求分词相邻,你可以通过调整slop参数设置分词出现的最大间隔距离。match_phrase 会将检索关键词分词。
这里可以看到 查询 杭州西湖 并没有查到数据,但是索引中是存在杭州西湖这样的文章的

我们先看一下文章分词结果
可以看到 杭州西湖 中间隔了一个 西湖区,所以需要使用 slop 进行设置最大间隔

这里设置了 允许间隔一个 可以看到能够查到对应数据了

GET _analyze
{
"analyzer": "ik_max_word",
"text": ["杭州西湖区太子湾景区"]
}
GET /es_db/_search
{
"query": {
"match_phrase": {
"address": {
"query": "杭州西湖",
"slop": 1
}
}
}
}query_string query
允许我们在单个查询字符串中指定AND | OR | NOT条件,同时也和 multi_match query 一样,支持多字段搜索。和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。
注意: 查询字段分词就将查询条件分词查询,查询字段不分词将查询条件不分词查询
语法:
注意 AND OR 需要大写
GET /es_db/_search
{
"query": {
"query_string": {
"default_field": "FIELD",
"query": "this AND that OR thus"
}
}
}未指定字段查询
可以根据查询条件,去全字段匹配,并计算算分返回

指定一个字段
指定字段后,只匹配指定的字段

指定多个字段

simple_query_string
类似Query String,但是会忽略错误的语法,同时只支持部分查询语法,不支持AND OR NOT,会当作字符串处理。支持部分逻辑:
- + 替代AND
- | 替代OR
- - 替代NOT


