【2024泰迪杯】A 题:生产线的故障自动识别与人员配置 Python代码实现

1 问题
一、问题背景
随着新兴信息技术的大规模应用,工业生产线的智能化控制技术日益成熟。自动生产线
可以自动完成物品传送、物料填装、产品包装和质量检测等过程,极大地提高了生产效率和产品质量,减少了生产成本。自动生产线融入故障智能报警技术,能避免因故障带来的生产中断和经济损失;同时合理的人员配置,能够减少资源浪费、提高生产效率。
二、解决问题
问题 1: 根据附件 1 中的数据,分析生产线中各装置故障的数据特征,构建故障报警模型,实现故障的自动即时报警。
问题 2: 应用问题 1 所建立的模型,对附件 2 中的数据进行分析判断,实现生产线中各装置故障的自动即时报警,给出故障报警的日期、开始时间与持续时长,将结果存放到result2.xlsx 中(格式见表 1,模板文件在附件 2 中),并在论文中给出每条生产线中各装置每月的故障总次数及最长与最短的持续时长。
表 1 result2.xlsx 的格式
| 故障编号 | 1001 | 2001 | … | 6002 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 序号 | 日期 | 开始时间 | 持续时长/秒 | 日期 | 开始时间 | 持续时长/秒 | … | 日期 | 开始时间 | 持续时长/秒 |
| 1 | 3 | 579 | 67 | 1 | 4792 | 98 | … | 1 | 2047 | 51 |
| 2 | 4 | 1648 | 101 | 1 | 18379 | 72 | … | 2 | 9482 | 48 |
| 3 | 7 | 20947 | 96 | 3 | 1971 | 122 | … | 3 | 1903 | 58 |
| … | … | … | … | … | … | … | … | … | … | … |
问题 3 : 根据附件 3 中的数据,分析产品的产量、合格率与生产线、操作人员等因素的关系。
问题 4: 根据实际情况,现需要扩大生产规模,将生产线每天的运行时间从 8 小时增加到 24 小时不间断生产。针对问题 3 的 10 条生产线,结合问题 3 的分析结果,考虑生产线与操作人员的搭配,制定最佳的操作人员排班方案,将结果存放到 result4-1.xlsx 和result4-2.xlsx 中(格式见表 2 和表 3,模板文件在附件 4 中),并在论文中给出最佳的排班方案及相关结果。
要求排班满足如下条件:
(1) 各操作人员做五休二,尽量连休 2 天;
(2) 各操作人员每班连续工作 8 小时;
(3) 班次时间:早班(8:00-16:00)、中班(16:00-24:00)、晚班(0:00-8:00);
(4) 各工龄操作人员的人数比例与问题 3 中的比例相同;各操作人员的班次安排尽量均衡。
2 问题分析
2.1 问题一
(1)分析故障数据特征,包括故障发生的时间分布、故障发生的频率、故障类型的分布等。
(2)构建故障报警模型,是多标签的分类问题,或者是针对每个故障编码建模,就是一个分类问题。分类算法包括决策树、随机森林、支持向量机、逻辑回归和神经网络等。也可以建立成一个时间序列问题,注意数据集给的日期和时间,格式不是标准的datetime格式,是1、2、3、4这样的格式。需要转换为datetime再去建模。
2.2 问题二
(1)故障识别
- 如果建立成一个分类问题,针对每个生产线、每个故障编码的序列,分别训练一个分类模型。
- 如果建立时间序列回归问题,可以采用ARIMA、LSTM等构建模型进行故障预测。
题目要求以附件一的数据作为训练集,预测附件2,然后生成result2.xlsx文件。但是目前还没有提供附件二的数据,就可以以附件一为训练集和测试集。跑通baseline模型。
(2)故障时长计算
- 单次故障,不连续,持续时间为1
- 连续两次故障,持续时间为2
- 连续多次故障,持续时间为,开始时刻和结束时刻之间的时间差加1。
(3)每条生产线中各装置的每月统计数据
注意需要计算每个生产线的每个月统计数据,则需要使用分组操作来分析每条生产线中各装置的每月统计数据(故障次数、最长持续时长和最短持续时长)。
(4)输出结果
将每种类型的故障分析结果,横向排列,纵向是按故障发生的顺序排列,整理为dataframe格式,输出到result2.xlsx中。
2.3 问题三
(1) 产量分析
使用时间序列分析方法(如ARIMA模型)来预测产量随时间的变化趋势。
回归分析来探索产量与其他因素(如生产线编号、推送状态、装置故障等)的关系。
(2)合格率分析
逻辑回归分析来探索合格率与其他因素之间的关系;
使用决策树或随机森林等分类算法,寻找影响合格率的关键因素
(3) 故障分析
关联规则挖掘算法查找故障与其他因素(如操作人员、生产线编号)之间的关联性。
2.4 问题四
(1)在问题三的基础上,计算出每个生产线的生产效率和合格率,找出与操作人员、班次等因素的关系;
(2)根据生产效率和合格率的关系,制定最佳的操作人员排班方案;制定最佳的操作人员排班方案涉及到多个因素,包括但不限于:工作时间要求、人员能力匹配、轮班规则、休息时间安排、法定假期等。
(3)根据实际数据进行生产效率和合格率的计算,然后根据操作人员的工作时间和班次对其进行排班。这可能涉及到安排不同技能水平的操作人员,以确保生产线能够在高效率和高合格率下运行。实时调整排班计划,随着生产线的运行,实时监控生产效率和合格率的变化,及时调整操作人员的排班计划以适应变化的生产需求。结合其他因素进行综合考虑,如在排班计划中、操作人员的休息时间、加班安排、交接班等,以确保生产线的持续稳定运行。
3 Python代码实现
3.1 问题一
import pandas as pd
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = 'SimSun' # 换成自己环境下的中文字体,比如'SimHei'
df = pd.read_csv('A题-示例数据/附件1/M101.csv')
# 查看数据前几行
print(df.head())
# 故障数据分析
fault_columns = [col for col in df.columns if '故障' in col]
fault_counts = df[fault_columns].sum()
print(fault_counts)
# 可视化故障数据
plt.figure(figsize=(10, 6))
colors = sns.color_palette("hls", len(fault_counts))
fault_counts.plot(kind='bar', color=colors)
plt.title('Device Fault Counts')
plt.xlabel('Device')
plt.ylabel('Fault Count')
plt.savefig('img/1.png',dpi=100)
plt.show()



