深度学习
- 深度学习是特殊的机器学习,使用复杂的、多层神经网络进行学习。
- 深度神经网络(DNN),每层学习的信息的复杂度是不断增加的。
- 例如面部识别,第一层识别眼睛、第二层识别鼻子,直到所有的面部特征识别完毕。
- 深度学习近年来才热门起来,原因是数据产生速度变快了,处理海量数据的基础实现了
- 深度学习成为驱动机器学习的关键技术,在图像识别、自动驾驶、语音识别和游戏领域应用广泛。
- 关键:数据对机器学习非常重要,相当于汽车中的石油,而图形处理单元(GPU)相当于汽车中的发动机。
数据分析工具Pandas
在机器学习中,数据的处理是非常重要的一个环节,当然离不开Python的数据分析工具Pandas。
Pandas提供丰富的数据结构和数据处理工具,使得在数据中处理数据和分析变得非常高效
核心的两个工具是Series和DataFrame
- Series:类似于一组数组对象,由一组数据以及与之相关的索引组成
- DateFrame:类似于二维表格的数据结构,可以看作是多个series组成的数据结构,每个series代表一列数据
- 功能丰富:数据读取和写入,数据清洗和转换、数据筛选和排序、数据分组和聚合、时间序列分析等等。
用DataFrame导入数据
下面以加州大学欧文分校(UCI)免费提供的鸢尾属植物数据集为例:
这个数据包含了(萼片的长度和宽度,花瓣的长度和宽度),是区分不同类型鸢尾花的特征。
import pandas as pd
input_path=r"F:\ML\machine_learning_databases\iris\iris.data"
df=pd.read_csv(input_path,names=['sepal_length','sepal_width','petal_length','petal_width','class'])
print(df.info())
从上面的图中,我们可以看到数据有150行,每一行有5列,其中前四列的数据属性是浮点型的数值形式,花萼的长度宽度、花瓣的长度和宽度,最后一列是非数值形式,表示花的种类。
使用describe函数获取四个数值列的统计信息。
print(df.describe())sepal_length sepal_width petal_length petal_width count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.054000 3.758667 1.198667 std 0.828066 0.433594 1.764420 0.763161 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000
查看前十行数据
print(df.head(10))sepal_length sepal_width petal_length petal_width class 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa 5 5.4 3.9 1.7 0.4 Iris-setosa 6 4.6 3.4 1.4 0.3 Iris-setosa 7 5.0 3.4 1.5 0.2 Iris-setosa 8 4.4 2.9 1.4 0.2 Iris-setosa 9 4.9 3.1 1.5 0.1 Iris-setosa
使用loc命令获取数据集中花萼长度大于5.0的行
df2=df.loc[df['sepal_length']>5.0,]
print(df2.head(10))sepal_length sepal_width petal_length petal_width class 0 5.1 3.5 1.4 0.2 Iris-setosa 5 5.4 3.9 1.7 0.4 Iris-setosa 10 5.4 3.7 1.5 0.2 Iris-setosa 14 5.8 4.0 1.2 0.2 Iris-setosa 15 5.7 4.4 1.5 0.4 Iris-setosa 16 5.4 3.9 1.3 0.4 Iris-setosa 17 5.1 3.5 1.4 0.3 Iris-setosa 18 5.7 3.8 1.7 0.3 Iris-setosa 19 5.1 3.8 1.5 0.3 Iris-setosa 20 5.4 3.4 1.7 0.2 Iris-setosa
可以看到此时呈现出来的数据集,花萼长度那一列的数据已经过滤掉小于5.0的数据了
