文章目录
- TEASEL:一种基于Transformer的语音前缀语言模型
- 文章信息
- 研究目的
- 研究内容
- 研究方法
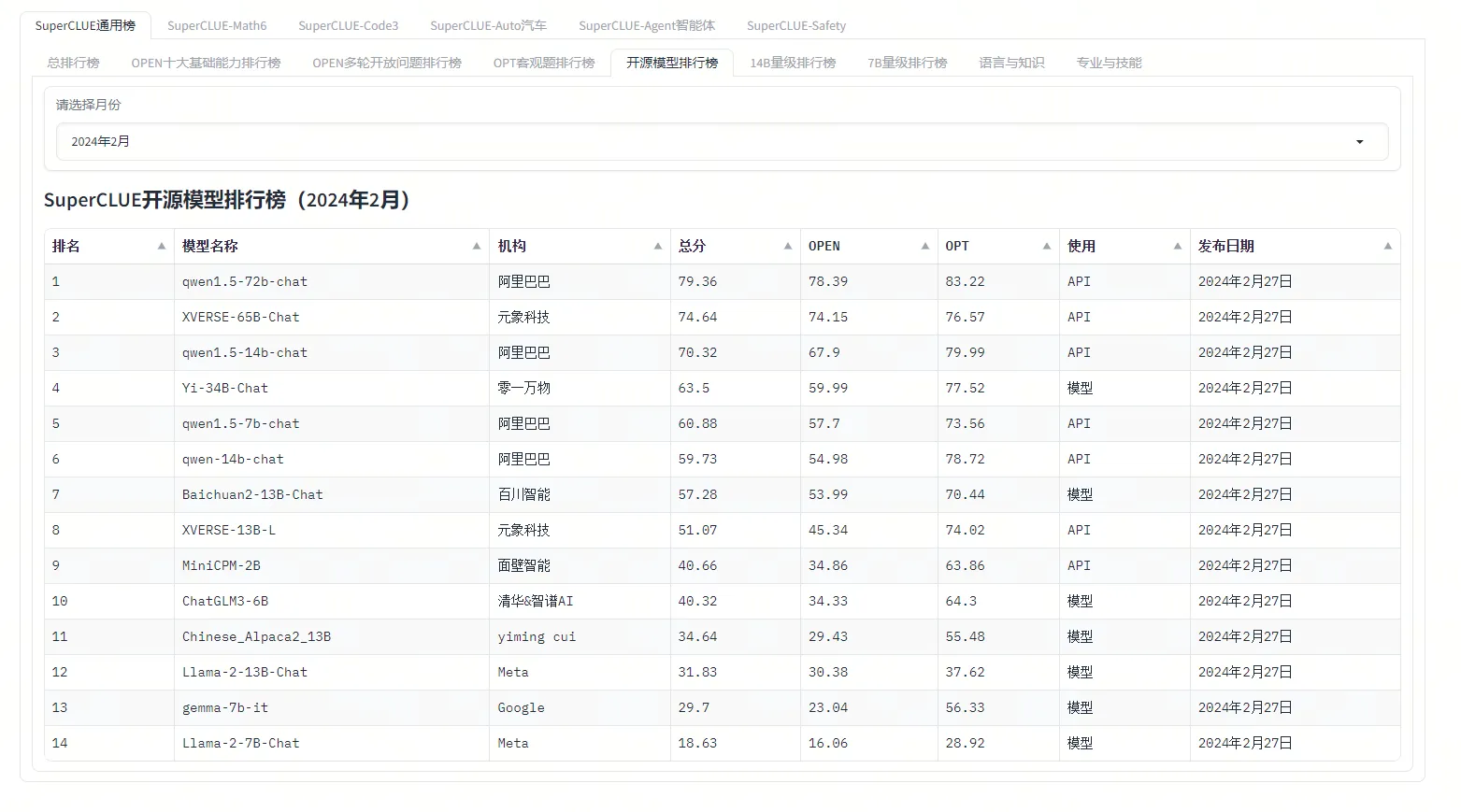
- 1.总体框图
- 2.BERT-style Language Models(基准模型)
- 3.Speech Module
- 3.1Speech Temporal Encoder
- 3.2Lightweight Attentive Aggregation (LAA)
- 4.训练过程
- 4.1预训练阶段
- 4.2微调阶段
- 4.3TEASEL模型训练的算法伪代码
- 结果与讨论
- 代码和数据集
- 附录
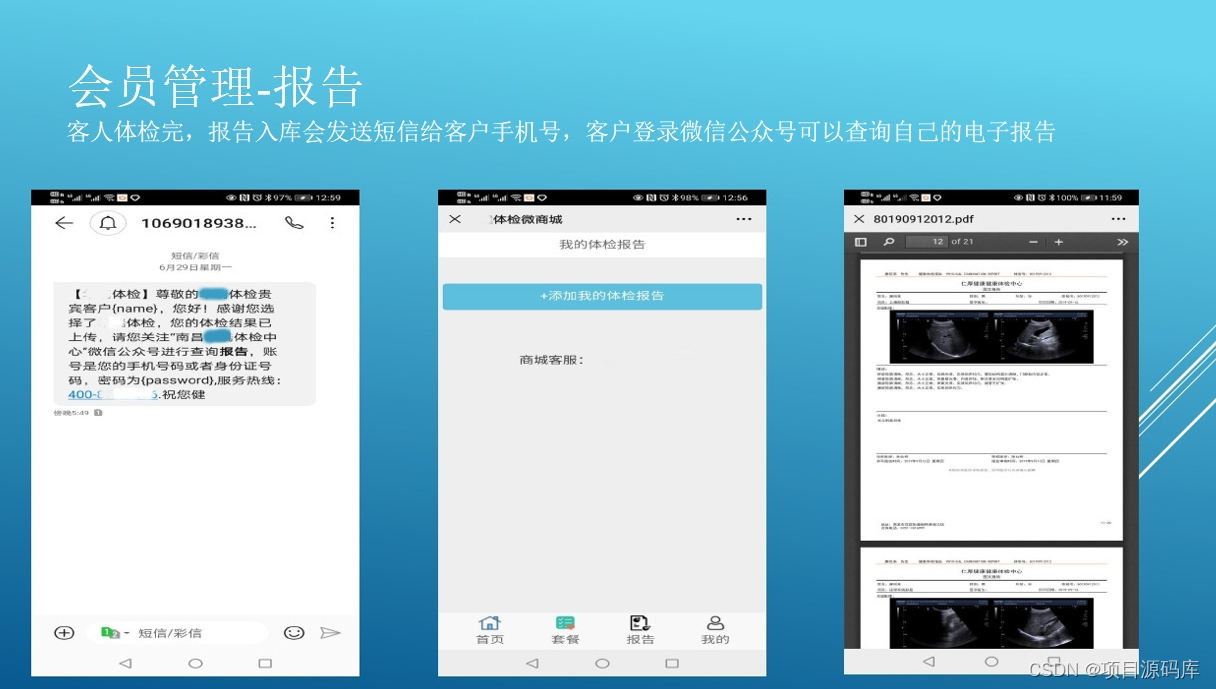
TEASEL:一种基于Transformer的语音前缀语言模型
总结:论文提出了一种基于 Transformer 的语音前缀语言模型 TEASEL,实际本质是用了一个 RoBERTa 模型作为框架,然后加入了一个 LAA 模块(LAA模块就是将音频特征编码为 RoBERTa 编码器的前缀 token)。在训练的时候主要是训练 LAA 模块的参数,当 LAA 模块的参数收敛后,在CMU-MOSI数据集上面微调整个模型。
该论文在2021年就挂在arXiv上面了,但是一直没有发表,看了这篇论文之后,终于知道为什么没有发表了,论文里面有一些错误的地方,而且对自己方法的介绍稀里糊涂的,一些词用的很偏僻,很难以理解。但是最奇怪的是,作者没有提供代码,GitHub上面有人根据算法的思想实现了这个模型,并且在 MSA 任务上的一些指标竟然是 SOTA 的结果。所以本人参考代码,以及论文的思想,终于把这篇论文挖掘出来了。如果大家有不同的看法,欢迎留言 😃
文章信息
作者:Mehdi Arjmand,Mohammad Javad Dousti
单位:University of Tehran(德黑兰大学-伊朗)
会议/期刊:arXiv
题目:TEASEL: A transformer-based speech-prefixed language model
年份:2021
研究目的
解决在多模态语言学习(包括多模态情感分析与多模态情感识别)中,由于数据不足,难以训练一个关于多模态语言学习的自监督Transformer模型的问题。(换句话说,作者想要在不训练完整的Transformer模型的情况下,训练一个关于多模态语言学习的自监督 Transformer模型。)
研究内容
提出了一种基于Transformer的语音前缀语言模型TEASEL。与传统的语言模型相比,增加了语音模态作为动态前缀。该模型可以达到与花费较长时间重新训练Transformer相同的性能水平,而无需训练完整的Transformer模型。
研究方法
1.总体框图
该模型利用传统的预训练语言模型(指的就是RoBERTa)作为跨模态注意力模块。从根本上来说,TEASEL 模型专注于将语音特征表示为RoBERTa的前缀(参考图中的 C A C_A CA)。