# 生产线编号分析
line_counts = df['生产线编号'].value_counts()
print(line_counts)
# 可视化生产线编号分布
plt.figure(figsize=(10, 6))
colors = sns.color_palette("hls", len(line_counts))
line_counts.plot(kind='bar',color = colors)
plt.title('Production Line Distribution')
plt.xlabel('Production Line Number')
plt.ylabel('Count')
plt.tight_layout()
plt.savefig('img/2.png',dpi=100)
plt.show()

import matplotlib.pyplot as plt
import warnings
import seaborn as sns
warnings.filterwarnings('ignore')
df = pd.read_csv('A题-示例数据/附件1/M101.csv')
# 物料推送气缸状态分析
push_counts = df['物料推送气缸推送状态'].value_counts()
pull_counts = df['物料推送气缸收回状态'].value_counts()
push_pull_counts = pd.DataFrame({'Push': push_counts, 'Pull': pull_counts})
print(push_pull_counts)
plt.figure(figsize=(10, 6))
# 可视化物料推送气缸状态
colors = sns.color_palette("hls", len(push_pull_counts))
push_pull_counts.plot(kind='bar', stacked=True,color = colors)
plt.title('Material Push Cylinder State')
plt.xlabel('State')
plt.ylabel('Count')
plt.tight_layout()
plt.savefig('img/3.png',dpi=100)
plt.show()