数据可视化
探索性数据分析是机器学习过程中的非常重要的缓解,Pandas可以帮助我们轻松实现数据可视化,可视化需要使用的包是Matplotlib
举个例子,我们可以使用散点图来查看鸢尾花的花瓣长度和宽度之间的分布关系,通过点的分布差异来看出特征的差异分布。
不同类别的点要用不同的标记,下面是不同标记的程序代号
图片来源:【python】Matplotlib作图常用marker类型、线型和颜色 - 大大西瓜吃不饱 - 博客园 (cnblogs.com)

import matplotlib.pyplot as plt
marker_shapes=['P','*','d']
colors=['red','blue','green']
ax=plt.axes()
for i,species in enumerate(df['class'].unique()):
species_data = df[df['class']==species]
species_data.plot.scatter(x='petal_length',y='petal_width',marker=marker_shapes[i],color=colors[i],s=100,title="Petal Width VS Length by Species",label=species,figsize=(10,7),ax=ax)-
for i,species in enumerate(df['class'].unique())::遍历数据中的物种类别,使用enumerate函数获取物种类别唯一值索引i和物种名称species。 -
species_data = df[df['class']==species]:根据物种名称筛选数据,选择对应物种的数据,并存储到species_data中。
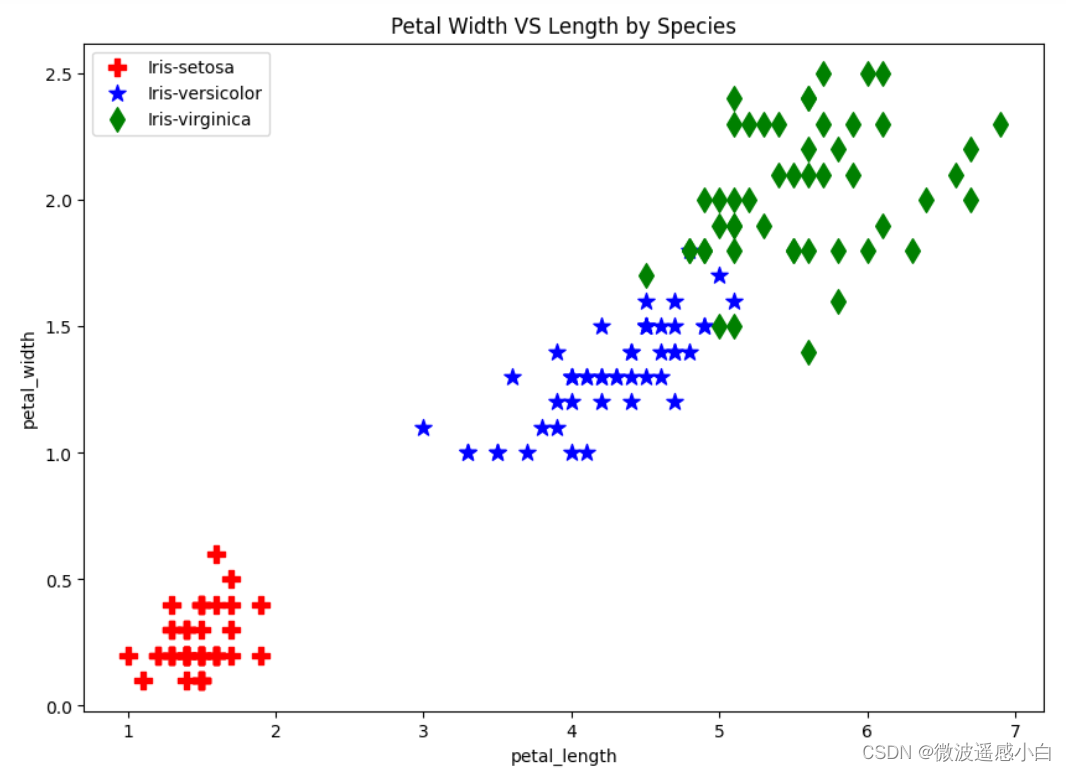
从图中可以看出,根据鸢尾花的花瓣的长度和宽度已经可以明显地区分出鸢尾花的类别了,其次鸢尾花的花瓣的长度和宽度呈现线性关系。所以我们明白,想要区分鸢尾花的类别,花瓣的长度和宽度是非常重要的特征。
其次,直方图是查看数据分布的非常有效的方法。
使用pandas内嵌的直方图函数绘制直方图。
plt.figure(figsize=(10,7))
df['petal_length'].plot.hist(title='Histogram of Petal Length',color='orange')
从图中我们可以看到,鸢尾花的花瓣长度有着明显的两极分化的,长度很长,短的也很短。
然后使用箱线图对数据进行挖掘,箱线图可以让我们知晓数据的分布情况,最大最小值,第一四分位数,中位数,第三四分位数。

通过箱线图,我们看到,花瓣长度有着最大的方差,数据离散程度大,而花萼宽度方差小,数据更加聚集。
Pandas进行数据预处理
编码类别变量
- 类别变量是很常见的,比如时期,物种,语言等等,都是用非数值的方式表示的
- 但是机器学习中是无法处理非数值表示的变量,只能接收数值变量
- 所以对类别变量进行编码是非常有必要的
- Pandas中get_dummies函数实现类别变量转换为二元特征变量。
独热编码
独热编码(One-Hot Encoding)是一种常用的数据编码方式,也被称为一位有效编码。它的基本思想是使用N位状态寄存器来对N个状态进行编码,每个状态都由它独立的寄存器位,并且在任意时候只有一位有效。
例如,如果我们有一个分类特征,如性别,其可能的值为“男”和“女”,那么我们可以使用独热编码将其转换为一个两位向量。在这个例子中,“男”会被编码为`[1,0]`,而“女”会被编码为`[0,1]`。同样地,如果我们有一个特征是年级,可能的值为“初一”,“初二”和“初三”,那么我们可以使用独热编码将其转换为一个三位向量。在这个例子中,“初一”会被编码为`[1,0,0]`,“初二”会被编码为`[0,1,0]`,而“初三”会被编码为`[0,0,1]`。
独热编码的主要作用是将非数字型的数据转换为数字型,使得数据可以在计算机程序中使用。此外,独热编码还可以增加数据的维度,使模型能够更好地捕捉到不同类别间的差异。
需要注意的是,虽然独热编码可以将非数字型的数据转换为数字型,但并不能保证转换后的数据是有序的。也就是说,我们不能认为`[1,0]`比`[0,1]`大,或者`[1,0,0]`比`[0,1,0]`大。这是因为独热编码只是将每个类别映射到一个唯一的编码,而不考虑类别的顺序或相对位置。