训练包含两个阶段:预训练和微调。
- 在预训练阶段,使用 LAA 模块学习语音模态的表征,以便在 RoBERTa 中插入语音模态,训练步骤相对较少(总共 8000 步)。(预训练阶段做的事情,就是对 LAA 模块进行训练)
- 在微调阶段,固定了 LAA 模块的大部分内容,并在 CMU-MOSI 数据集上微调了 RoBERTa 模型,将其作为多模态情感分析下游任务的跨模态 Transformer。(微调阶段做的事情,就是对 RoBERTa 模型进行了调参)
2.BERT-style Language Models(基准模型)
将 RoBERTa 模型作为 BERT-style Language Models(选择RoBERTa作为基准模型是因为RoBERTa是专门针对 MaskedLM 任务训练的)。
RoBERTa tokenizer标记器将句子 L 分解为:
{
[
C
L
S
]
,
l
1
,
l
2
,
…
,
l
T
L
,
[
S
E
P
]
}
=
t
o
k
e
n
i
z
e
r
(
L
)
\{[CLS],l_{1},l_{2},\ldots,l_{T_{\mathbf{L}}},[SEP]\}=tokenizer(L)
{[CLS],l1,l2,…,lTL,[SEP]}=tokenizer(L)
| 符号 | 含义 |
|---|---|
| l i ∈ R d l_i \in R_d li∈Rd | 每个token |
| T L T_L TL | 文本模态的时间步数(序列的长度) |
| [CLS] | 代表序列的开始,只关注[CLS]对应的输出 |
| [SEP] | 代表分割 |
| [MASK] | 代表屏蔽的token |
3.Speech Module
3.1Speech Temporal Encoder
选择 wav2vec 预先训练好的固定参数的 CNN 作为音频特征编码器,来提取音频特征。
{
z
1
,
z
2
,
…
,
z
T
A
;
z
i
∈
R
d
A
}
=
C
N
N
θ
w
(
ψ
)
\{z_1,z_2,\ldots,z_{T_{\mathbf{A}}};z_i\in\mathbb{R}^{d_A}\}=\mathrm{CNN}_{\theta_{\mathbf{w}}}(\psi)
{z1,z2,…,zTA;zi∈RdA}=CNNθw(ψ)
| 符号 | 含义 |
|---|---|
| ψ \psi ψ | 原始的语音数据 |
| z i z_i zi | 第i个时间步对应的特征 |
3.2Lightweight Attentive Aggregation (LAA)
轻量级注意力聚合模块 LAA 的目的是将 Z(Z就是经过CNN提取的音频特征) 编码为 RoBERTa 编码器的前缀 token。

LLA 在提取的语音特征的顶部执行双向门控循环单元(BiGRU),以双向行为捕捉信息。然后利用聚合模块(Aggregation Module)将 BiGRU 的输出进行动态加权求和。