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 统计各装置故障的情况
fault_columns = ['物料推送装置故障1001', '物料检测装置故障2001', '填装装置检测故障4001', '填装装置定位故障4002',
'填装装置填装故障4003', '加盖装置定位故障5001', '加盖装置加盖故障5002',
'拧盖装置定位故障6001', '拧盖装置拧盖故障6002']
# 加载数据
data = pd.read_csv('A题-示例数据/附件1/M101.csv')
# 构建故障报警模型
# 首先,选取特征和目标变量
feature_columns = ['时间', '物料推送气缸推送状态', '物料推送气缸收回状态', '物料推送数', '物料待抓取数',
'填装数', '加盖数', '拧盖数', '合格数', '不合格数']
target_columns = fault_columns
data_len = 10000
X = data[feature_columns][0:data_len]
# 多标签问题
y = data[target_columns][0:data_len]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用随机森林模型进行训练
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 评估模型性能
print('混淆矩阵:')
print(confusion_matrix(y_test.values.flatten(), y_pred.flatten()))
print('\n分类报告:')
print(classification_report(y_test.values.flatten(), y_pred.flatten()))

3.2 问题二
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from datetime import datetime
from collections import defaultdict
# 读取数据
data = pd.read_csv('A题-示例数据/附件1/M101.csv')
# 定义故障字段
fault_columns = ['物料推送装置故障1001', '物料检测装置故障2001',
'填装装置检测故障4001', '填装装置定位故障4002', '填装装置填装故障4003',
'加盖装置定位故障5001', '加盖装置加盖故障5002',
'拧盖装置定位故障6001', '拧盖装置拧盖故障6002']
data.replace({1001: 1, 2001: 1, 4001: 1, 4002: 1, 4003: 1, 5001: 1, 5002: 1, 6001: 1, 6002: 1}, inplace=True)
# 故障报警日期、开始时间与持续时长
fault_info = defaultdict(list)
# line_number = data.groupby(['生产线编号'])
for line_number,line_data in data.groupby(['生产线编号']):
for label in fault_columns:
# 训练数据集长度
data_length = 10000 #只取部分数据,用于跑通baseline,应该为len(line_data)
# 构建故障预警模型
X = line_data[line_data.columns.difference(['日期', '时间','生产线编号'])][0:data_length]
y = line_data[label][0:data_length]
# 80%用于训练,20%用于测试
# train_len = int(0.8*len(X))
# X_train, X_test, y_train, y_test = X[0:train_len],X[train_len:],y[0:train_len],y[train_len:]
# 假设100%用于训练,100%用于测试
X_train, X_test, y_train, y_test = X,X,y,y
print(f'生产线编号:{line_number},故障编码:{label},训练集样本数:{len(X_train)},测试集样本数:{len(X_test)}')
。。。略,请下载完整资料
acc = accuracy_score(y_test, y_pred)
print("模型准确率:", acc)
# 预测故障报警,假设全部数据集为附件2数据
file2_df = line_data[line_data.columns.difference(['日期', '时间','生产线编号'])]
predictions = rf.predict(file2_df)
# 用生产线编号和故障编号,组成唯一的键,来唯一表示某个生产线上的特定故障数据
key = (line_number,label)
# 统计故障发生的日期、开始时间、持续时长
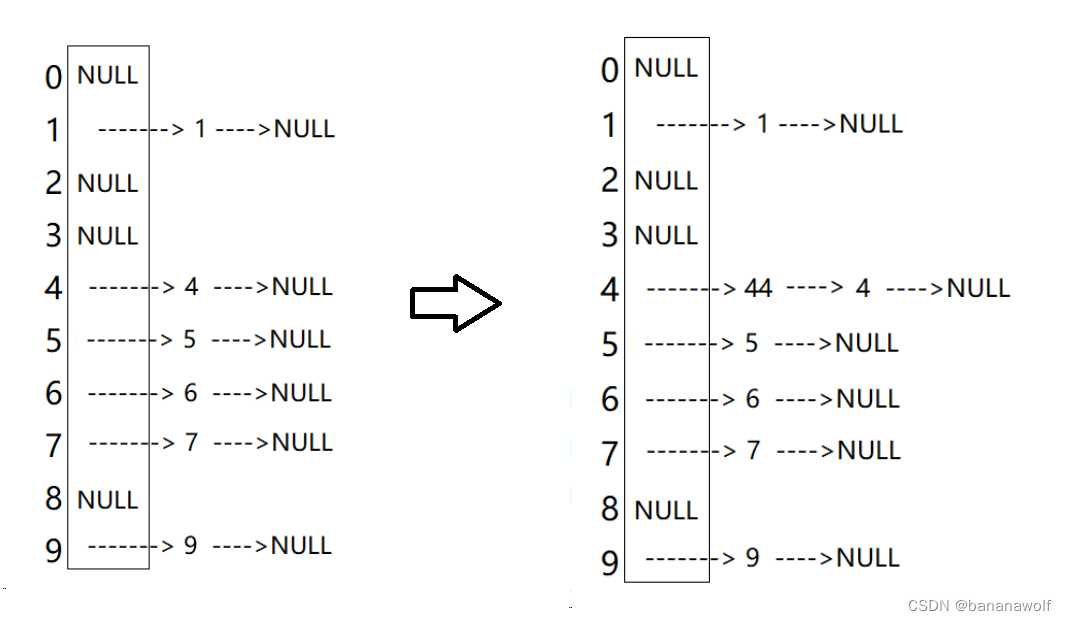
for i in range(len(predictions) - 1):
if predictions[i] == 1 and predictions[i+1] == 0:
# 只发生一次,持续时长为1
...略
fault_info[key].append((happend_date,happend_time,happend_duration))
if predictions[i] == 1 and predictions[i+1] == 1:
if len(fault_info[key])==0:
# 连续两次发生,持续时长为2
...略
fault_info[key].append((happend_date,happend_time,happend_duration))
else:
# 连续多次发生,持续时长为,当前时间-上一次发生时间
...略
fault_info[key][-1] = ((happend_date,happend_time,happend_duration))
fault_info