df3=pd.DataFrame({"Day":["Monday","Tuesday","Wednesday","Thursday","Friday","Saturday","Sunday"]})
print(df3)Day 0 Monday 1 Tuesday 2 Wednesday 3 Thursday 4 Friday 5 Saturday 6 Sunday
对原始数据进行独热编码
Day_Friday Day_Monday Day_Saturday Day_Sunday Day_Thursday \ 0 0 1 0 0 0 1 0 0 0 0 0 2 0 0 0 0 0 3 0 0 0 0 1 4 1 0 0 0 0 5 0 0 1 0 0 6 0 0 0 1 0 Day_Tuesday Day_Wednesday 0 0 0 1 1 0 2 0 1 3 0 0 4 0 0 5 0 0 6 0 0
填充缺失数据
真实世界数据庞杂且包含缺失值
机器学习模型遇到缺失值就不能工作
对缺失值进行填充非常必要
方法一 删除缺失值
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
marker_shapes=['P','*','d']
colors=['red','blue','green']
input_path=r"F:\ML\machine_learning_databases\iris\iris.data"
df=pd.read_csv(input_path,names=['sepal_length','sepal_width','petal_length','petal_width','class'])
random_index=np.random.choice(df.index,replace=False,size=10)
df.loc[random_index,'sepal_length']=None
print(df.isnull().any())使用`np.random.choice`函数从DataFrame `df`的索引中随机选择10个不重复的索引值。`replace=False`参数确保每个索引值只被选中一次。然后,使用`.loc[]`访问器将这些随机选定的行中'sepal_length'列的值设置为`None`。这样做将会在DataFrame `df`中随机选择10行,并将这些行的'sepal_length'列的值清除掉。
sepal_length True sepal_width False petal_length False petal_width False class False dtype: bool
使用dropna函数移除缺失值
print("Number of rows before deleting: %d" % (df.shape[0]))
df2=df.dropna()
print("Number of rows after deleting: %d" % (df2.shape[0]))shape[0]表示行数,shape[1]表示列数
Number of rows before deleting: 150 Number of rows after deleting: 140
方法二 均值替换法
df.sepal_length = df.sepal_length.fillna(df.sepal_length.mean())使用df.sepal_length.fillna()方法将'sepal_length'列中的所有NaN值替换为步骤1计算出的平均值。
在Pandas中,访问DataFrame的列可以通过两种方式进行:
-
使用方括号
df['sepal_length']:这种方式允许你通过列名(字符串类型)访问DataFrame的列。如果列名是一个有效的Python变量名,你也可以不使用引号。使用方括号访问列时,返回的是一个Series对象。 -
使用点号
df.sepal_length:这种方式同样可以访问列,但它要求列名遵循Python的变量命名规则,即只能包含字母、数字和下划线,且不能以数字开头。使用点号访问列时,也会返回一个Series对象。
开源深度学习库
TensorFlow和Keras
- TensorFlow是最流行的机器学习库之一
- 很多的AI服务都是由机器学习库TensorFlow支持的,图像搜索,推荐引擎,语音识别
- Keras是一个高级应用程序接口,构建在Tensorflow,Keras的作用消除了构建神经网络的复杂性,可以快速构建模型进行实验和测试,而不需要让用户考虑底层实现细节。