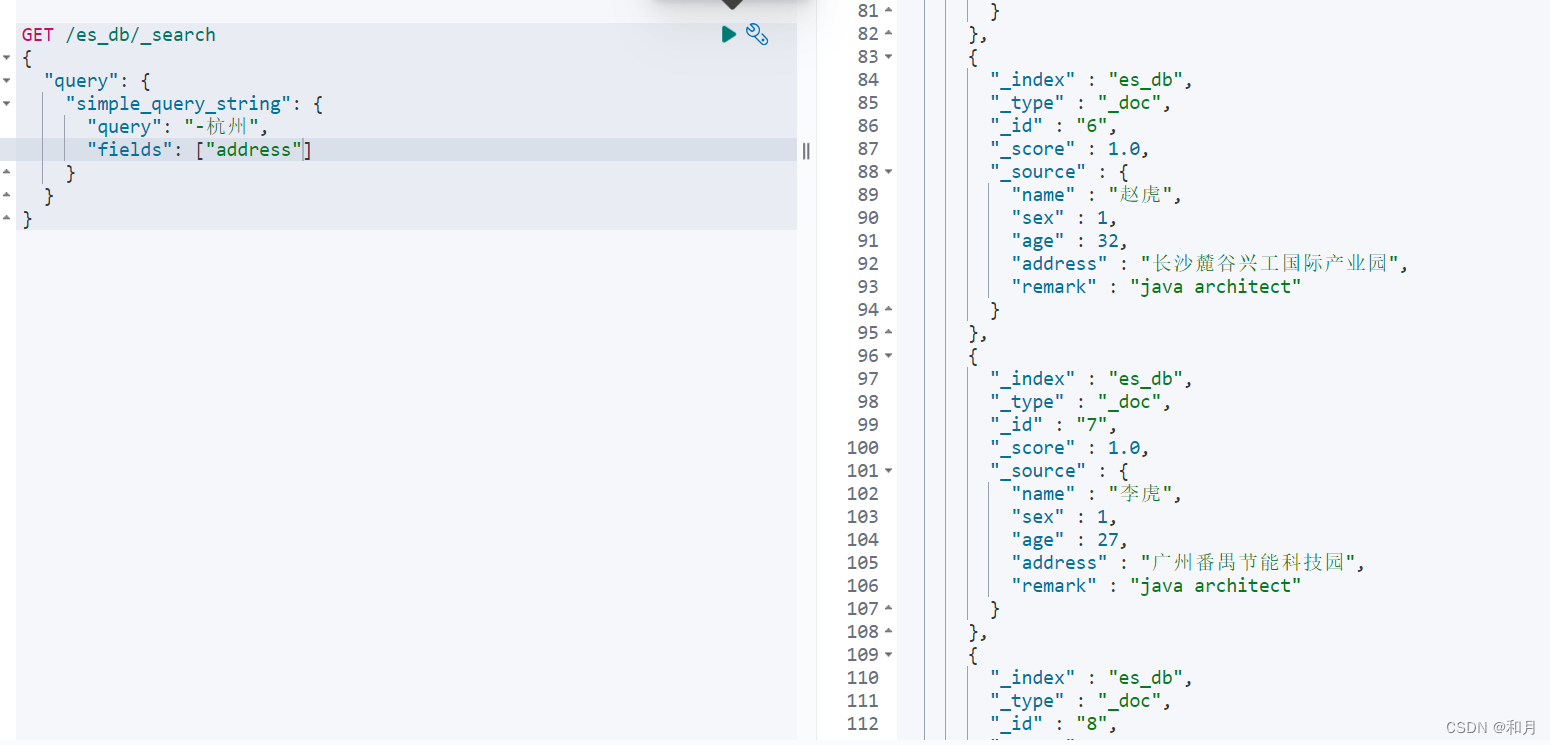
GET /es_db/_search
{
"query": {
"simple_query_string": {
"query": "星云 + 杭州",
"fields": ["address", "name"]
}
}
}
GET /es_db/_search
{
"query": {
"simple_query_string": {
"query": "星云 | 杭州",
"fields": ["address", "name"]
}
}
}
GET /es_db/_search
{
"query": {
"simple_query_string": {
"query": "-杭州",
"fields": ["address"]
}
}
}bool query布尔查询
布尔查询可以按照布尔逻辑条件组织多条查询语句,只有符合整个布尔条件的文档才会被搜索出来。
在布尔条件中,可以包含两种不同的上下文。
- 搜索上下文(query context):使用搜索上下文时,Elasticsearch需要计算每个文档与搜索条件的相关度得分,这个得分的计算需使用一套复杂的计算公式,有一定的性能开销,带文本分析的全文检索的查询语句很适合放在搜索上下文中。
- 过滤上下文(filter context):使用过滤上下文时,Elasticsearch只需要判断搜索条件跟文档数据是否匹配,例如使用Term query判断一个值是否跟搜索内容一致,使用Range query判断某数据是否位于某个区间等。过滤上下文的查询不需要进行相关度得分计算,还可以使用缓存加快响应速度,很多术语级查询语句都适合放在过滤上下文中。
布尔查询一共支持4种组合类型:
| 类型 | 说明 |
| must | 可包含多个查询条件,每个条件均满足的文档才能被搜索到,每次查询需要计算相关度得分,属于搜索上下文 |
| should | 可包含多个查询条件,不存在must和fiter条件时,至少要满足多个查询条件中的一个,文档才能被搜索到,否则需满足的条件数量不受限制,匹配到的查询越多相关度越高,也属于搜索上下文 |
| filter | 可包含多个过滤条件,每个条件均满足的文档才能被搜索到,每个过滤条件不计算相关度得分,结果在一定条件下会被缓存, 属于过滤上下文 |
| must_not | 可包含多个过滤条件,每个条件均不满足的文档才能被搜索到,每个过滤条件不计算相关度得分,结果在一定条件下会被缓存, 属于过滤上下文 |
准备数据:
DELETE /books
PUT /books
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 1
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"language": {
"type": "keyword"
},
"author": {
"type": "keyword"
},
"price": {
"type": "double"
},
"publish_time": {
"type": "date",
"format": "yyy-MM-dd"
},
"description": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
POST /_bulk
{"index":{"_index":"books","_id":"1"}}
{"id":"1", "title":"Java编程思想", "language":"java", "author":"Bruce Eckel", "price":70.20, "publish_time":"2007-10-01", "description":"Java学习必读经典,殿堂级著作!赢得了全球程序员的广泛赞誉。"}
{"index":{"_index":"books","_id":"2"}}
{"id":"2","title":"Java程序性能优化","language":"java","author":"葛一鸣","price":46.5,"publish_time":"2012-08-01","description":"让你的Java程序更快、更稳定。深入剖析软件设计层面、代码层面、JVM虚拟机层面的优化方法"}
{"index":{"_index":"books","_id":"3"}}
{"id":"3","title":"Python科学计算","language":"python","author":"张若愚","price":81.4,"publish_time":"2016-05-01","description":"零基础学python,光盘中作者独家整合开发winPython运行环境,涵盖了Python各个扩展库"}
{"index":{"_index":"books","_id":"4"}}
{"id":"4", "title":"Python基础教程", "language":"python", "author":"Helant", "price":54.50, "publish_time":"2014-03-01", "description":"经典的Python入门教程,层次鲜明,结构严谨,内容翔实"}
{"index":{"_index":"books","_id":"5"}}
{"id":"5","title":"JavaScript高级程序设计","language":"javascript","author":"Nicholas C. Zakas","price":66.4,"publish_time":"2012-10-01","description":"JavaScript技术经典名著"}
must
条件必须同时满足
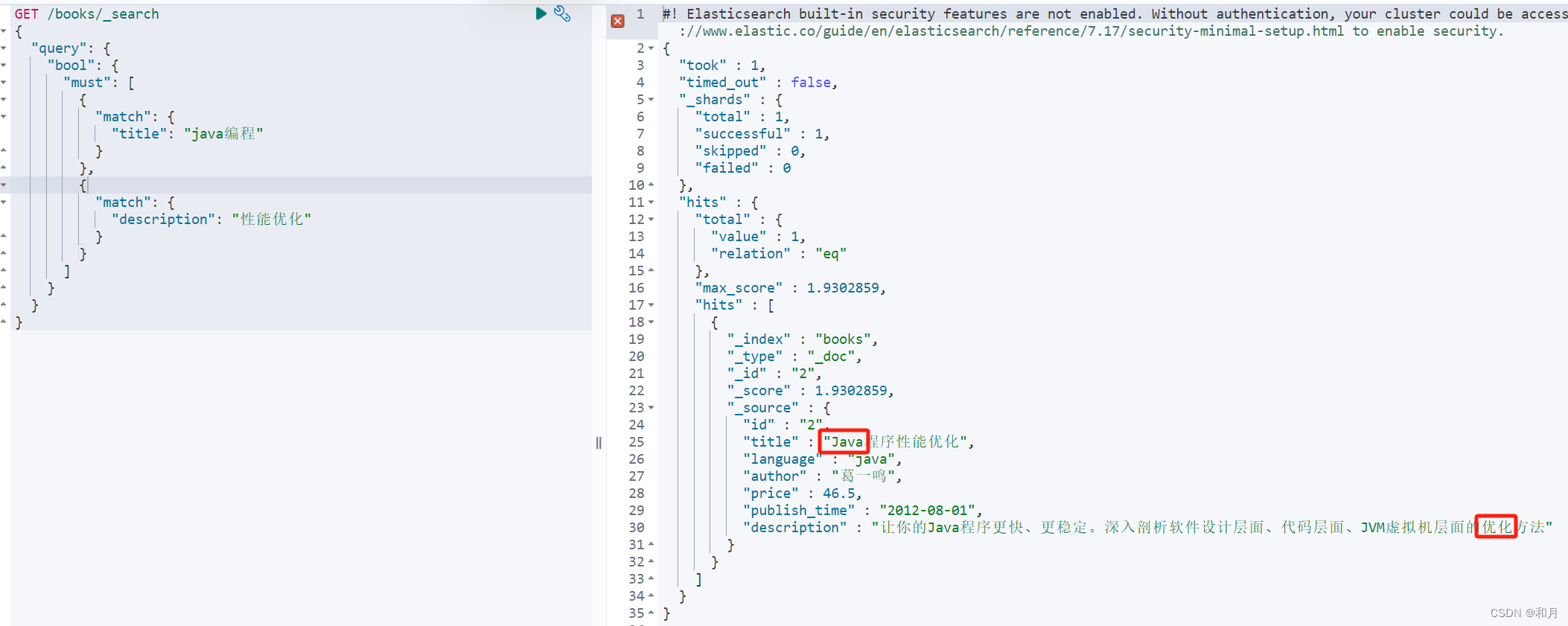
should
至少满足其中一项