# 将每条生产线,故障发生的日期、开始时间、持续时长数据,转为result2.xlsx格式
fault_info_new = defaultdict(list)
for key in fault_info.keys():
if len(fault_info_new[key[1]])==0:
fault_info_new[key[1]] = fault_info[key]
else:
fault_info_new[key[1]] += fault_info[key]
print(fault_info_new)

result_df_list = []
for df_cols in fault_info_new.keys():
print(df_cols)
# 将特定故障编号的数据,保存为单个表格
temp_error_df = pd.DataFrame(fault_info_new[df_cols],columns=['日期', '开始时间', '持续时长/秒'])
result_df_list.append(temp_error_df)
# 横向合并所有故障编号的数据
result2_df = pd.concat(result_df_list,axis=1)
result2_df.loc[-1] = [x for x in fault_info_new.keys() for _ in range(3)] # 添加故障编码到首行
result2_df.index = result2_df.index + 1 # 将索引整体后移
result2_df = result2_df.sort_index() # 重新按索引排序
result2_df.to_excel('./提交数据/result2.xlsx',index=False)
print(result2_df)

# 统计每条生产线的数据,故障发生的日期、开始时间、持续时长数据
fault_info_new = defaultdict(list)
for key in fault_info.keys():
if len(fault_info_new[key[0]])==0:
fault_info_new[key[0]] = fault_info[key]
else:
fault_info_new[key[0]] += fault_info[key]
print(fault_info_new)

for line_n in fault_info_new.keys():
line_fault_info = fault_info_new[line_n]
third_elements = [x[2] for x in line_fault_info]
monthly_fault = sum(third_elements)
max_duration = max(third_elements)
min_duration = min(third_elements)
print(f"生产线:{line_n},每月故障总次数:{monthly_fault},最长时间:{max_duration},最短时间:{min_duration}")

3.3 问题三、四
请下载完整资料
4 完整资料