- Keras基于TensorFlow提供了简单且符合直觉的API用于构建神经网络,且设计准则是模块化具有扩展性。
- 可以将Keras理解为积木,通过各个模块的拼接实现代码大楼的搭建。
Keras中的基础构建单元
- 基础构建单元是层(Layer),多个层进行线性地堆叠起来,可以构建出神经网络模型
- 使用优化器对模型进行训练并选择损失函数作为评估标准
- 在上一章节中,使用了简单的感知机来进行训练和预测,其实那就是keras层封装的内容。
keras基本构建单元之间的关系
- 输入
- 层1
- 层2
- 层3
- 层4
- 模型层的结合
- 损失函数
- 优化器
- 编译
- 训练
- 输出
详细了解层的概念
层与层之间的关系有着数学运算,可能是线性运算,上一层的输出也是下一层的输入。
Keras中的核心层包括致密层(dense layer),激活层(activation layer)和Dropout层
更为复杂的层有卷积层(convolutional layer)和池化层(pooling layer)
池化(Pooling)是一种在卷积神经网络(Convolutional Neural Networks, CNNs)中常用的操作,旨在减少数据的空间尺寸,从而减少计算量和参数的数量,同时保持重要信息。池化层是指在CNN中专门执行池化操作的一层。
keras最常用的层是Dense layer,也就是全连接层。
在Keras中,全连接层(Dense layer)的数学函数通常是一个线性变换,加上一个非线性激活函数。具体来说:
1. 线性变换:对于输入向量 ,全连接层会将其映射到输出向量
,其中 m 是该层的神经元数量。线性变换由权重矩阵
和偏置向量
定义,计算公式如下:
这里是未经激活函数处理的中间输出向量。
2. 非线性激活函数:为了引入非线性,通常会在上述线性变换后应用一个激活函数σ。最常用的激活函数包括Sigmoid、Tanh和ReLU。激活函数的选择会影响网络的学习能力和表达能力。
模型——层的集合
常见的模型:
- 顺序模型——模型的线性堆叠
Keras可以很轻松地解决连续层之间保持相互兼容的维度问题
损失函数
损失函数是评价模型预测好坏的标准
keras有很多损失函数
mean_squared_error (MSE)、categorical_crossentropy 和 binary_crossentropy 是Keras中用于计算损失函数的三种不同类型,它们分别适用于不同的预测任务:
-
mean_squared_error (MSE):均方误差损失函数用于回归任务。它计算了预测值与真实值之间差异的平方的平均值。对于单个样本,损失函数计算公式为:
其中y是真实值,
是预测值,n是特征的数量。
-
categorical_crossentropy:多分类交叉熵损失函数用于多类分类问题。在这种情况下,目标变量是一个独热编码(one-hot encoded)的向量。损失函数的计算公式为:
其中N是样本数量,C是类别数,
是真实标签的独热编码,而
是模型预测的概率,表示第 i 个样本属于第 j 个类别的概率。
-
binary_crossentropy:二分类交叉熵损失函数用于二分类问题。目标变量是一个二元向量,表示为0或1。损失函数的计算公式为:
其中 N 是样本数量,
是真实标签,而
是模型预测的概率,表示为属于正类的概率。
如果默认的损失函数不能很好地适用于问题,那么根据实际需要,可以自定义损失函数,然后将损失函数传递给keras的compile方法。
优化器——神经网络训练算法
优化器是一种在神经网络训练过程中更新权重的算法,keras中的优化器基于梯度下降算法。
-
梯度下降(Gradient Descent, GD):
- 最简单的优化算法。
- 通过沿着梯度的负方向更新参数来减少损失函数的值。
- 存在多种变体,如批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent, SGD)和小批量梯度下降(Mini-batch Gradient Descent)。
- 可能会陷入局部最小值或鞍点,且需要精心调整学习率。
-
随机梯度下降(Stochastic Gradient Descent, SGD):
- 每次更新只使用一个训练样本。
- 引入了随机性,有助于跳出局部最小值。
- 收敛速度较慢,但计算效率高。
- 适合浅层神经网络
-
动量(Momentum):