filter 过滤
可以看到是不计算 算分 的

highlight高亮
highlight 关键字: 可以让符合条件的文档中的关键词高亮。
highlight相关属性:
- pre_tags 前缀标签
- post_tags 后缀标签
- tags_schema 设置为styled可以使用内置高亮样式
- require_field_match 多字段高亮需要设置为false
示例数据:
#指定ik分词器
PUT /products
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
PUT /products/_doc/1
{
"proId" : "2",
"name" : "牛仔男外套",
"desc" : "牛仔外套男装春季衣服男春装夹克修身休闲男生潮牌工装潮流头号青年春秋棒球服男 7705浅蓝常规 XL",
"timestamp" : 1576313264451,
"createTime" : "2019-12-13 12:56:56"
}
PUT /products/_doc/2
{
"proId" : "6",
"name" : "HLA海澜之家牛仔裤男",
"desc" : "HLA海澜之家牛仔裤男2019时尚有型舒适HKNAD3E109A 牛仔蓝(A9)175/82A(32)",
"timestamp" : 1576314265571,
"createTime" : "2019-12-18 15:56:56"
}默认高亮

GET /products/_search
{
"query": {
"match": {
"name": "牛仔"
}
},
"highlight": {
"fields": {
"*": {}
}
}
}也可以指定高亮标签