整体过程如下所示:(公式在原论文的基础上进行了修改,个人认为作者的公式在动态加权求和的时候有问题)
Z
^
=
L
a
y
e
r
N
o
r
m
(
Z
)
(
1
)
Φ
=
B
i
G
R
U
(
W
1
⊺
Z
^
+
b
1
)
,
(
2
)
Φ
=
{
{
ϕ
1
,
1
,
…
,
ϕ
1
,
T
A
}
,
{
ϕ
2
,
1
,
…
,
ϕ
2
,
T
A
}
}
,
(
3
)
u
k
,
i
=
σ
(
W
A
g
g
1
T
ϕ
k
,
i
+
b
A
g
g
1
)
,
k
∈
{
1
,
2
}
,
i
∈
{
1
,
T
}
(
4
)
α
k
,
i
=
S
o
f
t
m
a
x
(
W
A
g
g
2
I
u
k
,
i
+
b
A
g
g
2
)
,
α
k
,
i
∈
[
0
,
1
]
(
5
)
C
A
=
∑
i
=
1
T
α
k
,
i
ϕ
k
,
i
(
6
)
\begin{gathered} \hat{Z}=LayerNorm(Z)\quad(1)\\ \\ \Phi=BiGRU(W_{1}^{\intercal}\hat{Z}+b_{1}), \quad(2)\\ \\ \Phi=\{\{\phi_{\mathbf{1},1},\ldots,\phi_{\mathbf{1},T_{\mathbf{A}}}\},\{\phi_{\mathbf{2},1},\ldots,\phi_{\mathbf{2},T_{\mathbf{A}}}\}\}, \quad(3)\\ \\ u_{k,i}=\sigma(W_{Agg_1}^\mathsf{T}\phi_{k,i}+b_{Agg_1}),k\in\{1,2\},i \in {\{1,T\}}\quad(4)\\ \\ \alpha_{k,i}=Softmax(W_{Agg_2}^{\mathsf{I}}u_{k,i}+b_{Agg_2}),\alpha_{k,i}\in[0,1]\quad(5)\\ \\ \mathcal{C}_\mathbf{A}=\sum_{i=1}^T\alpha_{k,i}\phi_{k,i} \quad(6) \end{gathered}
Z^=LayerNorm(Z)(1)Φ=BiGRU(W1⊺Z^+b1),(2)Φ={{ϕ1,1,…,ϕ1,TA},{ϕ2,1,…,ϕ2,TA}},(3)uk,i=σ(WAgg1Tϕk,i+bAgg1),k∈{1,2},i∈{1,T}(4)αk,i=Softmax(WAgg2Iuk,i+bAgg2),αk,i∈[0,1](5)CA=i=1∑Tαk,iϕk,i(6)
| 符号 | 含义 |
|---|---|
| Φ ∈ A 2 × T A × d A \Phi\in\mathbf{A}^{2\times T_{A}\times d_{A}} Φ∈A2×TA×dA | Bi-GRU的输出序列 |
| σ \sigma σ | 激活函数 |
| C A ∈ R 2 × d a \mathcal{C}_\mathbf{A}\in\mathbb{R}^{2\times d_a} CA∈R2×da | 两个可用于 RoBERTa 的语音前缀token |