- 基于物理动量的概念,加速SGD的收敛速度。
- 利用过去梯度的信息来加快当前梯度的方向。
- 有助于稳定训练过程并加速到达最低点。
-
Nesterov加速梯度(Nesterov Accelerated Gradient, NAG):
- 是动量的一个变种。
- 在计算动量时考虑了未来的梯度方向。
- 有时可以更快地收敛,但可能会导致更大的震荡。
-
AdaGrad(Adaptive Gradient Algorithm):
- 为每个参数维护一个历史梯度累积值。
- 自动调整每个参数的学习率,对稀疏数据特别有效。
- 学习率会随着时间递减,可能过早地减小学习率,导致收敛困难。
-
RMSprop(Root Mean Square Propagation):
- 解决了AdaGrad学习率单调递减的问题。
- 为每个参数维护一个指数移动平均的梯度平方。
- 动态调整每个参数的学习率。
-
Adam(Adaptive Moment Estimation):
- 结合了Momentum和RMSprop的优点。
- 同时追踪梯度的一阶矩估计(即梯度的平均值)和二阶矩估计(即梯度的未中心化方差)。
- 是目前最常用的优化器之一。
- 适合深层神经网络
-
AdamW:
- 在Adam的基础上加入了权重衰减(Weight Decay)。
- 权重衰减是一种正则化方法,可以防止模型过度拟合。
- AdamW在大型模型训练中表现出色。
Adagrad(自适应梯度算法)是一种用于机器学习和深度学习模型训练的优化算法。它在2011年由Duchi等人提出。Adagrad的核心特点是对每个参数使用不同的学习率,这种自适应学习率是根据每个参数的历史梯度平方和来调整的。
Adagrad的工作原理如下:
- 对于每个参数,初始化一个累加器(通常为零),用于记录该参数的梯度平方和。
- 在每一次迭代中,计算当前参数的梯度,并将其平方与累加器中的值相加。
- 更新累加器的值,通常是取梯度平方和的平方根。
- 使用累加器的值来缩放当前参数的梯度,从而得到自适应学习率。
- 最后,使用这个自适应学习率来更新参数。
Adagrad的优势在于它能够自动调整学习率,对于不同参数的重要性给予不同的关注。在处理具有不同尺度的特征时,这种自适应性尤其有用,因为它可以减轻梯度消失或爆炸的问题,使得训练过程更加稳定。
使用Keras创建神经网络
导包,声明一个顺序模型
from keras.models import Sequential
model = Sequential()上面会创建一个顺序模型,我们现在只要往里面填充就好了
填充起来很简单,相当于搭积木
-
第一个Dense层有4个神经元(units=4),并且使用sigmoid激活函数。输入维度被设置为3(input_dim=3),这意味着网络预期的输入数据是一个包含3个特征的向量。
-
第二个Dense层有1个神经元(units=1),也使用sigmoid激活函数。这通常用于二分类问题,输出层的单个神经元可以表示概率。
调用model.summary函数来验证模型结构:
from keras.models import Sequential
from keras.layers import Dense
from keras import optimizers
import numpy as np
np.random.seed(9)
model = Sequential()
model.add(Dense(units=4, activation='sigmoid', input_shape=(3,)))
model.add(Dense(units=1, activation='sigmoid'))
sgd = optimizers.SGD(lr=1)
model.compile(loss='mean_squared_error', optimizer=sgd)
# 生成新的测试数据
X_test = np.array([[0, 0, 1], [0, 1, 1], [1, 0, 1], [1, 1, 1]])
Y_test = np.array([0, 1, 1, 0])
# 使用新的测试数据进行预测
predictions = model.predict(X_test)
print(predictions)
最后的与预测结果为:
| 0.0130. 0 |
| 0.9438 1 |
| 0.9457 1 |
| 0.0603 0 |
预测值非常接近真实值。
参考书籍《Python神经网络项目实战》[美]詹姆斯·洛伊