GET /products/_search
{
"query": {
"multi_match": {
"query": "牛仔",
"fields": ["name", "desc"]
}
},
"highlight": {
"pre_tags": ["<span style='color:red'>"],
"post_tags": ["</span>"],
"fields": {
"*": {}
}
}
}
多字段高亮
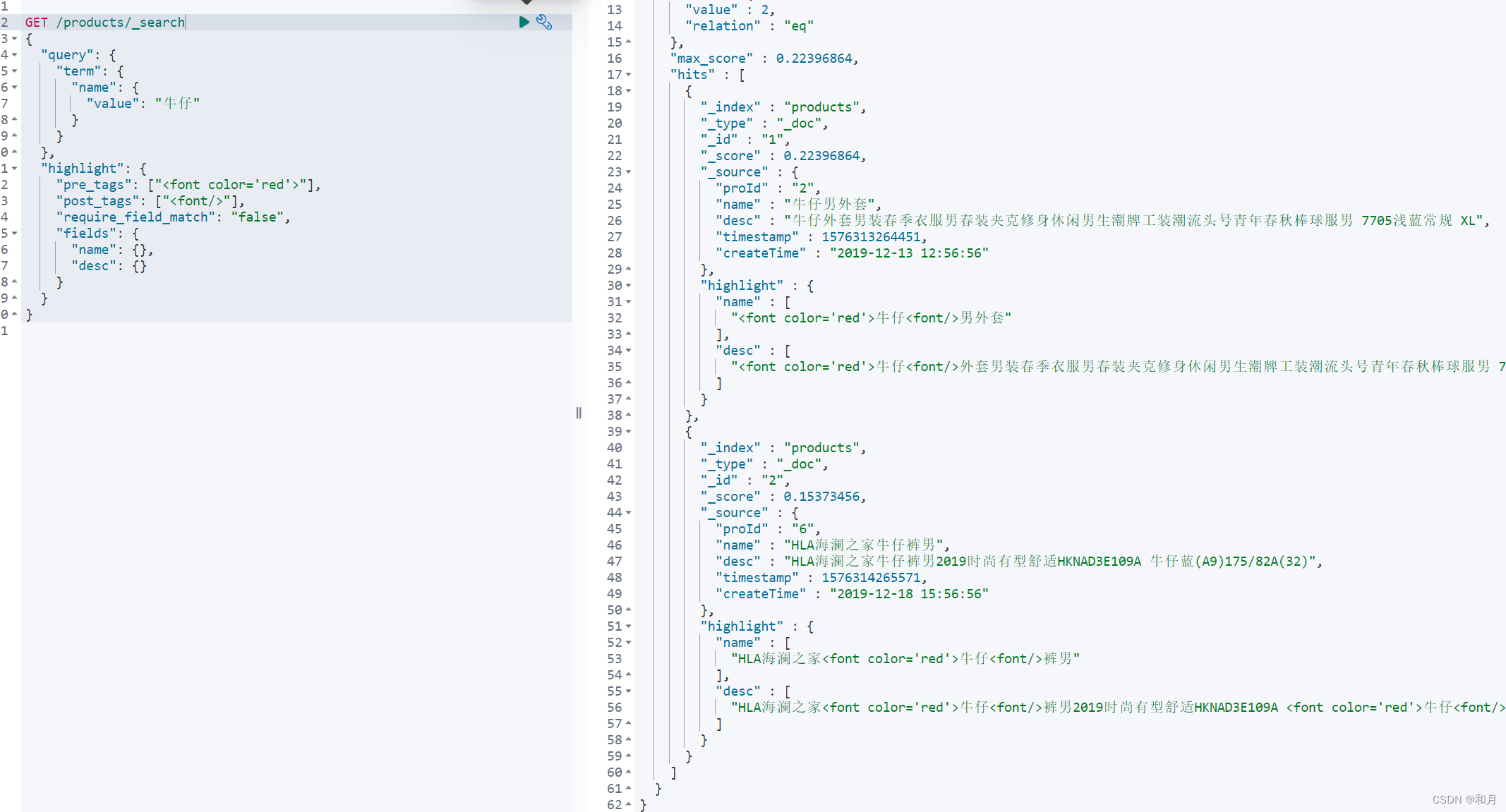
GET /products/_search
{
"query": {
"term": {
"name": {
"value": "牛仔"
}
}
},
"highlight": {
"pre_tags": ["<font color='red'>"],
"post_tags": ["<font/>"],
"require_field_match": "false",
"fields": {
"name": {},
"desc": {}
}
}
}感谢观看!!!感兴趣的小伙伴可以关注留言,持续更新中!!!