4.训练过程
4.1预训练阶段
输入序列 { [ C L S ] , l 1 , l 2 , … , l T L , [ S E P ] } \{[CLS],l_{1},l_{2},\ldots,l_{T_{\mathbf{L}}},[SEP]\} {[CLS],l1,l2,…,lTL,[SEP]}给预先训练好的 RoBERTa 模型,然后只计算语音输出token(也就是 C A C_A CA)的损失函数,梯度只影响 LAA 模块。
使用 LIBRISPEECH 数据集对 LAA 模块进行了 8000 步训练(通过实验观察,进行8000步,模型收敛,F1分数趋于稳定,故训练8000步)。每 2,000 步保存一次模型,并对保存的参数进行微调,以便在 CMU-MOSI 数据集上进行高效的多模态情感分析。

4.2微调阶段
将语音前缀和文本token输入到 RoBERTa 模型,根据[CLS]对应的输出,对 RoBERTa 模型进行微调。

4.3TEASEL模型训练的算法伪代码

结果与讨论
⚠ 斜体是消融实验
- 通过与一些仅限于文本的流行Transformer方法、基于Transformer的冻结特征方法、为下游任务微调Transformer的方法进行对比,TEASEL在Corr、ACC-2与F1分数上的表现是最佳的。
- 在相同的条件下,对预训练TEASEL的不同步数下的参数进行微调,表明了预训练 LAA 模块是有效的,也证明了训练8000步是刚刚好的。
- 通过对微调部分应该固定 LAA 模块的哪些部分进行了详尽的实验,证明了不需要对整个 LAA 模块进行微调。
- 对测试集中的某个随机数据的注意力激活层进行可视化,证明了语音前缀的有效性。
代码和数据集
此代码是别人复现的,论文作者并没有提供。
代码:https://github.com/tjdevWorks/TEASEL
数据集:CMU-MOSI
实验环境:GitHub上面,有人复现这个代码,使用Tesla V100都显示CUDA内存不足。
附录
MaskedLM 任务:旨在使用句子中未屏蔽的全部词语来预测随机屏蔽的标记。标准的 MaskedLM 80% 的时间使用 [MASK] token,10% 的时间使用random token,10% 的时间使用unchanged token,迫使语言模型顺利地预测输出标记。
wav2vec模型:wav2vec模型利用五层卷积神经网络(CNN)作为时间特征编码器,并利用BERT-style Transformer作为上下文编码器。
BiGRU单元:BiGRU单元指的是双向门控循环单元(Bidirectional Gated Recurrent Unit)。它是一种特殊的循环神经网络(RNN)结构,用于处理序列数据。BiGRU通过结合两个GRU层来工作,一个处理正向时间序列(从开始到结束),另一个处理反向时间序列(从结束到开始)。这种结构允许网络同时学习过去和未来的上下文信息,提高了对序列数据的理解能力。GRU单元结构:

😃😃😃